







任务解析
任务是爬取豆瓣上的电影名称、评分、年份、国家、类型、评价人数、导演中文名、导演英文名、主演以及代表句。
电影名称:<span class='title'>中可以使用select或者find来抓取数据集
评分:<span class='rating_num'>中可以使用select或者find来抓取数据集
年份:<p class>在数据中第一个
国家:<p class>在数据中第二个
类型:<p class>在数据中第三个
评价人数:<span>去除人评价
导演中文名:<p class>第一个
导演英文名:<p class>第二个
主演:<p class>
代表句<p class='quote'>。
难点分析
电影名称、评分所在的标签都是相同的属性,需要使用到列表的切片;年份、国家、类型、导演中文名、导演英文名、主演基本有的数据都在一个属性中,需要使用正则或者切片来处理。按网页页数来抓取数据集,最后把数据存入csv文件中。
数据位置
1、写入关键的代码
-
首先我们先将url导入浏览器中看该网站的网页数据存放的位置,浏览器的请求方式为get
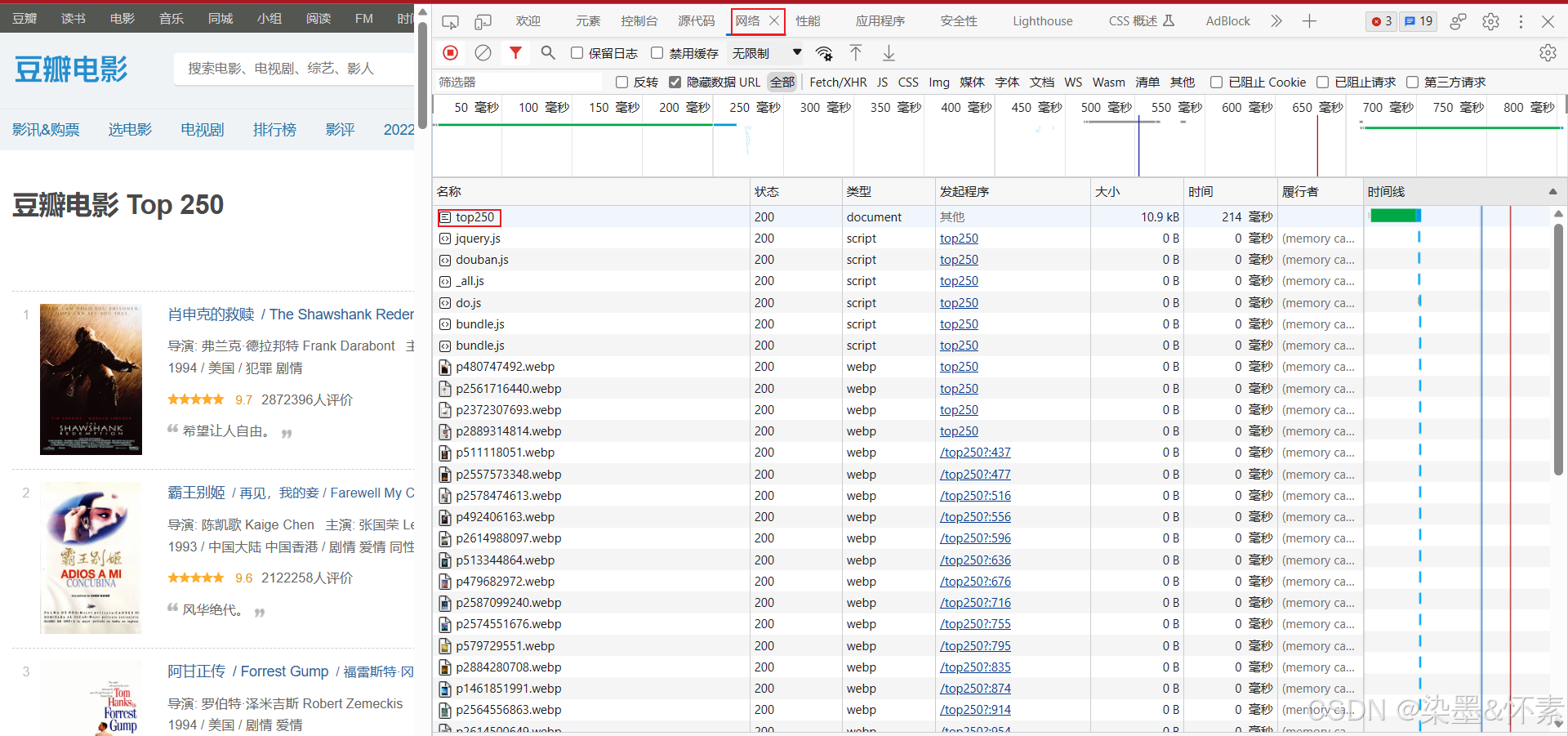
-
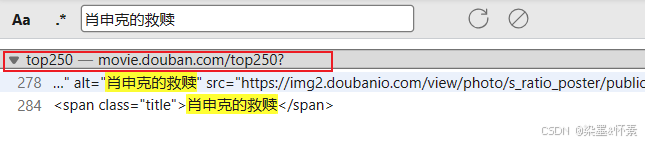
F12,点击网络,搜索首个电影肖申克的救赎,看看他的数据源是存储在html中,还是在动态的js中。
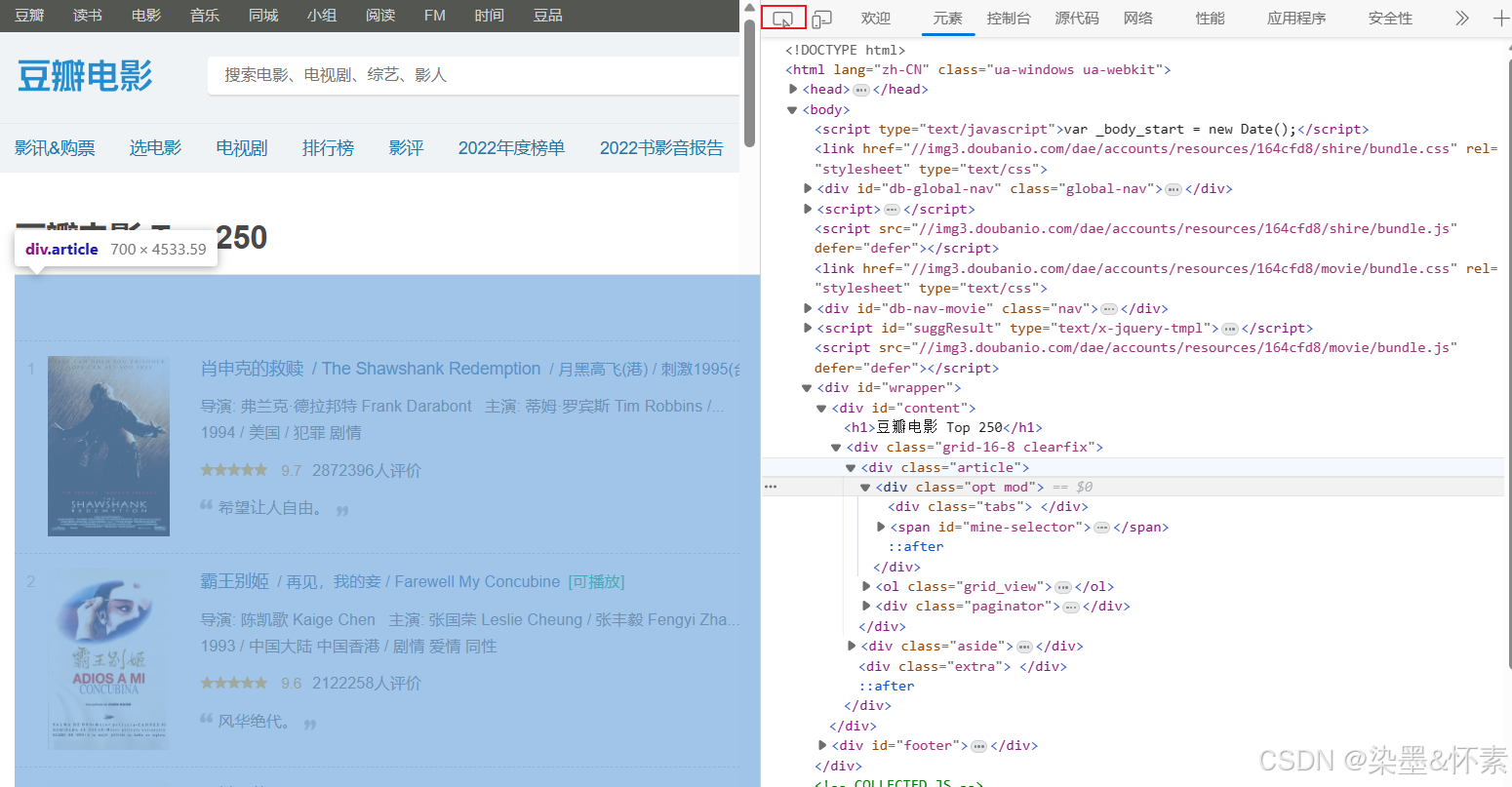
- 然后我们接着使用手动寻找到数据在那个html样式中,通过bs4库来解析整个网页
通过上述的首先我们要知道的是其网页是一个静态的网页https://movie.douban.com/top250?,拿到一个网站我们要先导好需要的库
import requests
from bs4 import BeautifulSoup
import pandas as pd
from fake_useragent import UserAgent
hearders = {
'User-Agent':UserAgent().random
}
url = 'https://movie.douban.com/top250?'
