






Nothing in this world can take the place of persistence. Talent will not: nothing is more common than unsuccessful men with talent. Genius will not; unrewarded genius is almost a proverb. Education will not: the world is full of educated derelicts. Persistence and determination alone are omnipotent.
Attention models 是NLP从业者工具箱中的一个强大工具。与LSTM类似,它们能够学习哪些词语在短语、句子、段落中最为重要。而且,attention models在缓解梯度消失问题上比LSTM表现得更为出色。Attention机制 vs. 传统方法: NMT的新时代已经了解到如何将注意力机制与LSTM结合,构建适用于机器翻译等任务的编码器-解码器模型。
本文将attention融合到transformers,理论部分我已经在这篇文章解释了(Transformer),更详细的部分可以参考原论文"Attention is All You Need"。
除了嵌入、位置编码、密集层和 residual connection,attention 是transformers的关键组成部分。
下面显示一张简化的图片:
Dot product attention
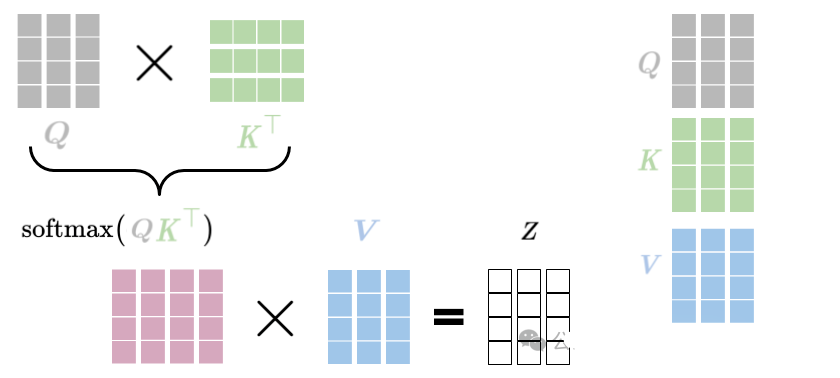
通过基本的dot product attention,可以捕获查询中的每个单词(嵌入)和键中的每个单词之间的交互。如果查询和关键字属于同一个句子,这就构成了bi-directional self-attention。然而,在某些情况下,只考虑当前单词之前的单词更合适。这种情况,特别是当查询和关键字来自同一个句子时,属于causal attention。
Dot product attention 直接用Q和K的点积。
Scaled dot product attention 通过除以 Key 维度的平方根来归一化点积,使其在数值上更加稳定,尤其是对于高维向量。
Follow the formula below:
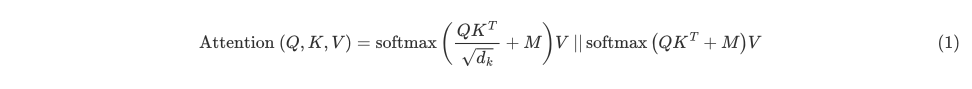
- Q is the matrix of queries
- K is the matrix of keys
- V is the matrix of values
- M is the optional mask you choose to apply
- dk is the dimension of the keys, which is used to scale everything down so the softmax doesn’t explode
# Dot Product Attention
def dot_product_attention(q, k, v, mask, scale=True):
"""
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Returns:
attention_output,attention_weights
"""
# Multiply q and k transposed.
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk with the square root of dk
if scale:
dk = tf.cast(tf.shape(k)[-1], tf.float32)
