






多模态大型模型(MLMs)正成为重要的研究焦点,它们结合了强大的大型语言模型和多模态学习,以在不同数据模态上执行复杂任务。本综述探讨了MLMs的最新发展和挑战,强调了它们在实现人工通用智能和作为通往世界模型的途径方面的潜力。我们提供了关键技术(如多模态思维链(M-COT)、多模态指令调整(M-IT)和多模态上下文学习(M-ICL))的概览。此外,我们讨论了多模态模型的基础和特定技术,突出了它们的应用、输入/输出模态和设计特点。尽管取得了显著进步,但开发统一的多模态模型仍然难以捉摸。我们讨论了整合3D生成和具身智能以增强世界模拟能力,并提出纳入外部规则系统以改进推理和决策制定。最后,我们概述了未来的研究方向,以解决这些挑战并推进该领域。
关键词 —— 多模态大型模型,基于规则的系统,具身智能,世界模拟器
我们翻译解读最新论文:从高效多模态大模型到世界模型综述,文末有论文链接。
I. 多模态模型和世界模型的发展现状
A. 世界模型
世界模型目前是人工智能领域最热门的研究方向之一。从OpenAI到Meta,主要的AI公司都在努力开发世界模型。世界模型的概念可以追溯到强化学习和机器人控制领域。传统上,强化学习算法依赖于智能体在真实环境中通过试错学习,这不仅成本高昂,有时甚至不可行。为了克服这些限制,研究人员开始探索在内部环境中进行模拟和学习的方法。Jurgen等人[1]描述了一种使用生成性循环神经网络(RNN)通过无监督环境快速训练的方法,以压缩时空表示并模拟常见的强化学习环境。Jurgen等人将这称为世界模型。在AI研究中,提出世界模型的目的是为了区分这个方向和另一个研究重点:智能体。
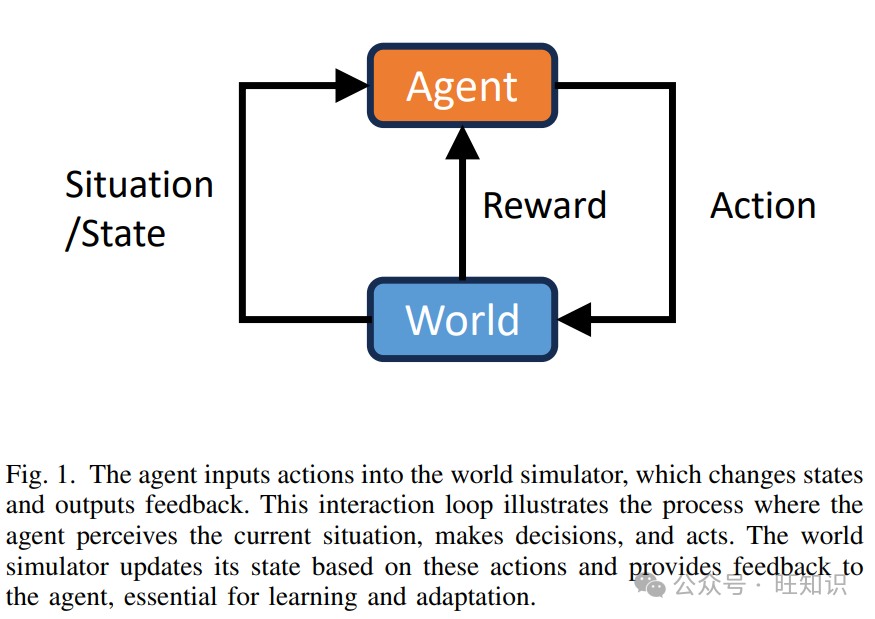
图1. 智能体将动作输入到世界模拟器,模拟器改变状态并输出反馈。这个交互循环说明了智能体如何感知当前情境、做出决策并采取行动。世界模拟器根据这些动作更新其状态,并向智能体提供反馈,这对于学习和适应至关重要。
B. 通往世界模型的途径
目前,发展世界模型主要有两种途径:自回归方法和JEPA(联合嵌入预测架构)方法。自回归模型在生成领域占有重要地位,其著名代表包括GPT系列和Sora。这些模型基于Transformer架构,逐步生成数据,每个输出依赖于之前的隐状态。这种增量式生成使模型能够捕捉上下文信息,产生连贯和逻辑性强的序列。自回归模型具有强大的上下文理解能力,并且易于训练,因此在世界建模领域确立了其主导地位。通过在生成过程中利用之前生成的内容,自回归模型在理解和保持上下文一致性方面表现出熟练,从而产生更连贯和有意义的输出。自回归模型的训练过程相对简单,涉及基于已知序列数据的逐步预测和优化,这有助于在大规模数据集上训练时取得令人称赞的性能。尽管自回归模型在自然语言处理任务上表现出色,通过预训练和微调生成高质量的文本段落,但批评者认为这些模型缺乏现实世界的常识,被大量信息所遮蔽。例如,婴儿通过观察世界,学习世界如何运作,并且能够预测结果,与大型语言模型所需的大量训练数据相比,婴儿的实践要少得多。为了应对这一挑战,Meta提出了JEPA框架。JEPA的核心思想是分层规划,这是一种特别适合处理复杂任务和大规模问题的决策和控制方法。这种方法包括将问题分解为多个层次,每个层次处理不同抽象级别的子任务,简化了整个问题的解决过程。LeCun用一个例子来说明这一点:要从纽约旅行到北京,一个人必须首先到达机场,然后乘飞机到北京,整体的成本函数代表了从纽约到北京的距离。解决这个问题涉及将任务分解为毫秒级控制,找到使预测成本最小化的行动序列。他认为所有复杂任务都可以通过这种分层方法完成,分层规划是最大的挑战。
JEPA模型通过一系列编码器提取世界状态的抽象表示,并使用不同层次的世界模型预测器预测不同时间尺度上的各个状态。受人脑以分层方式理解和对环境做出反应的能力的启发,JEPA采用分层架构将复杂任务分解为多个层次,每个层次处理不同抽象级别的子任务。这种方法使JEPA能够高效地捕捉和预测复杂动态系统的变化,提高了模型处理长时间跨度和多尺度数据的能力。其独特的分层预测机制不仅提高了对环境状态的理解和预测准确性,而且在处理大规模、多样化数据时增加了适应性和鲁棒性,在许多实际应用中展现了显著的优势。总结起来,我们可以将通往世界模型的途径总结为两个方面:规则和数据驱动。
C. 多模态模型
无论通往世界模型的途径如何,多模态模型都是不可或缺的一部分。多模态模型指的是能够处理和理解来自不同模态的数据,如图像、文本、音频和视频的机器学习模型。人类与现实世界的互动涉及多种模态的信息,包括语言、视觉和音频。因此,世界模型必须能够处理和理解多种形式的数据,这意味着它们必须具备多模态理解能力。此外,世界模型模拟动态环境变化以进行预测和决策,需要强大的多模态生成能力。简单来说,世界是多模态的,世界模拟器必须能够接受和生成多模态信息。本质上,世界模型是通用模型(General-Purpose Models)。多模态模型的研究可以广泛地分为几种技术方法:对齐、融合、自监督和噪声添加。基于对齐的方法将不同模态的数据映射到一个共同的特征空间进行统一处理。融合方法在不同模型层整合多模态数据,充分利用每种模态的信息。自监督技术在未标记数据上预训练模型,提高各种任务的性能。噪声添加通过在数据中引入噪声来增强模型的鲁棒性和泛化能力。结合这些技术使多模态模型能够展示出在处理复杂现实世界数据方面的强能力。它们能够理解并生成多模态数据,模拟和预测环境变化,并帮助智能体做出更精确有效的决策。因此,多模态模型在发展世界模型、标志着通往通用人工智能(General AI)的关键步骤中发挥着至关重要的作用。以下各节将详细介绍多模态模型的技术路线。
D. 本文的结构
第2节,我们将介绍基础架构的基本技术。第3节,我们将介绍模型架构的优化技术。第4节涵盖了多模态模型的特定技术。第5节比较和对比了不同途径的多模态模型。最后,第6节概述了多模态模型成为世界模型的潜在发展路径。
II. 多模态模型的基本技术
在本章中,我们将介绍多模态模型的基本技术,这些技术通常用于规则驱动和数据驱动的两种途径,从底层架构到块架构。
A. Transformer及其挑战者
Transformer架构目前是最受欢迎的深度学习模型架构之一,特别适用于自然语言处理(NLP)和计算机视觉(CV)任务。Transformer是一种设计用于处理序列数据的深度学习模型,采用注意力机制来模拟序列内的长距离依赖关系。与传统的递归神经网络(RNN)不同,Transformer不依赖于序列的顺序,利用自注意力同时关注序列中的所有位置,从而大大提高了并行计算效率。Transformer由编码器和解码器组成,编码器将输入序列映射到连续的表示空间,解码器基于这个表示生成输出序列。编码器和解码器的每一层都包括多头自注意力机制和前馈神经网络,并通过残差连接和层归一化进行稳定。由于其高效的并行计算和强大的表示学习能力,Transformer在自然语言处理和其他需要序列数据处理的任务中取得了显著的成功。
