






 本文详细解释了Pandas库中Series和DataFrame两种数据结构,重点讲解了如何利用参数axis进行列或行操作,包括求和、删除等,并展示了在Series和DataFrame中axis=0和axis=1的不同效果。
本文详细解释了Pandas库中Series和DataFrame两种数据结构,重点讲解了如何利用参数axis进行列或行操作,包括求和、删除等,并展示了在Series和DataFrame中axis=0和axis=1的不同效果。
pandas库中提供了2种数据结构,Series和DataFrame。参数axis的使用,可以指定是对哪些数据进行处理。
Series
先从Series说起。Series 是一种类似于一维数组的对象,由下面两个部分组成:
1、index:相关数据的索引标签(也可以认为是行标签);
2、 values:一组数据,可以视为一列数据。
我们先创建一个Series:
data = pd.Series([3,5,7,9], index=[0, 1, 2, 3])
print(data)
#输出,数据以列方式显示 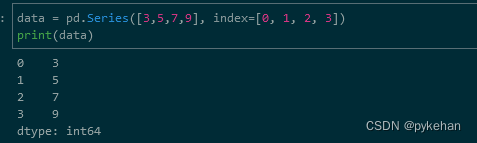
接下来,对data求和。data只有一维数据,按列方式展示,可以认为Series是一组列数据,以下四种方式都可以进行sum操作。
data.sum()
data.sum(axis=0)
data.sum(axis='index')
data.sum(axis='rows')结果是:对Series中的所有数据求和。
如果是用drop删除data中的某一个数据,默认情况下参数还是axis=0。
其中,另一个参数是索引号。
data.drop(0)
data.drop(0, axis=0)
data.drop(0, axis='index')
data.drop(0, axis='rows')结果是:对Series中索引号为0的数据进行drop操作。
结合上面两个操作例子,可以认为,sum()或者drop()以及其他的函数,其作用对象是在Series上。
DataFrame
DataFrame,可以看成是按一定顺序排列的多列Series组成,它将Series的使用场景从一维拓展到多维。DataFrame由下面三个部分组成:
行索引:index
列索引:columns
值:value
DataFrame 既有行索引,也有列索引,就可以由参数axis来指定是对行或列进行某项操作。
对于DataFrame,也应该是以Series为整体做为一个处理对象。
df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
print(df) 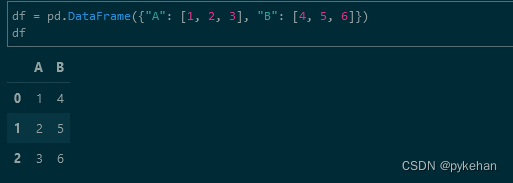
df.sum(axis=0) #与Series类似,可以另有其他三种写法#axis=0,与单独对Series的处理机制结合起来(垂直方向上的处理),应用到DataFrame上,
就是在垂直方向上取第一个Series做处理,再将相同的处理过程应用到其他列Series上。
axis=0时,对Series的处理过程 ,相应的应用到DataFrame中的单列,而其他列照此办理;
axis=1时,对DataFrame中的行Series应用函数,再逐行处理。
总结: 主要是依据Series应用参数axis=0,是对单列数据进行处理,扩展到DataFrame时,参数axis=0也是对列Series进行处理,axis=1时对行Series进行处理。
最后,看看concat分别在Series和DataFrame的作用效果。
# importing the module
import pandas as pd
# creating the Series
series1 = pd.Series([1, 2, 3])
display('series1:', series1)
series2 = pd.Series(['A', 'B', 'C'])
display('series2:', series2)
# concatenating
display('After concatenating:')
display(pd.concat([series1, series2]))

# importing the module
import pandas as pd
# creating the Series
series1 = pd.Series([1, 2, 3])
display('series1:', series1)
series2 = pd.Series(['A', 'B', 'C'])
display('series2:', series2)
# concatenating
display('After concatenating:')
display(pd.concat([series1, series2],
axis = 1))

# importing the module
import pandas as pd
# creating the DataFrames
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
display('df1:', df1)
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7']})
display('df2:', df2)
# concatenating
display('After concatenating:')
display(pd.concat([df1, df2],
keys=['key1', 'key2']))

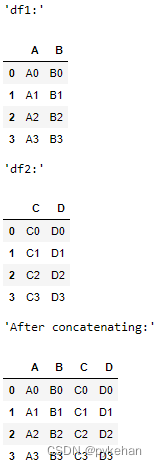
# importing the module
import pandas as pd
# creating the DataFrames
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
display('df1:', df1)
df2 = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
display('df2:', df2)
# concatenating
display('After concatenating:')
display(pd.concat([df1, df2],
axis = 1))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









