







首先需要明确的一点是你写的汇编代码和最终编译的汇编代码是不一样的。所以当你学完了Go汇编入门,然后想从go tool compile -S -N -l xxx.go开始实践时,往往会发现它和你想象的不一样。比如函数帧会多出8个字节,局部变量偏移也不对,这是因为编译器输出的汇编代码会自动保存BP寄存器,并且加入了维护真SP寄存器的代码,而这些编译器会自动帮你完成,所以编写汇编代码是不用处理这些的。另外你会发现编译器输出的汇编代码不会使用FP寄存器,而且通过伪SP寄存器访问局部变量也都是正偏移。总的来说,你写的汇编代码更贴近Go代码,也更简单;而编译器输出的汇编代码更贴近汇编,更能反应底层真实的情况,也更复杂。
认识寄存器
这里主要是认识一下Go汇编引入的4个伪寄存器,它们在不同的平台有着一致的表现,也是我们编写Go汇编代码需要经常用到的寄存器。
PC: Program Counter,程序计数器SB: Static Base Pointer,静态基址指针FP: Frame Pointer,帧指针SP: Stack Pointer,栈指针
PC寄存是对IP寄存器的直接抽象,它两其实是一个东西,指示当前执行指令的地址。
SB寄存器是访问指令和数据的基址,用来定义函数和全局变量,以及调用函数。你在汇编中写的变量和函数名就是基于它的一个偏移量。比如GLOBL ·Id(SB),NOPTR,$8或TEXT ·main(SB),NOSPIT,$0-0,不管是符号Id还是符号main都只是一个偏移量,要访问它们对应的内存,就是基于SB偏移来访问。
变量是对内存的抽象,也是过程式编程最重要的概念之一(函数式编程没有变量的概念)。在学习编程中,我们总是很难理解一片内存是如何与一个变量名产生关联的。这需要从变量的访问方式说起,CPU通过地址来访问内存,而地址是通过基址加偏移量计算出来的。那么接下来的问题就是变量名又是如何与偏移量关联的,变量名只是一个符号,经过编译之后变量名就是一个数字。汇编中也没有变量的概念,只有偏移量和基址。
FP寄存器是方便用来访问函数自己的参数和返回值的,之所以说“方便”是因为不用它也能访问到自己的参数和返回值。我们知道Go是通过栈来传递返回值的,所以函数自己的返回值也是通过FP寄存器加一个偏移量来访问的。
SP寄存器,确切的说是伪SP寄存器是用来访问函数的局部变量的。FP寄存器通过正偏移来访问自己的局部变量,伪SP寄存器通过负偏移来访问自己的局部变量。
与伪SP寄存器对应的还有一个真SP寄存器,它指向的是调用栈的栈顶。由于x86架构栈是从高地址向低地址增长的,因此真SP寄存器指向的是地址更小的内存。我们知道,Go的函数调用是Caller-Save模式,也就是由调用者准备被调函数的参数和返回值。真SP寄存器的作用就是访问被调函数的参数和返回值。
伪寄存器访问语法
普通寄存器的使用语法是±偏移量(寄存器名),但是伪寄存器必须在偏移量前加上一个符号:符号±偏移量(寄存器名),至于这个符号是什么,是否重复并不重要,重要的是偏移量,只是出于便于阅读的目的,我们一般将符号写成与变量相同的名字。所以伪寄存器前面的符号仅仅是编译器为了区分真伪寄存器的语法要求,并没有实际含义。
为什么伪寄存器的符号并不重要呢?因为伪寄存器并不真实存在,它们会在编译后替换成真实存在的寄存器,而那些真实存在的寄存器只需要偏移量。
如果偏移量是0,还可以省略偏移量,访问普通寄存器变为(寄存器名),伪寄存器变为符号(寄存器名)。
Go汇编中有两个SP寄存器,它正是通过语法的不同加以区分的。真SP寄存的语法是±偏移量(SP),而使用伪SP寄存器的语法是符号±偏移量(SP)。它们的唯一区别是在偏移量前面有没有符号。
汇编指令
汇编没有类型的概念,汇编指令直面内存,有内存宽带的区别。一个汇编指令操作多少字节的内存由后缀可以区别,而这些后缀基本都是通用的。
| 后缀 | 含义 | 内存宽度 |
|---|---|---|
| B | byte | 1字节 |
| W | word | 2字节 |
| L | long word | 4字节 |
