







数据预处理
数据可划分为结构化数据与非结构化数据,定义如下:
- 结构化数据
代表性的有数值型、字符串型数据 - 非结构化数据
代表的有文本型、图像型、视频型以及语音型数据
结构化数据预处理
预处理一般可分为缺失值处理、离群值(异常值)处理以及数据变换
缺失值处理
一般来说,未经处理的原始数据中通常会存在缺失值、离群值等,因此在建模训练之前需要处理好缺失值。
缺失值处理方法一般可分为:删除、统计值填充、统一值填充、前后向值填充、插值法填充、建模预测填充和具体分析7种方法。
直接删除
缺失值最简单的处理方法是删除,所谓删除就是删除属性或者删除样本,删除一般可分为两种情况:
-
删除属性(特征)
如果某一个特征中存在大量的缺失值(缺失量大于总数据量的40%~50%及以上),
那么我们可以认为这个特征提供的信息量非常有限,这个时候可以选择删除掉这一维特征。 -
删除样本
如果整个数据集中缺失值较少或者缺失值数量对于整个数据集来说可以忽略不计的情况下,
那么可以直接删除含有缺失值的样本记录。
注意事项:
如果数据集本身数据量就很少的情况下,不建议直接删除缺失值。
代码实现
构造假数据做演示,就上面两种情况进行代码实现删除
import numpy as np
import pandas as pd
# 构造数据
def dataset():
col1 = [1, 2, 3, 4, 5, 6, 7, 8, 9,10]
col2 = [3, 1, 7, np.nan, 4, 0, 5, 7, 12, np.nan]
col3 = [3, np.nan, np.nan, np.nan, 9, np.nan, 10, np.nan, 4, np.nan]
y = [10, 15, 8, 12, 17, 9, 7, 14, 16, 20]
data = {'feature1':col1, 'feature2':col2, 'feature3':col3, 'label':y}
df = pd.DataFrame(data)
return df
data = dataset()
print(data)
# 删除属性
def delete_feature(df):
N = df.shape[0] # 样本数
no_nan_count = df.count().to_frame().T # 每一维特征非缺失值的数量
del_feature, save_feature = [], []
for col in no_nan_count.columns.tolist():
loss_rate = (N - no_nan_count[col].values[0])/N # 缺失率
# print(loss_rate)
if loss_rate > 0.5: # 缺失率大于 50% 时,将这一维特征删除
del_feature.append(col)
else:
save_feature.append(col)
return del_feature, df[save_feature]
del_feature, df11 = delete_feature(data)
print(del_feature)
# 删除样本
# 从上面可以看出,feature2 的缺失值较少,
# 可以采取直接删除措施
def delete_sample(df):
df_ = df.dropna()
return df_
delete_sample(df11)
统计值填充
-
对于特征的缺失值,可以根据缺失值所对应的那一维特征的统计值来进行填充。
-
统计值一般泛指平均值、中位数、众数、最大值、最小值等,具体使用哪一种统计值要根据具体问题具体分析。
注意事项:当特征之间存在很强的类别信息时,需要进行类内统计,效果比直接处理会更好。比如在填充身高时,需要先对男女进行分组聚合之后再进行统计值填充处理(男士的一般平均身高1.70,女士一般1.60)。
代码实现
使用上面数据帧 df11 作为演示数据集,分别实现使用各个统计值填充缺失值。
# 均值填充
print(df11.mean())
df11.fillna(df11.mean())
# 中位数填充
print(df11.median())
df11.fillna(df11.median())
# 众数填充
# print(df11.mode())
# 由于众数可能会存在多个,因此返回的是序列而不是一个值
# 所以在填充众数的时候,我们可以 df11['feature'].mode()[0],可以取第一个众数作为填充值
def mode_fill(df):
for col in df.columns.tolist():
if df[col].isnull().sum() > 0: # 有缺失值就进行众数填充
df_ = df.fillna(df11[col].mode()[0])
return df_
mode_fill(df11)
# 最大值/最小值填充
df11.fillna(df11.max())
df11.fillna(df11.min())
统一值填充
- 对于缺失值,把所有缺失值都使用统一值作为填充词,所谓统一值是指自定义指定的某一个常数。
- 常用的统一值有:空值、0、正无穷、负无穷或者自定义的其他值
注意事项:当特征之间存在很强的类别信息时,需要进行类内统计,效果比直接处理会更好。比如在填充身高时,需要先对男女进行分组聚合之后再进行统一值填充处理。(男士的身高缺失值使用统一填充值就自定为常数1.70,女士自定义常数1.60)。
前后向值填充
- 前后向值填充是指使用缺失值的前一个或者后一个的值作为填充值进行填充。
离群值处理
标准差法
又称为拉依达准则(标准差法),适用于有较多组数据的时候。
工作原理:它是先假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,
按一定概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,
含有该误差的数据应予以剔除。
标准差本身可以体现因子的离散程度,是基于因子的平均值μ而定的。在离群值处理过程中,
可通过用μ±nσ来衡量因子与平均值的距离
公式:假设有近似服从正态分布离散数据X=[x1,x2,…,xn],其均值μ与标准差σ分别为:
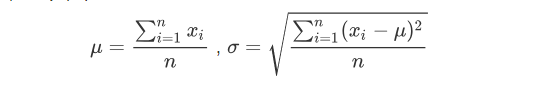