resp = requests(url=url,headers=headers)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text,'lxml')
print(soup.prettify())他会展示一个网页html的大致情况,我们也可以再在Pycharm的输出栏寻找肖申克的救赎,看看数据是否是在静态网页中。
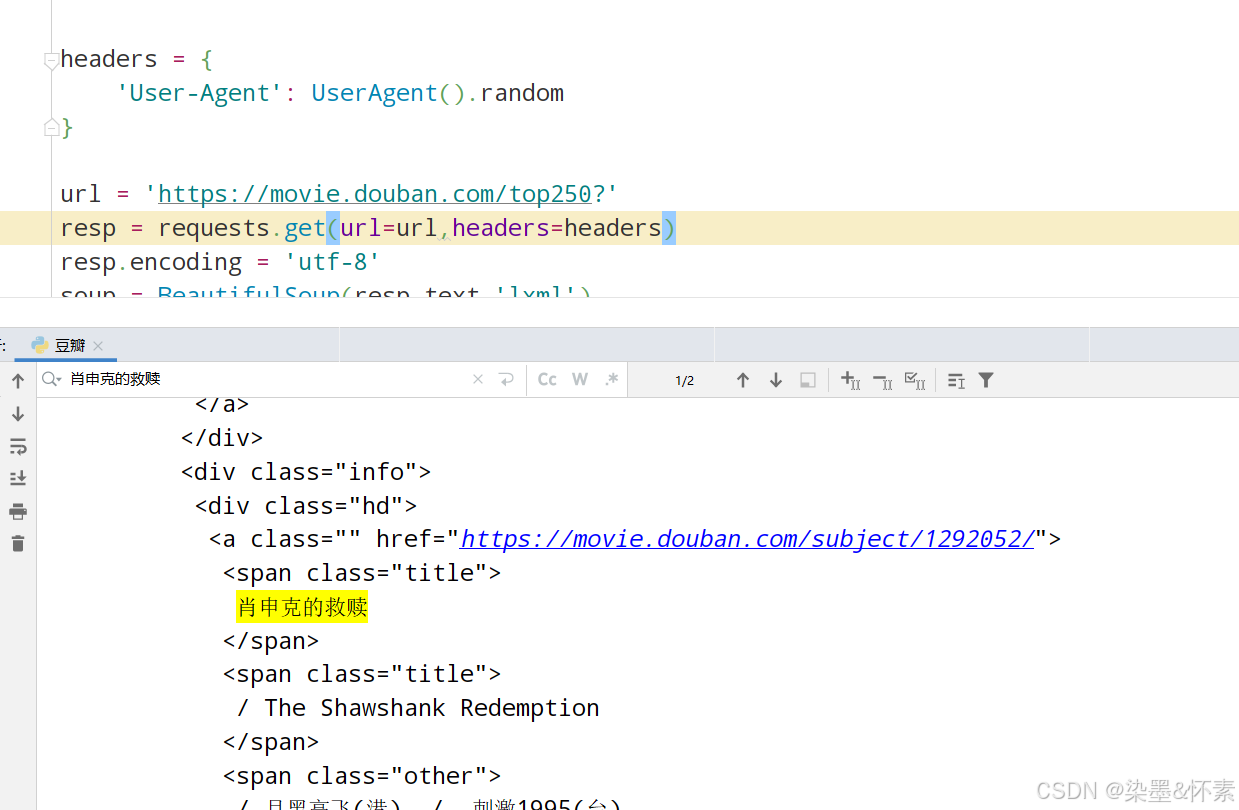
可以再次的确定数据确实是存放在html中的。
2、解析网页
-
我们先查看他的网页是否是有规律可循的,那样我们可以使用find_all将其更好的用解析出来。
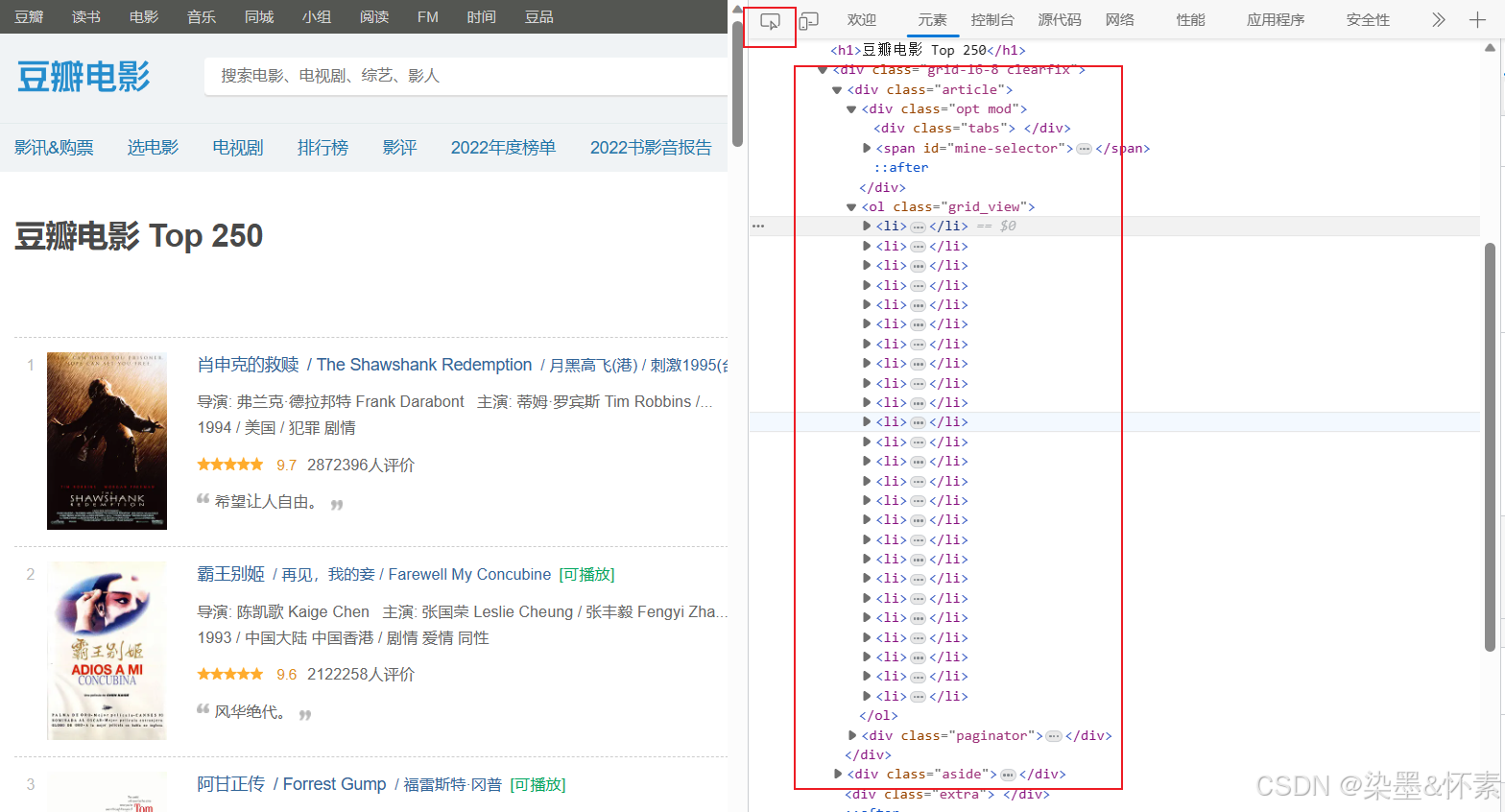
可以看到每个电影的数据都在一个li标签中,那么我们可以使用find_all函数来解析每一个电影的数据接着我们再细分下去会观察出在<div class='info'>中都是电影的具体数据,那么我们就可以使用上述的函数来找出所有电影的这个标签属性
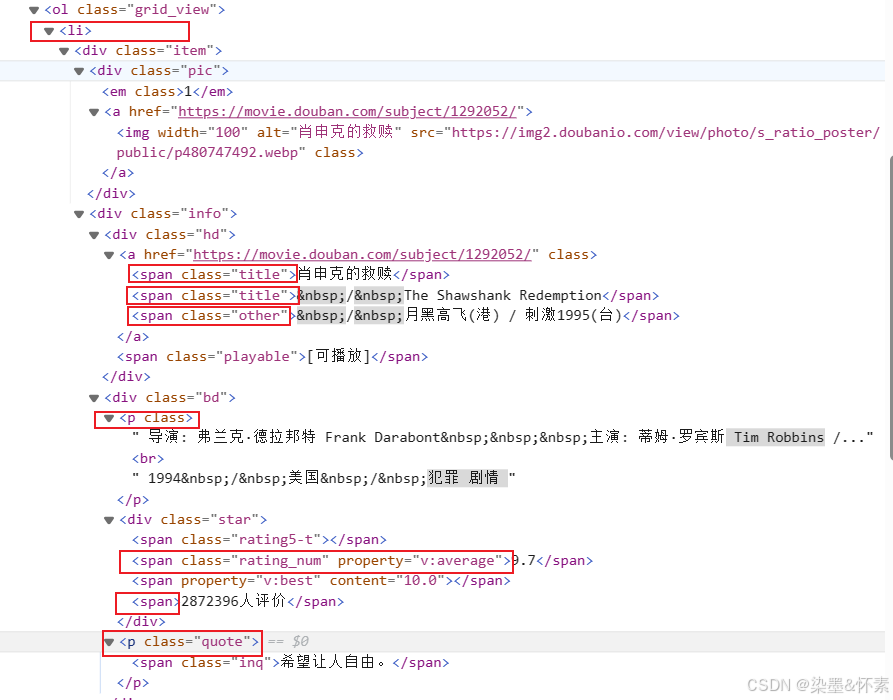
3、对任务上的字段进行分步爬取
import pandas as pd
mvs = soup.find_all('div',class_='info')
data = []
for mv in mvs:
dic={}
dic['电影名称'] = mv.find('span',class_='title').text.strip()
dic['评分'] = mv.find('span',class_='rating_num').text.strip()
dic['年份'] = mv.find('p',class_='').text.strip().split('\n')[-1].split('/')[0].replace(' ','')
dic['国家'] = mv.find('p',class_='').text.strip().split(':')[-1].split('/')[-2]
dic['类型'] = mv.find('p',class_='').text.strip().split(':')[-1].split('/')[-1]
dic['评价人数'] = mv.find('div',class_='star').text.strip().split('\n')[2].rstrip('人评价')
dic['导演中文名'] = mv.find('p',class_='').text.split('\n')[1].split(':')[1].split(' ')[1]
dic['导演英文名'] = mv.find('p',class_='').text.split('\n')[1].split(':')[1].split(' ')[2]
