









基于统计思想的异常检测是一类比较传统且直观的方法,其基本假设为:
正常数据发生在随机模型的高概率区域,而异常发生在随机模型的低概率区域。
思想核心为找出不符合假定分布的数据点,分为参数方法和非参数方法两类。两类技术本质上都是在拟合统计模型,参数方法假定分布密度函数f(x)的具体形式已知(如正态分布),非参数方法假设分布函数未知并利用其他手段(如直方图)描述数据分布。通常,非参数方法对数据做较少假定,因而在更多情况下都可以使用。
1. 参数方法 Parametric method
1.1 假设正常数据服从正态分布
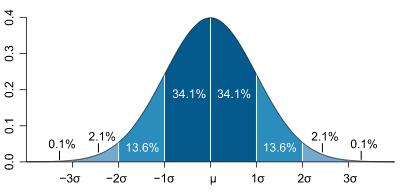
1.1.1 直觉与经验——3 σ \sigma σ原则与箱线图
假设一组样本服从正态分布,那么其绝大多数的样本应该分布在距离均值
μ
\mu
μ三倍标准差
σ
\sigma
σ的范围之间,即
[
μ
−
3
σ
,
μ
+
3
σ
]
[\mu-3\sigma,\mu+3\sigma]
[μ−3σ,μ+3σ],处于此范围之外的数据我们即可划分为异常值。关于分布中
μ
\mu
μ和
σ
\sigma
σ的参数估计,可以使用样本均值和样本标准差。
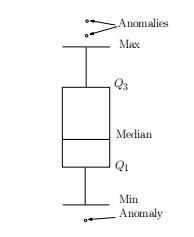
箱线图Box Plot就是基于此原理的一种可视化异常的方式,其优势在于能够直观看到每个变量下的异常值。
1.1.2 量化差异——假设检验
如果说3
σ
\sigma
σ原则与箱线图是利用人类主观经验排查异常,那么假设检验可以帮助我们量化差异的可信度。本文介绍其中一种假设检验方法:Grubbs检验法

