









关于Cookie和Session位置信息
Safari浏览器缓存的Cookie在MAC上的存储路径
Safari浏览器存储的Cookie位于个人用户下的隐藏的library文件夹下面

打开隐藏文件快捷键
Shift+command+.
快捷查看Cookie文件
直接搜索路径 ~/library/cookies
Chrome浏览器中保存的Cookie在MAC上所在路径
同上直接搜索:
~/library/application support/google/chrome
Session的存储位置查看以及更改
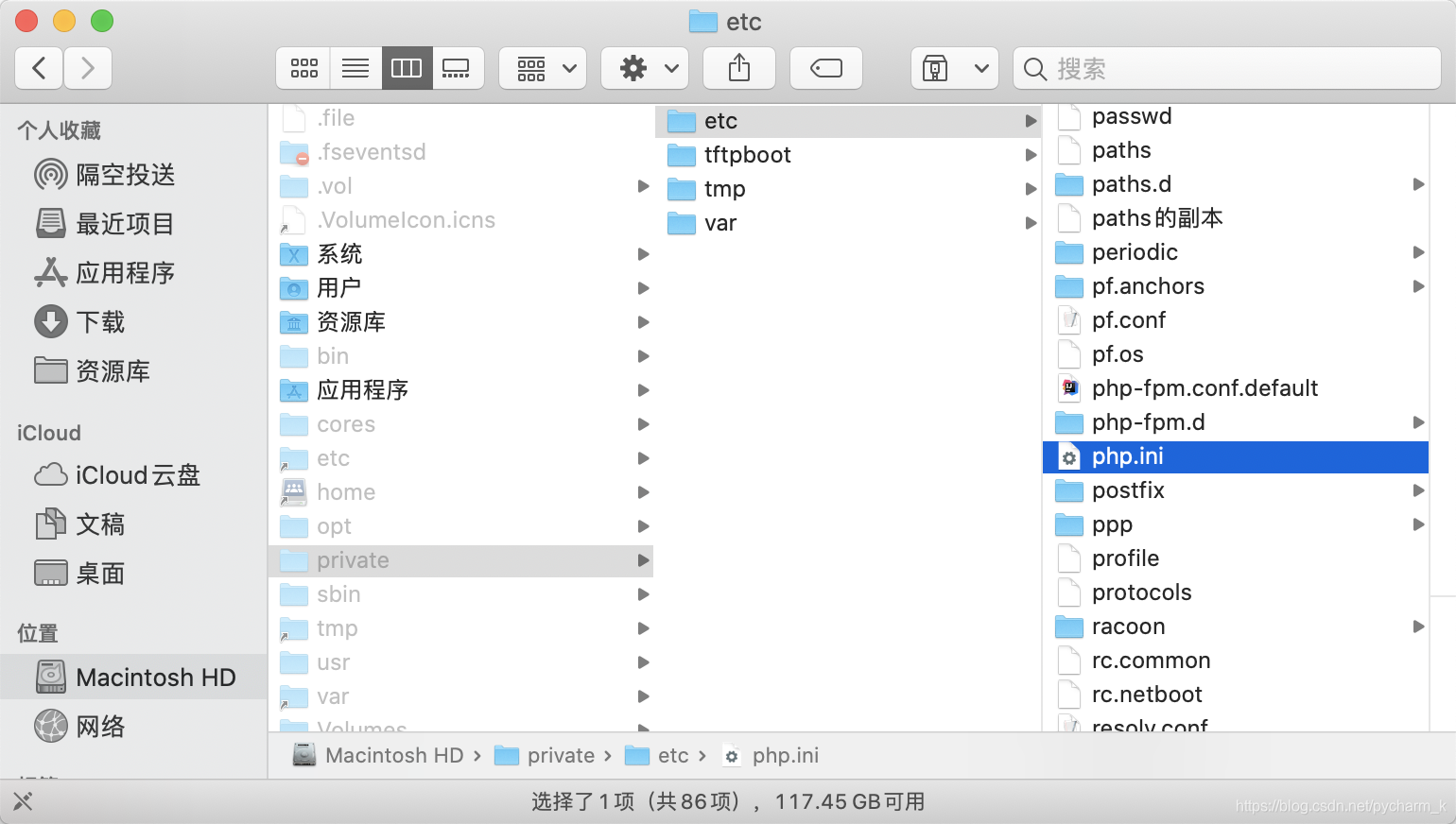
