







简介
最近《我本是高山》引发热烈讨论,热搜一波连着一波,究竟是为何扑街成这样呢?今天来教大家如何用Python来分析电影数据,获取豆瓣电影短评以及词云。

这里以《海上钢琴师》为例,给大家做个示范
【最新Python全套从入门到精通学习资源,文末免费领取!】
一、requests+lxml非登录爬取豆瓣数据
1、首先打开豆瓣,找到想要爬取的电影短评地址url,例如:
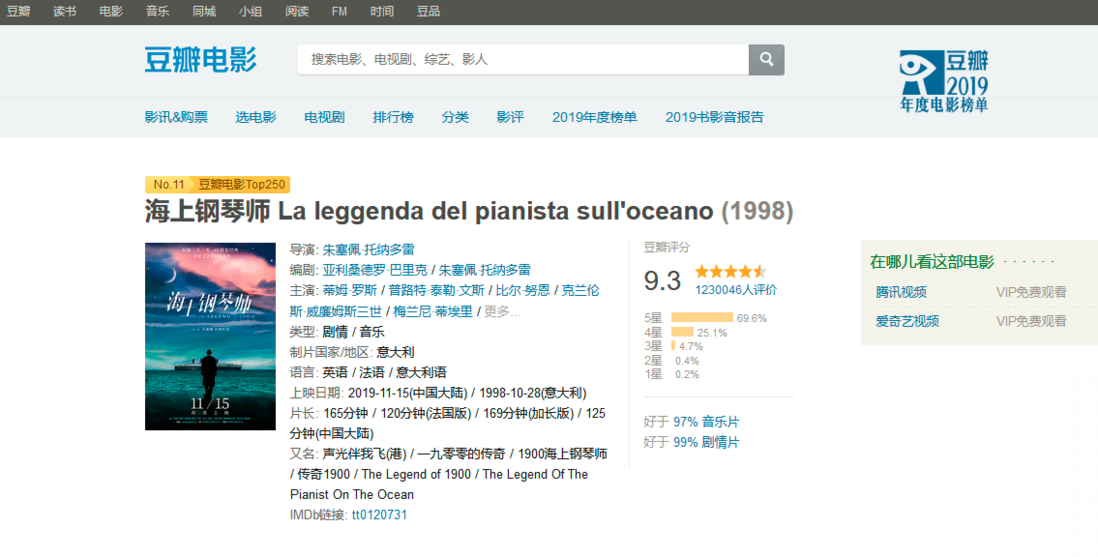
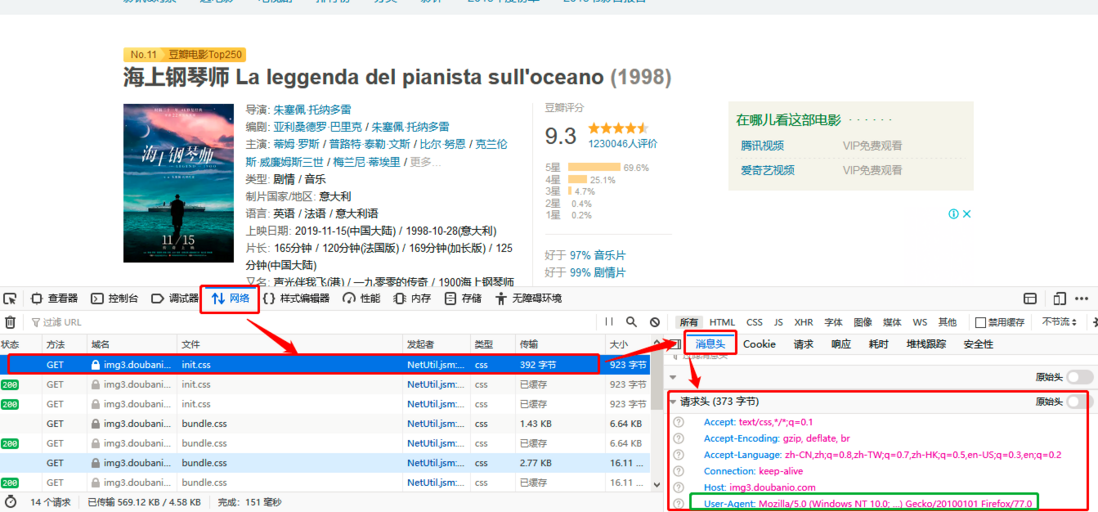
2、打开网页中开发者工具,大部分电脑直接按F12即可,也有不同的,比如ThinkPad使用Fn+F12打开,在页面中找到网络->点击第一行->在右边找到消息头->下滑,找到请求头,记下user-agent
⭐**注意:**这里的user-agent包含浏览器相关信息和硬件设备信息等,可以伪装成合法的用户请求,否则报错403:服务器上文件或目录拒绝访问
3、代码部分
#引包
import requests as rq
from lxml import etree
#url+headers信息
url = 'https://movie.douban.com/subject/1292001/'
headers = {'User-Agent':'****'}
4、获取网页数据(网页html式样)
⭐非登录状态下使用的是get()方法
data = rq.get(url,headers=headers).text
data的输出结果:
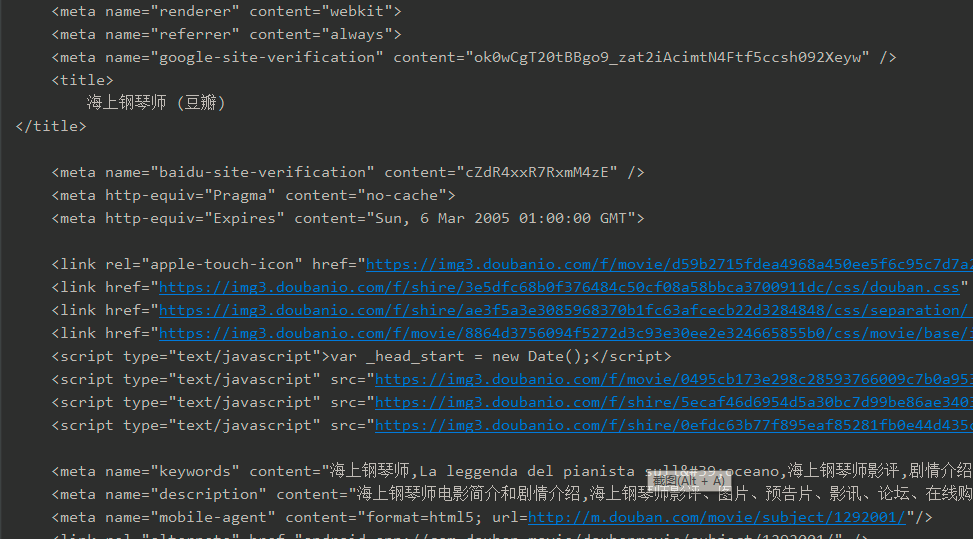
5、获取到网页数据后要对网页进行解析
s = etree.HTML(data)
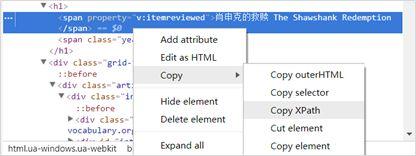
