









突然提出了一个质疑:http2一定比http1.1快吗?
中学老师经常告诉我们,当题中有“一定”这个关键词时,这个题基本都是错的。
那么对于“http2一定比http1.1快吗?”这个问题也是如此,在很多场景下http1.1仍然比http2快。
具体在哪些场景下http2比http1.1慢,在了解了http1.1和http2的原理后,便可很容易列举几个,再配合实验验证即可。
根据上面的前言,提炼下本文的重点有:
- http1.1的基本原理,解决了什么问题?
- 作为http1.1的升级,http2解决了什么问题?
- 什么场景下http2比http1.1快,并举例实践证明
- 什么场景下http2反而比http1.1慢,并举例实践证明
- http1.1和http2所依赖的传输层TCP是如何工作的?
http1.1快速回顾
http1.1正式发布于1997年,在它之前的http版本为http1.0,支持tcp持久连接是http1.1的最大的特点。即:
- HTTP/1.0: 每个请求都需要建立一次新的 TCP 连接,处理完请求后立即关闭,称为短连接。
- HTTP/1.1: 默认启用了持久连接(也称为长连接),允许在同一个 TCP 连接上发送多个请求,避免频繁的连接建立与断开,从而减少延迟和服务器资源消耗。
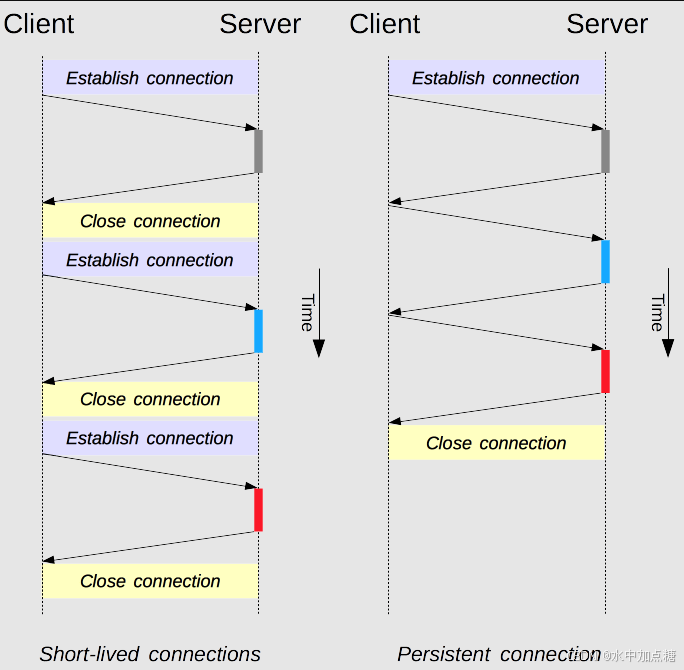
了解TCP的朋友都知道,一个tcp的连接与释放需要3次握手和4次挥手,如果一个网页加载的资源过多,仅tcp建连过程就会带来较多的RTT(Round-Trip Time,往返时延)开销。
从前,在那个网页基本全是本文的年代,每次打开一个网页进行一次tcp建连也并没有什么影响
而如今,互联网早已是4G、5G、千兆各种带宽的背景下,一个页面所需要加载的资源数和以前相比早已不是一个数量级,HTTP1.1中的tcp长连机制也是技术变革必然的产物。
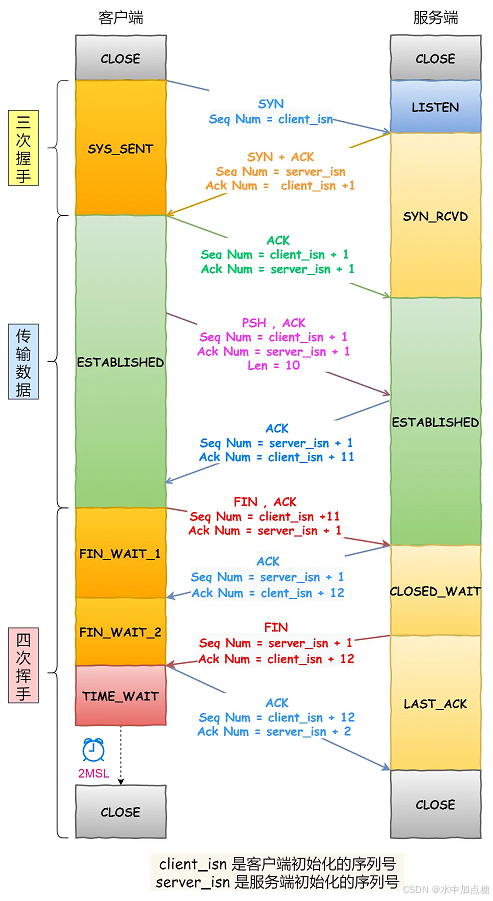
TCP通信的全流程图如下:
以一个具体的例子为例,对比下http1.0和http1.1时的耗时。
例一:
假设一个网页中只有一个小于mtu大小的html纯文本,无其他css、图片、js等资源,客户端到服务端的一次RTT耗时为30ms,一个网页加载在http1.0和http1.1情况下,RTT和耗时数据则分别为:
- http1.0,RTT=4.5,耗时=4.5*30ms=135ms
- http1.1,RTT=4.5,耗时=4.5*30ms=135ms
例二:
假设一个网页中由150个小于mtu大小的资源文件组成,则RTT与耗时数据为:
- http1.0,RTT=4.5150=675,耗时=67530ms=20250ms
- http1.1,RTT=4.51+150=154.5,耗时=154.530=4635ms