以MAC作为本地回环的服务器,它的Session存储位置可以在php.ini配置文件当中更改。
php.ini配置文件位置
更改php.ini配置文件
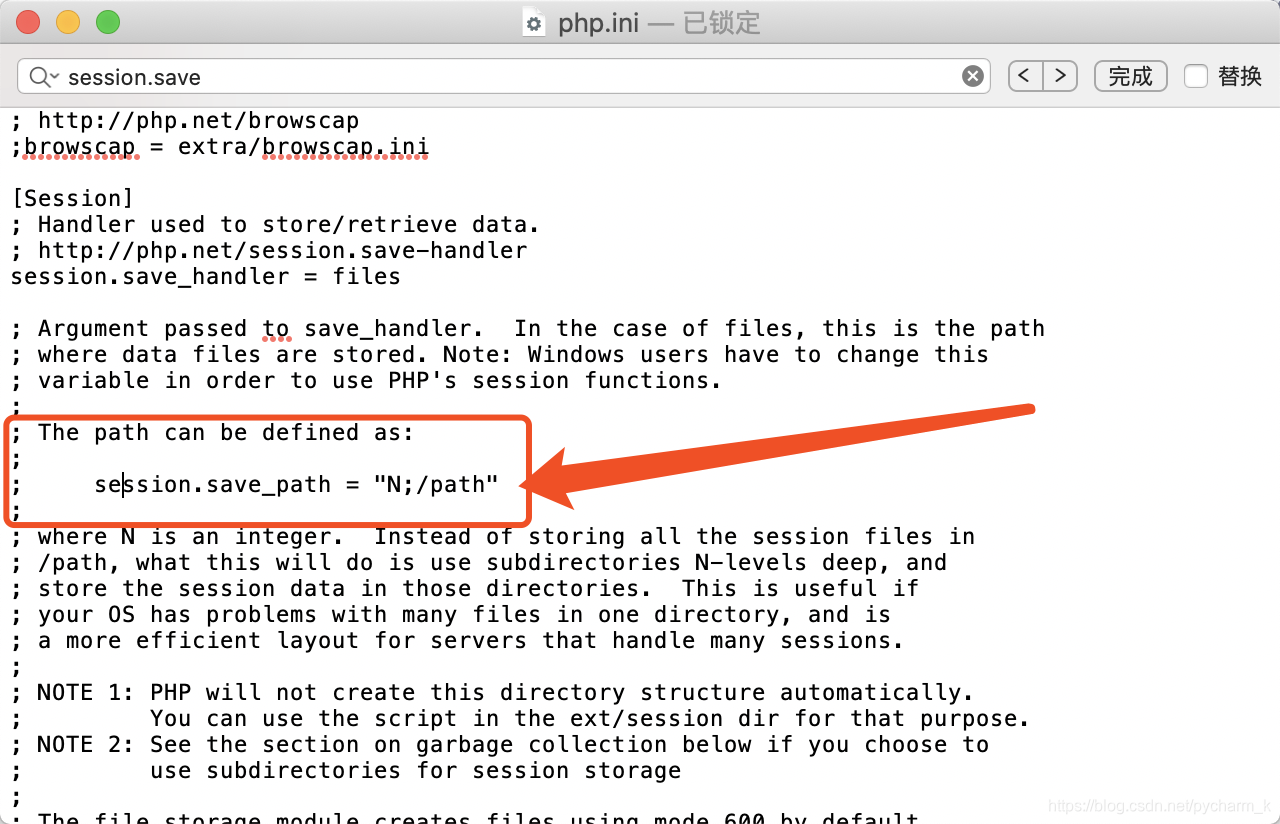
记得去除分号注释后才能够生效,若是不更改配置文件所存储的session将为临时文件,浏览器关闭以后session将自动销毁。
如有错误请评论指出,将及时修改

















 1884
1884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