dic['主演'] = mv.find('p',class_='').text.strip().split(':')[-1].split('\n')[0].replace('/','')
try:
dic['代表句'] = mv.find('span', class_='inq').text.strip()
except:
dic['代表句'] = ""
data.append(dic)
data = pd.DataFrame(data)
data.to_csv('./data/moive.csv')dic['电影名称'] = mv.find('span',class_='title').text.strip()
其中
span标签的属性为title,然后用text提出其中的文本,再使用strip去除空格 下面的评分数据提取规则一样。
dic['年份'] = mv.find('p',class_='').text.strip().split('\n')[-1].split('/')[0].replace(' ','')
在
p标签中含有的爬取数据较多,查看网页源码中发现年份的数据在换行符后面可以将其先分为六步骤将数据剔除空格
mv.find('p',class_='').text.strip()得到如下格式:
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
使用split切割换行符
mv.find('p',class_='').text.strip().split('\n')得到如下格式:
['导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins ', '...\n\n1994 ', '?美国?', '?犯罪 剧情']
提取最后的一组后面
mv.find('p',class_='').text.strip().split('\n')[-1]得到如下格式:
1994 / 美国 / 犯罪 剧情
看到数据中还有其他符号分割,要使用split对其进行切片,取出列表中的第一个元素,去除空格。
mv.find('p',class_='').text.strip().split('\n')[-1].split('/')[0].replace(' ','')得到如下格式:
1994
-
其他的爬取分析和这个一样的思路,一步来解析。
但是上述的爬取也只是爬取了一页的数据,接下来我们再观察,点击下一页,url会发生什么的变化。在url最后会有一个数字递增
我们可以将其写入循环中来爬取
data = []
for i in range(0,226,25):
url = 'https://movie.douban.com/top250?start='+str(i)