在http1.1和http1.0时,一般浏览器都允许对同一个域名最大允许6个tcp并行执行,则上例中的http1.1最终的理论时延大致为:4635ms/6=772.5ms;http1.0时,20250/6=3375ms
3375/772.5约等于4
由此可以看出,在一个网页所需加载资源较多的情况下,http1.1与http1.0相比,http1.1的性能提升是巨大的。
http2快速回顾
目前的浏览器,一般都允许对同一域名同时发起多个连接,以某个浏览器使用http1.1发起请求,其http瀑布图如下:
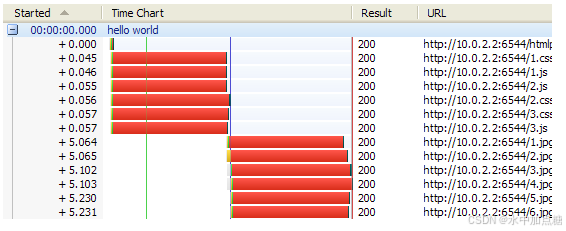
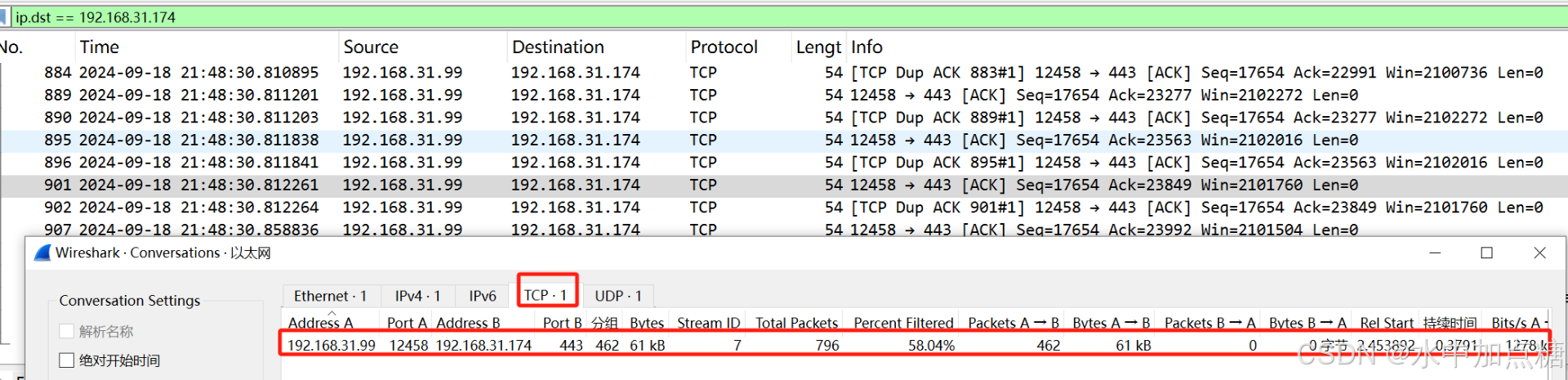
从图中可以看出,此浏览器同一时刻对同一域名发起了6个http请求,再通过抓包可以看出这6个http请求会开辟6个tcp连接,通过对tcp连接的复用来循环发起http请求。
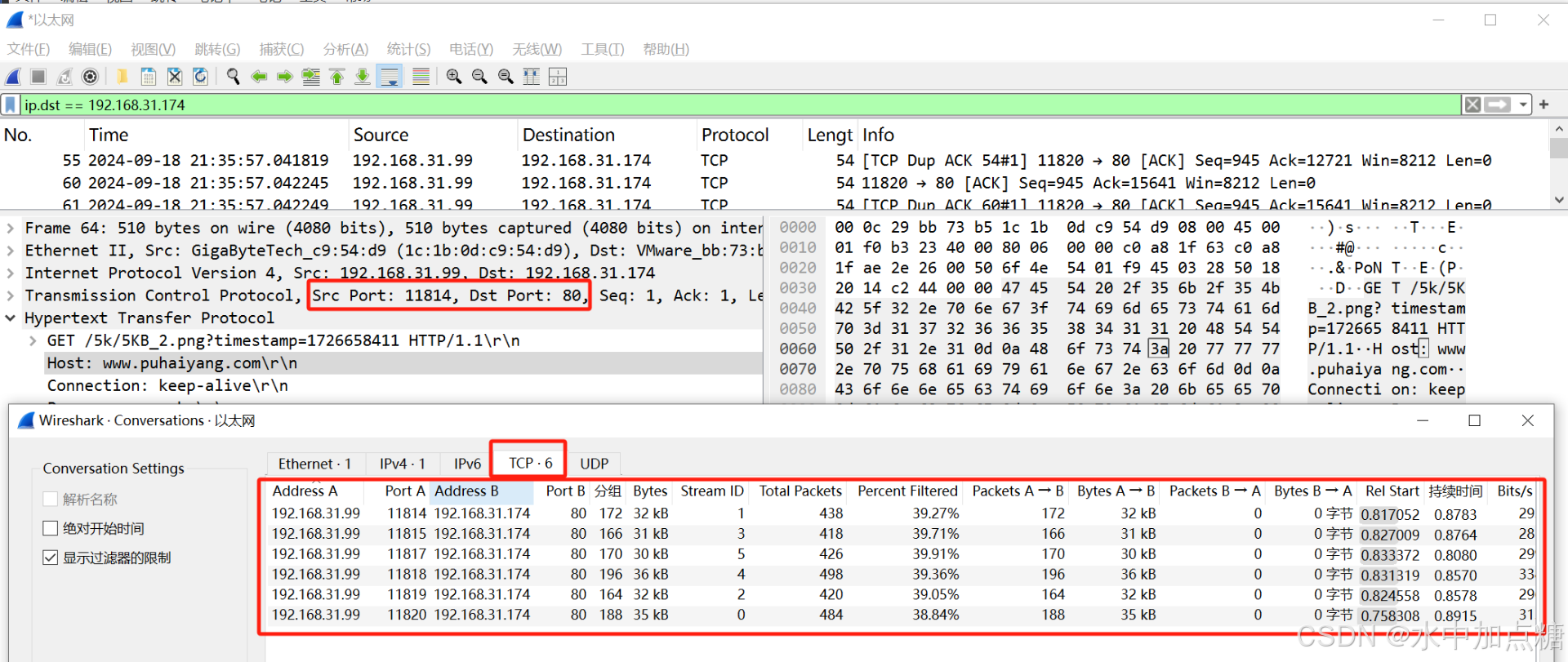
但对于服务端来讲,每新增一个tcp连接,服务端都需要对它进行维护,tcp层数量上的消耗并没有减少。
另一方面,如果同一时刻浏览器发起的所有请求所需执行的时间过长,则整个http请求也会被同步等待。
那么是否有一种机制,让TCP只建立一次在后续的http通信中复用这一个TCP连接即可?
答案是:有的。http多路复用——便是http2的亮点之一。
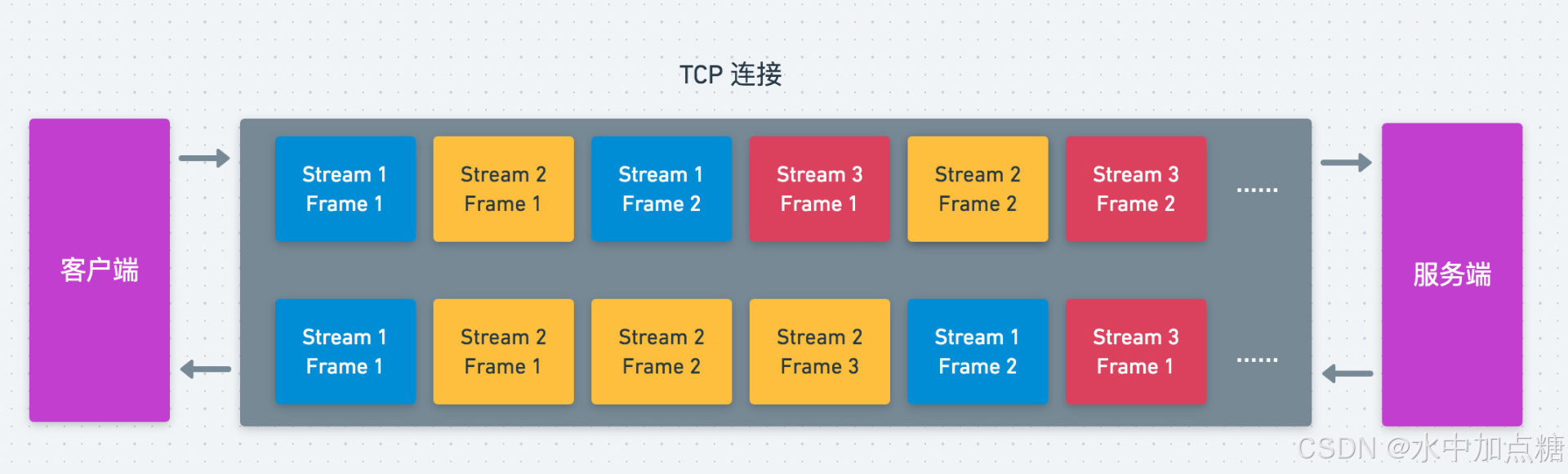
在http2中引入了stream(流)和frame(帧)的概念,并不再使用Http1.1及之前版本中的字符流,改由二进制的字节流进行数据的传输。
当发送一个http请求时,客户端为每一个请求分配一个独立的stream并为它编号,再根据stream的大小拆分为一个或多个frame,当服务端收消息后,再将frame组装为完整的请求。服务端向客户端响应数据时也使用上述流程进行响应。
由此,http请求的发送与响应不再与独立的http请求为单位,发送时仅依靠同一个TCP通信即可,通过这种机制也解决了http1.1中的队头阻塞问题。
http1.1与http2通信示例图如下:
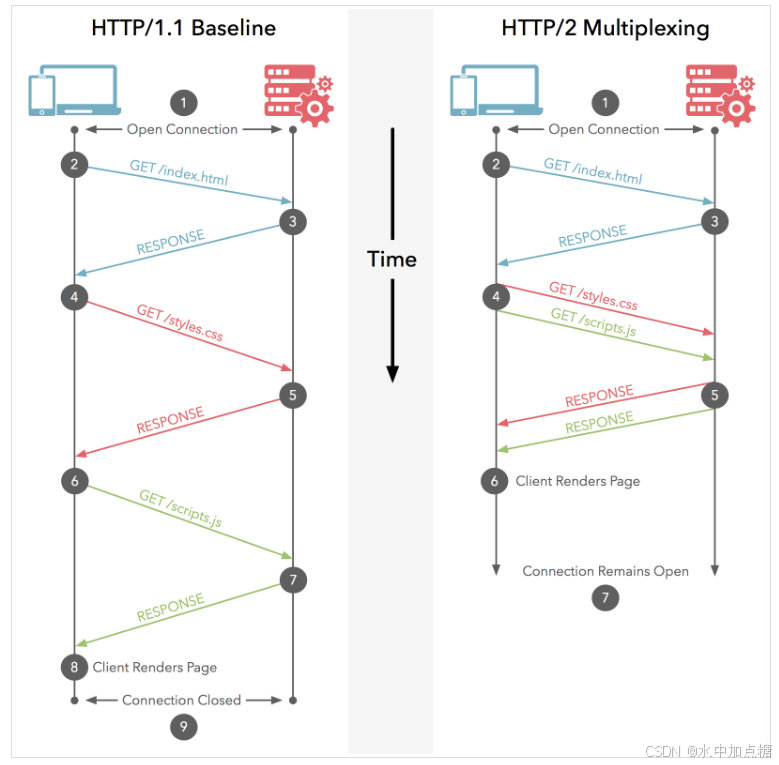
http2与http1.1相比的升级内容还有数据压缩、服务器推送、优先级依赖等其他升级点,这里不再详细展开。
http2请求某网页瀑布图如下:
使用harviewer查看
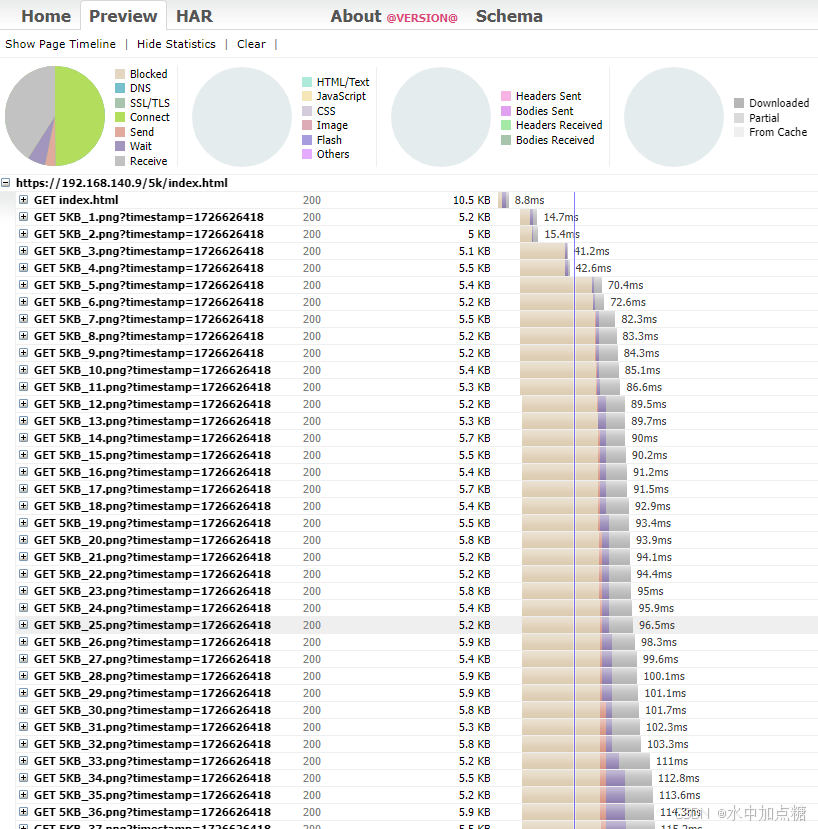
从瀑布图中可以看出,http2.0时各请求不再会有tcp连接最大并行数的限制,而更像是一个大水管一样,各个http请求一起跑,不再有http1.1那样的明显的排队阻塞情况。
tc模拟服务器延时
