






利用AmazonAI芯片征服人工智能性能、成本和规模
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, Trinium, Machine Learning Models, Trinium Ai Chips, Large Language Models, Model Training Performance, Distributed Model Parallelism]
导读
生成式AI有望彻底改变各行各业,但其巨大的计算需求和不断攀升的成本带来了重大挑战。为了克服这些障碍,亚马逊云科技设计了专门用于AI的芯片,包括亚马逊云科技 Trainium2和亚马逊云科技 Inferentia2。在本次会议中,您将深入了解从芯片、服务器到数据中心的创新。此外,您还将听到亚马逊云科技客户Poolside以及负责开发Rufus(亚马逊的生成式AI助手)的亚马逊内部团队分享他们如何使用亚马逊云科技 AI芯片在各种产品和服务中构建、部署和扩展基础模型。
演讲精华
以下是小编为您整理的本次演讲的精华。
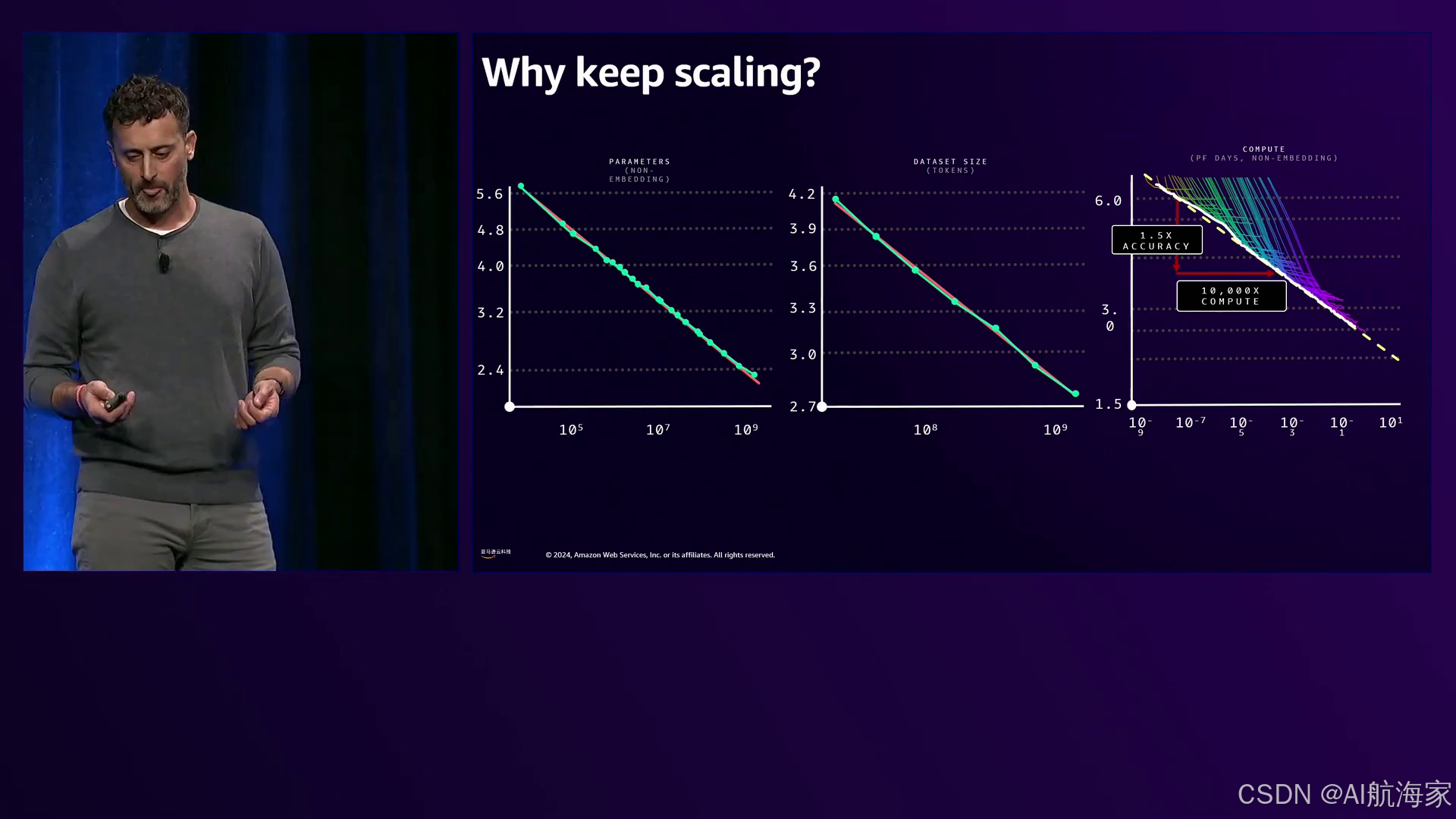
在过去十年中,AI模型的指数级增长得益于一项深刻的发现:同时增加模型规模、计算能力和训练数据量,可以提高模型的准确性和性能。这一发现由2020年著名论文“神经语言模型的规模定律”所证实,该论文表明只要计算、训练数据和模型规模以相似的速率增长,性能就会持续改善。深入探讨性能方面,该研究揭示了一个惊人的模式——在对数对数图上,如果数据科学家希望将基线模型的性能提高50%,他们需要投入高达10,000倍的计算资源才能实现这一目标。
这一认识对负责构建系统以满足客户日益增长的计算需求的Annapurna Labs团队产生了深远影响。为了在扩展以满足这些需求的同时控制功耗,持续的性能改进至关重要。客户的趋势是明确的:模型规模将继续增长,需要开发更强大的解决方案,如Trinium 2芯片。
Trinium 2是Annapurna Labs迄今为止最复杂的芯片设计,拥有令人印象深刻的1.3佩塔浮点运算能力。从单个Trinium 2芯片的计算能力比五年前推出的第一代Trinium服务器高出30%可以看出它的强大。此外,Trinium 2引入了一项突破性创新——它是云中唯一提供4倍稀疏性的解决方案,这意味着如果模型是稀疏的,用户可以享受高达4倍的可用计算能力提升。