resp = requests.get(url=url,headers=headers)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text,'lxml')
all=soup.find_all('div',class_='info')
for mv in all:
dic={}
dic['电影名称'] = mv.find('span',class_='title').text.strip()
dic['评分'] = mv.find('span',class_='rating_num').text.strip()
dic['年份'] = mv.find('p',class_='').text.strip().split('\n')[-1].split('/')[0].replace(' ','')
dic['国家'] = mv.find('p',class_='').text.strip().split(':')[-1].split('/')[-2]
dic['类型'] = mv.find('p',class_='').text.strip().split(':')[-1].split('/')[-1]
dic['评价人数'] = mv.find('div',class_='star').text.strip().split('\n')[2].rstrip('人评价')
dic['导演中文名'] = mv.find('p',class_='').text.split('\n')[1].split(':')[1].split(' ')[1]
dic['导演英文名'] = mv.find('p',class_='').text.split('\n')[1].split(':')[1].split(' ')[2]
dic['主演'] = mv.find('p',class_='').text.strip().split(':')[-1].split('\n')[0].replace('/','')
try:
dic['代表句'] = mv.find('span', class_='inq').text.strip()
except:
dic['代表句'] = ""
data.append(dic)
至此,我们实现了页面上所有的数据抓取工作。
完整代码如下
#encoding:gbk
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import pandas as pd
headers = {
'User-Agent': UserAgent().random
}
url = 'https://movie.douban.com/top250?'
resp = requests.get(url=url,headers=headers)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text,'lxml')