觉得跑得太快,可以在server端用系统自带的TC(Traffic Control)模拟下网络延迟,以让请求效果更逼真。tc模拟某个网卡的延迟,配置示例命令如下:
# 删除任何现有的qdisc
root@ubuntu:/data/nginx/html# sudo tc qdisc del dev enp1s0 root
# 查看当前qdisc策略
root@ubuntu:/data/nginx/html# tc qdisc show dev enp1s0
qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn
root@ubuntu:/data/nginx/html# sudo tc qdisc add dev enp1s0 root handle 1: htb default 12
# 设置带宽,1Gbit
root@ubuntu:/data/nginx/html# sudo tc class add dev enp1s0 parent 1:1 classid 1:12 htb rate 1000mbit ceil 1000mbit
# 设置延迟,100ms
root@ubuntu:/data/nginx/html# sudo tc qdisc add dev enp1s0 parent 1:12 handle 10: netem delay 100ms
# 查看qdisc策略
root@ubuntu:/data/nginx/html# sudo tc qdisc show dev enp1s0
qdisc htb 1: root refcnt 2 r2q 10 default 18 direct_packets_stat 437 direct_qlen 1000
qdisc netem 10: parent 1:12 limit 1000 delay 100.0ms
# 查看class策略
root@ubuntu:/data/nginx/html# sudo tc class show dev enp1s0
class htb 1:12 root leaf 10: prio rate 1Gbit ceil 1Gbit burst 1375b cburst 1375b
root@ubuntu:/data/nginx/html#
之后再看一下http请求的瀑布图,效果如下:
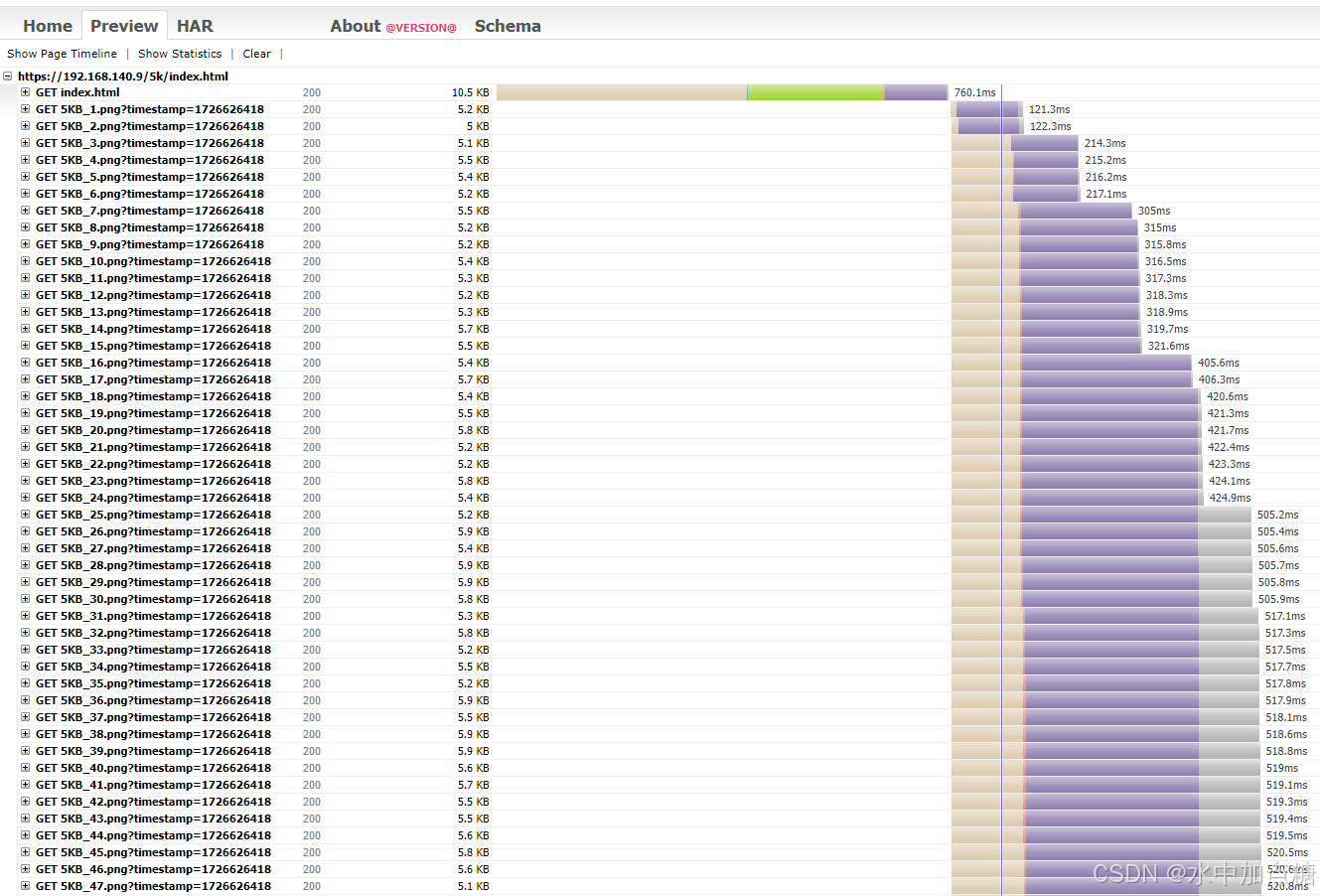
http2.0时,在wireshark中的某个抓包,截图如下:
从上面可以看出,使用http2进行通信时tcp仅只有一个通道。
http2.0优于http1.1请求实例
在了解http2.0与http1.1的基本知识后,我们知道在http2.0中因为有了tcp的多路复用、头部压缩、采用二进制等特点,在大多数的web场景下http2.0的性能是优于http1.1的。
测试环境:
这里以一个有150张图片的网页,每张图片大小5k,且客户端和服务端网络链路流畅的情况下测试一下耗时。