| Q | quadword | 8字节 |
带后缀的指令有以下几种:
数据移动类指令:MOV、LEA
MOV指令的两个操作数中只能有一个是内存,也就是说你可以在内存和寄存器之间移动数据,但是不能直接在两片内存之间移数据,想想这是为什么呢?欢迎留言。
LEA(Load Effect Address)指令相当于Go的&,它和MOV指令非常类似。不同的是MOV指令将第一个操作数解释伪地址,移动的是地址对应内存中的内容。而LEA指令将第一个操作数解释为值,也就是将内存有效地址移动到第二个操作数指向的内存。
数据运算类指令:ADD、SUB、MUL、DIV、INC、DEC
INC和DEC都只有一个操作数,类似于++和--这样的操作,分别将操作数加一和减一。
逻辑运算类指令:AND、OR、NOT
栈操作类指令:PUSH、POP
数据比较类指令:CMP
CMP指令在比较完两个操作数之后会设置flag寄存器,在接下来要介绍的跳转指令中,有一部分条件跳转指令,它们的条件就是flag寄存器。
跳转指令也有三类,它们和代表数据宽度的后缀已经没有关系了。
无条件跳转指令:JMP
条件跳转指令:
| 指令 | 全称 | 含义 |
|---|---|---|
| JLT | Jump Less | 小于0跳转 |
| JLE | Jump Less Equal | 小于等于0跳转 |
| JEQ | Jump Equal | 等于0跳转 |
| JNE | Jump Not Equal | 不等于0跳转 |
| JGT | Jump Greater | 大于0跳转 |
| JGE | Jump Greater Equal | 大于等于0跳转 |
| JMP | Jump | 无条件跳转 |
函数相关指令:CALL、RET
CALL用于函数调用,原理就是设置IP寄存器并跳转。RET用于函数返回。
语法
汇编定义函数的语法如下:
TEXT ·函数名(SB)[,标识],$栈帧大小[-参数和返回值大小]
指令
RET
方括号中的表示可选项,举个例子:TEXT ·max(SB),NOSPLIT,$8。
这里函数名,或者称为符号的一些规则和标识可以参考Go汇编之全局变量这篇文章,标识可以通过|操作支持多个。函数相关的标识符有以下几种,同样定义在textflag.h文件中。
NOPROF:不要分析此函数,已弃用NOSPLIT:禁止栈分裂WRAPPER:此函数为包装函数,不应算作禁用recover计数NEEDCTXT:此函数是一个闭包,需要传入上下文寄存器NOFRAME:不插入现场保护/恢复代码,不管是不是叶子函数,仅对申明栈帧大小为0的函数有效TOPFRAME:此函数在调用栈的顶部,Traceback应该在此处停止
在64位系统上,栈帧大小必须8字节对齐。此外需要留意最后的空行,它也是必须的。
函数调用
调用函数的关键问题之一是传递参数和返回值,这是通过真SP寄存器完成的。我们通过一个例子来看如何给函数传递参数,如何接收返回值。
第一步:新建main.go文件,输入以下代码
package main
func main()
func test(a, b int) (c, d int) {
println("a:", a)
println("a:", b)
return 11, 22
}
func printInt(i int) {
println(i)
}
第二步:新建main.s文件,输入以下代码
TEXT ·main(SB), $40
MOVQ $1, (SP) //传递参数a
MOVQ $2, 8(SP) //传递参数b
CALL ·test(SB) //调用test
MOVQ 16(SP), AX //返回值c
MOVQ AX, (SP) //参数i
CALL ·printInt(SB) //调用printInt
MOVQ 24(SP), AX //返回值d
MOVQ AX, (SP) //参数i
CALL ·printInt(SB) //调用printInt
RET
不出意外,运行上面的程序,我们能看下下面的输出。
a: 1
a: 2
11
22