matmul_qk = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
matmul_qk += (1. - mask) * -1e9
# softmax is normalized on the last axis (seq_len_k) so that the scores add up to 1.
attention_weights = tf.keras.activations.softmax(matmul_qk)
# Multiply the attention weights by v
attention_output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return attention_output, attention_weights
q = np.array([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]]).astype(np.float32)
k = np.array([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]).astype(np.float32)
v = np.array([[0.0, 1.0, 0.0], [1.0, 0.0, 1.0]]).astype(np.float32)
mask = np.array([[1.0, 0.0], [1.0, 1.0]])
ou, atw = dot_product_attention(q, k, v, mask)
ou = np.around(ou, decimals=2)
atw = np.around(atw, decimals=2)
print(f"Output:\n {ou}")
print(f"\nAttention weigths:\n {atw}")
Output:
[[0. 1. 0. ]
[0.85 0.15 0.85]]
Attention weigths:
[[1. 0. ]
[0.15 0.85]]
For causal attention,可以在softmax函数的参数中添加一个掩码,如下所示:
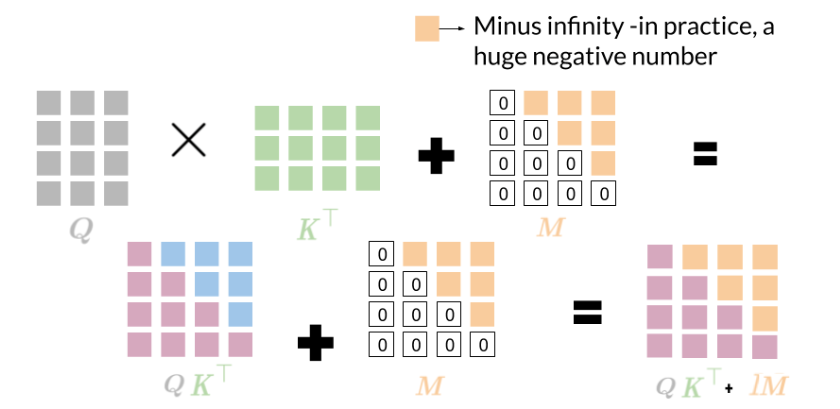
def causal_dot_product_attention(q, k, v, scale=True):
""" Masked dot product self attention.
Args:
q (numpy.ndarray): queries.
k (numpy.ndarray): keys.
v (numpy.ndarray): values.
Returns:
numpy.ndarray: masked dot product self attention tensor.
"""
# Size of the penultimate dimension of the query
mask_size = q.shape[-2]
mask = tf.experimental.numpy.tril(tf.ones((mask_size, mask_size)))
output, atw = dot_product_attention(q, k, v, mask, scale=scale)
return output
result = causal_dot_product_attention(q, k, v)
display_tensor(result, 'result')
Output
result shape: (2, 3)
[[0. 1. 0. ]
[0.8496746 0.15032543 0.8496746 ]]
Masking
在构建Transformer网络时,有两种类型的遮罩很有用:Padding mask 和 Look-ahead mask。两者都有助于 softmax 计算为输入中的单词赋予适当的权重。
- Padding mask
Padding Mask 是在 Transformer 模型中用于忽略填充部分(通常是 0)的一种掩码机制。当处理变长序列时,短序列会被填充至统一长度。
E.g.
[["Do", "you", "know", "when", "Jane", "is", "going", "to", "visit", "Africa"],
["Jane", "visits", "Africa", "in", "September" ],
["Exciting", "!"]
]
get vectorized as:
[[ 71, 121, 4, 56, 99, 2344, 345, 1284, 15],
[ 56, 1285, 15, 181, 545],
[ 87, 600]
]
set maximum length = 5
[[ 71, 121, 4, 56, 99],
[ 2344, 345, 1284, 15, 0],
[ 56, 1285, 15, 181, 545],
[ 87, 600, 0, 0, 0],
]
大于最大长度五的序列将被截断,并将零添加到截断的序列中以实现长度均匀。同样,对于短于最大长度的序列,也将添加零进行填充。
当这些向量通过 attention layers 时,0 通常会消失。然而,仍然希望network 只关注该向量中的前几个数字(由句子长度给出),这就是填充掩码派上用场的时候。首先需要定义一个boolean mask,指定哪些元素参与(1),哪些元素忽略(0),可以通过查看序列中的所有零来实现这一点。然后使用 mask 将向量的值(对应于初始向量中的零)设置为接近负无穷大(-1e9)。
def create_padding_mask(decoder_token_ids):
"""
Creates a matrix mask for the padding cells
Arguments:
decoder_token_ids (matrix like): matrix of size (n, m)
Returns:
mask (tf.Tensor): binary tensor of size (n, 1, m)
"""
seq = 1 - tf.cast(tf.math.equal(decoder_token_ids, 0), tf.float32)
return seq[:, tf.newaxis, :]
x = tf.constant([[7., 6., 0., 0., 0.], [1., 2., 3., 0., 0.], [3., 0., 0., 0., 0.]])
print(create_padding_mask(x))
tf.Tensor(
[[[1. 1. 0. 0. 0.]]
