






 本文介绍了在深度学习中如何将视频素材转换为图片,并对生成的图片进行数据清洗和打标。提供了一段Python代码示例,用于按指定帧率从视频中提取图片,同时指出了需要修改的代码部分,包括视频路径、保存图片的文件夹等。此外,还提到了使用Labelimg进行图片打标的教程链接。
本文介绍了在深度学习中如何将视频素材转换为图片,并对生成的图片进行数据清洗和打标。提供了一段Python代码示例,用于按指定帧率从视频中提取图片,同时指出了需要修改的代码部分,包括视频路径、保存图片的文件夹等。此外,还提到了使用Labelimg进行图片打标的教程链接。
1.前言
在深度学习的训练过程中,第一步要做的制作数据集。本文所介绍的内容就是在面临视频素材时,如何将这个视频素材转换成图片,并将生成的图片给打上标签。
2.视频转图片的代码展示
# coding=utf-8
import cv2
import os
root = "F:\HSvideo/HSsource/"
filename= os.path.join(root, "MP4/hat12.ps") # 视频的绝对路径
vc = cv2.VideoCapture(filename) # 读入视频文件,命名cv
n = 1 # 计数
if vc.isOpened(): # 判断是否正常打开
rval, frame = vc.read()
else:
rval = False
timeF = 10 # 视频帧计数间隔频率
i = 0
while rval: # 循环读取视频帧
rval, frame = vc.read()
if (n % timeF == 0): # 每隔timeF帧进行存储操作
i += 1
print(i)
save_path = os.path.join(root, 'Head/hatsplit_{}.jpg'.format(i))
print(save_path)
# input()
cv2.imwrite(save_path, frame) # 存储为图像
n = n + 1
cv2.waitKey(1)
vc.release()告诉大家拿到这段代码之后,想将自己的视频转化为自己指定文件夹的图片应该要修改哪些位置:
1.视频的根目录