传递参数实际上就是把值移动到参数所在栈内存,真SP寄存指向的是当前函数栈的栈顶,也是被调函数的第一个参数,通过一个正向偏移,我们就能访问被调函数的参数和返回值了。我们说过,Go的函数调用时Call-Save模式,所以被调函数的参数和返回值是在调用者的栈空间里的。接下来我们看看几个问题。
问题一:为什么参数和返回值是按书写顺序逆序排列的
X86架构下栈是由高地址向低地址增长,真SP寄存器指向的是地址更低的内存。从上例中我们可以看到被调函数的参数和返回值是按照书写顺序逆序入栈的。为什么是逆序,因为当我们通过伪FP寄存器访问自己的参数和返回值时,伪FP指向的就是就是第一个参数,通过正向偏移依次是第二个参数,第三个参数…第一个返回值,第二个返回值…就是这么神奇,它居然又正过来了。其实被调函数的伪FP寄存器和调用者的真SP寄存器指向的是同一个地方,逆序排列,正序访问。
其实在上例main函数的实现中,有个不规范的地方。我们在打印test函数返回值时,直接使用了16(SP)作为printInt函数的参数。规范的做法应该是先将test函数的返回值移动到局部变量,然后将局部变量作为参数调用printInt函数。由于还没讲到局部变量,这里就没用到局部变量保存返回值。这里之所以可以这样做是因为这个例子比较特殊,因为test函数的参数所占空间比printInt函数参数所占空间大,因此在准备printInt函数的参数时并不会覆盖掉test函数的返回值空间,因为参数和返回值是逆序排列的,返回值在更高的内存地址。我也不敢说这也是逆序的原因,但无疑逆序排列时有这个好处的。此外,从直觉上来讲,函数调用最关心的就是返回值,逆序排列可以让返回值离自己近点儿[狗头]。
还有一点需要注意的是函数给被调函数准备的参数和返回值空间是所有被调函数共用的,因此如果一个函数调用了多个函数,后者会覆盖前者。
问题二:为什么栈帧大小是40字节
函数栈帧是包含被调函数的参数和返回值的,在main函数里我们调用了test和printInt两个函数。test函数的参数和返回值共32字节,printInt函数参数和返回值共8个字节。但不是32+8=40,而是取最大的那个,也就是32字节。main函数没有局部变量,多出来的8字节是用来保存BP寄存器的。虽然最终的结果也是32+8=40,但是这个8的含义是不一样的。关于栈帧的问题,后面还会详细讨论。
问题三:为什么要写printInt函数,而不用runtime.printint函数
这个问题得好好说道说道,很多Go汇编文章中会说println函数编译后会被替换成runtime.printxxx系列函数和runtime.printnl函数。这是没错的,而且通过编译输出汇编代码也的确能看到确实如此。但是错就错在某些文章编写的汇编示例代码中也使用了runtime.printxxx函数,实际上这样的代码是编译不过了。runtime.print系列函数是内部ABI,我们写汇编代码的时候根本调用不了这样的函数。因此为了能在汇编代码中打印一点儿东西,我们需要先编写一些打印函数。
既然说到这里,那就再提一提内建函数print和println。这两个函数都在src\builtin\builtin.go中声明,注意只是声明,它们会在编译期被替换成runtime.printxxx调用。这个文件中还声明了很多东西,有兴趣的可以看一看。
参数和返回值
访问函数自己的参数和返回值用到的是FP寄存器。下面通过具体的例子来看如何访问自己的参数和返回值。
第一步:创建main.go文件,并输入以下代码。
package main
func test(a, b, c int) (d, e int)
func main() {
d, e := test(1, 2, 3)
println("d:", d)
println("e:", e)
}
func printInt(i int) {
println(i)
}
第二步:创建main.s文件,并输入以下代码。
#include "textflag.h"
TEXT ·test(SB), NOSPLIT, $16-40
//打印第一个参数
