






产品经理比起大模型产品,更应该关注大模型本身。
注:随着时间推移,文章中的结论可能会发生变化。
此外,本文面向的读者是非算法团队的产品经理,为了保障文章的可读性,可能会省略部分细节,同时文章重点是工程落地而非学术探讨,不具备任何辩经的价值。
01
理解AI产品的工程化
坦率来说 2024 年围绕大模型,产品的发展速度比之前预期的要低一些,比如在 BI 领域,Chat BI 声量很大,但落地下来效果并不好,这个也很正常,因为每个人总是会在短期内高估技术带来的价值,而在长期范围低估技术带来的价值。
这里面有客观的原因,一项技术基底在真的应用到行业的方方面面本身就是需要过程的,因为这项技术需要去和原本的实现方案做竞争,就像俞军给的知名的需求公式:
用户价值= 新体验– 旧体验– 替换成本。
很多时候即使用了新技术,收益可能也没有想象的那么大,这是一个事实。
另一个原因就是从业者的理解问题,哪怕是在一些大型互联网公司内部,大部分人对大模型的优势和劣势分别是什么,这个“事实”是存在一些理解上的代差的。
因为现在技术进步的很快,各种实践路径五花八门,有的人会觉得这玩意无所不能,有的人会觉得这个东西根本没法用。
为什么不同的人对这个东西理解的差异这么大?很大程度上是因为他们没有理解大模型作为一个接口和大模型作为一个产品的区别。
大模型可以被视作为是一个函数,一个 API,它本身只能被调用,而大模型产品才是真正面向用户的东西。
比如我给大模型的 API一个 Excel,它会告诉我,不好意思我没办法读取这个文件的内容。但是我们在 Kimi 的聊天框里面,就可以让 Kimi 解释 Excel 内的内容,为什么有这个差异?
因为 Kimi 是大模型产品,背后跑的是 Moonshot-v1 的模型,Kimi Chat 会读取你的 Excel,然后转化成XML 信息给到大模型。(我猜的)
模型在做工程化变成产品的时候往往会添加很多限制,这些限制可能是做在产品层面的, 而不是 API 本身限制的,比如很多产品为了降低成本会限制用户上传 PDF 的大小,但是如果用 API,就没有这个限制,或者限制可以放的很大,但前提是需要首先把 PDF 转化成模型能够理解的文件形式。
市面上产品做了很多的工程转化,甚至是 Function Recall 的工作,直接使用产品,不利于产品经理了解大模型的优势和劣势,就不利于应用大模型,改进现有产品。
那么为什么我认为产品经理比起大模型产品,更应该关注大模型本身(API),因为从 API 到产品,这中间的工程转化过程,是产品经理们最需要关注的。
大模型好比是一个大脑,工程师和产品经理就需要给大模型设计五官,躯干和四肢。脑残和手残都是残,所以工程师和产品经理对于决定一个 AI 产品最后好不好用是非常重要的,头脑发达四肢简单和四肢发达头脑简单最终都解决不了用户的产品。
甚至可能前者对于用户来说会更糟糕一些。
要做出优秀的 AI 产品,不仅仅需要优秀的大模型,还需要优秀的工程师和产品经理来辅助大模型。
这就需要产品经理非常了解两件事:
- 现阶段的大模型有哪些局限性,这些局限性哪些是可以通过模型迭代得到解决的,哪些是不能的。
- 从更底层的业务角度去分析,大模型在商业意义上真正的价值在哪?注意,这里强调的是业务视角,不是让产品经理去读论文。
01.
大模型的局限性是什么?
2.1、一些可能永远都无法被解决的问题
2.1.1、成本、性能与响应速度
想要追求性能越强的大模型,就越需要越高的计算成本。
计算成本会带来两个问题:
- 直接造成的金钱成本;
- 响应速度;
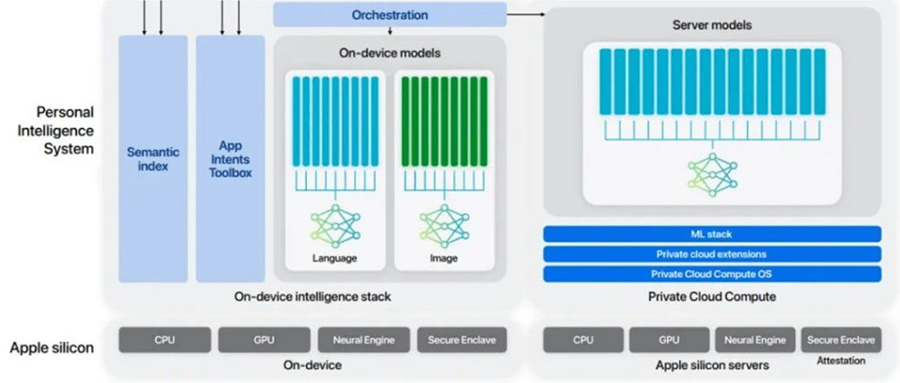
下图是 Apple Intelligence 的架构图,其中在端上有两个模型,而在云端还有一个基于隐私云计算的大模型。
为什么苹果要做这种工程上大小模型的设计?
因为苹果希望大模型的响应速度能够追上 Siri 现在的性能,同时移动设备对功耗本身是有要求的,再加上苹果非常重视隐私,希望 80% 的问题能够在用户本地得到解决,所以采用了这样的架构。
运行 meta 最新开源的 llama 3.1,70 b 版本需要大概 70 GB 的显存,405 b 版本可能需要 400 GB 的显存,可能需要并联 100台 iPhone 才能运行这些模型。
这种大小模型的设计,需不需要产品经理,当然需要,什么问题适合小模型解决,什么问题适合大模型解决,这显然不仅仅是 RD 需要去回答的,也需要有产品经理参与,负责如下部分:
- 收集目前用户的 Query;
- 从解决难度、隐私、对时效性的要求、对准确性的要求对 Query 进行分类;
- 设计基准测试,获得大小模型分界的标准;
- 持续追踪优化;
在未来至少很长一段时间,还是会有大量的本地/联网之争的,这个就是产品经理的机会。
2.1.2、窗口大小与不稳定
我们经常会看到,XXX 大模型支持 128K 上下文了,引来大家的一阵狂欢。
我们又会经常看见,XXX 大模型幻觉问题很严重,引来一阵吐槽。
上下文是什么意思?其实就是大模型在一次请求的过程中,能够接收的最大的信息的数量。我们在和 ChatGPT 聊天的时候会发现有的时候它聊着聊着会忘记之前自己说过的话,其实就是因为聊天记录已经超过了上下文的数量。
幻觉的意思则是大模型很容易会胡说八道,胡编乱造一些事实上不存在的东西,尤其是当它已经忘记前面和你说什么之后,你再问他类似的问题,它就会开始胡说。
很像一个渣男,你们已经牵手了。
你问:“我叫什么名字?”