[[1. 1. 1. 0. 0.]]
[[1. 0. 0. 0. 0.]]], shape=(3, 1, 5), dtype=float32)
如果将(1-mask)乘以-1e9并将其添加到样本输入序列中,则零基本上被设置为负无穷大。
mask = create_padding_mask(x)
# Extend the dimension of x to match the dimension of the mask
x_extended = x[:, tf.newaxis, :]
print("Softmax of non-masked vectors:\n")
print(tf.keras.activations.softmax(x_extended))
print("\nSoftmax of masked vectors:\n")
print(tf.keras.activations.softmax(x_extended + (1 - mask) * -1.0e9))

- look-ahead mask
The look-ahead mask 帮助模型假装正确地预测了一部分输出,并查看在 without looking ahead 的情况下,模型是否可以正确地预测下一个输出。
例如,如果预期的正确输出是【1,2,3】,并且想看看给定模型正确预测了第一个值,它是否可以预测第二个值,可以屏蔽第二个和第三个值。所以你可以输入屏蔽序列【1,-1e9,-1e9】,看看它是否能生成【1,2,-1e9】。
def create_look_ahead_mask(sequence_length):
"""
Returns a lower triangular matrix filled with ones
Arguments:
sequence_length (int): matrix size
Returns:
mask (tf.Tensor): binary tensor of size (sequence_length, sequence_length)
"""
mask = tf.linalg.band_part(tf.ones((1, sequence_length, sequence_length)), -1, 0)
return mask
x = tf.random.uniform((1, 3))
temp = create_look_ahead_mask(x.shape[1])
temp
<tf.Tensor: shape=(1, 3, 3), dtype=float32, numpy=
array([[[1., 0., 0.],
[1., 1., 0.],
[1., 1., 1.]]], dtype=float32)>
Positional Encoding
在 seq2seq 任务中,数据的相对顺序具有非常重要的意义。当你训练序列模型(如RNN)时,输入是按顺序逐步传递给网络的,数据的顺序信息会自然嵌入到模型中。然而,使用多头注意力机制训练Transformer时,数据是一次性输入到模型中的。虽然这显著加快了训练速度,但模型本身并没有捕捉到数据的顺序信息。此时,**位置编码(Position Encoding)**的作用就显现出来了,它帮助Transformer保留输入数据的顺序信息。
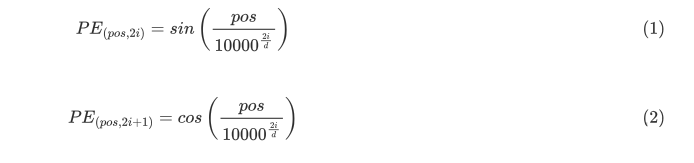
- d 是 word embedding 和 positional encoding 的维数.
- pos 是单词的位置.
- k 指位置编码中的每个不同维度,其中 i 等于 k // 2.
为了更好地理解位置编码,可以将它广义地看作是捕捉单词相对位置信息的一种特征。positional encoding 和 word embedding 相加后被一同输入到模型中。如果你仅通过在嵌入矩阵中硬编码位置,比如直接添加1或整数,这会扭曲嵌入的语义信息。相反,使用正弦和余弦函数生成的数值(范围在-1到1之间),可以避免嵌入的失真。positional encoding 不仅不会显著改变单词嵌入,还能为其加入位置信息。正弦和余弦函数的组合让 Transformer 能够关注输入数据的相对顺序,从而增强模型的性能。
def get_angles(position, k, d_model):
"""
Computes a positional encoding for a word
Arguments:
position (int): position of the word
k (int): refers to each of the different dimensions in the positional encodings, with i equal to k//2
d_model(int): the dimension of the word embedding and positional encoding
Returns:
_ (float): positional embedding value for the word
"""
i = k // 2
angle_rates = 1 / np.power(10000, (2 * i) / np.float32(d_model))
return position * angle_rates
def positional_encoding(positions, d):
"""
Precomputes a matrix with all the positional encodings
Arguments:
positions (int): Maximum number of positions to be encoded
d (int): Encoding size
Returns:
pos_encoding (tf.Tensor): A matrix of shape (1, position, d_model) with the positional encodings
"""
# initialize a matrix angle_rads of all the angles
angle_rads = get_angles(np.arange(positions)[:, np.newaxis],
np.arange(d)[np.newaxis, :],
d)
# apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
现在可以可视化 positional encodings.
