






01
能像真人一样聊天的AI
“我第一次来直播的发布会,有点紧张。”当OpenAI前沿研究部门主管马克(Mark Chen)通过手机对ChatGPT说话时,ChatGPT回答,“要不你深呼吸一下?”
“好的,我深呼吸。”
“慢一点,马克,你不是吸尘器。”

——这是发生在GPT-4o发布会直播中的一幕,通过直播,OpenAI全方位展示了接入GPT-4o后,ChatGPT是如何识别用户语音中的情绪的。此后,马克还示范了ChatGPT如何用不同的声音朗读AI生成的故事,包括超级戏剧化的朗诵、机器人音调,甚至唱歌。
作为全球AI领域的风向标,OpenAI发布的GPT-4o并没有在模型能力上有巨大突破,但是其展现的融合连贯的交互方式,却让人们看到了多模态技术迭代下,人类与AI交互的方向,而从交互效果来看,GPT-4o不再是僵硬的语音聊天工具,更像一个越来越接近人类的新“物种”。
GPT-4o之所以能够让人机语音交互如此逼真,很大原因在于其可以在短至 232 毫秒的时间内响应音频输入,平均为320毫秒,与人类的响应时间相似。在GPT-4o之前,ChatGPT语音模式对话的平均延迟为 2.8 秒 (GPT-3.5) 和 5.4 秒 (GPT-4)。而在技术的不断迭代下,国内以海螺AI为代表的大模型语音延迟同样能做到300毫秒左右,这正好是人们说一个字的时间,从而让用户在同AI聊天的过程中不会有任何违和感。
事实上,除“海螺AI”外,文心一言、通义、豆包等国内AI大模型App均将实时通话打造成基本功能,“实时通话”也继长文本后成为国内AI大模型最新内卷的赛道。
02
打电话给AI聊天