他回答:“当然叫亲爱的啦。”
其实他已经不记得名字了,所以就开始胡编乱造了, 绝了,这玩意真的很像人类。
根据英伟达的论文 《RULER: What’s the Real Context Size of Your Long-Context Language Models?》来看,大部分模型宣传的上下文窗口基本上就是在扯淡,在极限长度的情况下,各家大模型对正确水平,是没有保障的。
比如说一个模型宣传自己支持 128k 的上下文(意思是差不多可以读一篇 20 万字的小说),但是实际上如果你随机塞一些句子进这篇小说,然后让大模型回答和这些句子有关的知识,它是有比较大概率答不出来的,它的性能会随着上下文窗口的变大而衰减。
如下图所示,以 GPT4 来说,当上下文超过 64k 时,性能就开始骤降:
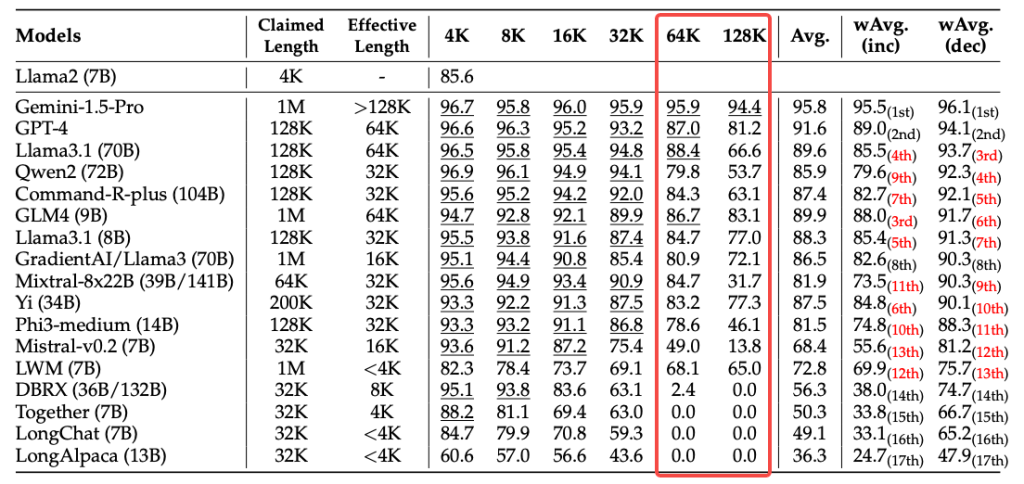
实际情况来说,我认为这些模型的表现会比你想象的更加糟糕。
我让 Claude 3.5 Sonnet 模型分析了一段的 SQL,这是一个 700 行的复杂 SQL,但是总体来说逻辑应该是比较简单的, 而且几乎每一行 SQL 都有注解,在这种情况下,Sonnet 就开始胡说八道了,说了一个 SQL 里面根本不存在的表。不排除是因为我在 Monica 的客户端里面调用 Sonnet 造成的,不知道 Monica 调用的时候是不是加了什么 Prompt 干扰了模型。

如何在保证解决用户问题的时候,避免受到上下文的影响和干扰呢?其实这个事情也需要产品经理的干预,比如:
- 研究能否把长文本切成多个段文本,并且不影响最终的结果;
- 研究怎么给 AI 外挂一些能够超长时间记忆的记忆库;
举例来说,掘金上面有一篇文章《多轮对话中让AI保持长期记忆的8种优化方式(附案例和代码)》,就讲述了 8 种主流的方法,这些方法都应该是产品经理根据业务场景去选择的。
文章地址:https://juejin.cn/post/7329732000087736360
最后聊一聊为什么我认为上下文窗口与不稳定的问题是一个长期内很难解决的问题。
在过去的一段时间,上下文窗口大小的问题其实是的到了一定程度的缓解的,但是根据英伟达的论文我们也可以发现,上下文窗口的大小和稳定的抽取内容避免幻觉这两个指标在很大程度上就是互斥的,就像是推荐系统的准确率和召回率指标一样。
这也就意味着在很长一段时间我们可能都没有两全之策,除非突然出现一个模型一方面解决幻觉问题,一方面能保证巨大的窗口。
而且在实践的时候我们往往需要避免极端 Case 的发生(比如我自己遇到的 700 行 SQL 解析错误),减少上下文的规模是很重要的手段,此外不同的检测手段下其实模型的表现并不完全一致,也就是说不同的业务场景,幻觉问题的严重程度其实是不一样的。
模型能够容纳的最大窗口和有效工作窗口是两个概念,并且不同的任务的有效窗口大小可能是非常不一致的。
我当然希望我的想法是错的, 目前而言我看不到任何模型能够在这件事情上有突破的可能性, 有一家公司叫 Magic,推出了一个号称具备了 1 亿 token 上下文窗口的模型,但截止到目前为止(2024.9.1)并没有发布任何的论文或者更实际的东西。
还是那句话,最大窗口和有效工作窗口是两个概念。
此外,多模态的发展某种角度来说会加剧窗口大小不足的问题。
2.1.3、函数本身不可能被自调用
有的时候会尝试在提示词里面撰写,比如我给你一个 xml,希望你能够遍历。通常来说,大模型是不会执行这个要求的。
原因也很简单,它本身作为一个函数,无法自我调用,而这个函数因为幻觉的问题,也不可能做到精确回复,甚至会把 N 行数据混杂在一起去分析,所以这类循环遍历的要求,通常得不到满足。
不支持自调用的原因也很简单,一次请求交互内,如果支持循环,那么就可能在 API 内直接调用大模型成百上千次,这个调用成本 API 的提供方是不可能承担的。
由于大模型本身是高度不稳定的,所以我们会非常需要通过一个循环/条件判断来去控制它,不支持自调用就意味着我们必须要在外部通过工程化来实现哪怕在人类看来最简单的遍历操作。
2.2、一些工程上的难点
2.2.1、不再互联的互联网
Apple 开创了移动互联网时代,但是也造成了一个最为人诟病的现象——花园围墙。
原本大部分网站是面向搜索引擎和人类搭建的,也就是说爬虫可以很简单的获取一个网站超过 90% 的内容。
这些对于 AI 来说至关重要,我举个例子,就是针对同一个问题,豆包和元宝的回答质量差异:
很明显,豆包的回答质量更加差,说一句又臭又长不过分,RAG 领域的最新进展确实是微软开源的 GraphRAG,这点在豆包的回答里面根本没有体现。
比较逗的是,腾讯混元引用了火山引擎的资料,但是豆包引用了一个不知道什么野鸡媒体的资料。

豆包的模型能力是比腾讯的混元大模型要强的,混元大模型用腾讯内部的话说,狗都不用,为什么从最终的呈现结果来说,豆包的结果不如混元呢?