pos_encoding = positional_encoding(128, 256)
plt.pcolormesh(pos_encoding[0], cmap='RdBu')
plt.xlabel('d')
plt.xlim((0, 256))
plt.ylabel('Position')
plt.colorbar()
plt.show()
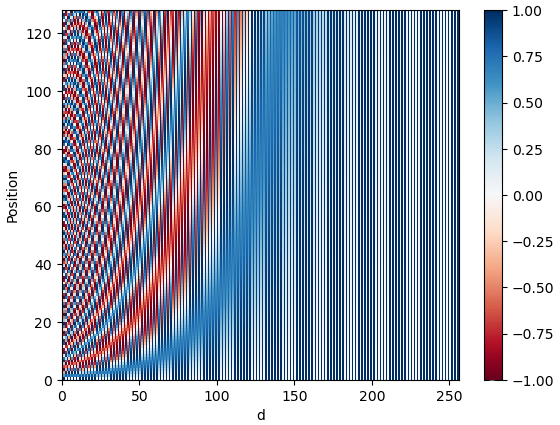
每一行代表一个位置编码——注意没有一行是相同的!现在已经为每个单词创建了唯一的位置编码。
Encoder
Transformer 编码器层将自注意力和卷积神经网络处理风格配对以提高训练速度,并将 K 和 V matrices 传递给解码器。
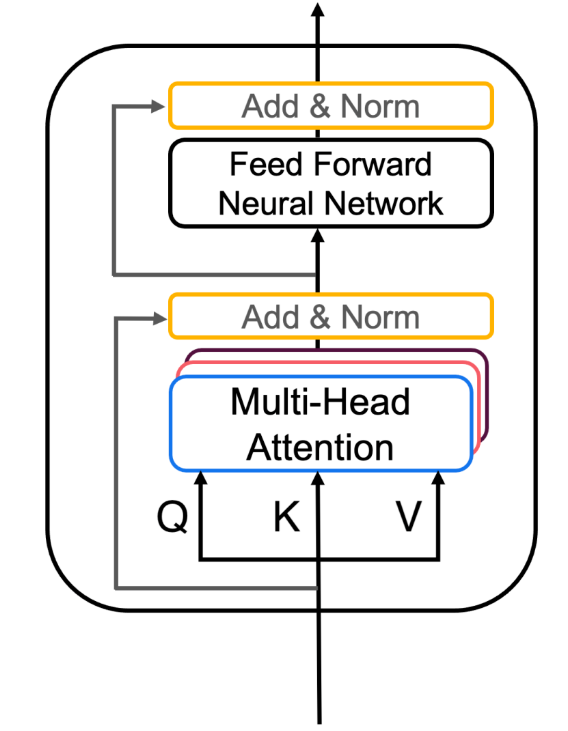
class EncoderLayer(tf.keras.layers.Layer):
"""
The encoder layer is composed by a multi-head self-attention mechanism,
followed by a simple, positionwise fully connected feed-forward network.
This architecture includes a residual connection around each of the two
sub-layers, followed by layer normalization.