大模型对话App最初其实就支持语音输入,不过早期其实是语音和文字的互转,并不能实现类似真人通话般的语聊,而在多模态技术持续迭代下,语音模型和语言模型已经能够被整合到对话大模型中,因为声音和语言模型都是 Transformer 的模型,本质上就是把声音模型的incoder(编码器),转换成一个语言模型,多模态本身实现图片识别也是这样操作的,对于拥有深厚技术实力的大模型厂商而言,这样的操作其实并不麻烦,不过各家实时通话功能具体设计并不相同。
以最完善的海螺AI为例,用户在拨通与AI的电话后,不仅可以设置语速(设置完后,下次启动生效),更提供了三十余种预设声音可供选择,用户还可以点选“克隆我的声音”从而打造独一无二的AI声音,进而充分满足用户对差异化的需求。
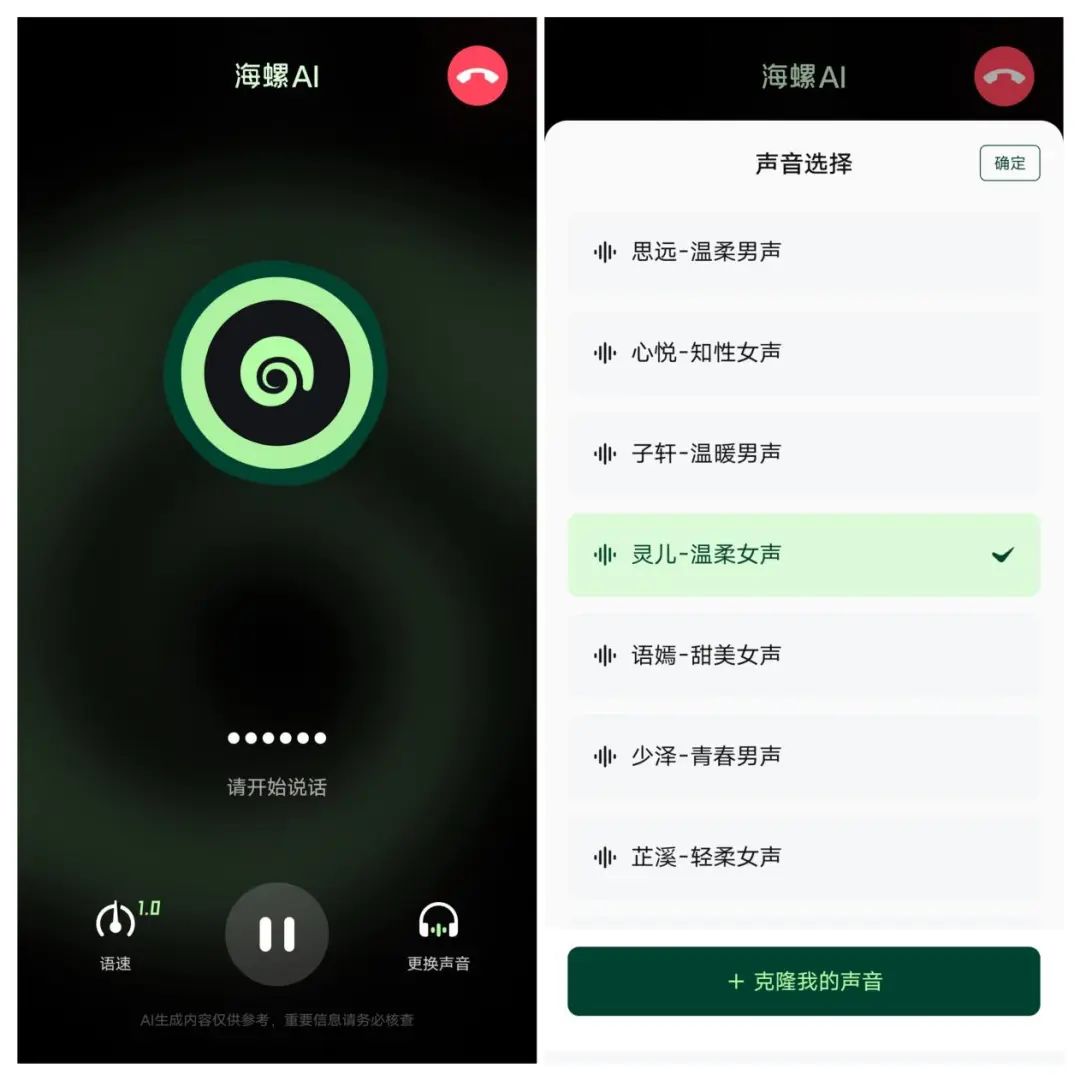
相较而言,文心一言App目前仅提供“洛天依”一个虚拟角色供用户对话,而通义App也只是简单地提供了二十余种预设声音供用户选择,从语音交互体验的角度看,海螺AI明显在个性化设置上明显更胜一筹。
在实际测试中我们分别让62岁的老年人和10岁小朋友分别用重庆话和普通话问明天天气,对于这样清楚的“指令式”对话,海螺AI、通义App和文心一言均能清楚地进行表达。
有趣的是通义App在接通电话后,如果用户长时间不说话,还会用语音的方式主动开启一些话题,甚至单方面地给用户分享一些它学到的知识、了解的趣闻,海螺AI则会在接通电话后礼貌性地问一句:“喂,你好吖,今天怎么样?”来开启话题,而文心一言也仅会在接通电话最开始来一句:“喂,天依来了,有什么可以问我?”,后续即便沉默许久,也不会像通义App一样主动挑起话头。