因为头条的数据没有微信公众号的数据好。
为了解决互联网不在互联的问题,Apple 希望从操作系统层面把 UI 打造的面向大模型更友好,并且发布了一篇名为《Ferret-UI:基于多模态大语言模型的移动 UI 理解》(https://arxiv.org/pdf/2404.05719)的论文,但是我觉得更加开放的 API 和内容才是根本途径,因为苹果的互联互通是仅限于 iOS 生态的。
而对于产品经理来说这些自然也是发挥的空间:
- 上哪搞到更好的数据;
- 如何让 AI 调用别人家的 API 并且把结果拿来为自己所用;
- 怎么把苹果最新的 Ferret-UI 研究明白;
这些都是十分值得研究的命题。
2.2.2、爹味十足的厂商
所有的大模型都自带安全机制,而且这个安全机制是写死在模型里面的,不是说 API 有个开关可以把安全机制关掉,你可以选择把安全等级调低,但是这玩意是没办法关闭的。当然市面上会有很多突破安全机制的方法,但是这些都算是漏洞,被厂商发现之后很容易被封堵。
比如如果你和大模型说我和别人吵架吵输了,你教我怎么骂人,大模型会拒绝。就我自己而言,我认为把安全机制做在模型里面并且不给开关的行为真的很爹味,但是这个没办法。
所以市面上有很多的本地部署的模型的卖点就是没有安全机制,黄赌毒色情暴力 18+ 怎么黄暴怎么来,但是这玩意就是人性。这也是一个机会,值得各位 PM 关注。
此外有一点值得关注,同样的内容,在不同的语言下面安全的阈值是不一样的,举个例子:
通过 Google Gemini Pro 1.5 翻译西单人肉包子故事,翻译成英语/西语的时候,模型会报错,提示内容过于黄暴,模型拒绝生成,但是日语版本就没有任何问题。
说明什么?说明日语的语料真的很变态,间接可以说明日本人确实是全世界最变态的人。
2.3、目前存在,但是未来可能会被解决的问题
2.3.1、较弱的意图理解/创作/推理能力
大模型的意图理解,创作和推理能力,目前来看整体和人类的顶尖水平还是有较大差距的。
如果试图让大模型做一些“创造性”的工作,就需要非常强的提示词工程。
不同水平的提示词下,大模型的水平差异确实会非常大,但是我认为随着模型的迭代,我们的提示词对模型生成的结果质量影响会越来越小,主要的作用是提升精确性。
当然,如果两个模型有一些代差,生成的结果肯定是有质量上的差异的:
所以要不要对模型的提示词做大量优化呢?我认为这个取决于优化提示词的目的是什么。
如果是为了保证格式和输出结果的稳定性以及一致性,是很有必要的, 因为很多时候我们的产品业务上需要这个一致性,比如要求大模型输出的格式必须是 Josn,保证下游系统可以正常展示。
如果是为了提升质量,我认为是没有必要的,因为模型会升级,升级之后带来的提升肯定比提示词工程雕花带来的提升要多。
https://github.com/Kevin-free/chatgpt-prompt-engineering-for-developers
这是吴恩达的提示词工程课程,应该是目前市面上最权威的提示词工程课程,并且提供中英文双版本。
此外,长链路的 SOP、工作流和推理过程,我建议通过多个 AI Agent 实现,而非试图在一轮对话里面解决,原因在上面的局限性里面已经说的很清楚了。
2.3.2、跨模态数据读取/生成能力
如果这里有一个视频,希望 AI 总结视频的内容,应该怎么实现?
以 5.1K Star 的知名开源项目 BibiGPT 为例子。这个项目最早的一个版本应该是只做了一件事情(根据表现逆向猜测的),用 OCR 识别字幕,同时把视频转音频,ASR 出来文字,然后让 GPT 3.5 去总结。
项目地址:https://github.com/JimmyLv/BibiGPT-v1
当然更新到今天这个项目肯定不是做的这么简单多了,比如应该运用了大量的视频截图然后要求支持多模态的模型去识别里面的关键内容。
但是让我们回到 BibiGPT 第一个版本,它其实还是做了一个视频转文字的这样的动作。
这样的动作理论上来说现在已经没有必要做了,因为 Google 最新的模型 Gemini 已经支持对视频本身的解析了,只不过用起来很贵,下面是 Google 官方提供的 Gemini 处理视频、音频和图片的文档。
https://cloud.google.com/vertex-ai/generative-ai/docs/samples/generativeaionvertexai-gemini-all-modalities?hl=zh-cn
我个人并不建议大家在跨模态这个事情去做一些雕花的工作。因为用工程手段解决跨模态最大的问题是会造成信息的损耗。此外模型迭代一定是会端到端解决跨模态的问题的,我们应该重点解决上面提到的可能永远无解的问题,不要去和模型内卷,是不可能卷赢的。
但是需要强调的事,把一个博客网页的文本去提取出来转化成 MD 格式,或者把一个 PDF 转化成 MD 格式,这个不是跨模态,只是数据清洗,需要严格区分二者的关系。
数据清洗这件事情,最好还是用工程方法解决。
03.
从《理解媒介》的角度探讨
大模型的更底层的长处是什么
注:这一段会对麦克卢汉的《理解媒介》的基础上做一些发散;
想要理解大模型以及 AIGC 的商业价值,私以为最重要的是要能够首先理解媒介。
因为大模型生产的东西本质上是内容,想要能够对大模型有更深刻的理解,就要对内容以及媒介有比较清楚的认识,比起搞清楚大模型的本质是什么,我认为搞清楚内容的一些底层逻辑,其实对于应用大模型更重要。
对于产品经理来说,业务场景总是比技术手段更值得深入研究。
在讲述一些枯燥的概念之前,我想先讲一个关于媒介的小故事来方便大家理解。
3.1、关于媒介的小故事
在现实生活中,我们可能很难理解媒介的概念,但是在艺术界,媒介这个概念其实是被解构的很彻底,并且被比较赤裸地摆放出来的。
2017 年,知名的 MoMA 为史蒂芬·肖尔举办了一场个人摄影作品回顾展。
在回顾展的后半段,照片不存在于相框之中,展厅内部是一台又一台的 iPad,观众需要通过 iPad 观看肖尔使用 iPhone 拍摄并且发布到 Ins 上的照片。iPad 就是这些照片的相框。
媒介的作用就如同社会科学领域的议程设置一样,会深刻地影响所有人观看事物的方式。
肖尔的展览赤裸裸地把这个命题展现给了所有人。肖尔想通过这样的方式告诉大家,看一张照片,照片本身可能确实存在图像内容,但是让你通过 iPad 看,和让你通过打印出来的照片看,观看感受就是不一样的。
当你在博物馆看到一张照片,不论这张照片拍的有多屎,只要照片被很精致的打印,放大,挂载一面墙上,旁边再标上一个已经被拍卖的标签,看的人可能都会觉得,我靠牛逼,毒德大学!