然而,Transformer的自注意力机制在处理长序列时具有高计算复杂度,限制了其在某些应用中的效率。为了解决这个问题,研究人员提出了各种方法来挑战Transformer架构。线性注意力简化了自注意力的计算,将其时间和空间复杂度从O(N^2)降低到O(N)。关键模型包括Performer、Linformer和Linear Transformers。这些模型可以高效处理长序列数据,减少计算资源消耗。此外,分组查询注意力和多查询注意力是重要的注意力机制变体。前者通过在查询头组之间共享一组键和值来平衡多头和多查询注意力,而后者通过为所有查询头共享相同的键和值来简化计算,从而提高效率。分组查询注意力和多查询注意力在推理期间减少键值对的大小,显著提高吞吐量。多查询注意力在多个头之间共享键值对,实现了30-40%的吞吐量降低。分组查询注意力将查询分组,在组内共享键值对,实现了与多查询注意力在效率和性能方面相当的结果。MQA和GQA在知名的开源大型语言模型Llama-2和Llama-3中使用。在块级别,优化方法包括紧凑架构,它减少层数和参数以实现紧凑的模型结构,降低计算成本;剪枝,通过剪枝技术减少冗余参数,提高计算效率;知识蒸馏,从大型教师模型中提取知识并应用到小型学生模型,显著降低模型复杂性和计算资源需求;量化,将模型参数从高精度浮点数转换为低精度格式,进一步降低计算和存储成本。这些优化方法共同旨在提高Transformer的效率和性能,使其能够更高效地在多模态任务中处理和整合不同模态的数据。
此外,还有挑战Transformer模型的架构方法,如门控卷积或门控MLP、递归模型、状态空间模型(SSMs)、H3、RWKV、Mega、Yan、JEPA,以及值得注意的Mamba和Mamba 2。门控卷积在卷积神经网络中引入门控机制,增强了模型捕获局部和长距离依赖的能力,同时降低计算负载。递归模型如LSTM和GRU通过其递归结构捕获序列中的时间依赖性,克服了传统RNN中的梯度消失问题。状态空间模型明确地模拟系统状态和观测之间的关系,为处理时间序列数据提供了灵活的框架,包括状态空间模型、H3、Mamba和Mamba 2。这些方法不仅提供了新的理论见解,而且在实践中展示了它们的优势。本章将详细介绍这些通用架构的基本技术,重点关注最具有代表性和主流的方法。
B. 注意力机制的优化技术
多头注意力机制是Transformer的核心组件,它通过并行计算多个注意力头来捕获输入序列中不同位置之间的依赖关系。然而,标准的多头注意力机制具有高计算复杂度,促使研究人员提出各种变体来优化其性能。标准Transformer模型在处理长序列时面临效率瓶颈,其自注意力机制的时间和空间复杂度是序列长度的二次方O(n^2)。这个问题源于注意力机制中的Softmax操作。如图2所示,没有Softmax,注意力计算简化为三个矩阵乘法,它们是可结合的,允许首先计算KT V,然后由Q左乘。这将复杂度从O(n^2)降低到线性O(n),是线性注意力的核心思想。
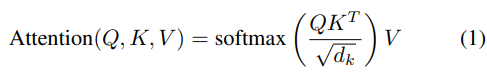

图 2. 线性注意力机制中简化计算的核心原则。传统的自注意力机制具有O(N^2)复杂度(上),通过更高效的线性注意力方法替换为O(N)复杂度(下)。这是通过移除softmax操作并近似函数实现的,允许注意力作为一系列与输入大小线性缩放的矩阵乘法来计算。
如果去掉Softmax,注意力计算的复杂度可以降低到线性O(n)。Scaled-Dot Attention本质上是用QKT加权V。因此,可以提出一个通用的注意力定义:
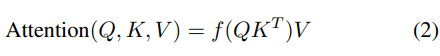
这里,f是一个通用函数,近似Softmax操作。为了适应Softmax,f必须确保非负性f ≥ 0。这种通用的注意力形式在计算机视觉中被称为Non-Local Networks。如果Q和K的元素是非负的,它们的点积自然是非负的。这表明可以引入核函数。通过向Q和K添加非负激活函数ϕ:
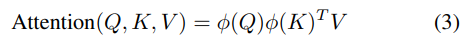
其中ϕ是一个非负激活函数,如ReLU(x)。这种方法,被称为核方法,由A Katharopoulos等人讨论。Performers使用线性空间和时间复杂度估计传统的(softmax)全秩注意力Transformers,同时保持可证明的准确性,不依赖于稀疏性或低秩先验。另一种方法利用Softmax的属性。在Efficient Attention中,Q沿维度d归一化,K沿维度n归一化,自然满足归一化条件。因此,分别对Q和K应用Softmax:
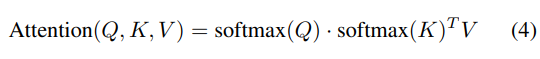
这是通用注意力定义的一个特例。此外,还有稀疏注意力方法,如OpenAI的Sparse Attention,通过仅保留局部区域的值,将大部分注意力值置零来减少计算。
稀疏注意力方法[30],例如OpenAI的Sparse Attention[31],通过仅保留局部区域的值,将大部分注意力值置为零,从而减少计算。经过特殊设计后,注意力矩阵的非零元素为O(n),实现了线性级别的注意力。Reformer[32]是另一个值得注意的改进,它通过使用局部敏感哈希(LSH)找到最大的注意力值并仅计算这些值,将注意力复杂度降低到O(n log n),实现了稀疏注意力。此外,Reformer通过构建可逆前馈网络(FFN),重新设计了反向传播过程,减少了内存使用。尽管解决了稀疏注意力的第一个缺点,Reformer仍然复杂,特别是基于LSH的注意力和可逆网络的反向传播。Performers[7]采用了一种新的快速注意力方法,Fast Attention Via Positive Orthogonal Random features (FAVOR+):
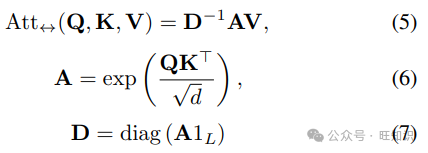
等价于上述注意力,缩放因子 𝑑𝑘 简化了A。快速注意力(FA)通过ϕ函数将Q和K映射为Q’和K’,近似A为它们的乘积
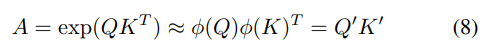
ϕ映射矩阵的行向量。FAVOR+有效地模拟了超出softmax的其他可核化的注意力机制。这种能力对于在大规模任务中准确比较softmax与其他核至关重要,有助于找到最优的注意力核。Performers与常规Transformers完全兼容,提供了强大的理论保证:无偏或近乎无偏的注意力矩阵估计,统一的收敛性和低估计方差。Linformer[8]通过低秩矩阵近似改进了自注意力,将复杂度降低到线性O(n)。Linformer保留了原始的Scaled-Dot Attention形式,但在注意力之前,使用n × k矩阵将Q和K投影到低维空间,减少了计算。虽然Linformer在某些任务上表现出色,但其在长序列任务上的性能仍有待验证。此外,Linformer在自回归生成任务中面临挑战,因为投影过程结合了整个序列信息,使得因果掩蔽复杂化。多查询注意力(MQA)和分组查询注意力(GQA)是值得注意的变体。这些方法优化了注意力计算过程,降低了计算复杂度和内存消耗,同时保持或提高了模型性能。多查询注意力(MQA)在所有注意力头之间共享键和值,为每个头计算独立的查询,从而降低了复杂度和内存使用。在MQA中,所有注意力头共享相同的键和值,仅查询不同:
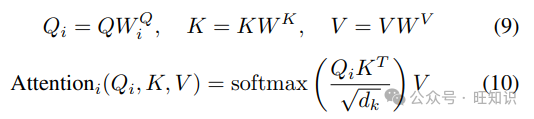
这里,𝑄𝑖是第i个注意力头的查询,K和V是共享的键和值。这显著减少了需要计算和存储的矩阵数量,降低了计算和内存复杂度。

如图3所示,分组查询注意力与MQA不同,它通过分组注意力头,每个组内的头共享相同的键和值,而每个组内的头有独立的查询。这种方法在降低复杂度的同时保持了灵活性:
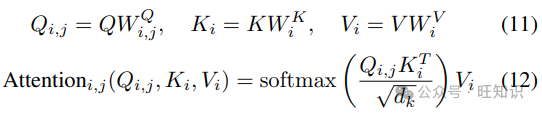