Trinium 2服务器是一款真正的计算巨无霸,拥有20.8佩塔浮点运算能力、46TB/秒的HBM带宽和1.5TB的HBM内存。与亚马逊云科技上的其他选择相比,Trinium 2服务器的计算能力比最新的GPU实例P5N Compute高出30%,HBM内存比P5vN实例多30%。这些服务器正被构建成Annapurna Labs有史以来最大的集群。
独立基准测试网站Artificial Analysis验证了Trinium 2的出色性能。他们的结果显示,Trinium 2在延迟(首个标记的时间)和输出速度(吞吐量)方面,均实现了比云供应商下一个可用解决方案高出3倍以上的吞吐量。另一个非凡的例子来自Anthropic,Trinium 2比上一代Trinium芯片的性能高出60%,在执行HaiKu 3.5模型时比另一家云供应商部署相同模型快41%。
由AWSAI芯片驱动的Amazon Rufus系统的可扩展性是令人难以置信的。自今年7月推出以来,Rufus已成功支持数百万客户在Prime Day等重大活动中使用,利用了一个拥有超过80,000个Trinium推理芯片的集群。在8月的Prime Big Deal Days期间,Rufus在高峰时段产生了惊人的300万个标记/秒,在两天的活动中总共产生了3200亿个标记。
为了将Rufus投入生产并使用数千台主机每秒为数万个请求提供服务,Trinium和Inf2实例被证明是最佳选择。与具有相似性能的GPU主机相比,由于高速芯片间通信和更大的加速器内存,Trinium和Inf2主机提供了更好的性能,并且能够在未来托管更大的模型。此外,这些实例非常经济高效,可在全球范围内使用,从而实现全球扩展和服务客户流量。
Rufus团队利用亚马逊云科技弹性容器服务(ECS)部署了他们的服务,每个区域都能够启动使用Trinium和Inf2实例的实例以应对流量突发。这种跨区域托管方法确保了高度的服务弹性。在每个ECS服务中,都构建并部署了容器,包括由Volum和AWSNeuron SDK驱动的Triton Server,使团队能够利用这两个组件的优化并受益于Triton丰富的推理服务器功能。
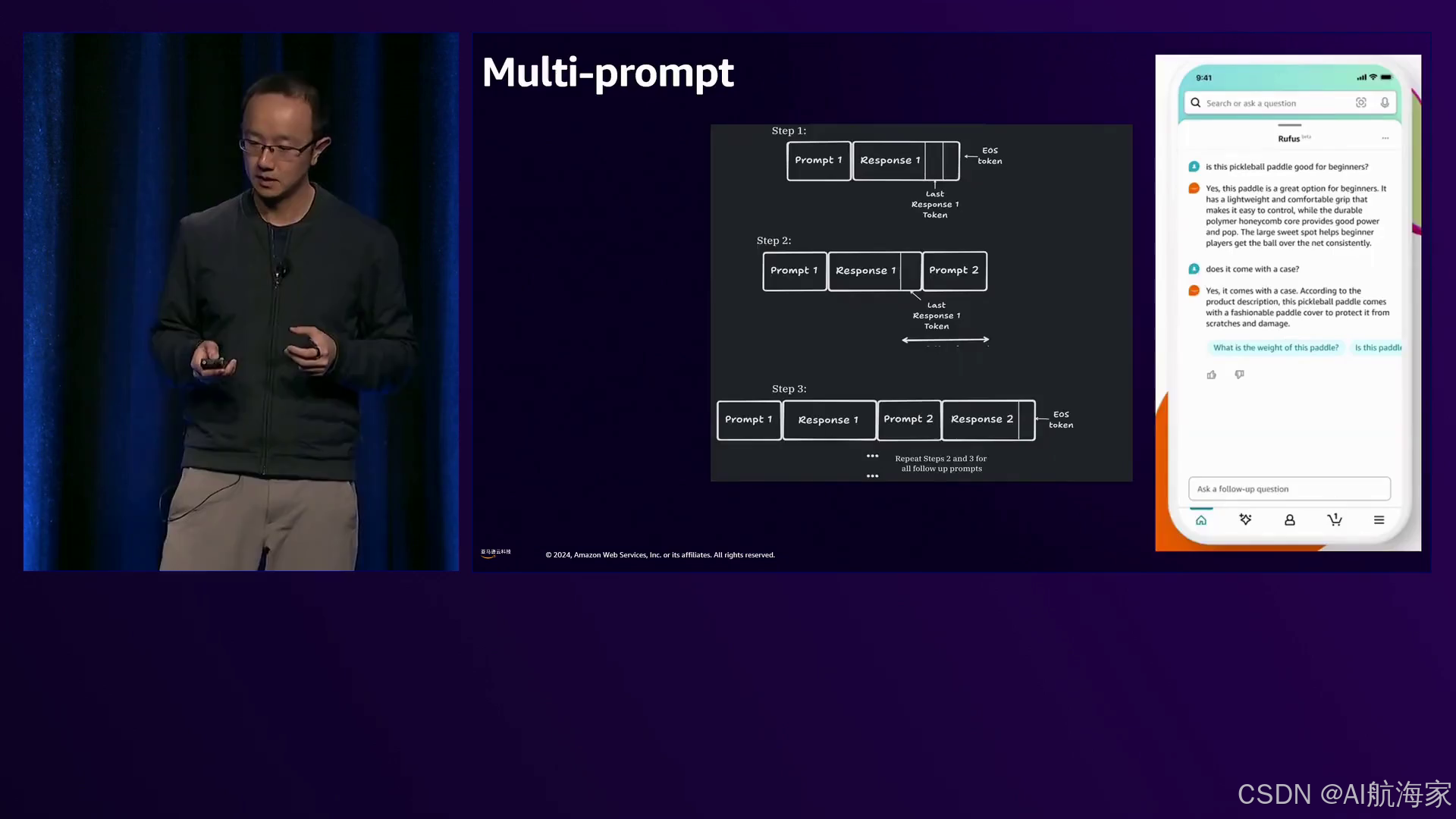
优化在Rufus取得成功中发挥了关键作用。分析发现初始性能不佳,促使团队根据模型大小设定了一个新的积极的延迟目标。流式处理(将标记在生成后立即返回,而不是等到最后)将整体首次响应延迟从3到15秒(取决于响应长度)降低到仅1秒。多提示(将提示分为初始提示和后续提示)进一步提高了性能和模型质量。量化(将模型权重从16位浮点数压缩为8位整数)降低了上下文编码和解码延迟。