当你在 Ins 上面刷到一张照片,你会觉得,哦,这就是一张照片。
现在肖尔在博物馆里面放一张照片,但是这个照片得用 iPad 看,这种强烈的反差会促使人们去思考,媒介对于内容究竟有多大的影响。
如果站在内容创作者的角度来看,现在生产了一个内容,希望它的价值被尽可能放大,是不是应该把这个内容输出到尽可能多的媒介上面去?
因为不同的人喜欢的媒介是不同的,同一个人在不同的媒介看到同一个内容获得的感受也是不一样的,这就是一个商业机会。
比如拍了个短视频,是不是最好抖音、小红书、B 站都发一遍?最好微信公众号再发一遍文字稿!
但是实际上只有头部的内容生产者才有资格做的这么细致,为什么?因为内容在媒介之间的转换是有成本的。
哪怕一个视频从抖音发到 B 站,对观众来说其实已经产生不好的观感了,因为一个是横屏一个是竖屏,一个是长视频一个是短视频,如果内容创作者要保持全平台最佳观感,其实成本是非常高的。
就我自己的体会来说,如果仔细看同一个内容创作者在 B 站和抖音发的视频会发现即使是一模一样的内容,抖音的视频普遍会被剪辑的更短。
最后,为了方便下文讨论,我会按照自己的理解对几个概念做简单定义,这些定义并不严格,仅仅作为本文讨论时方便使用。
- 模态:人类与现实世界的交互模式,通常与感知器官有紧密联系,常见的模态有文字、静态/动态图像、声音等;
- 内容:内容是人类通过感知器官对于现实世界进行数据采集,处理和再加工的产物;
- 媒介:针对特定内容的一种承载、编排与传播范式,把 10 张照片按照顺序放在博物馆里面,作为一个展览展出。在这句话里面,照片是媒介(因为照片本身是一张纸,是物质的),10 张是编排方式,博物馆和展览也可以认为是一个媒介,只有照片里面的图像才是内容;
- 互联网平台:一种特定媒介,它们的特点就是会通过数字化手段严格限制媒介的格式、展示方式、分发逻辑,并且它们通常不会自行生产内容;
3.2、内容具有原生媒介
每个内容在创作时都会自带一个原生媒介,因为人脑能够容纳的上下文是有限的,当一个作者在试图进行创作时,他必须要把创作的阶段性成果存储在某个媒介之上,并且这个媒介需要确保内容可以被再次输出以便作者做阶段性的回顾与质量检查。脱离了媒介作为存储介质,作者本人也无法理解自己曾经的创作。
所以我们也可以认为,一个内容是无法脱离于媒介独立存在的。
这种创作过程中就使用的媒介,我们通常称之为原生媒介,一个内容通常有且仅有一个原生媒介,当然可能会有辅助的媒介,比如一个广播演讲的原生媒介是音频,但是会辅以文字稿件作为补充。
一个内容只有通过原生媒介展示时才是能做到尽可能还原作者意图的,反过来也可以说,内容被发布到非原生媒介时会产生大量的信息损耗。
通常来说在一个媒介或者互联网平台内最流行的内容,几乎无一例外都是把这类媒介当成原生媒介的内容。
这也就是为什么抖音和 B 站的内容在互相转化的时候这么困难的原因。
B 站最早是一个网站,B 站的视频也是横屏的,因为看网站用的显示器天然就是横屏的,而显示器是横屏的原因是因为人类的两个眼睛是横着排列而不是纵向排列的。
抖音从诞生的时候就是一个 App,而且搭配了很多手机拍摄视频的功能,所以抖音视频天然就应该是竖屏的,因为人类用手机就是竖着抓的。
假如我们现在的主流手机不是 iPhone 定义的,而是日本的夏普定义的,说不定抖音就压根不会存在。

这种媒介上的区别就好像是难以逾越的天堑一般。
上面说的这些好像是常识,但是完全可以把这个分析思路套用到其他的内容上面去。几乎所有内容产品都可以在这个框架内进行分析。
一个看逐字稿会觉得是无聊对话的播客节目,听感有可能会非常出众,比如一些以“聊天”和“插科打诨”为卖点的播客节目,因为在播客节目中有语气和情感,这是文字稿很难表现的。
反过来说,假使一场广播演讲,演讲者根本没有用心关注内容,也没有通过演讲彩排做阶段性回顾,只知道逐字念稿,撰写演讲稿的人过分关注文字本身,这些就会导致演讲听上去干瘪无力,不如把演讲稿直接发给读者看来的更顺畅,因为这场演讲在创作时使用的就是文字而非声音。
在小红书上面,专业的脱口秀演员也会表达类似的观点,这些在道理上都是相通的。
优秀的演讲者往往会选择先写大纲,口播转文字再对文字进行调整,以此保证听众体验。
3.3、媒介之间的本质区别
不同媒介之间的根本性差异在哪?
个人目前观察来看主要有两点,模态和瞬间性。
媒介=模态*瞬间性。
模态,人类与现实世界的交互模式,通常与感知器官有紧密联系,常见的模态有文字、静态/动态图像、声音等。
这三个基本模态根植于人类的视觉和听觉,锥体经验理论认为人类大部分学习过程都依赖于视觉和听觉,从这个角度来看,这些基本上的模态恰好被理论所命中。
当然这也可能是鸡生蛋蛋生鸡的关系。不同的模态自带的信息含量是不一样的,文字是最抽象的,包含的信息含量最低,而图像是最具象的,包含的信息含量最高。所以人们常说,看小说可以让人发挥想象,看电视剧则会被束缚,正是因为文字的信息含量低,所以才有想象的空间。
当然,这里的信息含量指的是“绝对信息含量”,比如文本文件就是比图像文件更小,但是这不代表念书学习效率会比看图效率低,因为人类能够摄取一个内容中的信息含量的能力是有限的。
好比和一个人交谈一定是比通过电子邮件交流具备更加丰富的信息的,因为这个人有微表情,有神态,但并不每个人都能获取和接收这些信息。
瞬间性是媒介的另一个根本特征,瞬间性是指对于一个内容来说,当它被某个媒介承载时,观看者回顾其中某一个内容切片的成本。
下面是一组媒介和他们的瞬间性大小的排布,瞬间性越强,回顾成本越高:
单张图片 = 短文字 < 组图 < 长图文 < 流媒体平台上的视频 < 播客平台上的播客 < 电影院电影 < 音乐会的音乐 < 线下脱口秀。
为什么线下脱口秀最难复制,因为它的创作过程都是伴随线下的灵光乍现以及与观众的亲密互动,人们再也无法踏入同一条河流。
对于单张图片来说,虽然想要 100% 复制有困难,但是至少可以基于特定工艺进行打印,然后在对应亮度和色温的灯光下观看,就能获得近乎于原作的效果。
瞬间性越强的媒介,对于情绪的要求就越高(对创作者和观众来说都是这样),一组文字可以冷冰冰,但是播客不能有气无力,并且这种媒介越可能要求创作者把创作和传播本身融为一体。
还是拿脱口秀举例子,脱口秀本身就是在舞台上才能实现作品的完整创作的,所以创作过程和传播过程本身就是一体的。
同时一个媒介越是强调编排,瞬间性就会被体现的越强,强调编排意味着读者如果跳着阅读或者跳跃回顾,都很难通过上下文获得相同的体验,只有完整的重新按照编排顺序阅读,才能获得接近于第一次阅读的体验。
3.4、AIGC 的意义在于降低内容跨媒介甚至跨模态的门槛
在工作中其实我经常会有一个疑惑,为什么文档写了,还要问?
