







1 需求
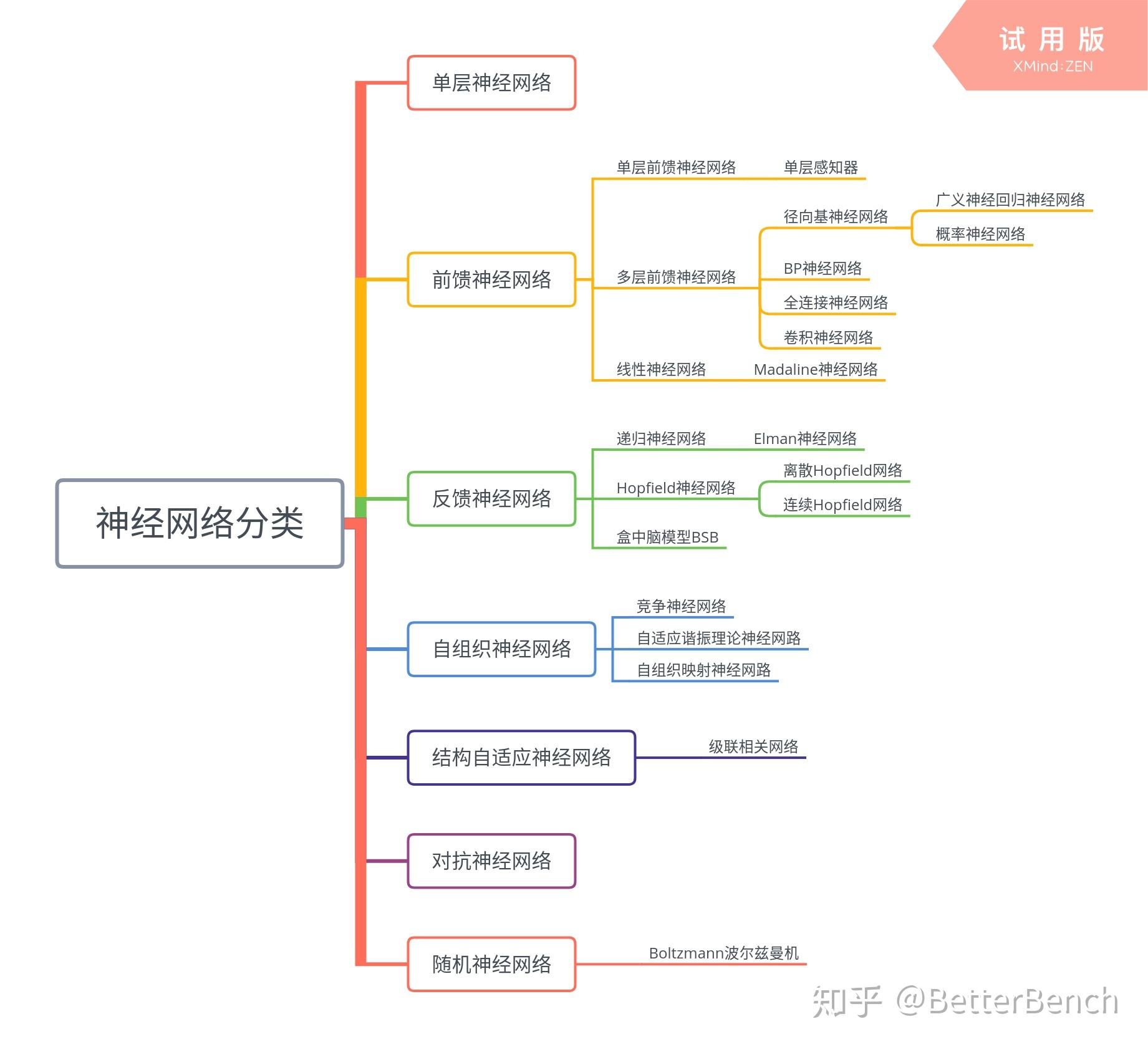
- MP模型
- 单层感知机模型
- MLP模型
- CNN模型:LeNet、Alexnet、VGGNet、GoogleNet(Inception)、ResNet
- RNN模型:RNN、LSTM、GRU
- GAN模型
- 自注意力模型(Transformer)
MP 模型(1943 年):
- 由美国神经生理学家沃伦・麦卡洛克(Warren McCulloch)和数理逻辑学家沃尔特・皮茨(Walter Pitts)提出,是最早的人工神经网络模型之一。
- 它基于神经元的基本结构和功能,模拟了生物神经元的信息处理方式。
单层感知机模型(1957 年):
- 由美国心理学家弗兰克・罗森布拉特(Frank Rosenblatt)提出。
- 是一种简单的线性分类器,能够对线性可分的数据进行分类。
MLP 模型(多层感知机,20 世纪 60 年代):
- 在单层感知机的基础上发展而来,引入了多个隐藏层,增强了模型的表达能力。
- 可以处理非线性问题,但在训练过程中容易出现梯度消失或梯度爆炸等问题。
CNN 模型:
- LeNet(1998 年):由 Yann LeCun 等人提出,是卷积神经网络的经典模型之一,用于手写数字识别等任务。
- Alexnet(2012 年):由 Alex Krizhevsky 等人提出,在 2012 年的 ImageNet 图像识别大赛中取得了巨大成功,推动了深度学习的发展。
- VGGNet(2014 年):由牛津大学的研究团队提出,通过增加网络的深度来提高模型的性能。
- GoogleNet(Inception,2014 年):由 Google 团队提出,采用了 Inception 模块,能够在不增加过多计算量的情况下提高模型的性能。
- ResNet(2015 年):由微软亚洲研究院的何恺明等人提出,引入了残差连接,有效地解决了深层神经网络的训练难题,使得网络可以更深。
RNN 模型:
- RNN(循环神经网络,20 世纪 80 年代):能够处理序列数据,通过循环结构将上一时刻的输出作为下一时刻的输入。
- LSTM(长短期记忆网络,1997 年):由 Hochreiter 和 Schmidhuber 提出,解决了 RNN 长期依赖的问题,能够更好地处理长序列数据。
- GRU(门控循环单元,2014 年):是 LSTM 的一种变体,简化了模型结构,计算效率更高。
GAN 模型(生成对抗网络,2014 年):
- 由 Ian Goodfellow 等人提出,由生成器和判别器组成,通过对抗训练的方式学习数据的分布,能够生成逼真的数据。
自注意力模型(Transformer,2017 年):
- 由 Google 团队提出,基于自注意力机制,在自然语言处理等领域取得了巨大成功,如用于机器翻译的 BERT 模型就是基于 Transformer 架构。
这些模型的发展推动了人工智能领域的不断进步,在图像识别、语音识别、自然语言处理等众多领域都取得了显著的成果。
神经网络模型:
- 全连接神经网络
- 卷积神经网络
- 循环神经网络
- 基于注意力机制的神经网络


https://zhuanlan.zhihu.com/p/268709618
2 接口
3.1 MP模型
深度学习入门,什么是MP神经元模型_哔哩哔哩_bilibili
import numpy as np
# 定义激活函数(这里是简单的阶跃函数)
def step_function(x):
return 1 if x >= 0 else 0
# MP神经元类
class MPNeuronWithWeightsBias:
def __init__(self, weights, bias):
self.weights = weights
self.bias = bias
def predict(self, inputs):
weighted_sum = np.dot(inputs, self.weights) + self.bias
output = step_function(weighted_sum)
return output
# 示例用法
if __na 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