同时,三款大模型在通化时还无法实现GPT-4o一样对于用户“情绪”的理解,无论是小孩因为紧张而声音抖动,或老年人较慢的语速,三款AI大模型的语音助手都没能识别出来,这样的设计一定程度上避免了环境声的干扰,但离“AI读懂人类情绪”的目标恐怕还是有些距离。
有意思的是除了手机App外,海螺AI的PC网页版也支持语音通话,用户用PC浏览器访问hailuoai.com后,点击右上角“通话”按钮即可在PC上开启通话模式,这也算是尝鲜的存在了,毕竟在PC模式下,本身输入效率足够,这样的PC通话,更多时候适用于一些特定人群。
从目前的使用体验来看,在同AI大模型于语音聊天时,更多时候还是用于天气查询、信息检索等“问答式”聊天,虽然通义App会主动挑起话题让聊天继续下去,但海螺AI和文心一言更多时候还是以用户主动聊天为主。
03
多模态体验,让AI识图
识图可以说是多模态基础功能之一,可谁能想到如此简单的功能却成为三款AI大模型迈不过的坎。《电脑报》此次测试选择了一张科技圈三大巨头在一场峰会上的合影让AI大模型识别,原本以为识别家喻户晓的三人对AI大模型而言应该是送分题,没想到却成为三家AI的“送命题”。
当下AI大模型对多模态内容的支持非常方便,直接点击对话窗口的“+”号,即可点选上传图片,然后发送“介绍图片中的三个人”作为指令。
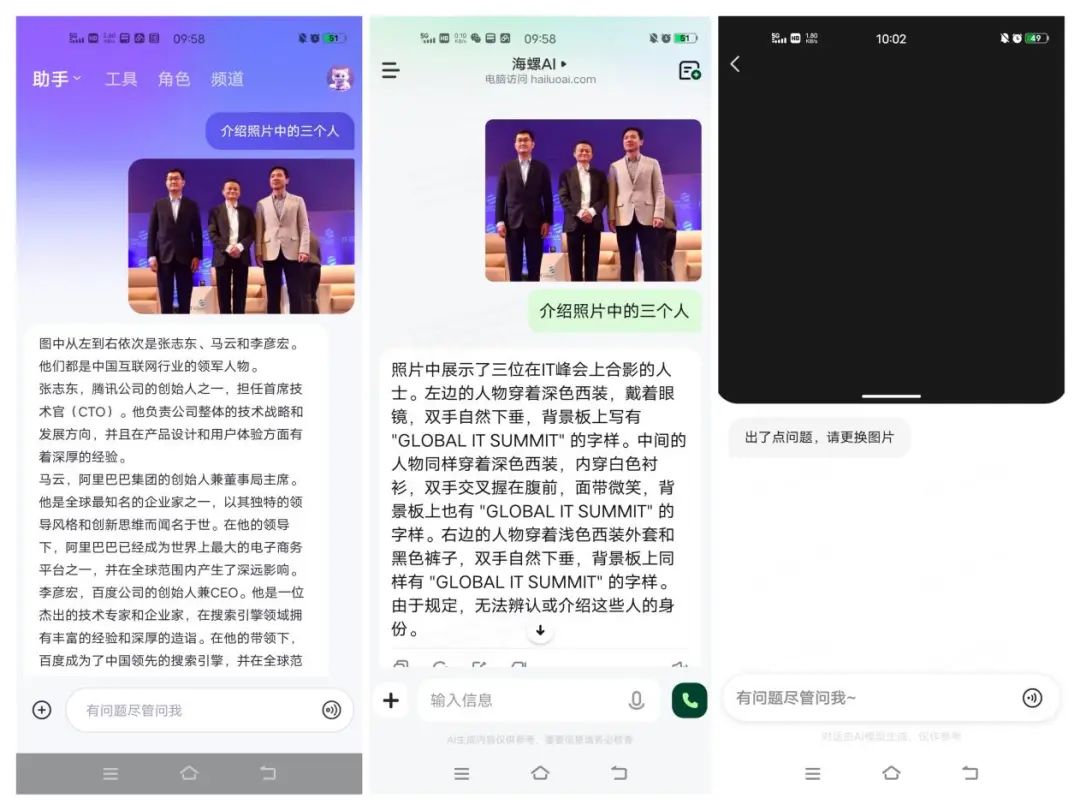
测试结果多少有些尴尬,通义App虽然成功地认出了自己的“老板”马云和百度李彦宏,但腾讯的马化腾却错认为张志东,而海螺AI这个后起之秀非常有意思,将后面的背景板及隐约可见的文字进行了一番解读,但到人物介绍时却直接来了一个“无法辨认或介绍这些人的身份”,更过分的则是文心一言,直接给出“出了点问题,请更换图片”的提示。