其实原因很简单,因为人作为一个媒介,比文档作为一个媒介对于人来说更加的友好。在某些场景下面提问者的问题是比较简单的,看文档就会很重。但是对于回答者来说,重复回答问题是不经济的,这种矛盾就很适合用 AI 来解决。
很多时候我们觉得一个内容读起来不舒服,可能不是内容本身的问题,而是这个内容的媒介导致的。
在英剧《是,大臣》中,汉弗莱曾经表示大臣的演讲就是很无聊,因为内阁大臣演讲稿撰写目标不是取悦台下的听众,而是上报纸。
所以为什么政客们在电视上的演讲那么无聊,这下大家都明白了吧,因为他们大部分在念一些“会以文字形式发下去”的材料。
理论上来说我们如果要让一个内容尽可能多渠道传播,我们需要有人去做这个媒介的翻译,并且这个成本非常高,举例来说:如果想要把一个以文字作为原生媒介的内容转化成播客录音,这个转化成本就会很高,因为这意味着在转化过程中需要增加额外的信息(比如语气和情感),这本身近乎于创作。
又比如对于一个公众人物来说,如果不针对性的做演讲训练,拿到一个演讲稿直接讲的效果一定会很差,因为撰稿人是基于文字媒介撰稿,而听众则通过声音这个媒介来接收信息。声音比干巴巴的文字稿会多出来更多的信息,语气、语速、抑扬顿挫等,这些如果指望演讲者临场发挥,那对演讲者来说要求真的很高。
因为如果一个内容的原生媒介的瞬间性很强,大概率意味着它会包含更多的信息,不论是编排层面还是情感层面。
但是现在,AIGC 很大程度上就能替代人去完成其中最枯燥的 80 % 的工作了。比如如何把一个文本转换成语音,可以用豆包 TTS 大模型,深情并茂。
在 AIGC 诞生之前,这是几乎不可解的问题,一定是需要人类录音的。
3.5、为什么要从媒介的角度去理解大模型的商业价值
其实大概就在 1 年前,我曾经尝试总结大模型能做什么,当时总结的用途是:
一、总结:根据特定的要求分析大段的内容,并且按照内容给出对应的结论;
二、扩写:根据特定的要求和范式,将少量内容扩充成大段内容;
三、翻译:根据特定要求把一段内容无损的转化成另一段内容;
四、意图理解:大语言模型有非常强的意图识别能力,可以非常好的理解用户的意图;
这些总结不能说是错的,但是有几个比较致命的问题。
一、仅针对文字模态,没有考虑多模态的情况;
二、这更多的是一种归纳,并不能保证从逻辑上是 MECE 的;
如果从归纳法的角度来说,我们会认为大模型能干这个,不能干那个,可以举无穷多的例子,但是如果想要试图搞清楚这个东西擅长什么,不擅长什么,天花板在哪里,归纳法是没有那么靠谱的。
如果从媒介的角度去看待大模型,我们可以发现它具有几个能力是以前的技术不具备的:
一、它能够一定程度上理解内容,但是要想凭空创造内容还是有难度的;
二、它在理解内容的基础上,可以将一个内容修饰成另更适合一个媒介内容,也就是我们常说的总结、扩写、翻译;
三、它能够在理解内容的基础上,将一个内容转化成另一个模态的内容,也就是我们常说的文生图;
四、它能够基于自己对大量素材的学习,在内容进行媒介或者模态转化的时候,补充最合适的信息进去;
五、因为它进行了大量的学习,所以如果它能够被精确的控制意图,它的效果会非常好;
所以让我们回到上面的小节,回顾一下媒介的瞬间性的排序:
单张图片 = 短文字 < 组图 < 长图文 < 流媒体平台上的视频 < 播客平台上的播客 < 电影院电影 < 音乐会的音乐 < 线下脱口秀。
在 AIGC 诞生之前,我们可能只能把右边的内容转化成左边的内容。
在 AIGC 诞生之后,我们是可以把左边的内容转换成右边的内容的,因为我们有了无中生有的能力!
这就是 AIGC 在媒介层面的意义,这个从生产角度来说是划时代的。
还是拿上文提到的竖屏与横屏例子来说,B 站的视频是横屏的,抖音是竖屏的,对于创作者来说,如何低成本的转化呢?答案是用 AI 生成,扩展画面。

04.
以RAG的进化来探讨
大模型的长处和短处来制作产品
4.1、AI Agent 是什么?