生成测试图片和网页
测试所用到的图片和网页html使用python脚本生成,代码如下:
from PIL import Image, ImageDraw, ImageFont
import io
import os
import time # 用于生成时间戳
# 生成带有文本的PNG图片
def generate_image_with_text_png(size_kb, index, initial_width=500, initial_height=250):
# 设置初始图片大小和步长
width = initial_width
height = initial_height
# 要写入图片的文本,显示目标大小和索引号
text = f"{size_kb}KB_{index}"
# 生成图片并调整大小直到达到目标文件大小
while True:
# 创建RGB图像(白色背景)
image = Image.new('RGB', (width, height), color=(255, 255, 255))
# 初始化绘图对象
draw = ImageDraw.Draw(image)
# 根据图片尺寸计算字体大小(字体大小为图片高度的 10%)
font_size = int(height * 0.1)
# 设置字体和大小(可以使用系统自带字体)
try:
font = ImageFont.truetype("arial.ttf", font_size) # 使用系统中的字体
except IOError:
font = ImageFont.load_default() # 如果找不到字体文件,使用默认字体
# 使用 textbbox 获取文本边界框
text_bbox = draw.textbbox((0, 0), text, font=font)
text_width = text_bbox[2] - text_bbox[0]
text_height = text_bbox[3] - text_bbox[1]
# 计算文本放置位置(居中对齐)
position = ((width - text_width) // 2, (height - text_height) // 2)
# 在图片上绘制文本
draw.text(position, text, fill=(0, 0, 0), font=font)
# 通过绘制一些线条和点来增加图像复杂性
for i in range(0, width, 20):
draw.line((i, 0, i, height), fill=(0, 0, 255), width=1)
for j in range(0, height, 20):
draw.line((0, j, width, j), fill=(255, 0, 0), width=1)
# 将图像保存到内存中
img_bytes = io.BytesIO()
