






批量下载某B主视频
文章目录
- 批量下载某B主视频
- 前言
- 一、基本思路
- 二、确定遍历循环结构
- 三、基本思路中第12步
- 三、基本思路中第345步
- 总结
前言
上一篇讲了如何去获取标题和视频链接。这篇就跟大家讲一下如何去下载这些视频。本篇会以标题和 视频链接 为突破口,来寻找 视频的下载链接 藏在哪里。
注意:分上下两篇来写,请先看Python 爬虫实战——爬取视频(一)。
一、基本思路
- 第一步:根据上篇找到的视频链接,打开它,会转到一个新的页面。
- 第二步:新页面刚打开,会弹出登陆窗口,关闭它。
- 第三步:使用 find 方法查找到视频下载链接的位置。
- 第四步:使用_request.get()_ 方法去下载该视频。
- 第五步:用爬到的标题给它们命名保存。
二、确定遍历循环结构
这里要意识到,我们需要将视频的标题和视频链接一一对应起来。这样才能达到理想的效果。
代码如下:
# 遍历地址和标题,让其一一对应起来
i = 0
while i < len(right_url_list):
# 视频链接
all_url = url_list[i]
# 视频标题
dirty_name = title_list[i]
i += 1
这里我采用的是while循环结构,简单通俗易懂,便于后面的进一步处理。
注意:后面的所有代码都是在while循环结构下写的
三、基本思路中第12步
代码如下:
# 再一次爬取
driver.get(all_url)
# 等待网页打开
time.sleep(8)
# 页面打开会弹出一个登录窗口
close = driver.find_element(by=By.CSS_SELECTOR, value='.dy-account-close')
# 等登录窗口弹出来
time.sleep(5)
# 关闭弹出的登录窗口
close.click()
# 等待网页加载完
time.sleep(5)
这里就不多解释了,上一篇有相似的内容。
三、基本思路中第345步
代码如下:
# 获取视频的下载地址
dirty_downloaded_url = driver.find_element(by=By.CSS_SELECTOR, value='video source:nth-child(3)').get_attribute(
'src')
# 下载视频
response = requests.get(dirty_downloaded_url, stream=True)
total_downloaded = 0
chunk_size = 1024
with open(f'{dirty_name}.mp4', 'wb') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
print(f'下载完了!!{dirty_name}.mp4')
此处有两个知识点需要大家去学习一下(学完再看上面那几行代码轻轻松松):
一是 driver.find_element(by 相关的知识点。
二是 下载和保存视频的方式的相关的知识点。
总结
此程序是在Python 3.11.6 版本的环境下编写的,注意哦要不然程序可能运行不起来。
运行完上面的程序,就会得到下面的东西。

以上就是今天的全部内容分享,觉得有用的话欢迎点赞收藏哦!
Python经验分享
学好 Python 不论是用于就业还是做副业赚钱都不错,而且学好Python还能契合未来发展趋势——人工智能、机器学习、深度学习等。
小编是一名Python开发工程师,自己整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
小编为对Python感兴趣的小伙伴准备了以下籽料 !
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑培训的!
- 学习时间相对较短,学习内容更全面更集中
- 可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!
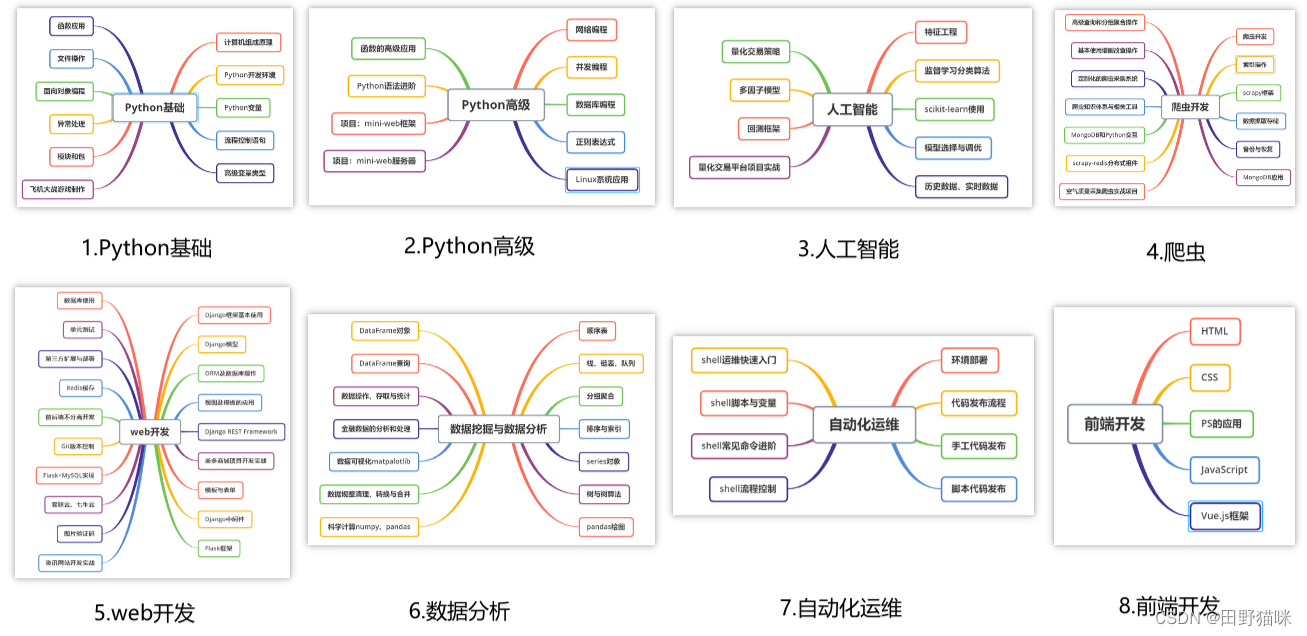
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
我已经上传至CSDN官方,如果需要可以扫描下方官方二维码免费获取【保证100%免费】

*今天的分享就到这里,喜欢且对你有所帮助的话,记得点赞关注哦~下回见 !














 8643
8643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