MOVQ a(FP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
//打印第二个参数
MOVQ b+8(FP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
//打印第三个参数
MOVQ c+16(FP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
//设置返回值
MOVQ $4, d+24(FP)
MOVQ $5, d+32(FP)
//函数返回
RET
运行上面的代码,不出意外应该能看到以下输出,不管什么原理,先把程序跑起来才是最开心的。
1
2
3
d: 4
e: 5
有了前面的前置知识,语法没什么好说的,我们来看一些比较细节的问题。
首先要说明的是,在使用FP寄存器时,我们用了变量名作为符号,这样做只是了为了方便阅读,你用b,p,m.f也是完全没问题的,即使重复也没问题。但是为了养成良好的编程习惯,还是尽量用变量名作为符号,后面还有不知道变量名的情况,那时候再用b,p,m,f。
问题一:为什么函数帧大小是16
因为test函数没有局部变量,它只调用了printInt函数,所需参数返回值共8字节,加上留给BP寄存器的8字节,共16字节。
问题二:$16-40最后为什么是40
根据语法我们知道40是函数test的参数和返回值的大小,它是可以省略的,因为Go编译器可以通过函数签名推导出参数和返回值的大小。为什么是40很明显,因为参数加返回值共5个int,5×8=40.至于这个大小要怎么算,可以参考go结构体内存对齐这篇文章,对齐规则都是一样的。计算参数和返回值总大小和把参数和返回值都放到一个结构体里,然后计算结构体大小是等价的。
问题三:为什么通过FP寄存器访问参数和返回值是正向偏移
伪FP寄存器其实指向的是当前函数栈的栈底,紧挨着调用者的栈顶。函数的参数和返回值在调用者的栈顶,调用者的栈空间在内存地址更大的地方,因此FP寄存器通过正向偏移就能去到调用者的栈空间访问自己的参数和返回值了。结合上例其实可以发现当前函数的FP寄存器和调用者的SP寄存器指向的是同一个地方。真SP寄存器通过正向偏移访问被调函数的参数和返回值,被调函数当然也通过正向偏移访问自己的参数和返回值。
局部变量
访问函数局部变量用到的是伪SP寄存器。我们还是通过例子来看如何访问局部变量。
第一步:新建main.go文件,输入以下代码。
package main
func test()
func main() {
test()
}
第二部:新建main.s文件,输入以下代码。
#include "textflag.h"
TEXT ·test(SB), NOSPLIT, $40
MOVQ $1, a(SP)
MOVQ $2, a-8(SP)
MOVQ $3, a-16(SP)
MOVQ $4, a-24(SP)
RET
这段代码不必运行,因为没什么效果。直接来讨论其中的一些细节。
问题一:不知道局部变量名怎么办
当使用汇编实现函数时,会发现一个问题,那就是不知道局部变量的名字。其实也不用知道,写什么都可以。上例中我们甚至全部都用a也没关系,还是那句话,重要的是偏移量。因为这些伪寄存器并不真实存在,经过编译后它们会被替换成真实存在的寄存器,而访问真实寄存器只需偏移量就够了。
问题二:为什么伪SP寄存器访问局部变量是负的偏移
这里也不是解释这个问题的最佳时机,后面再详细讨论。
问题三:伪SP寄存器有没有正向偏移的情况
答案是有的,当第一个局部变量小于8字节时,就有可能是第一个局部变量是基于伪SP寄存器的正向偏移。原因后面再解释。
问题三:栈帧大小为什么是40
这里注明的栈帧大小是40字节,而我们初始化的局部变量只有32字节。多出来的8字节并不是局部变量,而是留给BP寄存器的。另外局部变量也有对齐要求,规则同go结构体内存对齐一样,同样等价于将所有局部变量放到一个结构体中。
函数帧
兜兜转转,坎坎坷坷,终于来到了最重要的地方,希望你还能记得前面的那些问题,在这里我们会一一解开那些疑惑。
问题一:什么是栈帧