这里,𝑄𝑖,𝑗 是第i组中第j个注意力头的查询,𝐾𝑖 和 𝑉𝑖是第i组共享的键和值。这种组共享方法在降低复杂度的同时提供了更多的灵活性和表达力。此外,下采样技术如池化或使用带步长的一维卷积减少了序列长度。IBM的PoWER-BERT[33]和Google的Funnel-Transformer[34]通过逐渐下采样提高了模型效率。尽管这些技术显著降低了复杂度,但它们可能影响模型的生成能力。总的来说,修改注意力形式或结构有效地降低了计算复杂度,同时保持或提高了性能。这些变体为处理长序列数据提供了更有效的解决方案,并为多模态任务研究提供了新的思路和方法。
III. 模型架构的优化技术
在多模态方法的研究中,为了解决Transformer模型参数过多、计算复杂性高的问题,研究人员提出了各种优化和改进措施,以提高模型效率、降低计算复杂性,并改善性能。本节详细介绍了这些模型架构的改进。
A. 模型压缩
模型压缩的目标是减少深度神经网络中的参数数量和计算负载,提高效率并降低存储需求。预训练的深度神经网络模型通常面临过度参数化的问题,其中只有约5%的参数是有效的。模型压缩技术包括前端和后端压缩,旨在在不显著降低准确性的情况下缩小模型大小,从而提高实用性和效率。前端压缩方法包括知识蒸馏、紧凑模型结构设计和滤波器剪枝。知识蒸馏通过软化输出概率分布将复杂模型的知识转移到较小的模型,允许小模型在保持高计算效率的同时实现复杂模型的性能。例如,Hinton等人提出了知识蒸馏技术。紧凑的模型结构设计通过改进神经网络的卷积方法(例如,使用深度可分离卷积)来减少计算参数。MobileNet在这方面是一个成功的例子。滤波器剪枝通过移除不重要的权重矩阵来减少模型冗余。
后端压缩方法包括低秩近似和无限制剪枝。低秩近似使用几个低秩矩阵重构大权重矩阵,减少存储和计算资源消耗。例如,奇异值分解(SVD)广泛用于矩阵分解以实现压缩。无限制剪枝包括非结构化剪枝和结构化剪枝。非结构化剪枝移除个别权重。除此之外,Han Song团队提出了AutoML模型压缩(AMC),利用强化学习自动搜索模型压缩策略,提高在移动设备上部署神经网络模型的效率。AMC使用强化学习智能平衡模型大小、速度和准确性,比手工制定的启发式规则更有效和高效地自动生成最优压缩策略。这些模型压缩技术提高了计算和存储效率,允许深度神经网络广泛应用于资源受限的环境中。
B. 模型剪枝
剪枝技术通过移除模型中的冗余参数和连接来提高计算效率并减少模型大小。剪枝技术可以分为非结构化剪枝、结构化剪枝和混合剪枝。非结构化剪枝以细粒度操作,移除网络中的任意“冗余”参数。然而,这种方法可能导致不规则的网络结构,难以有效加速。LeCun在20世纪80年代末提出了最优脑损伤(OBD)算法[39],使用损失函数的二阶导数来确定参数重要性。Hassibi等人[40]、[41]通过最优脑外科医生(OBS)算法扩展了这一方法,不受限于OBD的对角线假设,将较不重要的权重置零,并重新计算其他权重以补偿激活值,实现更好的压缩结果。Srinivas等人[42]提出了在不依赖训练数据的情况下移除全连接层中的密集连接的方法,显著降低了计算复杂性。结构化剪枝基于预定义的标准移除结构化组件,例如注意力头或层。XPruner[43]利用可解释掩码端到端学习,测量每个单元对预测目标类别的贡献,并自适应搜索逐层阈值以保留最具信息量的单元,同时确定剪枝率。混合剪枝结合了非结构化和结构化剪枝方法,平衡它们的优势以获得更好的性能优化。例如,SPViT[44]基于动态注意力开发了一个多头令牌选择器,用于自适应实例级令牌选择,引入了一种软剪枝技术,将较不重要的令牌合并到包令牌中,而不是丢弃它们。ViT-Slim[45]引入了可学习和统一的稀疏性约束,以预定义因子表示各个维度内的全局重要性。这些剪枝技术在各种应用中表现出显著的有效性。在图像分类任务中,结构化剪枝可以显著降低卷积神经网络的计算成本,同时保持高分类精度。在自然语言处理任务中,非结构化和混合剪枝有效地减少了Transformer模型的复杂性,实现了在资源消耗较低的情况下进行推理和训练。通过应用这些剪枝技术,模型在显著降低计算和存储成本的同时,保持了高性能,提高了它们在实际应用中的可用性和效率。
C. 知识蒸馏
知识蒸馏(KD)是一种模型压缩技术,它将复杂模型(称为教师模型)中的知识转移到一个较小的模型(称为学生模型)中。这允许学生模型在保持高计算效率的同时实现教师模型的性能。知识蒸馏最初由Bucilua等人提出,他们使用伪数据分类器训练压缩模型,以复制原始分类器的输出[14]。KD可以分为同构KD和异构KD。同构KD意味着学生和教师模型具有相似或相同的结构。在这种方法中,学生模型通过模仿教师模型的输出(例如,logits、特征层输出)进行学习。常见的同构KD方法包括logit级蒸馏、特征级蒸馏和模块级蒸馏。例如,TinyViT[46]在预训练期间应用蒸馏,将大型教师模型的logits存储在硬件上,以便在将知识传递给较小的学生Transformer时实现内存和计算效率。DeiT-Tiny[47]采用patch级蒸馏,训练一个小型学生模型以匹配预训练教师模型的patch结构,然后使用分解的流形匹配损失进行优化,以降低计算成本。模块级方法如m2mKD[48]将教师模块从预训练的统一模型中分离出来,将学生模块与模块化模型结合起来,并使用共享的元模型进行组合,使学生模块能够模仿教师模块的行为。特征级蒸馏方法如MiniViT[49]将连续Transformer块的权重结合起来进行跨层权重共享,并引入转换以增强学习。异构KD指的是学生和教师模型具有不同结构。在这种方法中,尽管架构不同,学生模型仍然通过模仿教师模型的输出或中间特征进行学习。异构KD增强了学生模型的适应性,使其能够从教师模型中学习有用的信息。异构KD包括软标签蒸馏,其中学生模型通过模仿教师模型的软标签输出进行训练。KD通过模仿教师模型的输出或特征,将知识从复杂模型转移到较小模型,实现模型压缩和加速。同构和异构KD都通过模仿教师模型的输出或特征进行训练。这些方法不仅提高了学生模型的性能,还降低了计算和存储成本,使深度学习模型能够广泛应用于资源受限的环境中。研究表明,经过KD处理的模型可以在移动设备和嵌入式系统等资源受限环境中表现良好,进一步促进了深度学习技术的广泛部署。
D. 量化技术
量化技术将模型参数从高精度浮点数(例如32位或64位)转换为低精度格式(例如8位或16位),减少计算和存储成本[50],[51]。例如,在笔记本电脑上训练一个猫狗分类模型时,其参数大小可能是64MB。将其部署在使用ATmega328P微控制器进行8位运算的Arduino Uno上,量化模型可以将权重存储大小减少到原始大小的1/8,对准确性的影响可以忽略不计(大约1-3%)。这表明量化在减少存储需求和提高计算效率方面具有显著优势。权重是神经网络中的可训练参数,在训练过程中调整以最小化模型的损失函数,使模型能够从数据中学习。如果输入向量是x,权重矩阵W和偏置向量b,则神经网络层的输出可以表示为:𝑧=𝑊𝑥+𝑏
量化技术包括后训练量化(PTQ)、量化感知训练(QAT)和硬件感知量化(HAQ)。
- 后训练量化(PTQ) 在训练完成后对模型参数进行量化。PTQ的主要优点是简单和快速,不需要对训练过程进行调整。它通常包括权重和激活量化。
- 量化感知训练(QAT) 在训练期间考虑量化影响,模拟量化效果以帮助模型适应量化后的性能。QAT通常包括权重和激活量化。