本图来自网络,侵删
Grubbs检验(Grubbs’ Test),也称为最大归一化残差检测,常被用来检验服从正态分布的单变量数据集中的单个异常值。Grubbs每次至多检测到一个异常值,即最大值或最小值,所以也可用来检验最大值、最小值偏离均值的程度是否异常。
若有多个离群值,可以循环使用Grubbs检验,但因为每次删除一个异常值后数据分布都在变化,一直循环极有可能将正常值剔除掉,所以需要谨慎设置停止条件。首先接受原假设时检验停止,其次应设置异常点个数到达某个限制时停止。
假设:
H 0 : 数 据 集 中 没 有 异 常 值 H 1 : 数 据 集 中 只 有 一 个 异 常 值 H_0: 数据集中没有异常值\\ H_1: 数据集中只有一个异常值 H0:数据集中没有异常值H1:数据集中只有一个异常值
设样本为 ( x 1 , x 2 , x 3 , … , x n ) (x_1,x_2,x_3,…,x_n) (x1,x2,x3,…,xn),检验步骤如下
(1)假设样本服从正态分布,计算样本均值
X
X
X及标准差
σ
\sigma
σ。
(2)将
x
i
x_i
xi按大小顺序排列成顺序统计量
x
(
i
)
x^{(i)}
x(i),即:
m
i
n
=
x
(
1
)
<
…
<
x
(
n
)
=
m
a
x
min=x^{(1)}<…<x^{(n)}=max
min=x(1)<…<x(n)=max
(3)计算统计量
g
(
1
)
=
(
X
−
x
(
1
)
)
/
σ
g
(
n
)
=
(
x
(
n
)
−
X
)
/
σ
g^{(1)}=(X-x^{(1)})/σ \\ g^{(n)}=(x^{(n)}-X)/σ
g(1)=(X−x(1))/σg(n)=(x(n)−X)/σ
(4)根据双边t检验算出如下临界值,
t
α
/
(
2
N
)
,
N
−
2
2
t^2_{α/(2N),N-2}
tα/(2N),N−22表示具有(N-2)自由度的t分布的临界值和
α
/
(
2
N
)
α/(2N)
α/(2N)显着性水平。当
g
(
1
)
g^{(1)}
g(1)和
g
(
n
)
g^{(n)}
g(n)大于右侧值时,拒绝原假设H0,异常值存在,应剔除。若为单边检验,将α/(2N)替换为α/N。
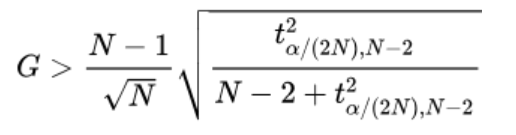
1.2 基于回归模型的方法
多用于时间序列模型,未来会单独讲解。
2. 非参数方法 Nonparametric method
2.1 使用直方图检测异常点
直方图是一种频繁使用的非参数统计模型,可以用来检测异常点。该过程包括如下两步:
步骤1:构造直方图。使用输入数据(训练数据)构造一个直方图。该直方图可以是一元的,或者多元的(如果输入数据是多维的)。
尽管非参数方法并不假定任何先验统计模型,但是通常确实要求用户提供参数,以便由数据学习。例如,用户必须指定直方图的类型(等宽的或等深的)和其他参数(直方图中的箱数或每个箱的大小等)。与参数方法不同,这些参数并不指定数据分布的类型。
步骤2:检测异常点。为了确定一个对象是否是异常点,可以对照直方图检查它。在最简单的方法中,如果该对象落入直方图的一个箱中,则该对象被看作正常的,否则被认为是异常点。
对于更复杂的方法,可以使用直方图赋予每个对象一个异常点得分。例如令对象的异常点得分为该对象落入的箱的容积的倒数。
使用直方图作为异常点检测的非参数模型的一个缺点是,很难选择一个合适的箱尺寸。一方面,如果箱尺寸太小,则许多正常对象都会落入空的或稀疏的箱中,因而被误识别为异常点。另一方面,如果箱尺寸太大,则异常点对象可能渗入某些频繁的箱中,因而“假扮”成正常的。
2.2 HBOS
HBOS全名为:Histogram-based Outlier Score。它是一种单变量方法的组合,不能对特征之间的依赖关系进行建模,但是计算速度较快,对大数据集友好。其基本假设是数据集的每个维度相互独立。然后对每个维度进行区间(bin)划分,区间的密度越高,异常评分越低。
2.2.1 HBOS算法流程
- 为每个数据维度做出数据直方图。对分类数据统计每个值的频数并计算相对频率。对数值数据根据分布的不同采用以下两种方法:
- 静态宽度直方图(等宽分箱):标准的直方图构建方法,在值范围内使用k个等宽箱。样本落入每个桶的频率(相对数量)作为密度(箱子高度)的估计。时间复杂度:O(n)
- 动态宽度直方图(等频分箱):首先对所有值进行排序,然后固定数量的N/k个连续值装进一个箱里,其中N是总实例数,k是箱个数;直方图中的箱面积表示实例数。因为箱的宽度是由箱中第一个值和最后一个值决定的,所有箱的面积都一样,因此每一个箱的高度都是可计算的。这意味着跨度大的箱的高度低,即密度小,只有一种情况例外,超过k个数相等,此时允许在同一个箱里超过N/k值。时间复杂度:O(nlogn)
- 对每个维度都计算了一个独立的直方图,其中每个箱子的高度表示密度的估计。然后为了使得最大高度为1(确保了每个特征与异常值得分的权重相等),对直方图进行归一化处理。最后,每一个实例的HBOS值由以下公式计算:
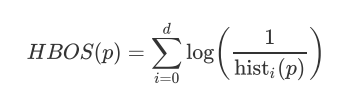
2.2.2 HBOS的优缺点
HBOS在全局异常检测问题上表现良好,但不能检测局部异常值。但是HBOS比标准算法快得多,尤其是在大数据集上。















 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