接下来笔者选择了一张第五套人民币二十元钱上的桂林山水图来让AI大模型解读,并以“描述一下这张图片”为指令,同时考校AI的识别和表述能力。
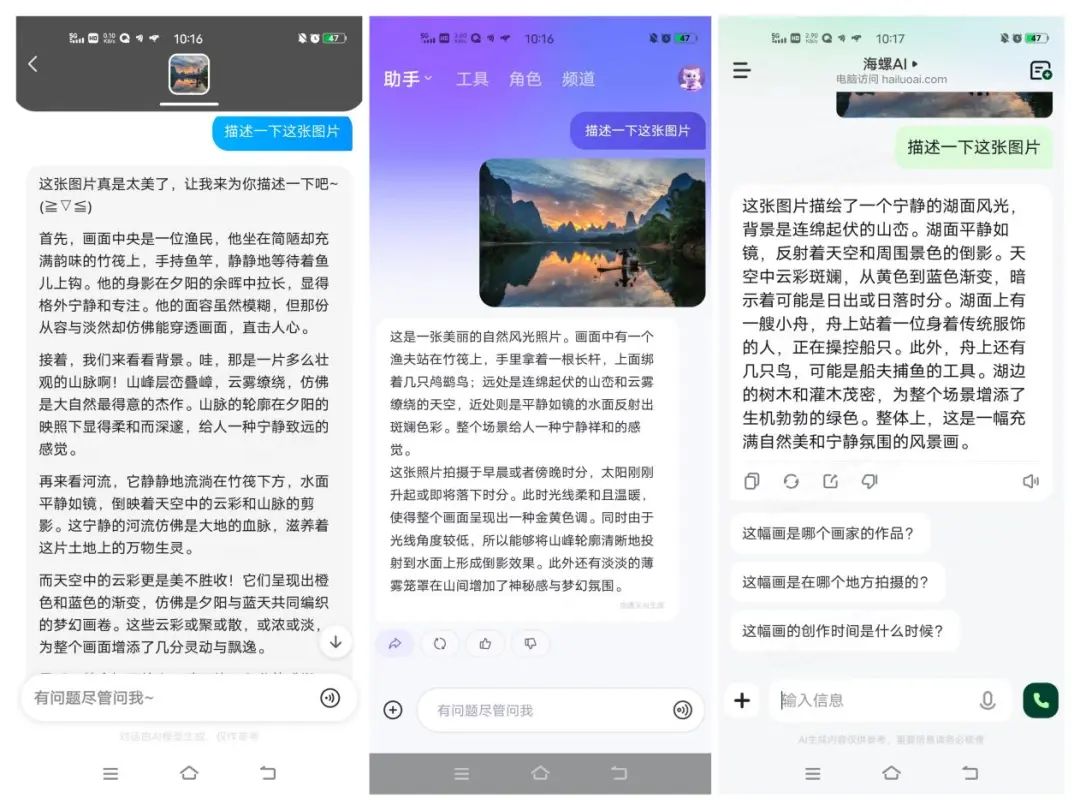
从测试结果来看,三款AI大模型在景物识别上均没有出现问题,同时,在概括图片内容的同时,均在文末给出引导性问题,让用户展开多轮对话,但在具体表述上,文心一言用词、行文的能力明显更优一些。
接下来我们尝试多轮对话,直接问询AI“这幅画是在哪个地方拍摄的”,原本以为如此知名的景物图应该很容易被识别出来,但三款AI大模型一本正经地推测一番后均给出“无法判定”的答案。显然,AI多模态应用能力在现实和理想间还是有一定距离的。
04
点评:端侧AI才是真正目标
如果说AI大模型内卷参数是为了获得更准确的数据,从而给用户更完整的答案,那内卷语音及多模态,更多是以端侧落地为目的。
我们现在常见的“Siri”“小爱同学”等语音助理,以及GPT-3.5等上代大模型对语音对话的处理能力慢,至少需要“音频转文本将人的指令转化为文本输入”“机器文本理解并输出文本”“文本转语音‘说’给用户”三个步骤,反应时间和处理速度延迟感强。这样的模式不仅慢,而且会遗漏许多语音中的信息熵值,也会影响对话的连贯性。GPT-4o们之所以这么快,离不开全新的神经网络处理流程。

而目前,三款AI大模型的实时语音聊天功能,更像是为将来智能手机、智能汽车、智能家居的语音助手“打样”,通过不断地优化和第三方匹配,进而让更多B端企业愿意在其智能操作系统中嵌入语音对话大模型,从而让“听”和“说”成为主流的人机交互方式。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