通过Neuron SDK和Triton Server的集成,Rufus可以利用Continuous批处理功能将单主机吞吐量提高4倍。这种优化允许服务器在标记生成级别对序列进行批处理,确保每个请求在完成时立即返回响应,从而最大化资源利用率。
为了克服由于可变延迟和低主机并发性导致无法均匀分配请求到各主机的挑战,Rufus团队利用了亚马逊云科技应用程序负载均衡器提供的最少未完成请求算法。该算法使他们能够根据每台主机的繁忙程度分配请求,与循环负载均衡相比,整体车队吞吐量提高了20%。
Continuous批处理进一步优化了资源利用率,允许服务器在标记生成级别对序列进行批处理。通过这种方法,请求可以在完成时立即返回响应,而无需等待填满静态批量大小。这种优化通过Volum和Neuron SDK的集成实现,使Rufus能够将单主机吞吐量提高4倍。
展望未来,Rufus团队计划利用Trinium 2主机提供的新计算功能,如低位量化计算和稀疏计算,为他们的下一代模型提供动力。此外,他们将利用Niki内核开发先进的算法,以更高效地处理数百或数百万个标记,并继续为Volum和Neuron SDK做出优化贡献。
Poolside是一家从事AI模型用于软件开发的前沿AI公司,他们分享了将基于PyTorch的推理堆栈移植到Neuron的经验。尽管一开始存在挑战,如保持性能并适应推理堆栈的频繁变化,但最终过渡还是成功了。关键的经验教训包括改变思维方式以与Neuron的方法保持一致、利用提供的库如NXD和Torch Neuron X,以及利用硬件的Niki语言功能。
Poolside见证了显著的性能提升,包括通过使用提供的跟踪实现100%的加速,以及通过编写专门的Niki内核在推理步骤中实现4倍的加速。这些内核虽然只有大约50行代码,但却能实现一些本来很难实现的优化,如在推理步骤中实现100倍的加速,在预填充步骤(处理提示)中实现2倍的加速。
对Poolside而言,过渡到Trinium 2被形容为“魔术般的体验”。仅仅通过在Trinium 2机箱上运行现有代码,他们就观察到了开箱即用的50%性能提升,无需任何代码更改。Trinium 2的128个神经元核心(是Trinium 1的4倍)使Poolside能够在每个实例上提供4倍数量的模型副本。此外,虚拟核心分组功能(将两个物理神经元核心组合为一个虚拟核心)提供了更大的内存(每个虚拟核心24GB HBM)和增强的设备内并行性。