image.save(img_bytes, format='PNG')
img_size = len(img_bytes.getvalue())
# 如果图片大小超过了目标大小,或者接近目标大小,结束循环
if img_size >= size_kb * 1024:
break
# 增大图片分辨率
width += 100
height += 50
# 返回生成的PNG图片数据
return img_bytes.getvalue()
# 生成HTML页面
def generate_html_page(image_paths, output_html="index.html"):
# HTML页面开头,增加了CSS的Flexbox布局
html_content = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Generated Images</title>
<style>
body {
font-family: Arial, sans-serif;
}
.gallery {
display: flex;
flex-wrap: wrap;
gap: 10px; /* 图片之间的间隔 */
}
.gallery img {
width: 100px;
height: 100px;
object-fit: cover; /* 保持图像缩放且不拉伸 */
}
</style>
</head>
<body>
<h1>Generated Images</h1>
<div class="gallery">
"""
# 为每个图片路径生成对应的<img>标签,使用相对路径并附加时间戳
timestamp = int(time.time()) # 获取当前时间戳
for img_path in image_paths:
relative_path = f"./{os.path.basename(img_path)}" # 使用相对路径
html_content += f'<img src="{relative_path}?timestamp={timestamp}" alt="{relative_path}">\n'
# HTML页面结尾
html_content += """
</div>
</body>
</html>
"""
# 将HTML内容保存到文件
with open(output_html, "w") as html_file:
html_file.write(html_content)
print(f"HTML page saved as: {output_html}")
# 批量生成图片并创建HTML页面
def generate_images_batch(size_kb, count, output_dir="generated_images", html_file="index.html"):