# 标准差法
import seaborn as sns
import numpy as np
def std_(df):
item, N = 'sepal_length', df.shape[0]
M = np.sum(df[item])/N
assert (M == np.mean(df[item])), 'mean is error'
S = np.sqrt(np.sum((df[item]-M)**2)/N)
L, R = M-3*S, M+3*S
return '正常区间值为 [%.4f, %.4f]' % (L, R)
df = sns.load_dataset('iris')
std_(df)
MAD法
概念:又称为绝对值差中位数法,是一种先需计算所有因子与中位数之间的距离总和来检测离群值的方法,适用大样本数据
公式:设有平稳离散数据X=[x1,x2,…,xn],其数据中位数记:
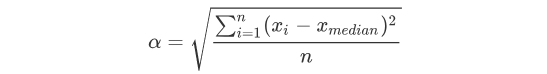

# MAD法
def MAD(df):
item, N = 'sepal_length', df.shape[0]
M = np.median(df[item])
A = np.sqrt(np.sum((df[item]-M)**2)/N)
L, R = M-3*A, M+3*A
return '正常区间值为 [%.4f, %.4f]' % (L, R)
MAD(df)
图像对比法
- 所谓的图像对比法是通过比较训练集和测试集对应的特征数据在某一区间是否存在较大的差距来判别这一区间的数据是不是属于异常离群值。
优缺点
- 优点:可以防止训练集得到的模型不适合测试集预测的模型,从而减少二者之间的误差。
应用场景及意义
- 意义:提高模型的可靠性和稳定性。
# 功能实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# 构造一个演示数据
D1 = {'feature1':[1,4,3,4,6.3,6,7,8,8.3,10,9.5,12,11.2,14.5,17.8,15.3,17.3,17,19,18.8],
'feature2':[11,20,38,40,59,61,77,84,99,115,123,134,130,155,138,160,152,160,189,234],
'label':[1,5,9,4,12,6,17,25,19,10,31,11,13,21,15,28,35,24,19,20]}
D2= {'feature1':[1,3,3,6,5,6,7,10,9,10,13,12,16,14,15,16,14,21,19,20],
'feature2':[13,25,33,49,45,66,74,86,92,119,127,21,13,44,34,29,168,174,178,230]}
df_train = pd.DataFrame(data=D1)
df_test = pd.DataFrame(data=D2)
L = [df_train.iloc[:,1], df_test.iloc[:,1], 'train_feature2', 'test_feature2']
fig = plt.figure(figsize=(15,5))
X = list(range(df_train.shape[0]))
for i in range(2):
ax = fig.add_subplot(1,2,i+1)
ax.plot(X, L[i],label=L[i+2],color='red')
ax.legend()
ax.set_xlabel('Section')