初步性能数字展示了Trinium 2为Poolside带来的潜力。在2k上下文长度时,他们实现了大约26个标记/秒,在4k上下文长度时略有下降。简单移植到Trinium 2在2k长度时产生了大约50%的性能提升,在4k长度时提升略小。然而,通过利用Niki中新的分片功能(允许明确指定跨核心的数据处理),Poolside观察到了比常规Trinium 2代码更大的性能提升,尽管在4k上下文长度时由于正在进行的优化工作而有所下降。
下面是一些演讲现场的精彩瞬间:
Edubrious公司的CEO强调,公司的使命是提供安全、高性能和可扩展的前沿人工智能技术访问,使客户能够创新并推动进步。

著名的2020年论文《神经语言模型的规模定律》表明,随着计算、数据和模型规模以相似的速率增长,性能会有可预测的提高,但要实现50%的改进需要计算量增加10,000倍。
亚马逊展示了他们的多提示优化技术,通过将提示分解为初始提示和后续提示,减少了令牌数量,提高了提示跟随质量,从而提高了语言模型的效率和质量。
Rufus通过连续批处理优化了输入处理,动态地将请求分组进行并行处理,避免了计算资源的浪费。

亚马逊云科技宣布推出Niki,一个新的单内核接口,允许开发人员直接在训练之上构建和定制计算内核,具有对芯片指令集的低级访问权限,并且语言与OpenAI Titan和Numpy保持一致。
使用Niki,开发人员可以编写Python式代码,直接利用底层硬件,实现高效和优化的操作,无需深入了解低级汇编或深入的技术知识。

Andy Jassy对亚马逊澳大利亚的启动客户和合作伙伴表示感谢,他们为开发和完善Jax技术提供了宝贵的支持。

总结
在这场引人入胜的演讲中,Annapurna Labs产品主管Gadi Hoot揭开了突破性的Trinium 2芯片和Ultra Server的面纱,旨在征服人工智能性能、成本和可扩展性的挑战。凭借惊人的1.3佩塔浮点运算和4倍稀疏性,Trinium 2承诺前所未有的性能提升。结合四个Trinium 2节点的Ultra Server,可提供高达80佩塔浮点运算的密集计算能力和6TB的HBM内存,从而支持训练万亿参数模型。
Gadi强调了三个关键点:1)模型规模的指数级增长需要持续创新计算能力和效率。2)Neuron SDK及其开源库NXD和Niki等,使开发人员能够充分利用Trinium芯片的潜力。3)与谷歌和Anthropic等行业领导者合作,利用JAX和PyTorch等框架,促进代码可移植性,加速人工智能创新。
演讲最后呼吁开发人员和研究人员拥抱Trinium生态系统,开启人工智能性能、成本效益和可扩展性的新境界,为该领域的突破性进展铺平道路。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