栈帧,也有叫函数帧的,它们只是一个东西的两种叫法。为了少打字,我就统一称为栈帧了。栈帧是一个函数运行时所需的栈空间。函数=指令+栈帧。指令只是函数的一部分,指令加上栈帧才是一个完整的函数。
问题二:栈帧包括哪些内容
栈帧包括函数的局部变量,被调函数的参数和返回值,被保存的现场。
问题三:栈帧大小的计算
栈帧大小=局部变量+被调函数参数和返回值(最大那个)+8
最后那个8字节就是用来保存BP寄存器的。另外栈帧大小要求8字节对齐,对齐规则参考go结构体内存对齐。完全可以将它们等价为一个结构体来计算。当一个函数没有局部变量也不调用其他函数时,它的栈帧大小可以是0,也就是不用保存和恢复BP寄存器。一旦发生函数调用,就需要保存和恢复BP寄存器,栈帧至少是8字节。
问题四:栈帧的内存布局
关于栈帧的内存布局,我们以f0调用f1,f1调用f2为例来说明。下图展示了f0、f1、f2的栈帧内存布局,主要关注f1的栈帧。
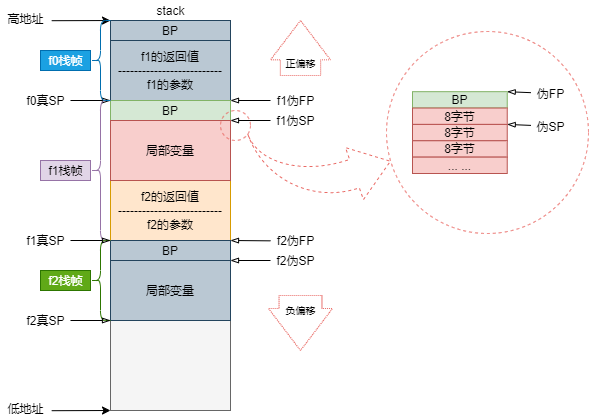
一图胜千言,是不是安排得明明白白的。
函数的栈帧包括被调函数的参数和返回值,但是不包括自己的参数和返回值。伪FP寄存器和真SP寄存器之间的就是当前函数的栈帧。为什么伪FP寄存器和真SP寄存是正向偏移,而伪SP寄存器是负向偏移,请看图说话。
这里唯一需要留意的一点是伪SP寄存器的指向问题,它和伪FP寄存器并不是指向同一个地方。伪SP寄存器在保存BP寄存器的内存后又偏移了8个字节,也就是和伪FP寄存器之间差了16字节。为什么会这样设计呢?试想一下,如果没有那8字节的偏移,那么访问第一个局部变量就必须使用一个负的偏移,而不能使用0偏移。但是伪FP寄存器访问第一个参数,以及真SP寄存器访问第一个参数都是0偏移。为了访问第一个变量是0偏移,于是伪SP寄存器多偏移了8字节。此时我们再来看伪SP寄存器正向偏移的情况,如果函数的前两个局部变量都是int32类型,那么第一个局部变量的偏移就是a+4(SP),而a(SP)则变成了第二个局部变量。
问题五:伪FP、伪SP、真SP寄存器的位置关系
关于这3个寄存器的位置关系,上图以及展示的很清楚了,后面也会通过示例来证明。真正指向同一个地方的只有调用者的真SP寄存器和被调函数的伪FP寄存器,但是千万不要犯傻通过真SP寄存器来访问被调函数的参数和返回值,因为函数调用一旦发生,真SP寄存器指向的位置也就改变了。
示例一:打印伪FP、伪SP、真SP寄存器的位置关系
第一步:新建main.go文件,输入以下代码
package main
func main() {
test(1)
}
func test(int)
func printInt(i int) {
println(i)
}
第二步:新建main.s文件,输入以下内容
#include "textflag.h"
TEXT ·test(SB), NOSPLIT, $24-8
LEAQ a+0(FP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
LEAQ a+0(SP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
LEAQ (SP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
RET
第三步:运行代码,观察输出
824633974640
824633974624
824633974600
可以看到,伪FP和伪SP寄存器之间差了16字节,而伪SP和真SP寄存器之间差为栈帧大小。这里面有8字节的空间其实是浪费的,不知道你能否看出其中的端倪。
示例二:通过FP寄存器访问局部变量
第一步:创建main.go文件,输入以下代码
package main
func main()
func printInt(i int) {
println(i)
}
第二步:创建main.s文件,输入以下内容
TEXT ·main(SB), $24
MOVQ $1, a-16(FP) //初始化第一个局部变量
MOVQ $2, a-24(FP) //初始化第二个局部变量