结论:
-
从上面的的图形对比,明显发现在区间 [10,15] 之间训练集 feature2 和测试集 feature2 的数据差距悬殊(严重突变),
因此区间 [10,15] 的数据可判定为离群异常值,应在训练集和测试集中同时剔除掉,防止训练集训练的模型不适用于测试集的预测。 -
如果不进行剔除或其他处理,训练模型在测试集预测会存在巨大的误差。
无量纲化
极差标准化(Min-nax)
Min-max区间缩放法(极差标准化),将数值缩放到[0 1]区间
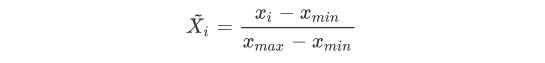
极大值标准化(Max-abs)
Max-abs (极大值标准化),标准化之后的每一维特征最大要素为1,其余要素均小于1,理论公式如下:
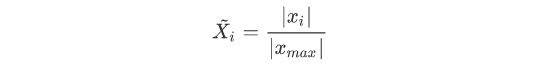
标准差标准化(z-score)
z-score 标准化(标准差标准化)为类似正态分布,均值为0,标准差为1
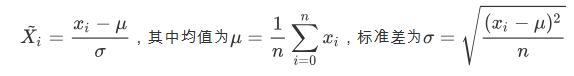
归一化——总和标准化
归一化(总和标准化),归一化的目的是将所有数据变换成和为1的数据,常用于权重的处理,在不同数据比较中,常用到权重值来表示其重要性,往往也需要进行加权平均处理。
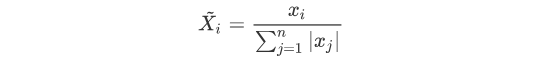
非线性归一化
非线性归一化:对于所属范围未知或者所属范围是全体实数,同时不服从正态分布的数据,
对其作Min-max标准化、z-score标准化或者归一化都是不合理的。
要使范围为R的数据映射到区间[0,1]内,需要作一个非线性映射。而常用的有sigmoid函数、arctan函数和tanh函数。