- 硬件感知量化(HAQ) 在量化期间考虑特定硬件架构特性,优化模型在特定硬件上的性能。HAQ不仅考虑缩放因子,还结合硬件特性进行优化,例如调整缩放因子和量化范围以适应硬件特性。业界广泛采用INT8量化,在推理期间替换FP32,而训练仍然使用FP32。许多深度学习软件,如TensorRT、TensorFlow、PyTorch和MxNet,已经启用或正在启用量化。量化技术使深度学习模型能够在资源受限的环境中得到广泛应用,同时保持高计算性能和低存储需求。
E. 合成数据技术
合成数据技术生成与真实数据相似但没有包含真实个人信息的数据,扩大训练数据集以提高模型的泛化能力和鲁棒性[52],[53]。在大型模型训练中,纯文本合成主要是通过其他大型模型完成的,而图像合成主要使用生成模型。合成数据通常需要通过统计方法进行验证,以确保与真实数据分布一致。统计方法通过对真实数据进行统计分析和建模,然后使用这些模型生成合成数据。例如,使用概率分布函数模拟真实数据的特征和分布,以生成合成数据。生成对抗网络(GANs)是用于生成逼真合成数据的深度学习技术。GANs由生成器和鉴别器组成,生成器产生合成数据,鉴别器区分真实和合成数据。通过持续的对抗性训练,生成器和鉴别器相互竞争,最终生成高质量的合成数据。GANs在医学成像、面部识别和自动驾驶等领域有广泛应用。变分自编码器(VAEs)是学习数据潜在表示以生成与真实数据分布相似的合成数据的生成模型。VAEs特别适合图像生成任务,在生成高质量、逼真图像方面表现良好。序列模型通过诸如马尔可夫链、递归神经网络(RNNs)和变分自编码器(VAEs)等模型为序列数据(例如文本、时间序列)生成合成数据,通过建模序列特征和依赖关系来生成合成数据。
F. 模型架构的评估技术
模型架构的评估技术用于衡量和比较不同深度学习模型的性能,以选择最佳架构。评估方法可以分为手动和自动评估。手动评估涉及专家或用户评估模型输出,适用于具有强烈主观性的任务,例如生成文本的质量或生成图像的真实感。然而,手动评估效率低下、成本高昂且难以扩展。自动评估通过计算各种性能指标来衡量模型性能,提供高效率和可重复性。常见的自动评估平台和工具包括Microsoft Azure AI Studio中的Prompt Flow、与LangChain结合使用的Weights Biases、LangChain中的LangSmith[54]、Confidence-ai中的DeepEval[]和TruEra[55]。这些平台和工具提供各种评估方法,如基于规则的和基于模型的评估。基于规则的评估方法使用预定义的规则和指标(例如准确率、精确度、召回率、F1分数、ROC-AUC曲线)来评估模型性能。例如,MMLU[56]、TriviaQA[57]和HumanEval[58]等数据集广泛用于评估语言模型的理解和生成能力。基于模型的评估方法使用预训练的裁判模型(例如GPT-4、Claude)或对抗性评估(例如LLM同行考试)来评估模型性能。这些方法全面评估模型在复杂任务和多模态数据上的性能。
G. 模型架构的微调技术
微调技术涉及在特定任务数据集上进一步训练预训练模型,以提高模型在该任务中的性能。以下是常见的微调技术和它们的最新进展:
- LoRA (Low-Rank Adaptation) [59] 是一种低秩适应技术,通过向预训练模型添加低秩矩阵进行微调,减少计算和存储成本,同时保持性能。
- QLoRA [60] 是一个改进版本,通过量化技术进一步优化微调过程。
- 检索增强生成 (RAG) [61] 结合了信息检索和生成模型,通过从外部数据源检索相关信息来增强生成模型的性能。
- LangChain [62] 库提供了各种工具,允许大型模型访问来自Google搜索、向量数据库或知识图谱等来源的实时信息,进一步提高RAG的有效性。
- LlamaIndex (GPT Index) [63],[64] 是一个集成的数据框架,旨在通过使用私有或自定义数据来增强大型语言模型(LLMs)。LlamaIndex提供数据连接器、索引和图构建机制以及高级检索和查询接口,简化了数据集成和信息检索过程。通过适当应用这些微调技术,可以充分利用预训练模型的知识,提高新任务中的性能,同时减少训练时间和计算资源消耗。
H. 模型架构的其他挑战者
在多模态大型模型领域,由于其出色的性能和灵活性,Transformer架构被广泛使用。然而,随着模型大小和应用需求的增加,Transformer架构在计算复杂性和内存瓶颈方面面临挑战。为了解决这些挑战,研究人员提出了各种优化策略和替代架构,以提高模型效率和可扩展性。除了Transformers,大多数其他挑战者架构源自递归神经网络(RNNs),包括门控卷积、时间卷积网络(TCN)、RWKV、Mamba和S4,它们用递归结构替代注意力。这种方法使用固定内存来记住先前的信息,尽管它可以记住一定长度的信息,但实现更长长度是具有挑战性的。另一种方法是改进Transformers,如前面提到的线性注意力改进。代表性模型包括Mega、Yan和JEPA。我们将介绍其中的一些代表性方法。RWKV模型[22]使用线性注意力机制,允许模型在训练期间并行化计算,并在推理期间保持恒定的计算和内存复杂性。RWKV模型由堆叠的残差块组成,每个块包含时间混合和通道混合子块,使用递归结构利用过去的信息。作者训练了大小从169百万到14亿参数的RWKV模型,使其成为迄今为止训练的最大密集RNN。实验结果表明,RWKV与类似大小的Transformers表现相当,表明未来的工作可以利用这种架构创建更高效的模型。然而,RWKV模型有一些局限性,例如线性注意力可能限制了在需要长期依赖性的任务上的性能。Mega模型[23]引入了稀疏注意力机制,将大部分元素在注意力矩阵中置零,只保留少数重要的注意力值。这种方法在保持预测性能的同时显著减少了计算负载和内存使用。与Longformer和Sparse Transformer类似,Mega模型在稀疏策略和实现方面具有独特的优化。通过使用稀疏注意力机制,Mega模型大大减少了计算复杂性和内存使用,使其在处理长序列任务时更加高效。JEPA(Joint Embedding Predictive Architecture)[24]是一种新型的机器学习模型,旨在通过分层决策和控制方法优化复杂任务和大规模问题的处理。核心思想是将问题分解为多个层次,每个层次处理不同抽象级别的子任务,简化了整体问题解决过程。JEPA的概念和研究主要由Meta的Yann LeCun团队提出,旨在克服当前大型语言模型(LLMs)在处理复杂任务方面的局限性。代表性方法是I-JEPA,一种非生成自监督学习方法,通过预测同一图像中不同目标块的表示来学习高度语义化的图像表示。这种新架构结合了RNNs和Transformers的优势,同时减少了它们的局限性。Mamba和Mamba 2[25],[26]是改进的关键方向。Mamba是对SSM的改进。状态空间模型(SSM)描述动态系统,在控制理论、信号处理和统计建模中广泛使用。SSM使用状态变量来表示系统的内部状态,由状态和输出方程描述。状态方程为:
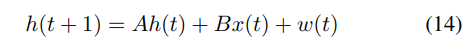
其中 ℎ(𝑡)是时间 𝑡 的状态向量,𝐴 是状态转移矩阵,𝑥(𝑡) 是时间 𝑡 的输入向量,𝐵 是输入矩阵,𝑤(𝑡) 是过程噪声,通常假定为零均值高斯白噪声。输出方程为:
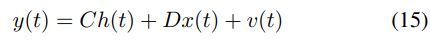