"""
def __init__(self, embedding_dim, num_heads, fully_connected_dim,
dropout_rate=0.1, layernorm_eps=1e-6):
super(EncoderLayer, self).__init__()
self.mha = tf.keras.layers.MultiHeadAttention(
num_heads=num_heads,
key_dim=embedding_dim,
dropout=dropout_rate
)
self.ffn = FullyConnected(
embedding_dim=embedding_dim,
fully_connected_dim=fully_connected_dim
)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=layernorm_eps)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=layernorm_eps)
self.dropout_ffn = tf.keras.layers.Dropout(dropout_rate)
def call(self, x, training, mask):
"""
Forward pass for the Encoder Layer
Returns:
encoder_layer_out (tf.Tensor): Tensor of shape (batch_size, input_seq_len, embedding_dim)
"""
# Dropout is added by Keras automatically if the dropout parameter is non-zero during training
self_mha_output = self.mha(x, x, x, mask) # Self attention (batch_size, input_seq_len, fully_connected_dim)
# skip connection
# apply layer normalization on sum of the input and the attention output to get the
# output of the multi-head attention layer
skip_x_attention = self.layernorm1(x + self_mha_output) # (batch_size, input_seq_len, fully_connected_dim)
# pass the output of the multi-head attention layer through a ffn
ffn_output = self.ffn(skip_x_attention) # (batch_size, input_seq_len, fully_connected_dim)
# apply dropout layer to ffn output during training
ffn_output = self.dropout_ffn(ffn_output, training=training)
# apply layer normalization on sum of the output from multi-head attention (skip connection) and ffn output
# to get the output of the encoder layer
encoder_layer_out = self.layernorm2(skip_x_attention + ffn_output) # (batch_size, input_seq_len, embedding_dim)
return encoder_layer_out
class Encoder(tf.keras.layers.Layer):
"""
The entire Encoder starts by passing the input to an embedding layer
and using positional encoding to then pass the output through a stack of
encoder Layers
"""
def __init__(self, num_layers, embedding_dim, num_heads, fully_connected_dim, input_vocab_size,
maximum_position_encoding, dropout_rate=0.1, layernorm_eps=1e-6):
super(Encoder, self).__init__()
self.embedding_dim = embedding_dim
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(input_vocab_size, self.embedding_dim)
self.pos_encoding = positional_encoding(maximum_position_encoding,
self.embedding_dim)
self.enc_layers = [EncoderLayer(embedding_dim=self.embedding_dim,
num_heads=num_heads,
fully_connected_dim=fully_connected_dim,
dropout_rate=dropout_rate,
layernorm_eps=layernorm_eps)
for _ in range(self.num_layers)]
self.dropout = tf.keras.layers.Dropout(dropout_rate)
def call(self, x, training, mask):
"""
Forward pass for the Encoder
Returns:
x (tf.Tensor): Tensor of shape (batch_size, seq_len, embedding dim)
"""
seq_len = tf.shape(x)[1]
# Pass input through the Embedding layer
x = self.embedding(x) # (batch_size, input_seq_len, embedding_dim)
# Scale embedding by multiplying it by the square root of the embedding dimension
x *= tf.math.sqrt(tf.cast(self.embedding_dim, tf.float32))
# Add the position encoding to embedding
x += self.pos_encoding[:, :seq_len, :]
# Pass the encoded embedding through a dropout layer
x = self.dropout(x, training=training)
# Pass the output through the stack of encoding layers
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x # (batch_size, input_seq_len, embedding_dim)
Decoder
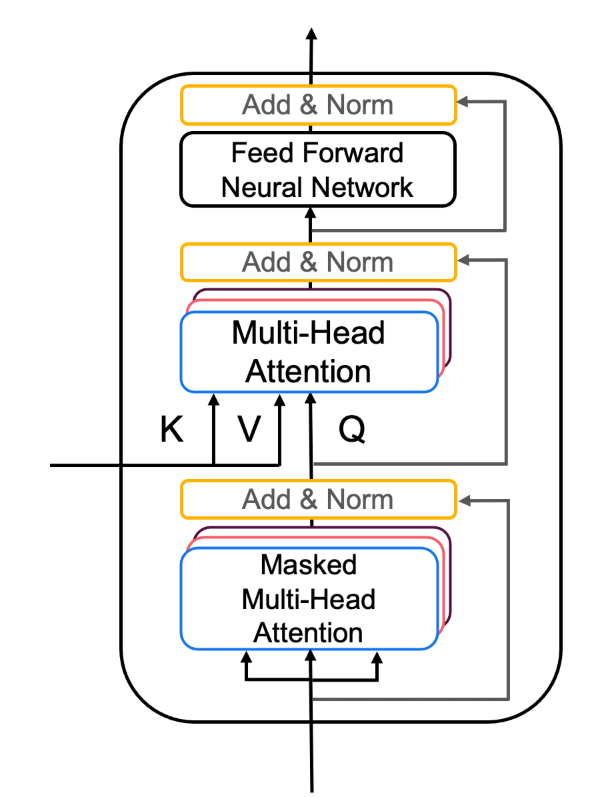
class DecoderLayer(tf.keras.layers.Layer):
"""
The decoder layer is composed by two multi-head attention blocks,
one that takes the new input and uses self-attention, and the other
one that combines it with the output of the encoder, followed by a
fully connected block.