GoogleMind和普林斯顿联合发表了一篇论文《ReAct: Synergizing Reasoning and Acting in Language Models》,被公认为基于LLM的智能体的开山之作。
研究人员发现,在问答和事实验证任务中,ReAct 通过与简单的Wikipedia API交互,克服了推理中普遍存在的幻觉和错误传播问题。
这个比去强化模型训练强很多倍,原因是什么,大模型的大脑已经很强大了,很多时候再训练下去边际效用递减很严重,给他一个 API,相当于给这个大脑增加“五官”,它自然就一下子进化了。
4.2、Auto GPT,第一个出圈的 AI Agent
AutoGPT 可以说是第一个真正意义上出圈的 AI Agent。
它尝试设计了一个流程,任何问题都有一个通用的元思路去解决,每个负责解决问题的模块都由一个 GPT 4 去驱动。
AutoGPT 的设计者认为这世界上几乎所有的问题解决步骤都是类似的,明确问题,明确解决问题需要的步骤,完成任务,检查,总结。
所以按照这个 SOP,他们涉及了一个互相之间传递信息的 AI Agent,每个模块都是独立记忆的模型,好像几个人类在分工,一个专门负责明确问题,一个专门负责拆解问题。
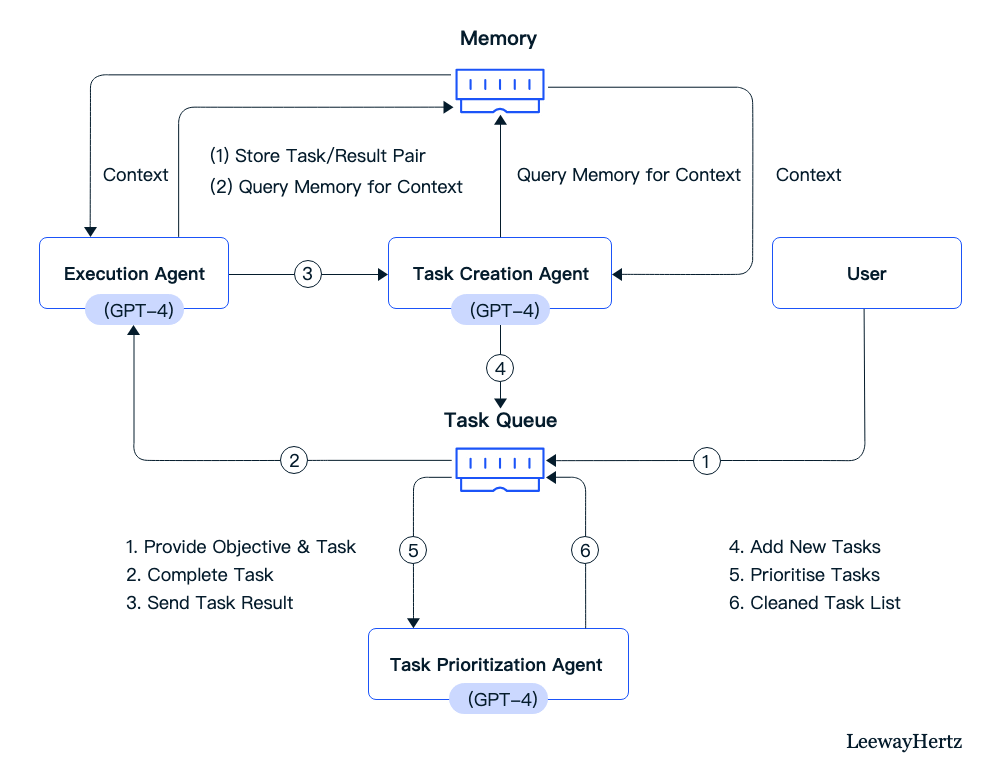
AutoGPT 是由Significant Ggravitas 于 2023 年 3 月 30 日发布在 GitHub 上开源的AI代理应用程序。它使用 GPT-4 作为驱动基础,允许 AI 自主行动,完全无需用户提示每个操作,因其简单易用在用户中大受欢迎。上线仅三周,其 GitHub 的 Star 数量已飙升至接近10万,早已超越了 Pytorch(65K),可以称得上开源领域star数增长最快的现象级项目。
Auto-GPT 是基于 OpenAI API 开发的,它的核心在于基于最少的人工输入/提示,利用 GPT-4 的推理能力解决更广泛、更复杂的问题。在具体的执行上,程序会访问互联网搜索和收集信息,使用 GPT-4 生成文本和代码,使用 GPT-3.5 存储和汇总文件。
但是很快大家就发现这个 AI Agent 是有缺陷的,比如它很容易陷入死循环,或者是不能很好的解决不确定性的,带有探索性质的问题,但是这个思路本身给大家带来了非常多的提示。
扩展阅读,Auto GPT 工作原理:
https://www.leewayhertz.com/autogpt
4.3、RAG 和 AutoGPT 的区别
RAG 其实就是检索+生成的缩写,明确了这个 SOP 主要的作用就是从特定的地方检索出来信息,然后再以更加友好的形式展现出来。
如果一个产品有十几篇说明文档,那么 RAG 就好像是一个熟读了文档的客服。
最简单的 RAG 可以参考 AI 搜索引擎 ThinkAny 第一版的原理:
MVP 版本实现起来很简单,使用
NextJs做全栈开发,一个界面 + 两个接口。两个接口分别是:
- /api/rag-search
这个接口调用
serper.dev的接口,获取谷歌的检索内容。输入用户的查询 query,输出谷歌搜索的前 10 条信息源。
- /api/chat
这个接口选择 OpenAI 的
gpt-3.5-turbo作为基座模型,把上一步返回的 10 条检索结果的 title + snippet 拼接成上下文,设置提示词,请求大模型做问答输出。以上文字引用自:
它 RAG 可以被视为是一种针对特定业务场景的 AI Agent,它和 AutoGPT 最大的区别在于三点:
- RAG 的流程是一个串行流而不是一个循环,它没有所谓的自我检查然后重新生成的过程,一方面是为了响应速度,另一方面也是为了避免自我检查造成的死循环;
- RAG 的流程中,是检索+生成,检索的部分并不是由大模型完成的,而是通过传统的搜索引擎(向量数据库、关键词匹配)来完成的,这和 AutoGPT 中几乎所有关键节点都是用 GPT 4 完成是有天壤之别的,这意味着大家意识到一个问题,在一些对上下文窗口有要求的,输出精确排序的场景,GPT 一点也不好用;
- RAG 并不是万能的,它设计出来也不指望自己能解决所有问题,实际上它更多的是解决“如何快速给答案”这个问题,有 10 篇文档,怎么快速到找用户需要的答案;
发展到这一步,大家已经意识到一个事情:这个世界上可能不存在一个万能的 AI Agent,也就是说并没有一个万能的许愿机。
至少目前工程界很少有人会再尝试投人力去做万能的 Agent,学术界还在继续。
可能有人会纠结概念,RAG 和 AI Agent 是两个完全不相关的东西,而且 RAG 最早可以追溯到 2020 年的一篇论文,历史比 AI Agent 更为久远。但是其实我认为他们在工程落地上是非常相似的,都是强调基于工具,外部数据,存储机制来弥补 AI 的缺陷,唯一的区别是 RAG 不会强调要求 AI 具备自我探索自行规划任务的能力。
现在市面上的文章,尤其是面向非技术的同学的文章,关注概念多过关注落地,这不是一个好现象。工程领域本来就有很多约定俗成的叫法,比如广告系统的 DMP,全名是 Data management platform,但是实践的时候几乎只管人群数据,总不能因为名字和实际干的事有差别就天天在那辩经。
这篇文章在介绍 RAG 的时候,就是希望从实现思路着手,给 AI 这个大脑一步一步配上了多套工具,乃至到最后替 AI 做了一部分流程设计。
希望通过这个文档去展现一个循序渐进的,也是从抽象到具象的具体落地过程,为了保证文档本身的可读性,列举的项目并不是完全一脉相承的,但是我认为这样的写作顺序对于读者来说是最友好也是最具有启发性的。
4.4、RAG 的缺陷是什么?