其中 𝑦(𝑡)是时间 𝑡 的输出向量,𝐶 是输出矩阵,𝐷 是直接传输矩阵,𝑣(𝑡) 是测量噪声,通常假定为零均值高斯白噪声。Mamba是基于SSM改进的选择性状态空间模型(SSSM)。图4显示了SSM和Transformer在处理多维输入数据时的架构差异。SSM独立处理每个维度,具有高并行计算能力和线性计算复杂度。相比之下,Transformer通过多头注意力机制捕获全局依赖关系,但计算复杂度更高。
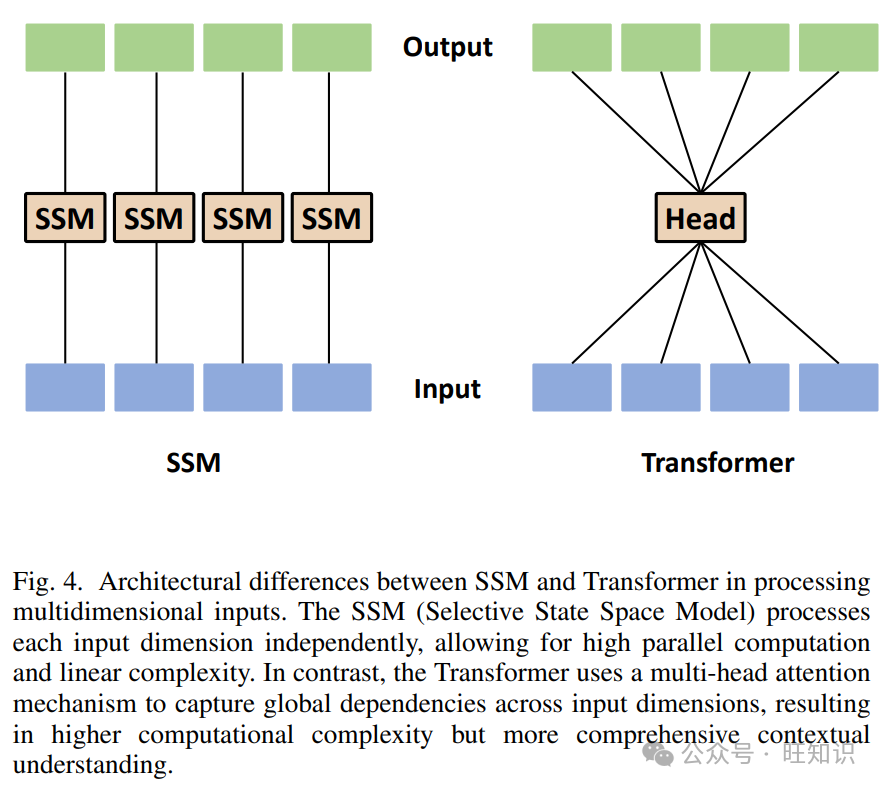
图4. SSM和Transformer在处理多维输入时的架构差异。SSM(选择性状态空间模型)独立地处理每个输入维度,允许高并行计算和线性复杂度。相比之下,Transformer使用多头注意力机制捕获输入维度之间的全局依赖关系,导致更高的计算复杂度,但更全面的上下文理解。
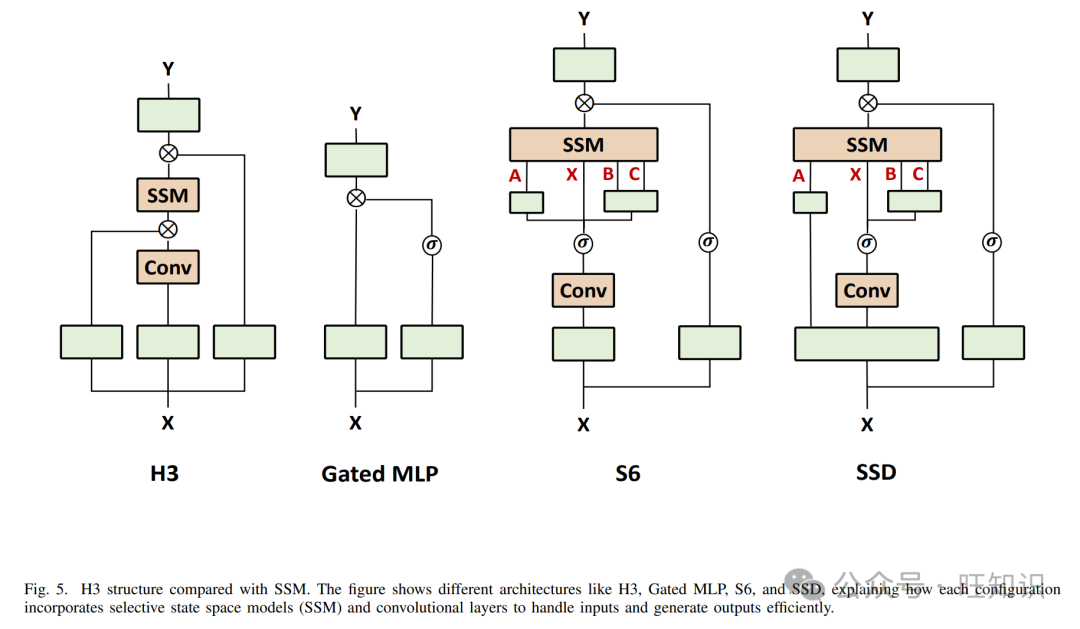
H3架构[21]是同质架构的基础设计,改进了最初的SSM结构,解决了SSM在记忆长期数据方面的挑战。如图5所示,研究人员将先前的SSM架构设计H3与门控MLP块合并为一个块,选择性地处理输入信息(选择机制),简化了深度序列模型架构,形成了一个具有选择性状态空间的简单、同质架构(Mamba)。与结构化SSM一样,选择性SSM是独立的序列转换,灵活地集成到神经网络中。Mamba-2提出了状态空间对偶(SSD)框架。基于此,研究人员设计了新的Mamba-2架构,其核心层是改进的选择性SSM。研究人员将4-6个注意力层与Mamba2层混合,超过了Transformer++和纯Mamba-2的性能,表明注意力和SSM是互补的。Mamba-2的一个主要目标是使用张量核心加速SSM。在Mamba-2的SSD结构中,实现了并行投影,突破了SSM的顺序计算限制,实现了并行计算。在实际架构变化中,一些SSM参数作为内部激活函数(状态)而不是层输入函数限制了并行计算和训练速度。在Mamba-2中,所有SSM参数都是层输入函数,容易应用张量并行性到输入投影。研究人员在Pile数据集上训练了一系列Mamba-2模型,表明Mamba-2在标准下游评估中匹配或超过了Mamba和开源Transformer。例如,在Pile数据集上训练了3000亿个token的2.7B参数Mamba-2超过了2.8B参数的Mamba和Pythia,以及6.9B参数的Pythia。
IV. 多模态模型的特定技术
A. 多模态架构技术
1. 通用多模态架构和训练策略
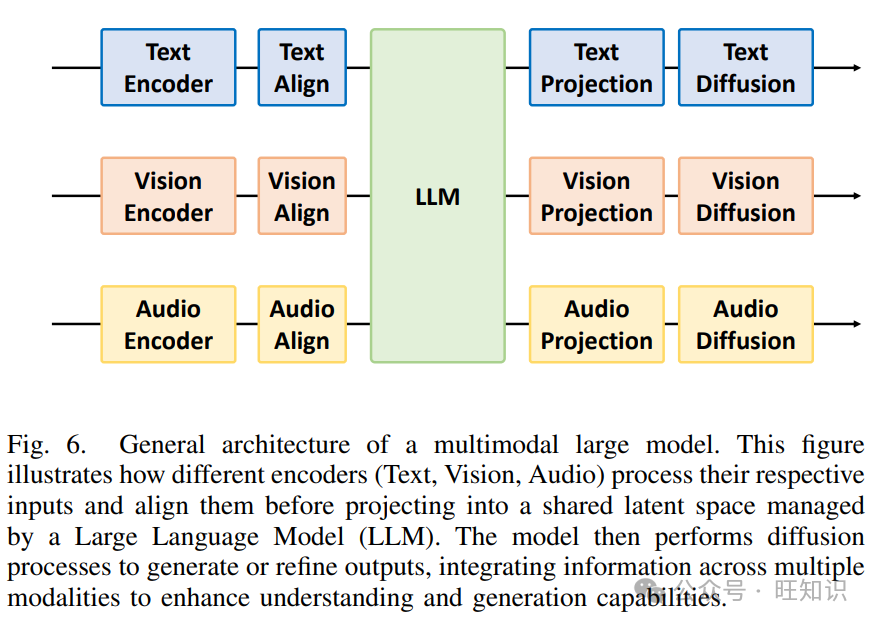
在多模态大型模型(MLM)领域,研究人员提出了各种架构技术来实现和优化多模态模型的性能和应用。图6显示了一个旨在处理文本、视觉和音频数据的通用架构。在这个架构中,每种模态的数据首先通过各自的编码器(文本编码器、视觉编码器、音频编码器)进行处理以提取特征。然后,这些特征通过对齐模块(文本对齐、视觉对齐、音频对齐)进行归一化和匹配,随后通过投影模块(文本投影、视觉投影、音频投影)将特征映射到一个共同的特征空间。最后,扩散模块(文本扩散、视觉扩散、音频扩散)进一步传播和调整特征。大型语言模型(LLM)集成这些多模态特征来处理和生成复杂的跨模态任务。这种设计允许不同模态的数据在统一的特征空间中进行融合和处理,增强了对多模态数据的理解和生成能力。编码、对齐、投影和扩散的专用模块使LLM能够高效地处理和集成文本、视觉和音频数据,从而提高整体模型的性能和适用性。端到端学习是多模态大型模型的一个关键训练策略,整个模型作为一个整体进行优化,而不是分阶段进行。与分阶段训练相比,端到端学习消除了每个步骤中的中间数据处理和模型设计。然而,端到端学习在多模态大型模型中有三个主要缺点。
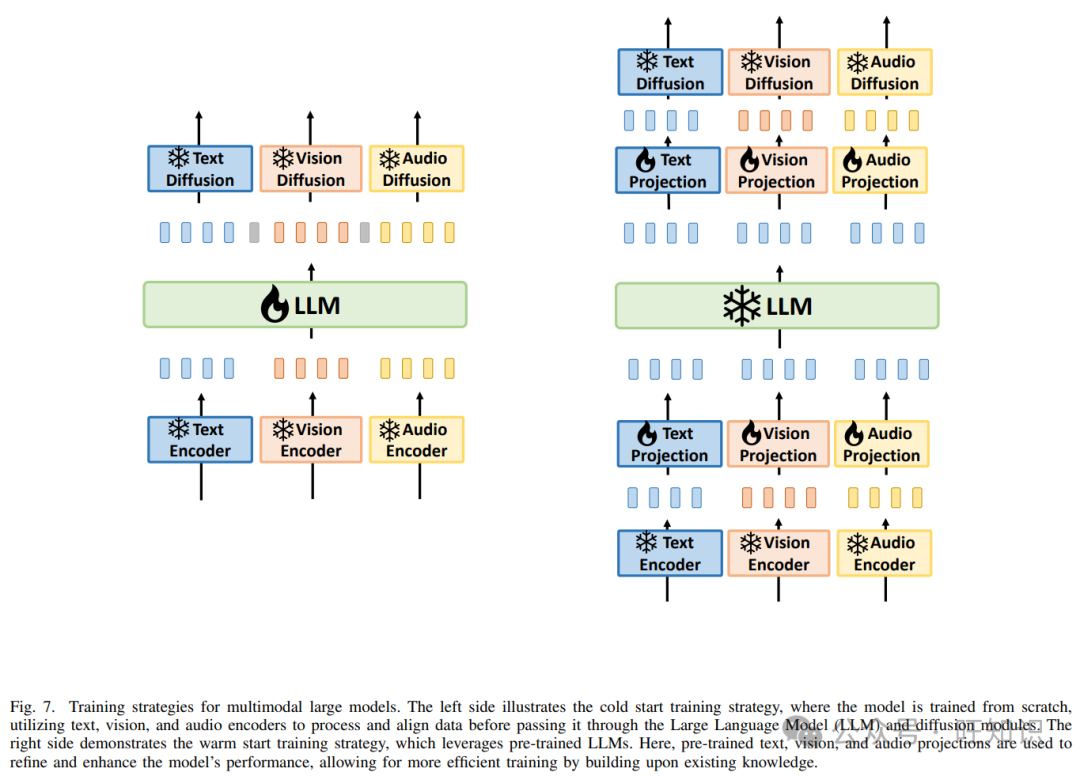
两个最大的缺点是大量数据和计算能力的需求。直接端到端学习需要大量的多模态数据集和计算资源。例如,OpenAI在GPT-4训练中使用了大约2.15e25 FLOPS,大约25,000个A100 GPU,训练90到100天,效率(MFU)约为32%到36%,其中包括大约1.3万亿个token。对于完整的多模态训练,这些需求至少会翻倍。最后一个缺点是建立复杂关系的困难。手动设计的模块经常注入人类先验知识,例如编码器、解码器、对齐层等,这可以简化模型。例如,如果我们旨在通过视频检测微表情,模型设计通常涉及关键帧选择、面部裁剪、面部动作单元识别,结合微表情理论和统计数据。一个端到端模型直接建立图像和微表情之间的联系显然是具有挑战性和复杂性的。鉴于这些挑战,大多数多模态大型模型并不完全使用端到端训练。图7显示了大型模型训练中使用的两种训练策略。左侧显示了冷启动训练策略,模型从头开始训练。它首先使用文本、视觉和音频编码器对不同模态的数据进行编码,然后通过扩散模块(文本扩散、视觉扩散、音频扩散)进行特征传播,然后使用大型语言模型(LLM)进行集成,最后通过投影模块(文本投影、视觉投影、音频投影)生成输出。该过程强调逐步扩展和调整特征,确保有效集成和处理多模态数据。右侧显示了热启动训练策略,模型从一些预训练开始。预训练的LLM直接通过投影模块(文本投影、视觉投影、音频投影)处理输入数据,生成初始特征,并通过扩散模块(文本扩散、视觉扩散、音频扩散)进行细化。与冷启动相比,热启动利用了预训练模型的现有知识,提高了训练效率和初始性能,适用于具有相关领域知识或基础模型的场景。这种方法使模型能够快速适应新任务,并在训练初期表现出高性能。
2. 通用多模态编码器
在视觉编码器方面,与主流MLM实践一致,通常选择预训练的CLIP模型进行视觉编码,因为它有效地对齐了视觉和文本输入的特征空间。鉴于视觉编码器在MLM参数中所占比例相对较小,轻量级优化不如语言模型关键。通过组合多个视觉编码器,可以捕获广泛的视觉表示,增强模型的理解能力。例如,Cobra[65]整合了DINOv2和SigLIP作为其视觉后端,结合了DINOv2的低级空间特征和SigLIP的语义属性。SPHINX-X[66]使用了两个视觉编码器,DINOv2和CLIP-ConvNeXt,它们通过不同的方法和架构进行预训练,以提供互补的视觉知识。高效的视觉编码模型使用诸如标记处理等技术来管理高分辨率图像,而不会带来过大的计算负担。高分辨率图像输入到轻量级视觉编码器,进行调整大小和分割以生成初始视觉标记。这些标记通过视觉标记压缩模块进行压缩,以减少计算和存储开销。压缩的标记通过高效的视觉-语言投影器投影到语言模型的特征空间,并与文本标记对齐。小型语言模型结合并处理这些对齐的视觉特征和文本标记,生成语言响应。
LLaVA-UHD[67]引入了一种图像模块化策略,将图像划分为较小的片段进行高效编码,降低了计算负载,同时保持了感知能力。视觉编码器的进步还包括MAE(掩蔽自编码器)[68],这是一种自监督学习方法,通过掩蔽和重建输入图像的部分来学习图像表示。文本编码器是多模态模型的另一个关键组成部分,用于处理和理解文本数据。Transformers是常见的文本编码架构,自注意力机制有效地捕获文本中的长距离依赖关系。BERT(基于Transformer的双向编码器表示)是基于Transformer的预训练模型,通过在大规模语料库上的双向训练生成高质量的文本表示,在各种自然语言处理任务中得到广泛应用。
