






PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance.
Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()
为了做数据分析,在生成一个DataFrame时,以日期作为行索引,股票名称作为列索引,每只股票的涨跌幅作为列数据。当数据量大的时候,创建的时候会报类似上面的错误。生成的目标DataFrame如下图所示(过去一年以来某些股票的涨跌幅数据):
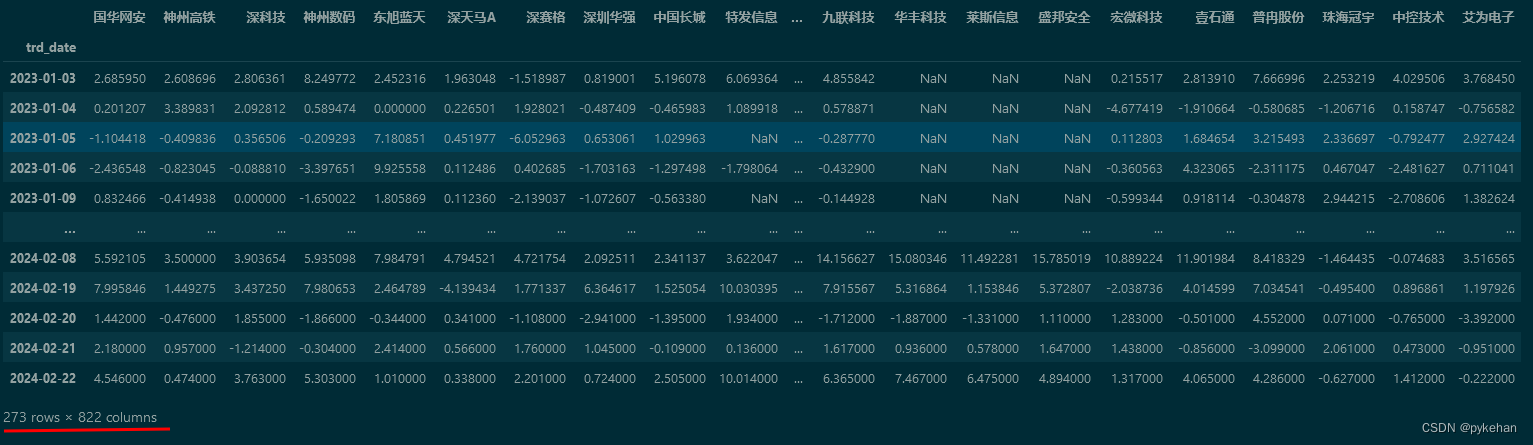
出现上述的“DataFrame is highly fragmented”报警,我用的是下面的代码:新建一个空的DataFrame,再逐个添加列。
df = pd.DataFrame()
for company in company_name[:]: # compnay是元素为dataFrame的list
company.drop_duplicates(subset=['trd_date'], inplace=True)
df[company['股票简称'].values[0]]=company['涨跌幅']那么,有什么解决办法呢?
1、处理的数据太多的话,报警输出很多,可以关闭掉报警。
import warnings
warnings.simplefilter(action='ignore', category=pd.errors.PerformanceWarning)2、按报警提示修改代码,用concat的方法,逐个合并dataFrame。
df = pd.DataFrame()
for company in company_name: # compnay是元素为dataFrame的list
company.drop_duplicates(subset=['trd_date'], inplace=True)
df = pd.concat([df, pd.DataFrame({company['股票简称'].values[0]:company['涨跌幅']})], axis=1).copy()
3、把数据添加到dict中,而后转成dataFrame。
dt = {}
for company in company_name:
company.drop_duplicates(subset=['trd_date'], inplace=True)
dt[company['股票简称'].values[0]]=company['涨跌幅']
df = pd.DataFrame(dt)最后,我们测试对比 一下性能:
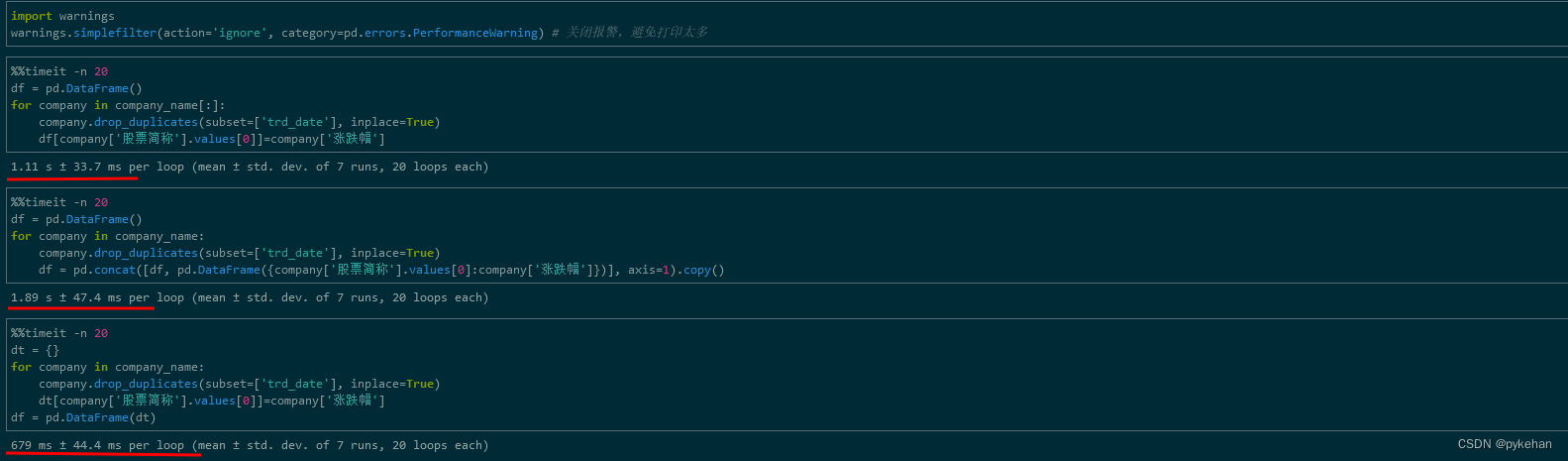
所以在碰到对dataFrame的行或列频繁进行添加时,避免逐个添加,可以先保存成dict,转换成dataFrame之后,再一次性追加到原有的dataFrame中。


















 2077
2077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









