







时隔多日,终于把第二篇特征工程的学习内容给整出来了,上一篇主要是集中讲了特征理解和特征增强,可以点击回顾特征构建和特征选择。
? 目录
-
? 特征理解
-
? 特征增强
-
? 特征构建
-
✅ 特征选择
-
? 特征转换(待更新)
-
? 特征学习(待更新)
如果我们对变量进行处理之后,效果仍不是非常理想,就需要进行特征构建了,也就是衍生新变量。
而在这之前,我们需要了解我们的数据集,先前两节中我们了解到了可以通过 data.info 和 data.describe() 来查看,同时结合数据等级(定类、定序、定距、定比)来理解变量。
? 基础操作
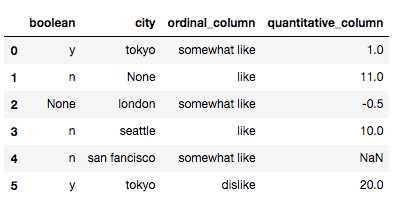
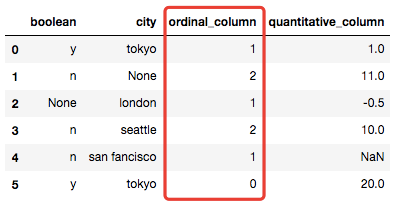
本小节中我们使用一个自定义数据集。
# 本次案例使用的数据集
import pandas as pd
X = pd.DataFrame({'city':['tokyo',None,'london','seattle','san fancisco','tokyo'],
'boolean':['y','n',None,'n','n','y'],
'ordinal_column':['somewhat like','like','somewhat like','like','somewhat like','dislike'],
'quantitative_column':[1,11,-.5,10,None,20]})
X
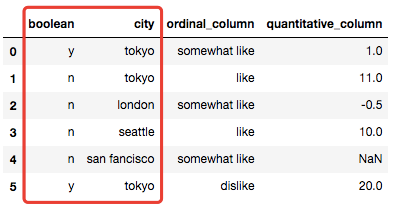
首先我们需要对分类变量进行填充操作,类别变量一般用众数或者特殊值来填充,回顾之前的内容,我们也还是采取Pipeline的方式来进行,因此可以事先基于TransformMixin基类来对填充的方法进行封装,然后直接在Pipeline中进行调用,代码可以参考:
# 填充分类变量(基于TransformerMixin的自定义填充器,用众数填充)
from sklearn.base import TransformerMixin
class CustomCategoryzImputer(TransformerMixin):
def __init__(self, cols=None):
self.cols = cols
def transform(self, df):
X = df.copy()
for col in self.cols:
X[col].fillna(X[col].value_counts().index[0], inplace=True)
return X
def fit(self, *_):
return self
# 调用自定义的填充器
cci = CustomCategoryzImputer(cols=['city','boolean'])
cci.fit_transform(X)
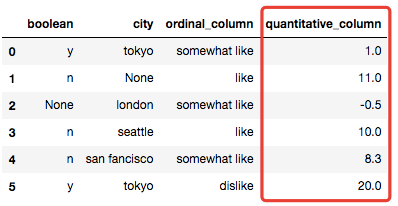
又或者利用 scikit-learn 的 Imputer类来实现填充,而这个类有一个 Strategy的方法自然就被继承过来用了,包含的有mean、median、most_frequent可供选择。
# 填充分类变量(基于Imputer的自定义填充器,用众数填充)
from sklearn.preprocessing import Imputer
class CustomQuantitativeImputer(TransformerMixin):
def __init__(self, cols=None, strategy='mean'):
self.cols = cols
self.strategy = strategy
def transform(self, df):
X = df.copy()
impute = Imputer(strategy=self.strategy)
for col in self.cols:
X[col] = impute.fit_transform(X[[col]])
return X
def fit(self, *_):
return self
# 调用自定义的填充器
cqi = CustomQuantitativeImputer(cols = ['quantitative_column'], strategy='mean')
cqi.fit_transform(X)
对上面的两种填充进行流水线封装:
# 全部填充
from sklearn.pipeline import Pipeline
imputer = Pipeline([('quant',cqi),