在音频编码方面,AudioCLIP[69]是一个有效的选择,通过结合音频和文本信息生成音频表示。AudioCLIP使用类似于CLIP的架构,通过对比学习在相同的特征空间内对齐音频、文本和图像特征。这种方法增强了音频数据的表示,并提高了多模态模型在音频-文本和音频-图像任务中的性能。
3. 通用多模态生成模型
模型的生成过程可以描述为将从先验分布 𝑝𝑧(𝑧)中提取的潜在样本𝑧转换为与目标数据分布𝑝data(𝑥) 一致的样本𝑥′。具体来说,潜在变量𝑧通过参数函数(通常实现为神经网络)学习将先验分布映射到目标数据分布。
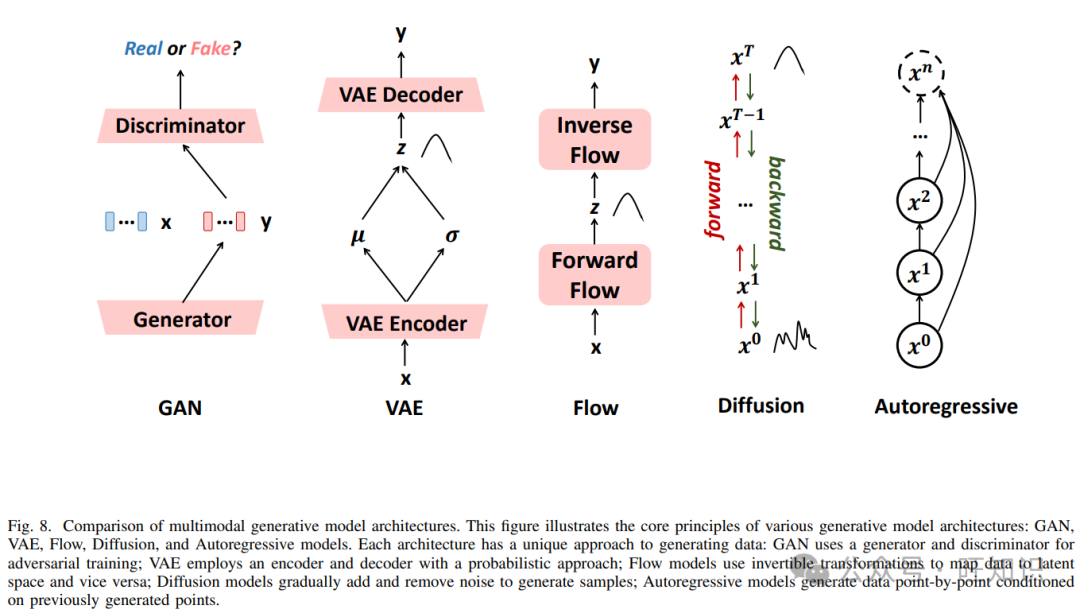
转换后的输出x’被视为一个合成实例,它在统计上模拟原始数据分布的特征,可能对应于各种模态,如图像、视频、3D表示、音频或文本。在多模态大型模型(MLMs)领域,生成模型在合成新数据样本方面发挥着关键作用。主要的生成方法包括生成对抗网络(GANs)、变分自编码器(VAEs)、基于流的模型、扩散模型和自回归模型,如图8所示。
-
生成对抗网络(GANs) [70]:GANs由两个神经网络组成:生成器和鉴别器。生成器从潜在变量 𝑧z 生成假样本x’,试图欺骗鉴别器,而鉴别器则区分真实样本 𝑥x 和生成样本。GANs广泛应用于图像和视频生成,以及高保真音频和文本创作。
-
变分自编码器(VAEs) [71]:VAEs包括编码器和解码器。编码器将输入数据 𝑥 映射到潜在空间 𝑧,学习均值 𝜇 和方差 𝜎 以生成潜在变量。解码器从潜在空间 𝑧重建数据x’′。VAEs旨在在保持生成多样性的同时最大化数据可能性,通常应用于图像合成和生成多样化对象。
-
基于流的模型 [72]–[74]:流模型使用一系列可逆变换在数据空间𝑥和潜在空间𝑧之间进行映射。前向流将输入数据𝑥映射到潜在变量𝑧,而反向流从潜在变量𝑧重建数据x’′。流模型的优势在于精确地建模数据可能性,常用于高维数据如图像和视频生成。
扩散模型 [75]:扩散模型包括前向过程和反向过程。前向过程逐渐将数据 x0 转换为噪声状态 xT,而反向过程将xT去噪恢复为数据x0
。扩散模型通过去噪学习逆转噪声过程,从简单分布中生成高质量样本,特别适用于高分辨率图像生成和复杂的多模态场景。 -
自回归模型:自回归模型按顺序生成数据,每一步的输出依赖于前一步的结果。模型按条件生成每个数据点xt ,条件是之前的点 xt−1, xt−2, . . . , x1。自回归模型将数据的联合概率分布分解为条件概率的乘积,广泛应用于文本生成、语言建模以及基于序列的任务,如音频和视频生成。
基于这些基本架构,最近出现了许多重要的进展。基于生成模型的文本到图像生成主要遵循两种范式:扩散模型和基于VIT的模型[76],[77]。由于训练简单,扩散模型已成为主流范式。在扩散框架内,有像素级和潜在级视频扩散模型。扩散模型通过使用UNet预测噪声来生成图像,尽管这个过程需要多次迭代(通常表示为T),随着T的增加,这个过程变得非常耗时。此外,扩散模型无法控制图像生成,只能随机生成。为了解决这些问题,Latent Diffusion Model (LDM)提出了一个两阶段的图像生成模型:第一阶段训练一个图像编码器-解码器,第二阶段生成图像[78]。具体来说,LDM通过将图像缩小到较低尺度并添加条件控制模块来简化计算,将图像和文本特征注入UNet以指导图像生成。Google的Imagen[79]进一步展示了预训练大型模型在文本到图像任务中的优势。该模型通过动态采样改进了噪声生成,并引入了一个轻量级UNet模型。Cascaded Diffusion Models[80]通过首先生成低分辨率图像,然后逐步上采样到高分辨率来提高图像清晰度和质量。RePaint[81]提出了一种无需训练的图像修复方法。DALLE2[82]使用CLIP模型的反向操作(unCLIP)进行图像生成,包括图像解码器和先验模型,包括自回归和基于扩散的方法。SDXL[83]进一步优化了扩散模型,通过级联基础和细化模型改进了高分辨率图像生成。当前基于LLM的视频编辑遵循与Instruct Pix2Pix[84]类似的方案,使用LLMs更有效地构建训练数据。Vid2Vid[85]-[87]是一种涉及通过LLMs构建训练数据的方法。该方法使用LLM模型生成合成视频指令对,然后训练一个编辑模型以使用自然语言指令执行受控视频编辑。DiT(Scalable Diffusion Models with Transformers)[88]是在Sora之后广泛讨论的模型,提出使用Transformers而不是UNet结构来增强生成。
B. 多模态优化技术
- 多模态指令调整 (M-IT): 多模态指令调整 (M-IT) 是一种技术,它通过对包含多模态数据的指令或任务描述进行微调,增强模型理解和执行多模态任务的能力。指令调整涉及对预训练的语言模型 (LLMs) 进行微调,这些数据集以指令格式组织,提高了它们对未见任务的泛化能力[89],[90]。这种方法已成功应用于像ChatGPT、InstructGPT、FLAN[91]和OPT-IML[92]等自然语言处理模型。传统的监督微调依赖于大量特定任务的数据,而提示方法通过提示工程减少了对大规模数据的依赖,尽管零样本性能有限。与这些方法不同,指令调整强调学习泛化到未见任务,与多任务提示密切相关。具体来说,为多模态指令调整构建的数据集包括特定任务、输入多模态信息和预期的模型输出。通过对这些多模态指令进行微调,模型更好地理解如何利用多模态能力以满足期望。当将指令调整扩展到多模态指令调整时,数据和模型需要调整以适应不同模态数据的特征及其在联合学习中的交互。例如,处理视觉-文本联合任务要求模型理解文本描述和相关的图像信息。通过设计多模态任务描述,将图像和文本作为输入集成,模型使用多模态对齐技术学习多模态特征。M-IT的核心目标是对模型进行微调,使其能够在各种应用场景中泛化并处理未见任务,展现出更强的适应性和泛化能力。
- 多模态上下文学习 (M-ICL): 多模态上下文学习 (M-ICL) 通过在训练或推理期间提供多模态上下文信息,增强模型对多模态数据的理解和处理能力[93],[94]。上下文学习 (ICL) 是大型语言模型 (LLMs) 的一项重要且新兴能力[95]。ICL通过类比学习实现少样本学习和解决复杂任务,与传统的监督学习范式不同,后者需要大量数据来学习隐式模式。在ICL设置中,LLMs从少数示例和可选指令中学习,泛化到新问题以解决复杂和未见任务。ICL无需训练,可以灵活集成到不同框架的推理阶段。在多模态大型模型 (MLMs) 的背景下,ICL扩展到更多模态,形成多模态上下文学习 (M-ICL)。在推理期间,M-ICL可以通过向原始样本添加演示集(一组上下文样本)来实现。具体来说,M-ICL与M-IT的区别在于构建具有多模态输入输出信息的数据集,这是上下文相关而不是预期的模型响应。通过指令和提供的演示,LLMs理解任务目标和输出模板,生成预期答案。在教授LLMs使用外部工具的场景中,示例通常只包含文本信息,并且更加详细。这些示例包括完成特定任务的顺序步骤,与思维链 (Chain of Thought, CoT) 密切相关。结合这些技术,M-ICL扩展了模型处理多模态任务的能力,并在各种应用场景中增强了其泛化和适应性。