6、接下来获取网页中元素信息,比如:电影名称,导演,演员,时长等…可手动获取网页信息,如下图:
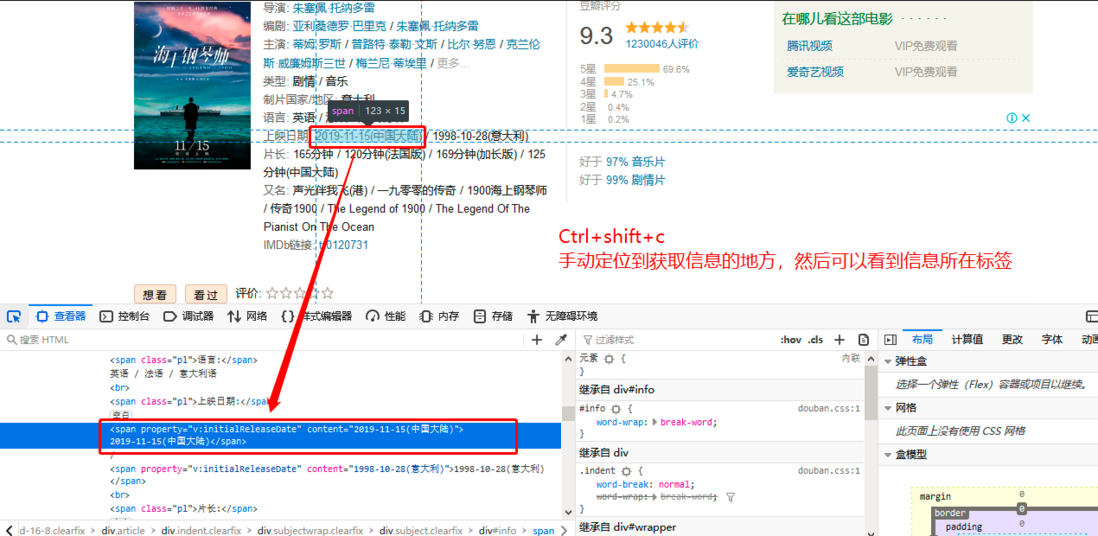
选中目标标签右键->复制->XPath(盗用网络图片)
7、代码部分
#默认返回的是list列表格式
film = s.xpath('/html/body/div[3]/div[1]/h1/span[1]/text()')
director = s.xpath('/html/body/div[3]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]/span[2]/a/text()')
Starring = s.xpath('/html/body/div[3]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[3]/span[2]/a/text()')
duration = s.xpath('/html/body/div[3]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[13]/text()')
print("影名:" , film[0])
print("director:",director[0])
print("Starring:",Starring[0])
print("duration:",duration[0])
二、模拟登录豆瓣爬取短影评
1、模拟登录豆瓣
(1)登录豆瓣的方式有很多种,这里选择密码登录
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2248
2248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