MOVQ $3, a-32(FP) //初始化第三个局部变量
//打印第一个局部变量
MOVQ a(SP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
//打印第二个局部变量
MOVQ a-8(SP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
//打印第三个局部变量
MOVQ a-16(SP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
RET
不出意外,能看到以下输出。
1
2
3
示例三:通过伪SP寄存器访问自己的参数和返回值
第一步:创建main.go文件,输入以下代码
package main
func main() {
a, b := test(1, 2, 3)
println("a:", a)
println("b:", b)
}
func test(int, int, int) (int, int)
func printInt(i int) {
println(i)
}
第二步:创建main.s文件,输入以下内容
TEXT ·test(SB),$8-40
MOVQ a+16(SP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
MOVQ a+24(SP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
MOVQ a+32(SP), AX
MOVQ AX, (SP)
CALL ·printInt(SB)
MOVQ $4, a+40(SP)
MOVQ $4, a+48(SP)
RET
不出意外的话,输出如下。
1
2
3
a: 4
b: 4
输出汇编代码
我并没有在一开始就写如何输出汇编代码,是因为我并不建议通过这种方式去学校Go汇编。你需要先了解一些前置知识,然后去看编译器输出的汇编代码才不会一脸懵逼。而且实际需要写汇编的场景并不多,需要去看编译器输出的汇编代码的场景就更少了。学习Go汇编的目的主要有两个:一是在看Go源代码的时候不至于一到汇编就劝退,二是了解一些底层的东西。正如我在开头说的那样,你看到的汇编和你写的汇编是不同的,记住这一点,学习的过程中才不会有一种这啥玩意儿的感觉。
虽然平时很少会去输出汇编代码,但是作为一个知识点,最后还是来介绍以下输出汇编的三种方式,毕竟都看到这里了,也不差最后这一点了。
方式一:go build -gcflags '-N -l -S' 包或go文件
向-gcflags传递多个参数时,必须用单引号包裹。-N表示禁用优化,-l标识禁用函数内联,-S表示输出汇编代码。函数内联是Go编译器抵消通过栈传递返回值带来性能损耗的重要手段。上面的命令会同时输出可执行文件和汇编代码,并且汇编代码会直接打印到控制台,不能重定向,建议是不用它。另外,这个命令输出的汇编艾玛是编译过程的中间汇编代码,也就是有伪寄存器的汇编代码。
方式二:go tool compile -N -l -S 包或go文件 > output.s
其中参数的函数与方式一相同,并且输出的也是中间汇编代码,有伪寄存器的,方便学习。此外这个命令支持输出重定向,可以将汇编代码输出到一个文件中。
方式三:go tool objdump xxx.o > output.go
这种方式是从.o文件反汇编生成汇编代码,注意不是编译生成的中间汇编,因此这种方式生成的汇编代码是没有伪寄存器的。生成.o文件可以用命令:go tool compile -N -l 包或go文件。
此外这种方式还可以反汇编特定的函数,通过-s指定函数名:go tool objdump -s 函数名 xxx.o > output.s。此处的函数名支持通配,比如print*可以反汇编所有print开头的函数。

















 232
232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