# 创建输出目录(如果不存在)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
image_paths = [] # 存储生成的图片路径
# 逐个生成图片
for i in range(1, count + 1):
# 生成带索引号的图片
image_data = generate_image_with_text_png(size_kb, i)
# 动态设置文件名
file_name = os.path.join(output_dir, f"{size_kb}KB_{i}.png")
# 将生成的PNG图像保存为文件
with open(file_name, "wb") as f:
f.write(image_data)
# 将图片路径添加到列表中
image_paths.append(file_name)
print(f"Image {i} saved as: {file_name}")
# 生成HTML页面
generate_html_page(image_paths, output_html=os.path.join(output_dir, html_file))
# 示例:生成150张大小为5KB的图片并生成对应的HTML页面
generate_images_batch(5, 150)
上面的python脚本可以生成150张大小为5K的图片,在每张图片由不同的线条和索引号组成;并且生成了一个index.html网页文件,在网页文件中会有150个img标签对生成的150个图片进行引用。
生成后的文件截图如下:

再将资源放到nginx中,并依次配置http1.1和http2.0进行测试。
nginx的配置部分可参考《NGINX开启HTTP3,给web应用提个速》中的配置章节。
1ms以内低延场景对比测试
http1.1时,将http2设置为off。在浏览器发送请求,耗时截图如下:
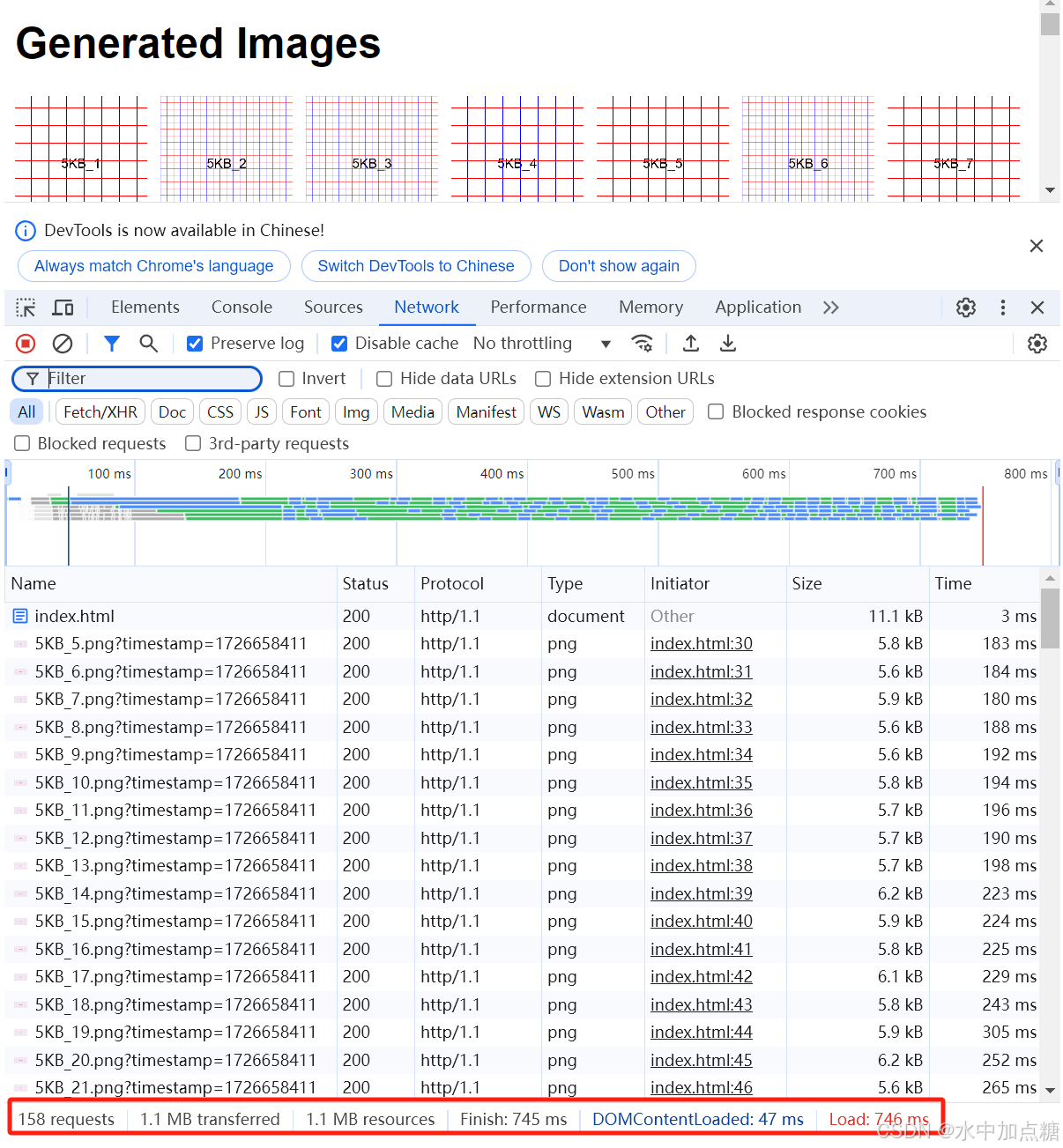
Finish时间为:745ms
http2.0耗时,将http2设置为on。截图如下:
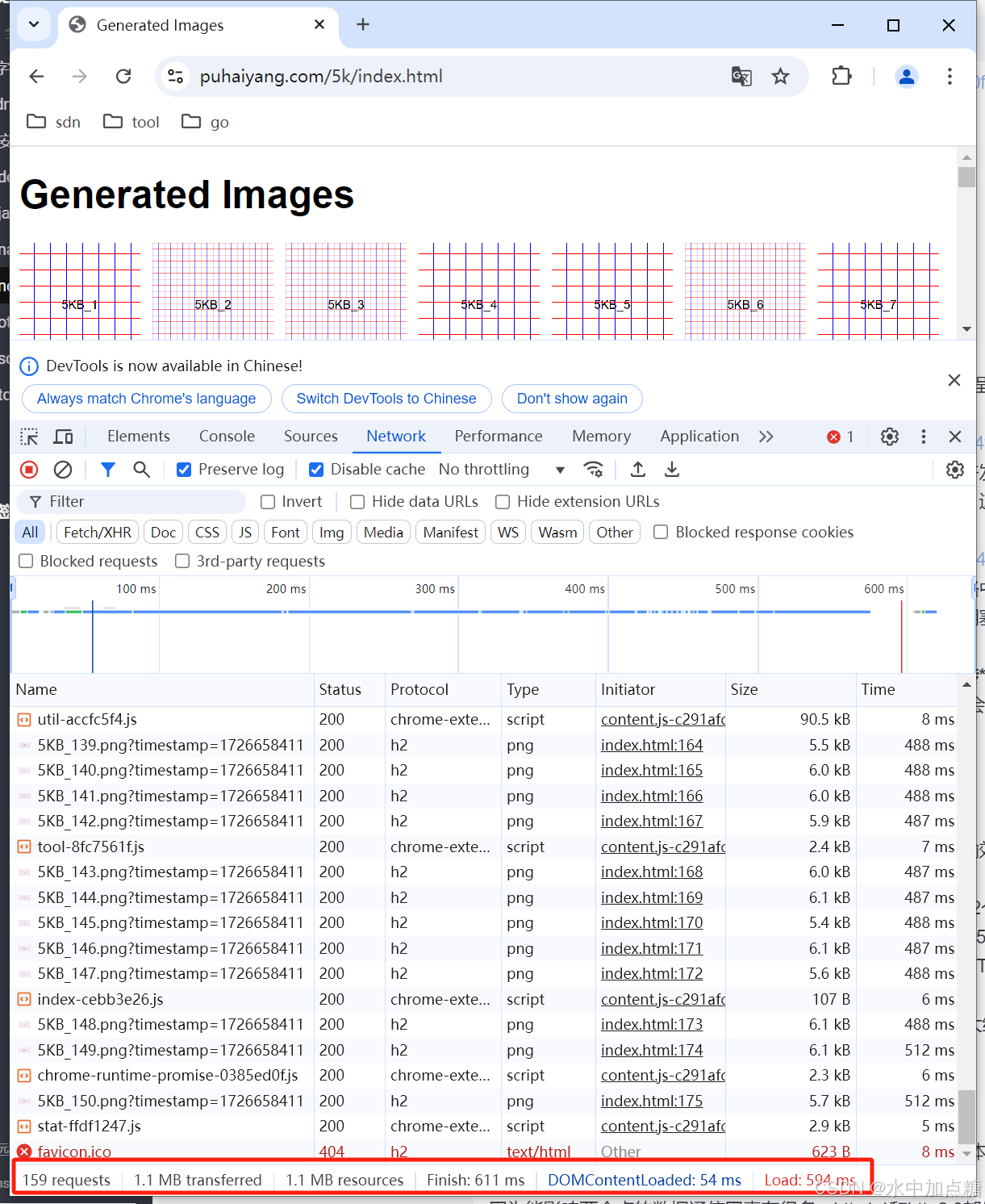
Finish时间为:611ms
从上面看差别并不明显,http2只比http1.1快100ms。这是因为客户端到服务器的时延非常低且没有链路阻塞,而在实际环境中客户端和服务器的时延一般会有几十毫秒。
50ms延时场景对比测试
这里再用tc工具模拟时延为50ms的场景。
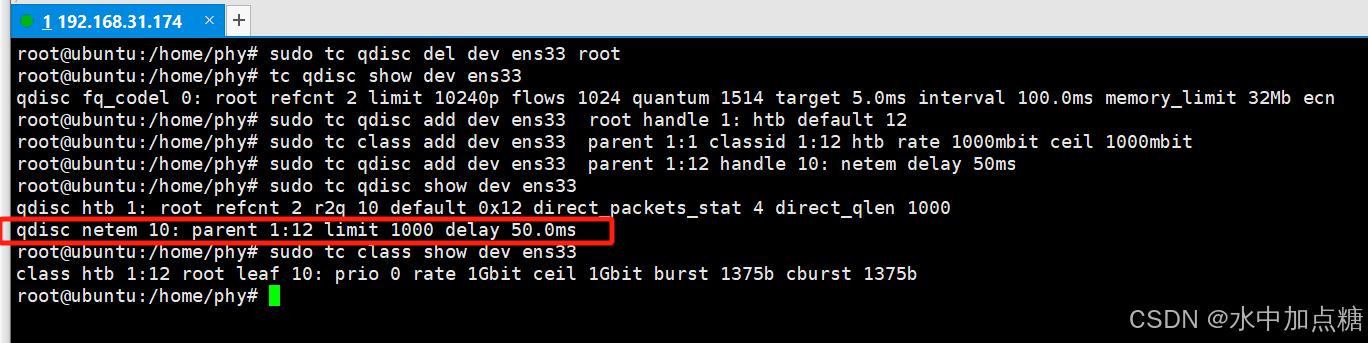
配置命令参考本文中tc模拟服务器延时部分,配置好后用icmp包验证下延时是否生效。
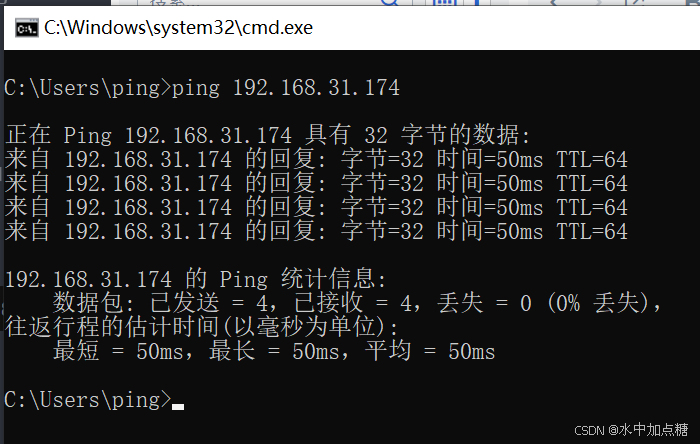
显示时间为50ms则代表配置时延成功。