- 多模态思维链 (M-COT): 大型语言模型 (LLMs) 在复杂推理方面展示了令人印象深刻的性能,特别是通过使用思维链 (CoT) 提示生成推理中间步骤来推断答案[4],[96]。然而,现有的CoT研究主要集中在语言模态上。多模态思维链 (M-COT) 是一种方法,它使模型能够通过逐步推导和连贯的思考来执行复杂的推理和决策。正如先前的工作所指出的,CoT是“一系列中间推理步骤”,在复杂推理任务中被证明是有效的。CoT的核心思想是提示LLM不仅输出最终答案,还要输出导致答案的推理过程,类似于人类的认知过程。受到自然语言处理 (NLP) 领域成功经验的启发,一些研究工作将单模态CoT扩展到多模态CoT (M-CoT)。Zhang等人[97]首次将CoT推理应用于多模态模型。M-COT是一个两阶段框架,微调语言模型以整合视觉和语言表示,以更好地执行多模态CoT推理。在第一阶段,模型使用结合视觉和语言输入进行微调,以理解和处理多模态数据。在第二阶段,模型使用这些多模态表示逐步生成中间推理步骤,在复杂任务中做出连贯和合理的决策。通过这种方法,M-COT不仅增强了模型在多模态任务中的推理能力,而且扩大了其在复杂场景中的应用范围,使其能够更有效地处理整合图像和文本信息的任务。
V. 多模态模型概述
在本章中,我们将介绍在多模态领域具有较大影响力的生成和基础模型。由于大多数多模态生成和底层模型是闭源的,我们将不会在这里做太多陈述。
A. 多模态生成模型
多模态模型在处理和理解来自不同模态的数据方面展现出了巨大的潜力和应用前景。通过分析现有的多模态模型,很明显它们在生成图像、视频、音频和3D模型方面取得了显著进展。这些模型通过处理如文本、图像、视频或音频等不同模态的数据,实现了跨模态的生成和转换。例如,自2021年以来由OpenAI开发的DALL-E系列模型(包括DALLE[98]、DALL-E 2[82]、DALL-E 3[99])已经发展到能够基于文本描述生成高质量的图像。DALL-E模型利用大规模数据集和Transformer架构的能力,从文本输入中理解和生成高度详细和创造性的图像。每一次迭代都在前一次的基础上进行了改进,DALL-E 3更是采用了更先进的技术来产生更加连贯和高质量的图像。2022年推出的Midjourney[100]专注于高质量的艺术图像生成,在创意设计中得到了广泛应用。该模型强调生成视觉吸引力和艺术价值高的图像,因此在艺术家和设计师中非常受欢迎。Google在2022年和2023年分别推出的Imagen和Imagen 2[79]通过包括编辑功能进一步增强了图像生成能力。Imagen模型允许用户对生成的图像进行修改,使创建和完善图像的过程更具互动性和用户友好性。
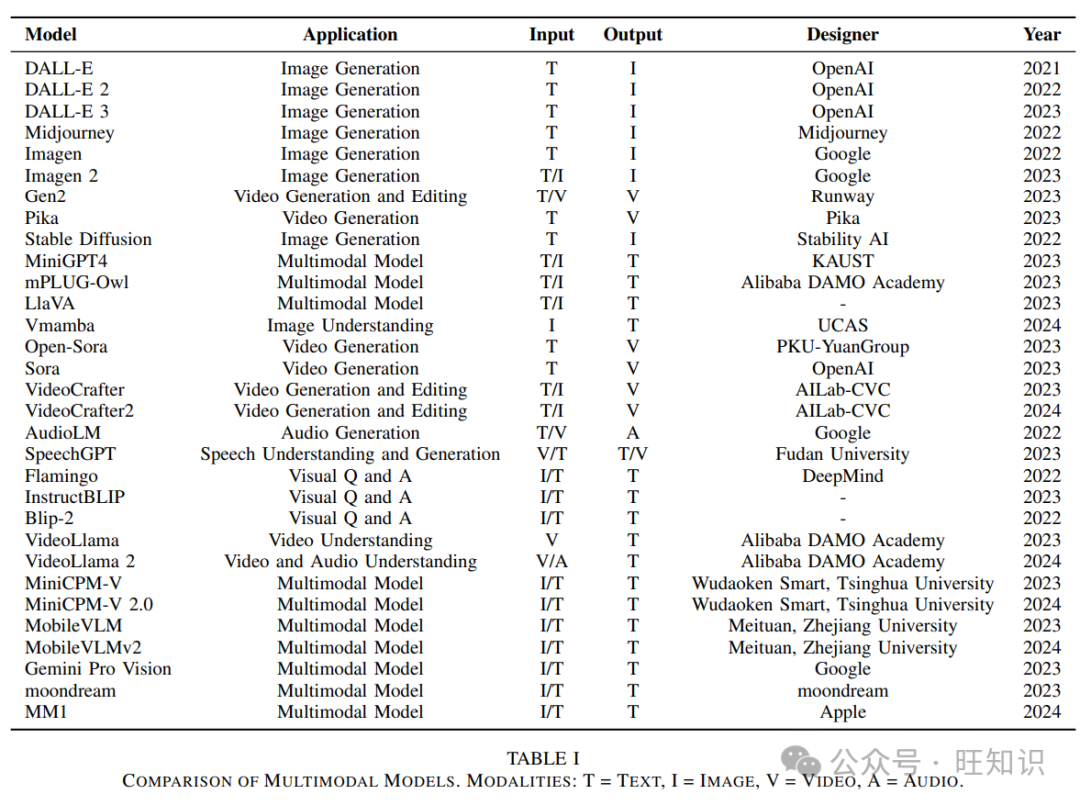 表I 多模态模型比较。模态:T = 文本,I = 图像,V = 视频,A = 音频。
表I 多模态模型比较。模态:T = 文本,I = 图像,V = 视频,A = 音频。
Stability AI在2022年开源的Stable Diffusion[78]推动了社区在图像生成方面的研究和应用。Stable Diffusion的开源特性鼓励了广泛的研究和开发活动,为图像生成技术的快速发展做出了贡献。
视频生成领域也取得了重大突破。OpenAI和PKU-YuanGroup在2023年发布了Sora和Open-Sora,能够生成高度逼真的视频。这些模型将图像生成的能力扩展到时间域,允许创建动态和栩栩如生的视频内容。
AILab-CVC在2023年和2024年分别发布的VideoCrafter和VideoCrafter2[101]进一步优化了视频生成和编辑功能。这些模型集成了先进的视频编辑能力,使创建和修改视频内容变得更加容易。Google在2022年推出的AudioLM[102]在音频生成方面表现出色,能够生成自然的声音、音乐和人类语音。这个模型展示了多模态生成模型在从文本描述中创建高质量音频内容方面的潜力。复旦大学在2023年推出的SpeechGPT[103]结合了语音识别和生成技术,提高了语音交互的自然性和准确性。SpeechGPT将先进的语言模型与语音技术相结合,提供了更流畅、更准确的语音交互。
B. 多模态基础模型
多模态基础模型专注于理解和对齐多模态数据,使更复杂的推理和任务执行成为可能。DeepMind在2022年推出的Flamingo,理解图像内容并回答相关问题,在视觉问答任务中表现出色。在2022年和2023年之间推出的InstructBLIP和Blip-2通过高效的视觉-语言预训练提高了视觉问答性能。DeepMind的Flamingo[104]理解图像内容并回答相关问题,在视觉问答任务中表现出色。该模型旨在弥合视觉输入和文本查询之间的差距,提供准确和上下文相关的答案。InstructBLIP和Blip-2[105]、[106]通过大规模预训练提高了它们理解和响应视觉查询的能力,使它们在各种视觉问答场景中更加有效。阿里巴巴达摩院在2023年和2024年分别推出的视频理解模型VideoLlama和VideoLlama 2[107]、[108],可以理解视频内容并执行视频字幕生成和视频-音频理解等任务。这些模型旨在处理和理解复杂的视频数据,实现更精细的视频分析和理解任务。像MiniGPT4[109]、mPLUG-Owl[110]和LlaVA[67]这样的多模态模型由KAUST和阿里巴巴达摩院在2023年开发,支持文本和图像的输入和输出。它们通过高效的多模态对齐技术实现了全面的文本和图像处理。这些模型旨在处理各种多模态任务,在文本-图像对齐和处理方面提供强大的性能。美团和浙江大学在2023年和2024年分别开发的MobileVLM和MobileVLMv2[111]、[112],为移动平台优化了模型性能和应用场景,进一步提高了多模态任务执行能力。这些模型专门设计用于在资源受限的平台上高效有效地运行,实现了在移动设备上的高级多模态功能。
VI. 从多模态模型到世界模型
基于当前技术,构建世界模型主要有两种方法。第一种方法依赖于基于规则的方法,并且只需要少量数据。第二种方法,以OpenAI为例,涉及使用大型数据集。在以下部分中,我们将介绍这两种方法,并探讨它们构建世界模型的潜在适用性。
A. 3D生成和规则约束
3D生成是多模态生成中的一个重要领域,它通过生成逼真的3D模型并在生成过程中引入规则约束,从而创造出高度逼真且可控的虚拟环境,类似于元宇宙。3D生成技术主要包括显式表示、隐式表示和混合表示。显式表示包括点云和网格,它们通过精确描述对象的几何形状来生成3D模型。隐式表示,如神经辐射场(Neural Radiance Fields, NeRF)和隐式曲面,通过学习数据的潜在表示来生成高质量的3D内容。混合表示结合了显式和隐式特征,保留了几何细节,同时提供了灵活的表示能力。特定的生成方法包括生成对抗网络(GANs)、扩散模型、自回归模型、变分自编码器(VAEs)和归一化流。这些方法通过不同的机制生成逼真的3D数据。例如,GANs通过生成器和鉴别器之间的对抗性训练来生成高质量的3D模型;扩散模型通过模拟数据的扩散过程来生成新样本;自回归模型通过逐步预测每个元素的条件概率来生成3D对象;VAEs通过学习输入数据的潜在表示来生成数据;归一化流使用一系列可逆变换将简单分布映射到数据分布以进行数据生成[114]。基于优化的生成方法使用优化技术在运行时生成3D模型,通常结合预训练网络根据用户指定的提示(如文本或图像)来优化3D模型。例如,文本到3D的技术使用文本提示指导3D内容的生成;图像到3D的技术从指定图像重建3D模型,保留图像外观并优化3D内容的几何形状。过程式生成使用预定义的规则、参数和数学函数来创建3D模型和纹理,包括分形几何、L-系统、噪声函数和元胞自动机[115],[116]。基于生成的新视角合成使用生成技术从单个输入图像预测新视图,基于条件3D信息生成新内容。基于Transformer的方法使用多头注意力机制从不同位置收集信息进行新视角合成;基于GAN的方法使用3D点云作为表示,合成缺失区域,并通过GAN生成输出图像。这些方法各有优势和应用场景,研究人员可以根据特定需求选择合适的3D生成技术[117],[118]。尽管3D生成质量和多样性有了显著提高,但当前挑战包括评估、数据集规模和质量、表示灵活性和可控性。多模态大型模型需要更深层次的网络和更大的数据集进行预训练。多模态大型模型通常在视觉和语言模态上进行预训练,未来的扩展可以包括更多模态,如图像、文本、音频、时间、热图像等。基于多种模态的大规模预训练模型具有更广泛的应用潜力。