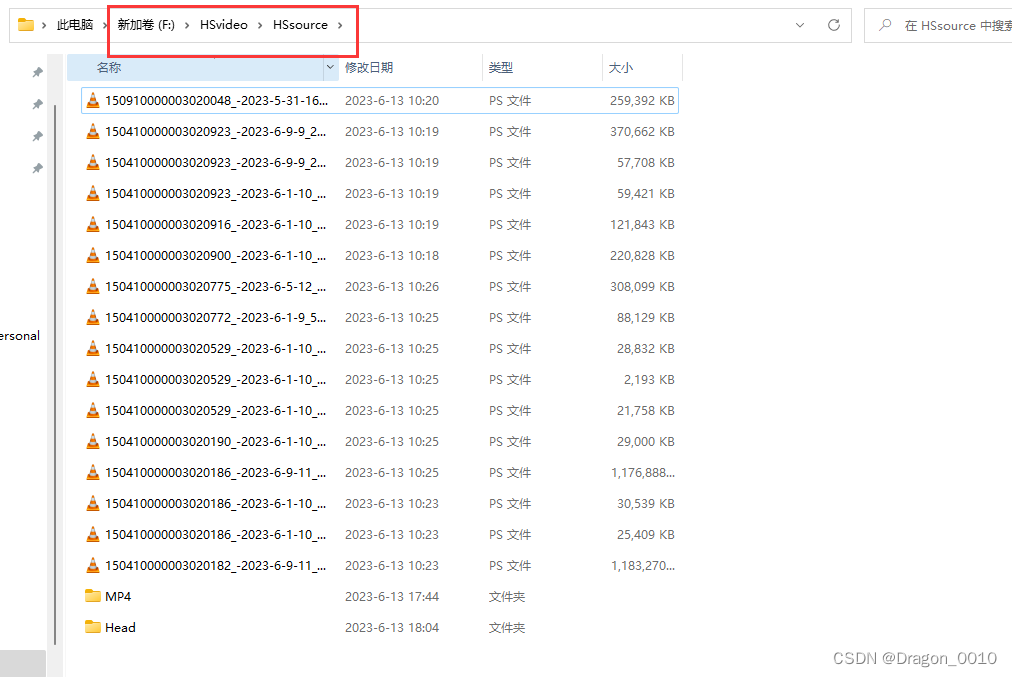
2.视频在根目录中所在的位置

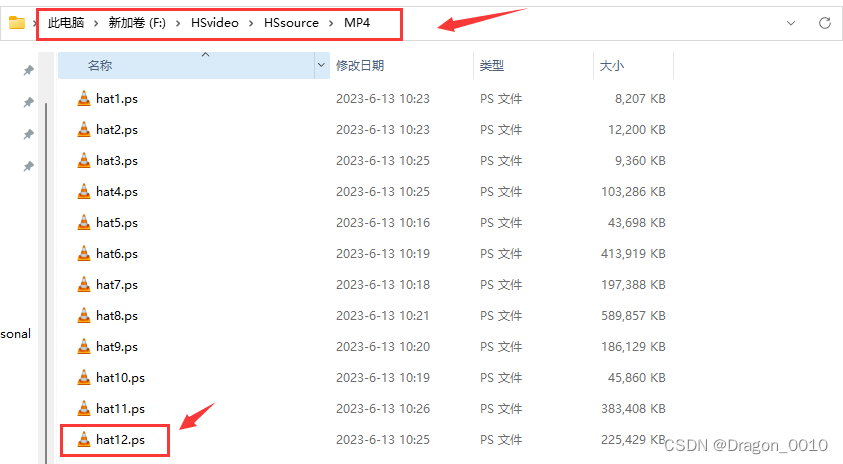
这里我的视频格式是.ps格式,具体可以根据你的视频格式来修改,也可以是.mp4格式
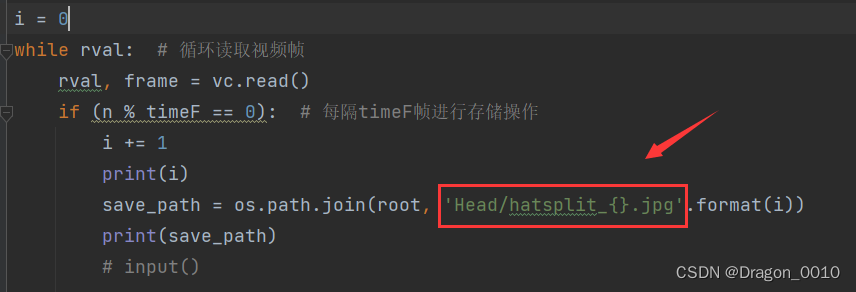
3.指定生成图片的文件夹
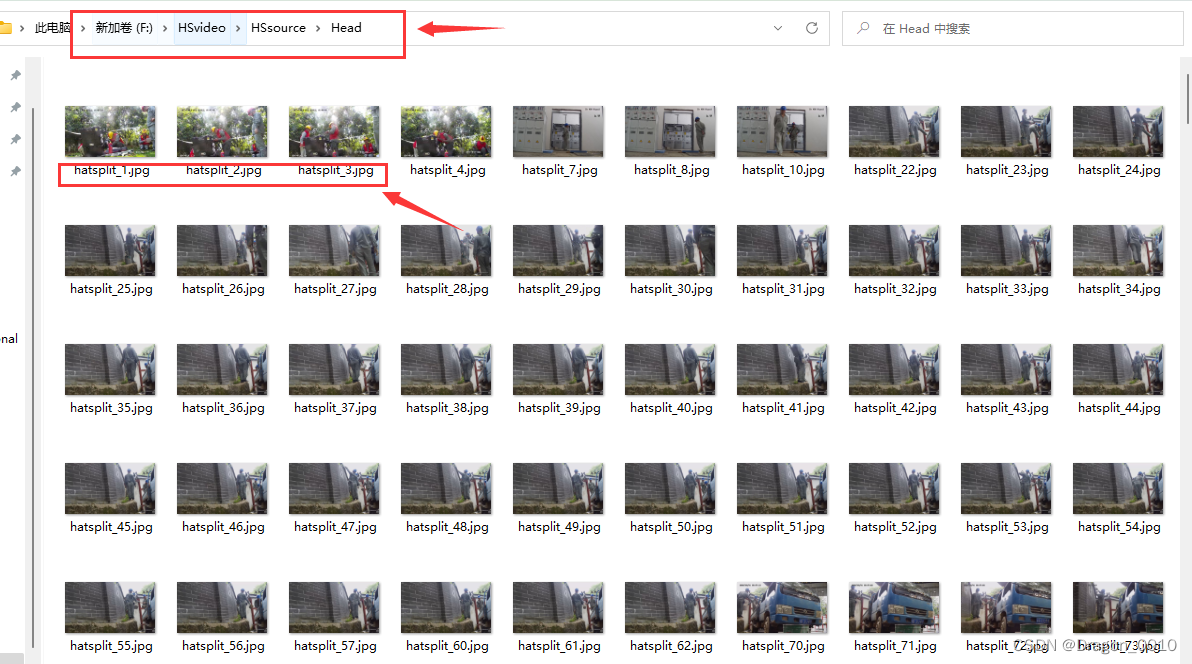
4.展示转化成功的结果
3.对生成的图片进行数据清洗并打标
1.数据清洗
剔除掉模糊、重复性高、失帧的图片
2.对筛选过后的图片进行打标
具体的打标教程之前我有写过,非常的详细,链接在这里:
使用Labelimg打标教学_labelimg jpegimages predefined_classes.txt_Dragon_0010的博客-CSDN博客




















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