再次打开浏览器进行验证。
http1.1
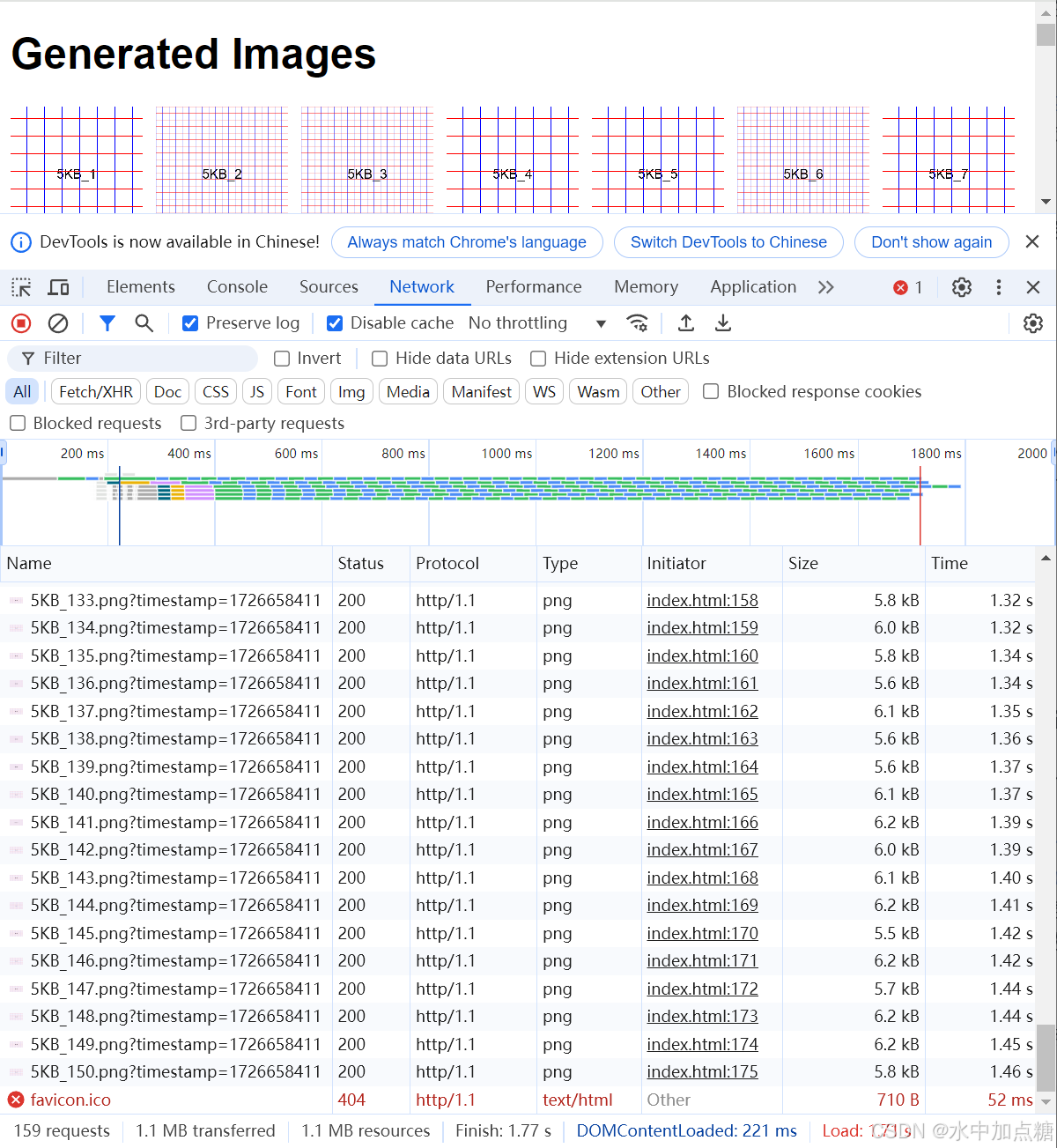
耗时:1.77s
http2.0
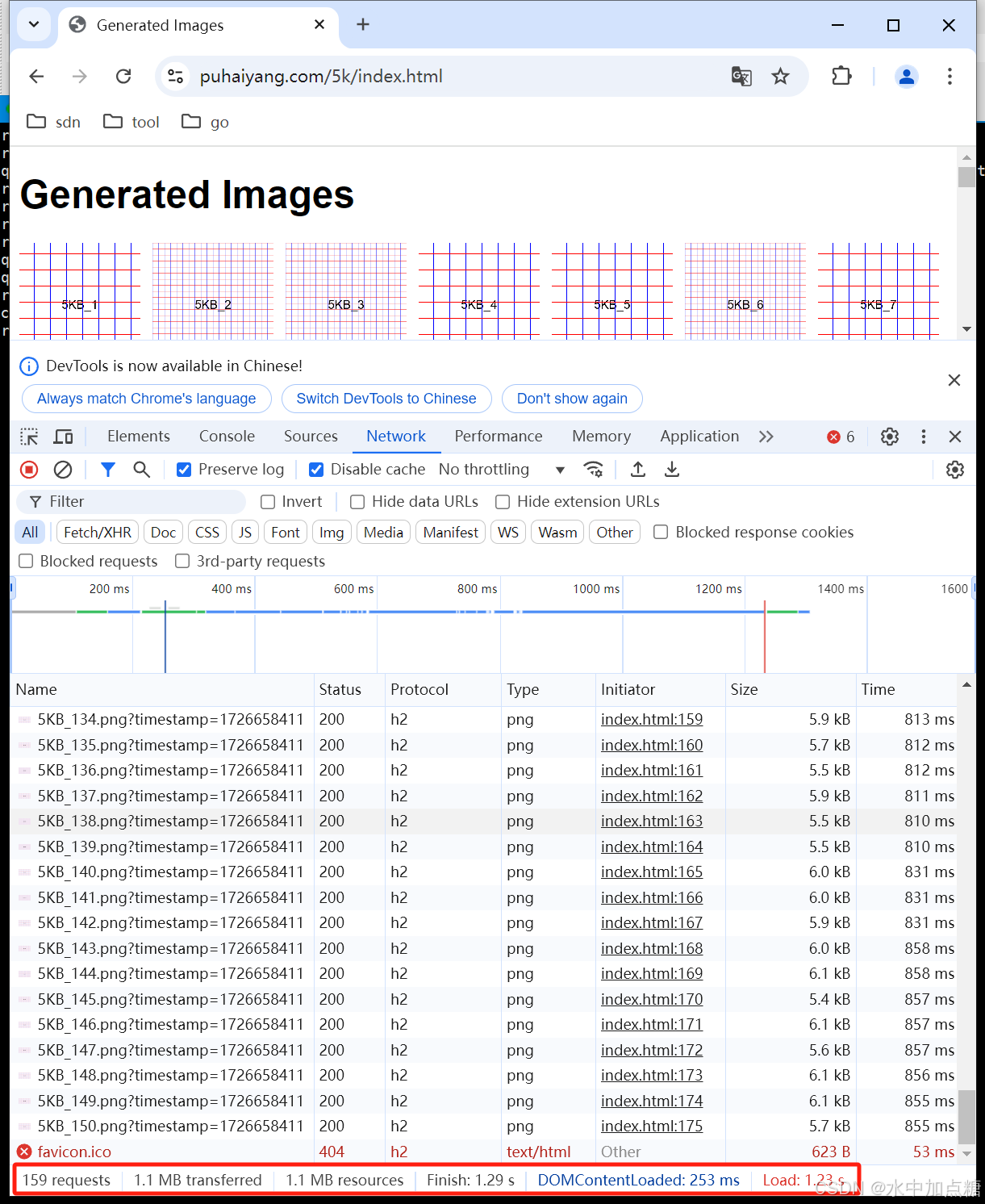
耗时:1.29s
差值为1.77-1.29=0.48s。
从结果来看,其性能略优于http1.1,如果某个http请求有阻塞的情况,则效果会更加明显,这里不再验证。
另外,网上可以找到这张gif图片,对比了http1.1和http2在加载同样一张图片区别:

从上图来看,http2还是比http1.1快上很多。
tcp滑动窗口与拥塞控制快速回顾
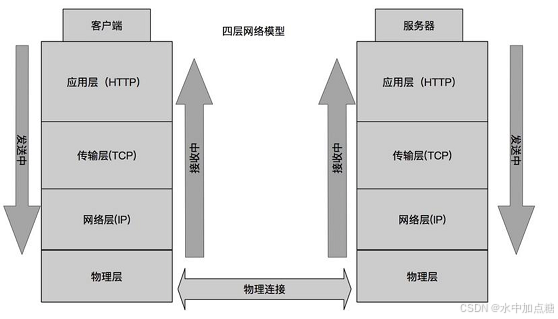
http协议属于应用层协议,他们的都基于传输层实现,关于它们的通信细节再一起回顾一下。
因为http1.1和http2.0都是基于tcp来进行通信的,在通信的过程中tcp中的各种机制也是避免不了的,其中和访问速率比较有相关性的是tcp的滑动窗口和拥塞控制机制。
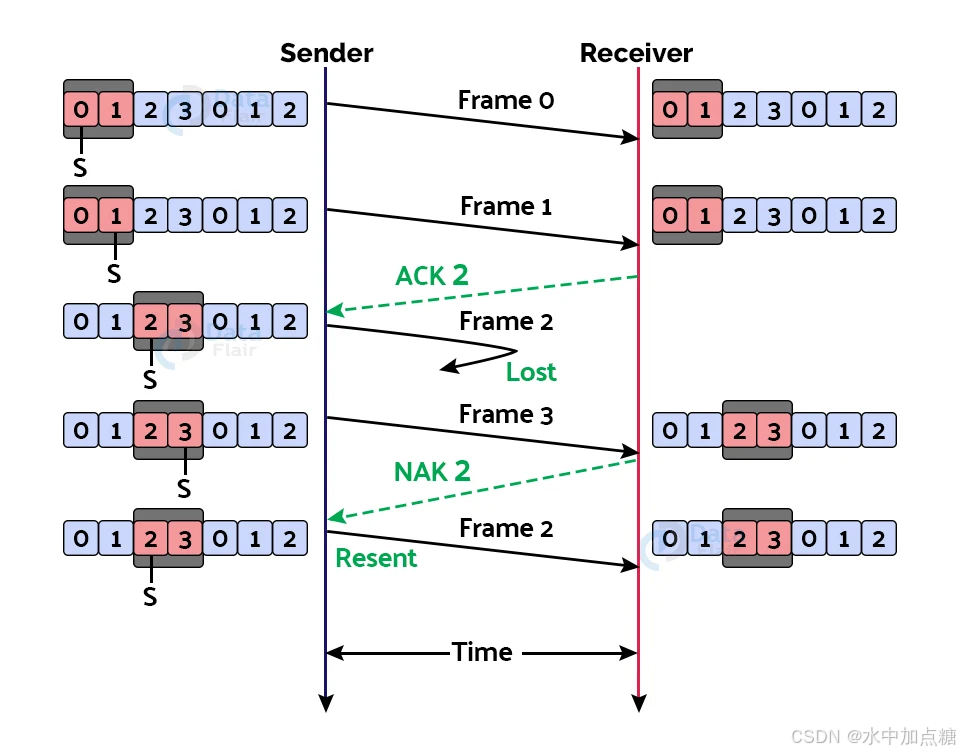
滑动窗口机制是TCP协议中实现流量控制的重要机制,它允许发送方在收到接收方的确认应答(ACK)之前,继续发送多个数据分组,而不是每发送一个分组就停下来等待确认,这样可以显著提高数据传输的效率。
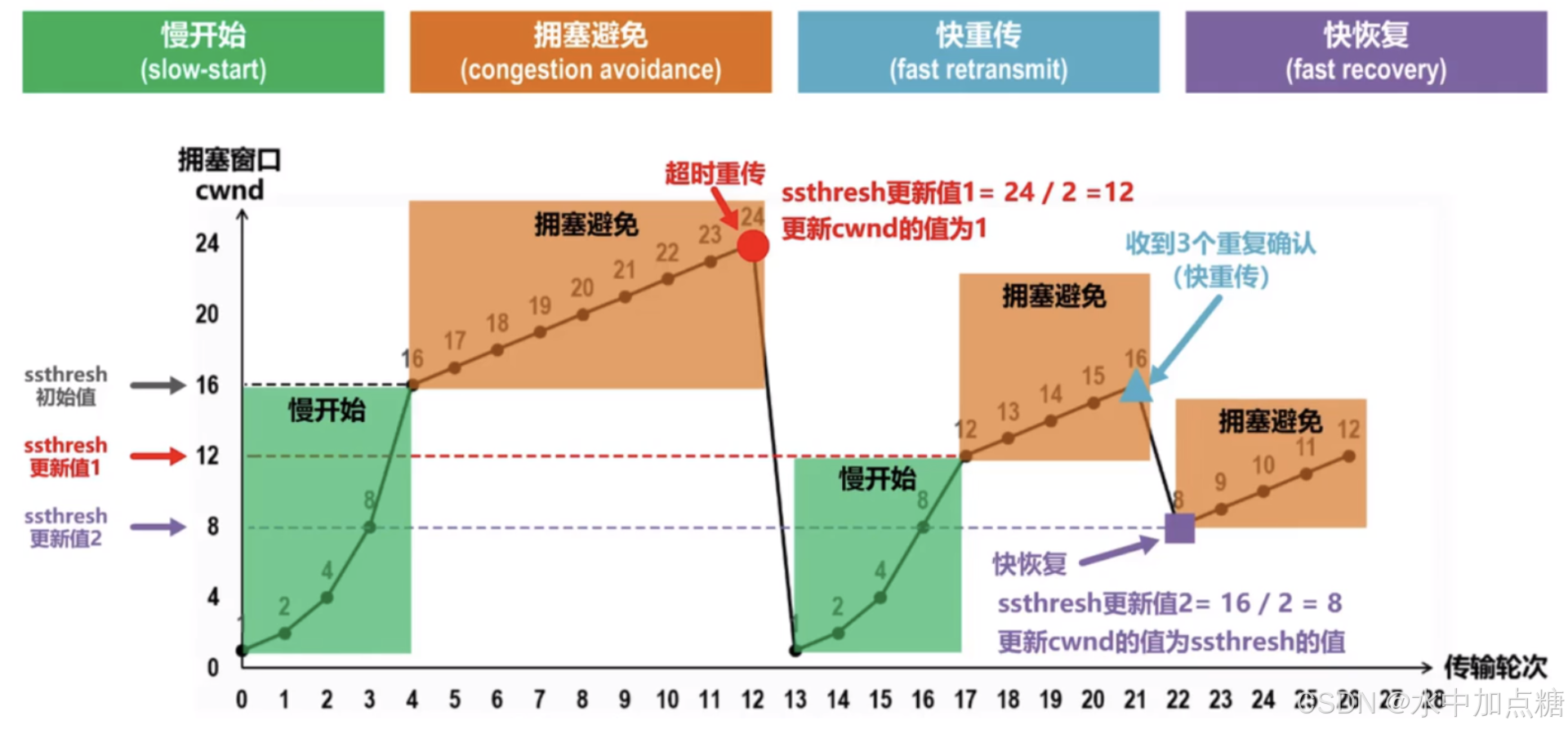
拥塞控制机制是TCP协议中防止网络拥塞的重要手段。当网络中的数据传输量超过网络的处理能力时,就会发生拥塞。拥塞控制机制通过调整发送方的发送速率来减轻网络的拥塞状况。
在tcp拥塞控制的机制中,每个tcp通信的初始和超时重传时都会经历慢开始(Slow Start) 的原因,在此阶段下每次tcp会话只能发送较小的数据包,这会导致请求资源时会经过多个rtt才能将数据请求完,对应的延迟也会随之增加。
常见的拥塞控制算法有:reno、cubic、bbr等,不同的拥塞控制算法在同一个场景下也会有产生出不同的传输效率。
http2.0弱于http1.1请求实例
在回顾了http1.1和http2.0及底层的tcp拥塞控制后,再次思考:http2一定比http1.1快吗?
答案是否定的。
因为能影响两个点的数据通信因素有很多,http1.1和http2.0都依赖于tcp,而http1.1时浏览器会同时开辟了多个tcp连接进行通信,http2.0仅开辟一个tcp连接,如果某一个tcp通信的速率跟不上(时延较大),http2.0的传输效率也是跟不上http1.1的。

这就好比是:同样排队过收费站,一般来讲一个ETC通道比一个人工通道更快,但遇到堵车排队的情况,单ETC的快速通道则不一定就会比多个人工通道快了。
http1.1和http2.0也是类似情况,在遇到tcp传输过程中网络丢包时tcp拥塞控制会触发慢开始,以让TCP滑动窗口每次只能发送一个较小值的数据包,以使得具有多路复用的http2.0使不上劲。