"""
def __init__(self, embedding_dim, num_heads, fully_connected_dim, dropout_rate=0.1, layernorm_eps=1e-6):
super(DecoderLayer, self).__init__()
self.mha1 = tf.keras.layers.MultiHeadAttention(
num_heads=num_heads,
key_dim=embedding_dim,
dropout=dropout_rate
)
self.mha2 = tf.keras.layers.MultiHeadAttention(
num_heads=num_heads,
key_dim=embedding_dim,
dropout=dropout_rate
)
self.ffn = FullyConnected(
embedding_dim=embedding_dim,
fully_connected_dim=fully_connected_dim
)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=layernorm_eps)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=layernorm_eps)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=layernorm_eps)
self.dropout_ffn = tf.keras.layers.Dropout(dropout_rate)
def call(self, x, enc_output, training, look_ahead_mask, padding_mask):
"""
Forward pass for the Decoder Layer
"""
# BLOCK 1
# calculate self-attention and return attention scores as attn_weights_block1.
# Dropout will be applied during training.
mult_attn_out1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask, return_attention_scores=True)
# apply layer normalization (layernorm1) to the sum of the attention output and the input
Q1 = self.layernorm1(mult_attn_out1 + x)
# BLOCK 2
# calculate self-attention using the Q from the first block and K and V from the encoder output.
# Dropout will be applied during training
# Return attention scores as attn_weights_block2
mult_attn_out2, attn_weights_block2 = self.mha2(Q1, enc_output, enc_output, padding_mask, return_attention_scores=True)
# apply layer normalization (layernorm2) to the sum of the attention output and the Q from the first block
mult_attn_out2 = self.layernorm2(mult_attn_out2 + Q1)
# BLOCK 3
# pass the output of the second block through a ffn
ffn_output = self.ffn(mult_attn_out2)
# apply a dropout layer to the ffn output
ffn_output = self.dropout_ffn(ffn_output, training=training)
# apply layer normalization (layernorm3) to the sum of the ffn output and the output of the second block
out3 = self.layernorm3(ffn_output + mult_attn_out2)
return out3, attn_weights_block1, attn_weights_block2
class Decoder(tf.keras.layers.Layer):
"""
The entire Encoder starts by passing the target input to an embedding layer
and using positional encoding to then pass the output through a stack of
decoder Layers
"""
def __init__(self, num_layers, embedding_dim, num_heads, fully_connected_dim, target_vocab_size,
maximum_position_encoding, dropout_rate=0.1, layernorm_eps=1e-6):
super(Decoder, self).__init__()
self.embedding_dim = embedding_dim
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(target_vocab_size, self.embedding_dim)
self.pos_encoding = positional_encoding(maximum_position_encoding, self.embedding_dim)
self.dec_layers = [DecoderLayer(embedding_dim=self.embedding_dim,
num_heads=num_heads,
fully_connected_dim=fully_connected_dim,
dropout_rate=dropout_rate,
layernorm_eps=layernorm_eps)
for _ in range(self.num_layers)]
self.dropout = tf.keras.layers.Dropout(dropout_rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
"""
Forward pass for the Decoder
"""
seq_len = tf.shape(x)[1]
attention_weights = {}
# create word embeddings
x = self.embedding(x)
# scale embeddings by multiplying by the square root of their dimension
x *= tf.math.sqrt(tf.cast(self.embedding_dim, tf.float32))
# add positional encodings to word embedding
x += self.pos_encoding[:, :seq_len, :]
# apply a dropout layer to x
x = self.dropout(x, training=training)
# use a for loop to pass x through a stack of decoder layers and update attention_weights
for i in range(self.num_layers):
# pass x and the encoder output through a stack of decoder layers and save the attention weights
x, block1, block2 = self.dec_layers[i](x, enc_output, training, look_ahead_mask, padding_mask)
# update attention_weights dictionary with the attention weights of block 1 and block 2
attention_weights['decoder_layer{}_block1_self_att'.format(i+1)] = block1
attention_weights['decoder_layer{}_block2_decenc_att'.format(i+1)] = block2
return x, attention_weights
后续搭建 Transformer 的代码就不展示了,有兴趣可私聊获取代码。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