('category',cci)
])
imputer.fit_transform(X)
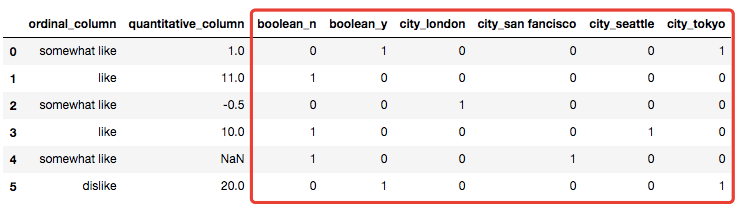
完成了分类变量的填充工作,接下来就需要对分类变量进行编码了(因为大多数的机器学习算法都是无法直接对类别变量进行计算的),一般有两种办法:独热编码以及标签编码。
1)独热编码
独热编码主要是针对定类变量的,也就是不同变量值之间是没有顺序大小关系的,我们一般可以使用 scikit_learn 里面的 OneHotEncoding来实现的,但我们这里还是使用自定义的方法来加深理解。
# 类别变量的编码(独热编码)
class CustomDummifier(TransformerMixin):
def __init__(self, cols=None):
self.cols = cols
def transform(self, X):
return pd.get_dummies(X, columns=self.cols)
def fit(self, *_):
return self
# 调用自定义的填充器
cd = CustomDummifier(cols=['boolean','city'])
cd.fit_transform(X)
2)标签编码
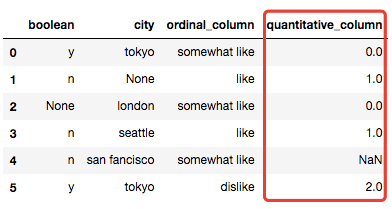
标签编码是针对定序变量的,也就是有顺序大小的类别变量,就好像案例中的变量ordinal_column的值(dislike、somewhat like 和 like 可以分别用0、1、2来表示),同样的可以写个自定义的标签编码器:
# 类别变量的编码(标签编码)
class CustomEncoder(TransformerMixin):
def __init__(self, col, ordering=None):
self.ordering = ordering
self.col = col
def transform(self, df):
X = df.copy()
X[self.col] = X[self.col].map(lambda x: self.ordering.index(x))
return X
def fit(self, *_):
return self
# 调用自定义的填充器
ce = CustomEncoder(col='ordinal_column', ordering=['dislike','somewhat like','like'])
ce.fit_transform(X)
3)数值变量分箱操作
以上的内容是对类别变量的一些简单处理操作,也是比较常用的几种,接下来我们就对数值变量进行一些简单处理方法的讲解。
有的时候,虽然变量值是连续的,但是只有转换成类别才有解释的可能,比如年龄,我们需要分成年龄段,这里我们可以使用pandas的 cut函数来实现。
# 数值变量处理——cut函数
class CustomCutter(TransformerMixin):
def __init__(self, col, bins, labels=False):
self.labels = labels
self.bins = bins
self.col = col
def transform(self, df):
X = df.copy()
X[self.col] = pd.cut(X[self.col], bins=self.bins, labels=self.labels)
return X
def fit(self, *_):
return self
# 调用自定义的填充器
cc = CustomCutter(col='quantitative_column', bins=3)
cc.fit_transform(X)
综上,我们可以对上面自定义的方法一并在Pipeline中进行调用,Pipeline的顺序为:
1)用imputer填充缺失值
2)独热编码city和boolean
3)标签编码ordinal_column
4)分箱处理quantitative_column
代码为:
from sklearn.pipeline import Pipeline
# 流水线封装
pipe = Pipeline([('imputer',imputer),
('dummify',cd),
('encode',ce),
('cut',cc)
])
# 训练流水线
pipe.fit(X)
# 转换流水线
pipe.transform(X)
? 数值变量扩展
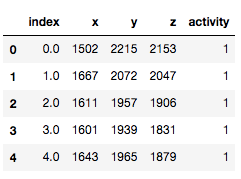
这一小节我们使用一个新的数据集(人体胸部加速度数据集),我们先导入数据:
# 人体胸部加速度数据集,标签activity的数值为1-7
'''
1-在电脑前工作
2-站立、走路和上下楼梯
3-站立
4-走路
5-上下楼梯
6-与人边走边聊
7-站立着说话
'''
df = pd.read_csv('./data/activity_recognizer/1.csv', header=None)
df.columns = ['index','x','y','z','activity']
df.head()
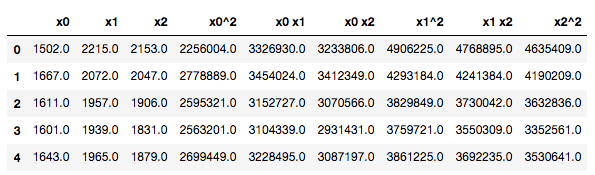
这边只介绍一种多项式生成新特征的办法,调用PolynomialFeatures来实现。
# 扩展数值特征
from sklearn.preprocessing import PolynomialFeatures
x = df[['x','y','z']]
y = df['activity']
poly = PolynomialFeatures(degree=2, include_bias=False, interaction_only=False)
x_poly = poly.fit_transform(x)
pd.DataFrame(x_poly, columns=poly.get_feature_names()).head()
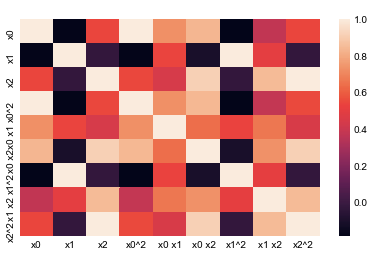
还可以查看下衍生新变量后的相关性情况,颜色越深相关性越大:
# 查看热力图(颜色越深代表相关性越强)
%matplotlib inline
import seaborn as sns
sns.heatmap(pd.DataFrame(x_poly, columns=poly.get_feature_names()).corr())
在流水线中的实现代码:
# 导入相关库
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
knn = KNeighborsClassifier()
# 在流水线中使用
pipe_params = {'poly_features__degree':[1,2,3],
'poly_features__interaction_only':[True,False],
'classify__n_neighbors':[3,4,5,6]}
# 实例化流水线
pipe = Pipeline([('poly_features',poly),
('classify',knn)])
# 网格搜索
grid = GridSearchCV(pipe, pipe_params)
grid.fit(x,y)
print(grid.best_score_, grid.best_params_)
0.721189408065 {'classify__n_neighbors': 5, 'poly_features__degree': 2, 'poly_features__interaction_only': True}
? 文本变量处理
文本处理一般在NLP(自然语言处理)领域应用最为广泛,一般都是需要把文本进行向量化,最为常见的方法有 词袋(bag of words)、CountVectorizer、TF-IDF。
1)bag of words
词袋法分成3个步骤,分别是分词(tokenizing)、计数(counting)、归一化(normalizing)。
2)CountVectorizer
将文本转换为矩阵,每列代表一个词语,每行代表一个文档,所以一般出来的矩阵会是非常稀疏的,在sklearn.feature_extraction.text 中调用 CountVectorizer 即可使用。
3)TF-IDF
TF-IDF向量化器由两个部分组成,分别为代表词频的TF部分,以及代表逆文档频率的IDF,这个TF-IDF是一个用于信息检索和聚类的词加权方法,在 sklearn.feature_extraction.text 中调用 TfidfVectorizer 即可。
TF:即Term Frequency,词频,也就是单词在文档中出现的频率。
IDF:即Inverse Document Frequency,逆文档频率,用于衡量单词的重要度,如果单词在多份文档中出现,就会被降低权重。
✅ 04 特征选择
好了,经过了上面的特征衍生操作,我们现在拥有了好多好多的特征(变量)了,全部丢进去模型训练好不好?当然是不行了?,这样子既浪费资源又效果不佳,因此我们需要做一下 特征筛选 ,而特征筛选的方法大致可以分为两大类:基于统计的特征筛选 和 基于模型的特征筛选。
在进行特征选择之前,我们需要搞清楚一个概念:到底什么是更好的?有什么指标可以用来量化呢?