tc模拟链路丢包
这里以上面的请求示例,请求一个有150张5K的图片的网页,客户端和服务端网络链路丢包率为20%的情况下,测试下http请求的耗时。
链路时延和丢包率仍使用tc工具模拟丢包,命令如下:
# ens33为服务端通信的网卡名
sudo tc qdisc del dev ens33 root
tc qdisc show dev ens33
sudo tc qdisc add dev ens33 root handle 1: htb default 12
sudo tc class add dev ens33 parent 1:1 classid 1:12 htb rate 1000mbit ceil 1000mbit
# 模拟延时为50ms,丢包率为20%
sudo tc qdisc add dev ens33 parent 1:12 handle 10: netem delay 50ms loss 20%
sudo tc qdisc show dev ens33
sudo tc class show dev ens33
发个icmp验证一下配置是否成功:
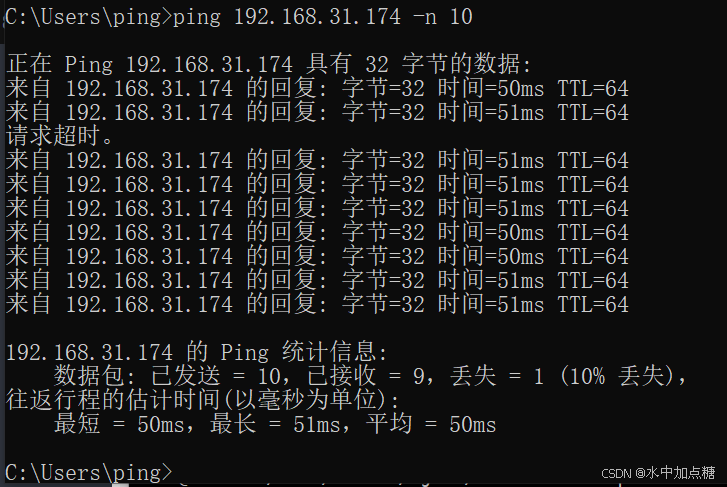
http1.1时
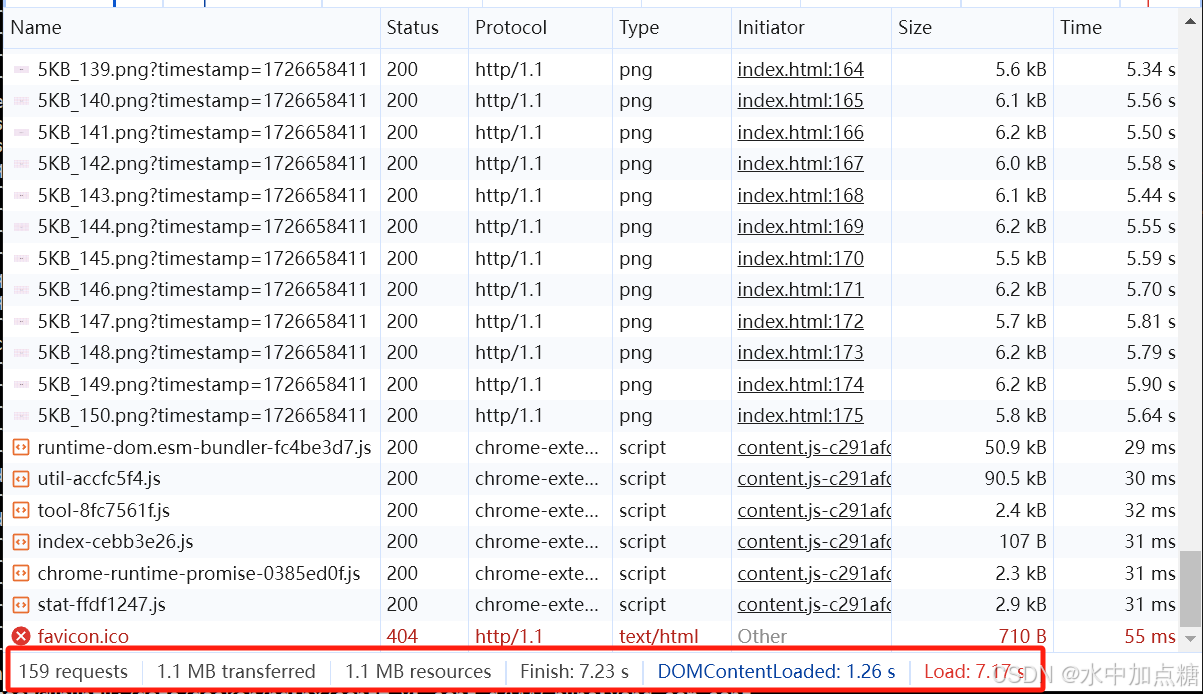
耗时:7.23s
http2时
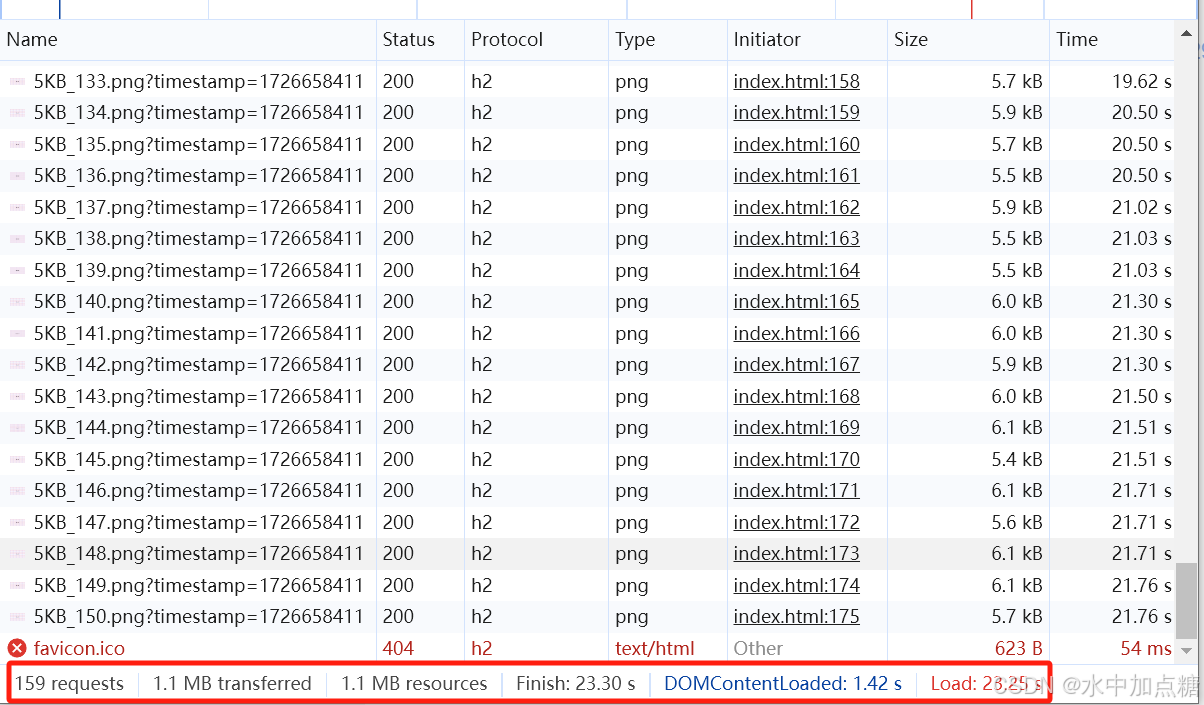
耗时:23.3s
时差:23/7=3.28。在链路丢包率为20%的情况下,http1.1的请求响应时间比http2的快了3倍。
下图的动画展示http2.0遇到丢包时的处理机制:

在http2时,由于一个请求会被拆分为多个小frame发送,一旦某个tcp的包丢失,会触发tcp的重传从而引起未完成的整个stream包重传。
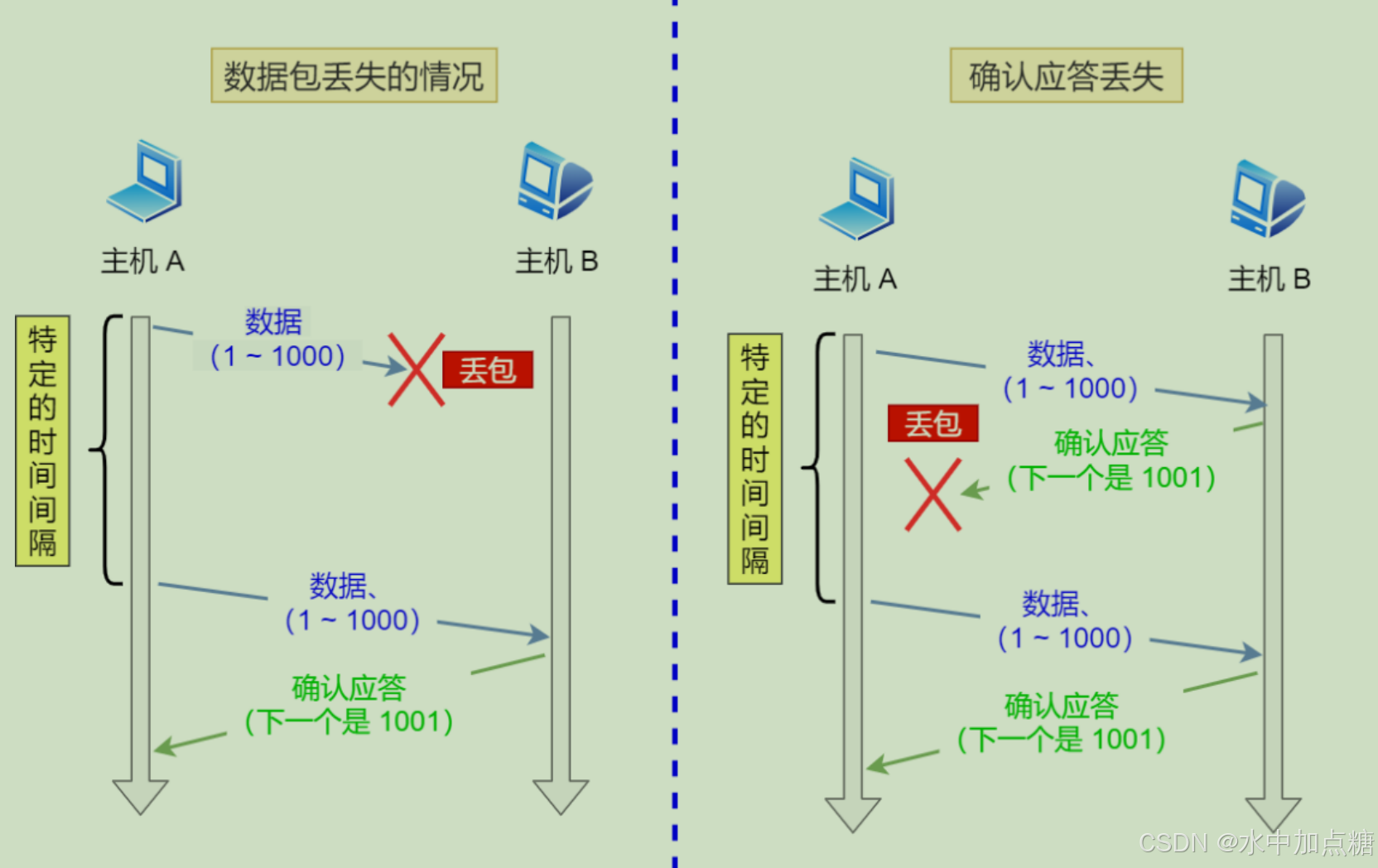
而http1.1时,由于浏览会开辟多个tcp连接,即便某个tcp的包发生了丢包,它的重传不会影响其他的http请求。
总结
目前使用较多的http1.1和http2均基于tcp通信,如要分析从性能角度对比哪个更快,则需要看具体的网络情况。
如在本文的示例中,当网络状态良好时http2的性能一般是要优于http1.1,而在链路丢包率较高的情况下http1.1的性能又要比http2更好。
所以,尽管http2是http1.1的升级版本,但它的性能并不一定就比http1.1更优,所需传输的资源类型、资源大小、网络带宽、延时、tcp拥塞控制算法类型等各种情况都需要考虑。


















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