B. 更多模态信息通向具身智能
实现世界模拟器的另一种方法是通过具身智能模型。当前的多模态模型涵盖了日常信息媒体,如图像、文本和音频。然而,开发具身智能机器人需要将这些模态信息扩展到包括坐标系统、点云和深度信息,这些对于机器人理解和操作真实世界至关重要。将这些额外的模态信息整合到多模态模型中可以实现初步的具身智能机器人[119],[120]。具身智能涉及机器人在物理世界中感知、理解和行动。为了实现这一点,机器人需要处理和理解来自多个传感器的数据,如摄像头、激光雷达(LiDAR)和深度传感器[121],[122]。这些传感器提供信息,包括坐标系统、点云和深度图,使机器人能够构建和理解其周围环境的详细3D表示。有了这些模态信息,机器人可以在真实世界中导航、识别对象和执行任务。通过在现实生活中部署机器人,可以收集足够的多模态信息,实现对真实世界的全面数据收集。通过结合具身智能和边缘设备收集的传感器信息,可以进一步提高具身智能的性能。有了足够的全面模态信息,不仅可以进一步提高具身智能的性能,而且还可以用来设计更现实世界模拟器。这样的世界模拟器可以为机器人提供一个虚拟训练环境,让它们在安全和受控的条件下学习和优化。通过不断的迭代和优化,最终可以实现高度智能和自主的具身智能机器人。
C. 整合更多外部规则系统
在构建世界模拟器的过程中,整合更多的外部规则系统是一个关键方法。人类依赖于客观世界中的数学、物理、化学和生物学工具,使用一系列定理来推导和预测尚未发生的事件的结果。例如,当我们踢一个球时,它会以弧线飞行。这些基于物理定律的预测帮助我们理解和操作真实世界。同样,规则系统可以帮助模型实现状态记忆和反馈。假设一场洪水破坏了大坝;模型需要根据规则推断随后的洪水状态。这些规则源于人类常识和定理库,是从长期实践和经验中总结出来的。通过将这些结论注入模型,模型可以在较少数据的情况下推断出合理的结果。在构建多模态大型模型时,整合外部规则系统可以显著增强模型的理解和推理能力。例如,使用数学定理,模型可以准确计算物体的轨迹;使用物理定律,模型可以预测复杂的环境变化;使用生物学知识,模型可以模拟生态系统的动态变化。这些规则系统为模型提供了一个框架,使其能够更准确地模拟真实世界。在实际应用中,具身智能机器人可以从这些规则系统中受益。当机器人在现实生活中收集大量多模态数据时,这些数据将与注入的规则系统相结合,增强机器人的预测和决策能力。例如,当机器人检测到水位上升时,它可以基于物理和地理知识预测潜在的洪水范围和影响,并采取相应的行动。通过整合这些外部规则系统,多模态大型模型可以在各种应用场景中表现出色,并实现更复杂和详细的任务。这种方法不仅提高了模型的智能性,而且为未来发展提供了更坚实的基础。
VII. 讨论
目前,多模态大型模型(MLMs)的发展仍处于早期阶段,无论是在相关技术还是特定应用方面都存在许多挑战和研究问题。现有MLMs的感知能力有限,导致视觉信息不完整或不正确,进而导致随后的推理错误。这种情况可能是由于当前模型中信息容量和计算负担之间的折衷所导致的。例如,降低图像分辨率和简化特征提取可能导致信息丢失,影响模型的整体性能。MLMs的推理链很脆弱,尤其是在处理复杂的多模态推理问题时。甚至简单的任务有时也会因为推理链断裂而得出错误答案。这表明模型对不同模态信息的理解和链接还有待提高,需要更稳定和连贯的推理机制来提高准确性和可靠性。MLMs的指令遵循性需要进一步提高。即使经过指令微调,一些MLMs仍然无法为相对简单的指令输出预期答案。这表明当前的微调方法和数据集尚未完全覆盖模型所需的各种指令场景,需要进一步优化和扩展训练数据。对象幻觉问题普遍存在,其中MLM输出与图像内容不匹配的响应,制造出对象。这不仅影响了MLM的可靠性,还揭示了视觉理解和语义生成的不足。解决这个问题需要更精确的视觉-语义对齐和验证机制。高效的参数训练是另一个紧迫问题。由于MLMs的容量很大,高效的参数训练方法可以在有限的计算资源下释放更多的MLM能力。例如,引入更有效的训练策略和硬件加速可以显著减少模型训练时间和资源消耗,提高模型的应用潜力。目前,还没有真正的统一多模态大型模型。尽管GPT-4o可能成为第一个,但还有待取得重大进展。这表明在实现真正的统一多模态世界模拟器之前,需要解决许多技术挑战。无论是通过OpenAI的大量数据训练,还是Meta提出的有限数据分层规划,还是本文提到的引入更多规则和知识库,这些都是通往世界模型的可行途径。从根本上说,大量数据模拟了人类文明开始以来遇到的信息,而使用有限数据引入规则模拟了后代使用祖先总结的经验和定理进行快速学习。这两种方法都是直观合理的。然而,目前需要解决的核心问题在于微观层面,特别是在简化注意力机制和使GPU适应线性注意力机制方面,这可以显著提高模型训练效率。通过部署边缘设备和具身智能来快速收集数据,世界模型的到来并不遥远。
VIII. 总结
本工作全面概述了多模态大型模型(MLMs)的发展和挑战,突出了它们在推进人工通用智能和世界模型方面的潜力。它详细涵盖了关键技术,如多模态思维链(M-COT)、多模态指令调整(M-IT)和多模态上下文学习(M-ICL),以及整合3D生成和具身智能。综述强调了外部规则系统在增强MLMs中的推理和决策能力方面的重要性。这项工作通过提供对当前MLM技术和应用的详细分析,为社区做出了贡献,指出了发展统一多模态世界模型所必需的差距和未来的研究方向。
 作者:张长旺,图源:旺知识
作者:张长旺,图源:旺知识
参考资料
标题:From Efficient Multimodal Models to World Models: A Survey
作者:Xinji Mai, Zeng Tao, Junxiong Lin, Haoran Wang, Yang Chang, Yanlan Kang, Yan Wang, Wenqiang Zhang
单位:Shanghai Engineering Research Center of AI and Robotics, Academy for Engineering and Technology, Fudan University, Shanghai, China 等
标签:人工智能、多模态学习、世界模型、通用人工智能、神经网络
概要:文章综述了多模态大型模型(MLMs)的最新发展,探讨了它们在实现人工通用智能和构建世界模型方面的潜力与挑战。
链接:https://arxiv.org/pdf/2407.00118
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