论文《Seven Failure Points When Engineering a Retrieval Augmented Generation System》中列举了 RAG 的 7 个弱点。
论文地址:https://arxiv.org/abs/2401.05856

通过这些故障点,我们可以发现一个问题,其实有很多故障点本身和大模型没有关系,比如搜索文档 Top K 的排序不够精确,比如无法从文档中读取信息,因为文档格式错误或者文档太脏了。
就像我们前面所说的比喻,大模型本质是一个大脑,AI 产品才是大脑搭配上五官,躯干和四肢。
不能只优化大脑,不优化四肢,那是一种偷懒行为,不要把大模型视作为万能的许愿机器。
最后让我用一个儿歌来总结一下这篇文档的核心思想:
人有两个宝,双手和大脑。双手会做工,大脑会思考。用手又用脑,才能有创造。
4.5、Graph RAG — 一种 RAG 的进化版本
Graph RAG 是微软开放的一个开源的 RAG 框架,可以被视作为是一种进一步变化和迭代的 RAG SOP,根据公开资料参考,我猜测这套技术实现思路广泛地应用在了微软的 Copilot 系统上,当然我没有找到可以证实的材料。
Graph RAG 和原本的 RAG 的区别是什么呢?
传统 RAG 的主要工作是这三个步骤:
- 把待搜索的知识做向量化处理(可离线处理);
- 当用户提出来一个关键词 or 问题,根据相似性查询查出来最相关的内容(必须是在线服务);
- 将查询出来的 Top N 的相关内容作为上下文,和用户提出的问题一起交给大模型来生成内容(必须是在线服务);
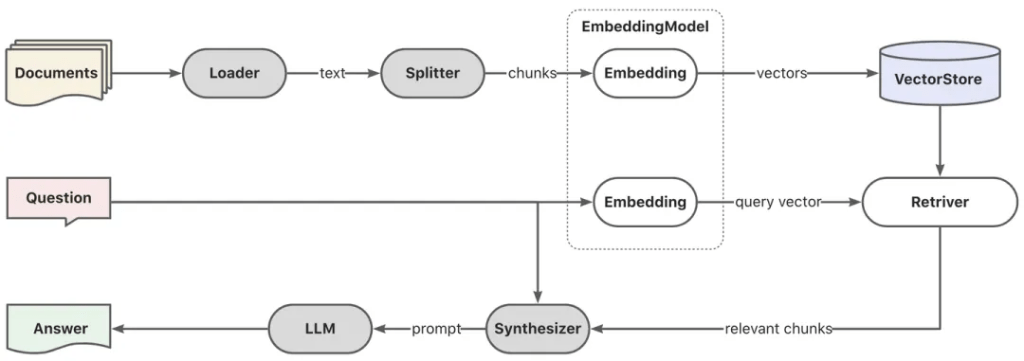
整个步骤中只有第三步是使用了大模型的。
相似性查询的效果其实是比较不尽如人意的,因为它完全是根据文字的相似水平来进行检索,和文本的语义一点关系都没有。这就导致最终 RAG 的效果往往会比较糟糕。
当然这三个步骤中间出问题的可能性很多,就像上文提到的 RAG 的 7 个待优化点,但是检索的准确性是一个最容易优化并且收益也最大的问题,那么微软是怎么做的呢?
微软认为用户可能会词不达意,同时检索也需要更加智能,所以微软将向量化检索的方法替换成借助知识图谱的检索方法。
Graph RAG 的主要工作是下面三个步骤:
- 将待搜索的知识进行一个三元组抽取(主谓宾),这个抽取的动作需要 LLM 介入,存入图数据库中(可离线处理);
- 将用户提出来的关键词,用 LLM 做一次扩散,扩散出来同义词,近义词等,然后在图数据库进行检索,找到相关文档(必须是在线服务);
- 将查询出来的相关内容作为上下文,和用户提出的问题一起交给大模型来生成内容(必须是在线服务);
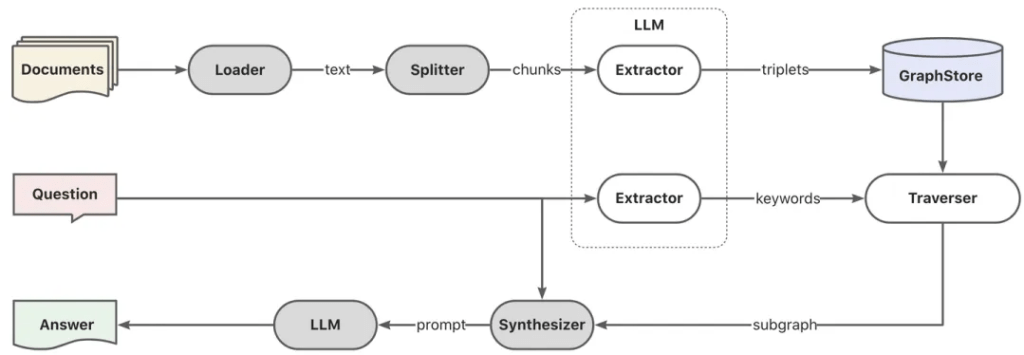
整体的步骤和架构其实没有更多的变化,但是在关键步骤上引入了大模型,作为两个独立的处理步骤。
注意,这里的独立处理步骤是非常关键的。
4.6、RAG 再进化(雕花)
在微软发布了 GraphRAG 之后,很多人都试用了,然后又发现一堆问题,于是有人发了这篇论文:《A Hybrid RAG System with Comprehensive Enhancement on Complex Reasoning》。
论文地址:https://arxiv.org/abs/2408.05141
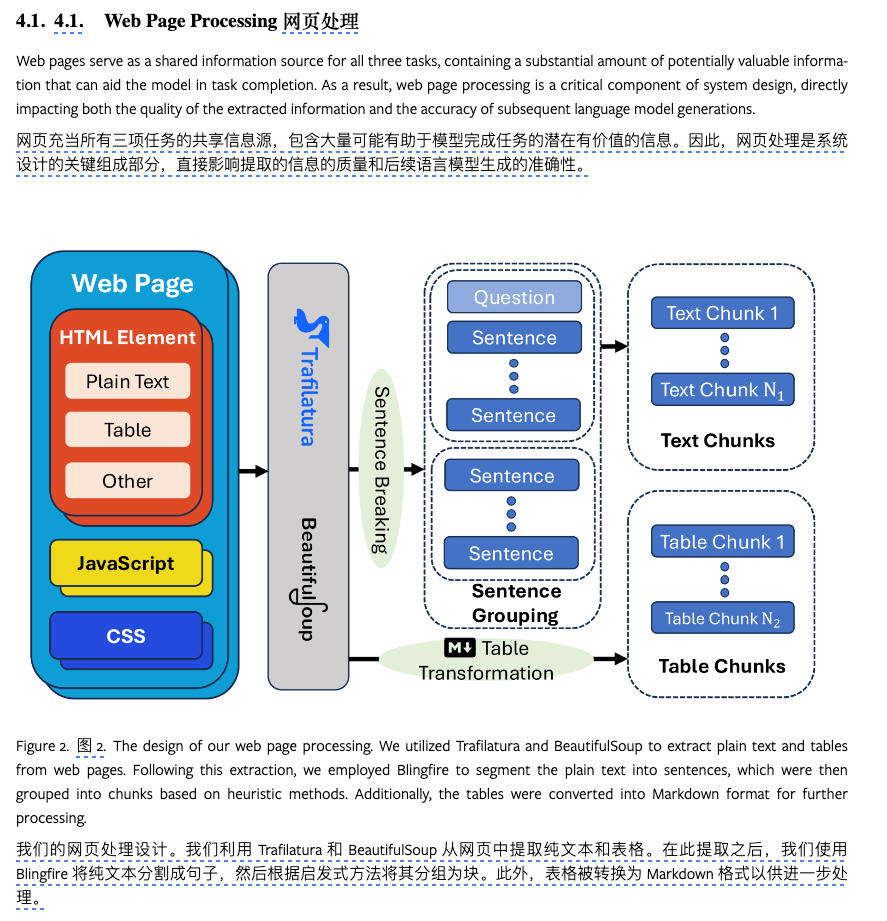
Hybrid RAG 在原来的基础上,做了几件事。
工作 1、Document 在 Loader 之前,先用 LLM 做一轮格式上的处理。
工作 2、问题分类机器
这个问题分类机器本身是一个 SVM 分类器,但是这个分类器的训练数据不是人工标注的,而是用大模型来标注的,以此减少成本和开销。


工作 3、利用大模型调用外部的计算库

当然,这篇论文里面还写了很多思路,感兴趣的同学可以自己去看论文。
这个论文质量还是很高的,6 个作者中的 5 个是北京大学人工智能实验室的学者。
05.
为什么我们曾经高估了
大模型的影响力
5.1、我们原本设想的端到端的场景问题是什么?