这大致也可以分为两大类:一类是模型指标,比如accuracy、F1-score、R^2等等,还有一类是元指标,也就是指不直接与模型预测性能相关的指标,如:模型拟合/训练所需的时间、拟合后的模型预测新实例所需要的时间、需要持久化(永久保存)的数据大小。
我们可以通过封装一个方法,把上面提及到的指标封装起来,方便后续的调用,代码如下:
from sklearn.model_selection import GridSearchCV
def get_best_model_and_accuracy(model, params, x, y):
grid = GridSearchCV(model,
params,
error_score=0.)
grid.fit(x,y)
# 经典的性能指标
print("Best Accuracy:{}".format(grid.best_score_))
# 得到最佳准确率的最佳参数
print("Best Parameters:{}".format(grid.best_params_))
# 拟合的平均时间
print("Average Time to Fit (s):{}".format(round(grid.cv_results_['mean_fit_time'].mean(), 3)))
# 预测的平均时间
print("Average Time to Score (s):{}".format(round(grid.cv_results_['mean_score_time'].mean(), 3)))
############### 使用示例 ###############
# 导入相关库
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
knn = KNeighborsClassifier()
# 在流水线中使用
pipe_params = {'poly_features__degree':[1,2,3],
'poly_features__interaction_only':[True,False],
'classify__n_neighbors':[3,4,5,6]}
# 实例化流水线
pipe = Pipeline([('poly_features',poly),
('classify',knn)])
# 网格搜索
get_best_model_and_accuracy(pipe, pipe_params, x, y)
通过上面的操作,我们可以创建一个模型性能基准线,用于对比后续优化的效果。接下来介绍一些常用的特征选择方法。
1)基于统计的特征选择
针对于单变量,我们可以采用 皮尔逊相关系数以及假设检验 来选择特征。
(1)皮尔逊相关系数可以通过 corr() 来实现,返回的值在-1到1之间,绝对值越大代表相关性越强;
(2)假设检验也就是p值,作为一种统计检验,在特征选择中,假设测试得原则是:” 特征与响应变量没有关系“(零假设)为真还是假。我们需要对每个变量进行检测,检测其与target有没有显著关系。可以使用 SelectKBest 和 f_classif 来实现。一般P值是介于0-1之间,简而言之,p值越小,拒绝零假设的概率就越大,也就是这个特征与target关系更大。
2)基于模型的特征选择
(1)对于文本特征,sklearn.feature_extraction.text里的 CountVectorizer有自带的特征筛选的参数,分别是 max_features、min_df、max_df、stop_words,可以通过搜索这些参数来进行特征选择,可以结合 SelectKBest 来实现流水线。
(2)针对?树模型,我们可以直接调用不同树模型算法里的 特征重要度 来返回特征重要度,比如 DecisionTreeClassifier里的feature_importances_,(除此之外还有RandomForest、GBDT、XGBoost、ExtraTreesClassifier等等)都可以直接返回每个特征对于本次拟合的重要度,从而我们可以剔除重要度偏低的特征,可以结合 SelectFromModel来实现流水线。
(3)使用正则化来筛选变量(针对线性模型)。有两种常用的正则化方法:L1正则化(Lasso)和L2正则化(岭)。
总结一下,有几点做特征选择的方法经验:
(1)如果特征是分类变量,那么可以从SelectKBest开始,用卡方或者基于树的选择器来选择变量;
(2)如果特征是定量变量,可以直接用线性模型和基于相关性的选择器来选择变量;
(3)如果是二分类问题,可以考虑使用 SelectFromModel和SVC;
(4)在进行特征选择前,还是需要做一下EDA。
















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