import seaborn as sns
import numpy as np
df = sns.load_dataset('iris')
print(df.shape)
df.head()
# 1.Min-max 区间缩放法-极差标准化
# 自己手写理论公式来实现功能
# 缩放到区间 [0 1]
def Min_max(df):
x_minmax = []
for item in df.columns.tolist()[:4]:
MM = (df[item] - np.min(df[item]))/(np.max(df[item])-np.min(df[item]))
x_minmax.append(MM.values)
return np.array(np.matrix(x_minmax).T)[:5]
Min_max(df)
# 直接调用 sklearn 模块的 API 接口
# 极差标准化(最大最小值标准化)
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
x_minmax_scaler = mms.fit_transform(df.iloc[:, :4])
x_minmax_scaler[:5]
# 2.MaxAbs 极大值标准化
# 自己手写理论公式来实现功能
def MaxAbs(df):
x_maxabs_scaler = []
for item in df.columns.tolist()[:4]:
Max = np.abs(np.max(df[item]))
MA = np.abs(df[item])/Max
x_maxabs_scaler.append(MA)
return np.array(np.matrix(x_maxabs_scaler).T)[:5]
MaxAbs(df)
# 直接调用 sklearn 模块的 API 接口
# 极大值标准化
from sklearn.preprocessing import MaxAbsScaler
mas = MaxAbsScaler()
x_maxabs_scaler = mas.fit_transform(df.iloc[:, :4])
x_maxabs_scaler[:5]
# 3.z-score 标准差标准化
# 自己手写理论公式来实现功能
# 标准化之后均值为 0,标准差为 1
def z_score(df):
N, x_z = df.shape[0], []
for item in df.columns.tolist()[:4]:
mean = np.sum(df[item])/N
std = np.sqrt(np.sum((df[item]-mean)**2)/N)
Z = (df[item] - mean)/std
x_z.append(Z)
return np.array(np.matrix(x_z).T)[:5]
z_score(df)
# 直接调用 sklearn 模块的 API 接口
# 标准差标准化
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
x_std_scaler = ss.fit_transform(df.iloc[:, :4])
x_std_scaler[:5]
# 4.归一化---总和归一化
# 自己手写理论公式来实现功能
# 处理成所有数据和为1,权重处理
def feature_importance(df):
x_sum_scaler = []
for item in df.columns.tolist()[:4]:
S = np.sum(df[item])
FI = df[item]/S
x_sum_scaler.append(FI)
return np.array(np.matrix(x_sum_scaler).T)[:5]
feature_importance(df)
# 5.非线性归一化
# 自己手写理论公式来实现功能
# sigmoid 函数归一化
def sigmoid(df):
x_sigmoid = []
for item in df.columns.tolist()[:4]:
S = 1/(1+np.exp(-df[item]))
x_sigmoid.append(S)
return np.array(np.matrix(x_sigmoid).T)[:5]
sigmoid(df)
类别数据处理
很多算法模型不能直接处理字符串数据,因此需要将类别型数据转换成数值型数据
序号编码(Ordinal Encoding)
通常用来处理类别间具有大小关系的数据,比如成绩(高中低)
假设有类别数据X=[x1,x2,…,xn],则序号编码思想如下:
- (1)确定X中唯一值的个数K,将唯一值作为关键字,即Key=[x1,x2,…,xk]
- (2)生成k个数字作为键值,即Value=[0,1,2,…,k]
- (3)每一个唯一的类别型元素对应着一个数字,即键值对dict={key1:0, key2:1,…, keyk:k}
# 序号编码
# 自己手写理论公式实现功能(可优化)
import seaborn as sns
def LabelEncoding(df):
x, dfc = 'species', df
key = dfc[x].unique() # 将唯一值作为关键字
value = [i for i in range(len(key))] # 键值
Dict = dict(zip(key, value)) # 字典,即键值对
for i in range(len(key)):
for j in range(dfc.shape[0]):
if key[i] == dfc[x][j]:
dfc[x][j] = Dict[key[i]]
dfc[x] = dfc[x].astype(np.float32)
return dfc[:5]
data = sns.load_dataset('iris')
le = LabelEncoding(data)
# 调用 sklearn 模块的 API 接口
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
x_le = le.fit_transform(data['species'])
独热编码(One-hot Encoding)
通常用于处理类别间不具有大小关系的特征,比如血型(A型血、B型血、AB型血、O型血),独热编码会把血型变成一个稀疏向量,A型血表示为(1,0,0,0),B型血表示为(0,1,0,0),AB型血表示为(0,0,1,0),O型血表示为(0,0,0,1)
- (1)在独热编码下,特征向量只有某一维取值为1,其余值均为0,因此可以利用向量的稀疏来节省空间
- (2)如果类别型的唯一类别元素较多,可能会造成维度灾难,因此需要利用特征选择来降低维度。
假设有类别数据X=[x1,x2,…,xn],则独热编码思想如下:
- (1)确定X中唯一值的个数K,将唯一值作为关键字,即Key=[x1,x2,…,xk]
- (2)生成k个数字为1的一维数组作为键值,即Value=[1,1,1,…,k]
- (3)每一个唯一的类别型元素对应着一个数字,即键值对dict={key1:0, key2:1,…, keyk:k}
- (4)创建一个空的数组v=V(n维 x k维)=np.zeros((n, k))
- (5)将数值对应的那一维为1,其余为0,最后将V与原始数据合并即可
原来的数据:

dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df.head()

















 4454
4454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