data = []
for i in range(0,226,25):
url = 'https://movie.douban.com/top250?start='+str(i)
resp = requests.get(url=url,headers=headers)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text,'lxml')
all=soup.find_all('div',class_='info')
for mv in all:
dic={}
dic['电影名称'] = mv.find('span',class_='title').text.strip()
dic['评分'] = mv.find('span',class_='rating_num').text.strip()
dic['年份'] = mv.find('p',class_='').text.strip().split('\n')[-1].split('/')[0].replace(' ','')
dic['国家'] = mv.find('p',class_='').text.strip().split(':')[-1].split('/')[-2]
dic['类型'] = mv.find('p',class_='').text.strip().split(':')[-1].split('/')[-1]
dic['评价人数'] = mv.find('div',class_='star').text.strip().split('\n')[2].rstrip('人评价')
dic['导演中文名'] = mv.find('p',class_='').text.split('\n')[1].split(':')[1].split(' ')[1]
dic['导演英文名'] = mv.find('p',class_='').text.split('\n')[1].split(':')[1].split(' ')[2]
dic['主演'] = mv.find('p',class_='').text.strip().split(':')[-1].split('\n')[0].replace('/','')
try:
dic['代表句'] = mv.find('span', class_='inq').text.strip()
except:
dic['代表句'] = ""
data.append(dic)
df = pd.DataFrame(data)
print(df.head())

















 1720
1720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