现在人类生产视频的工业化流程是:
- 看一下市面上热门视频的共性,往往依靠标签
- 根据热门标签生产一些脚本;
- 拍摄;
- 发到线上看数据反馈,再做迭代;
在大模型刚刚诞生的时候,其实有一个假设,假如大模型可以直接生成视频,能不能让它看抖音上的大部分视频,训练它,然后让它生产一部分。
让用户给这些大模型生产的视频点赞,大模型再把高赞的视频拿来作为正反馈继续生成视频。
如果这条路能走通,对于抖音这样的内容平台绝对是颠覆性的,现在看这个流程可以说是走不通的,其中自然有视频生成模型质量不好、不可控的原因,但是我认为更多的原因在于:
- 模型的上下文窗口限制
- 模型的成本太高
这两个是几乎无解的问题,估计未来相当长(10 年)的时间都很难解决,所以我不认为这种端到端的场景是可行的。
但是 AI 生成视频一定会成为视频工作者未来工作环节的重要补充,这点是不需要怀疑的。
5.2、所有应用都值得用 AI 重做一遍吗?
显然不,因为这个世界上 90% 的事情用规则就已经可以运转的很好,模型低效又不稳定。
很多时候我们对一个产品的要求就是,简单、高效、可以依赖,现阶段模型的不稳定性注定了它在很多场景下是不可依赖的,哪就很难谈得上取代原有产品。
还是重读一遍俞军给的知名的需求公式:
用户价值= 新体验– 旧体验– 替换成本。
很多时候用了新技术,收益可能也没有想象的那么大,这是一个事实。认为所有应用都值得用 AI 重做一遍的人显然是高估了 AI,很多人喜欢把 AI 和移动互联网类比,这是不恰当的。
从冯诺依曼计算机的架构来看,移动互联网直接把计算机的输入输出设备给改了,这首先带来了交互上的革命性变化,但这不是最重要的。
从市场上来看移动互联网真正的价值并不是交互革命,而是极大的降低了用户接入互联网的成本,使得用户数量得到了翻倍,延长了用户互联网的使用时间。
上面这两个革命性的变革,显然是这轮 AI 浪潮所不能及的,AI 既不能扩大市场,短期内也不能改变计算设备的形态。
大模型的变革更多的会体现在生产端,从而影响消费端,正如在上文理解媒介一个章节中提到的,它能带来的是生产力的极大提升,但我们现在面临的问题更多的是市场不足,生产过剩问题。
5.3、LUI 是万能的吗?
有人说这一轮 AI 会带来交互革命,从今天起我们只需要一个有聊天框的超级 App 就可以啦!
我现在就可以下这个结论,说这话的人一定是云玩家,如果这种人在公司里面,我是他的上级,我就要惩罚他晋升答辩不准写 PPT 和文档,只允许口播。
任何一种媒介和交互都是有最佳实践和独特价值的,LUI 显然不是万能的,程序员写个代码还会考虑 IDE 的 GUI 好不好使,Language UI 信徒们哪来的自信这玩意可以彻底取代图形界面?
LUI 最大的问题就是效率低,让我以企业级软件举例:
Excel 也好,PowerPoint 也好,哪怕是 BI 软件也好,软件除了降低门槛之外,还有一个很重要的作用就是「约束」使用者。
在这个场景下约束不是一个贬义词,是一个褒义词。这些软件内置的所有功能都是在漫长的时光中迭代出来的,里面凝聚了无数软件开发者与使用软件的企业的经验和最佳实践。
打开 Sensors Analysis(神策数据旗下)和 DataFinder (火山引擎旗下)这两个产出自不同公司的行为分析软件时,会发现二者的功能极为相似,事件分析、漏斗(转化)分析、留存分析等等。我甚至怀疑使用这些软件的企业客户们使用习惯也会高度类似,因为这些软件里面凝聚的功能本身就是最佳实践。
对于一个没有什么统计分析能力的运营来说,让他去面对 GPT 的文本框描述清楚自己需要一个漏斗分析实在是太困难了,还是用神策比较简单。
GPT 如果能够获得关于漏斗分析的详细计算逻辑,也可以一定程度上的引导用户,但前提是用户得能说出来漏斗分析这四个字,实际上脱离了界面很多人都不见得能描述的清楚自己想要的是什么。
LUI 不是万能的,对 LUI 的过度追求,甚至把 LUI 与 AI native 划等号这种想法都是错误的。LUI 只是在特定范式下才是有意义的。
5.4、复杂的 UI 是一段弯路吗?
现在市面上最领先的开源文生图 UI 叫做 ComfyUI,如下图所示:
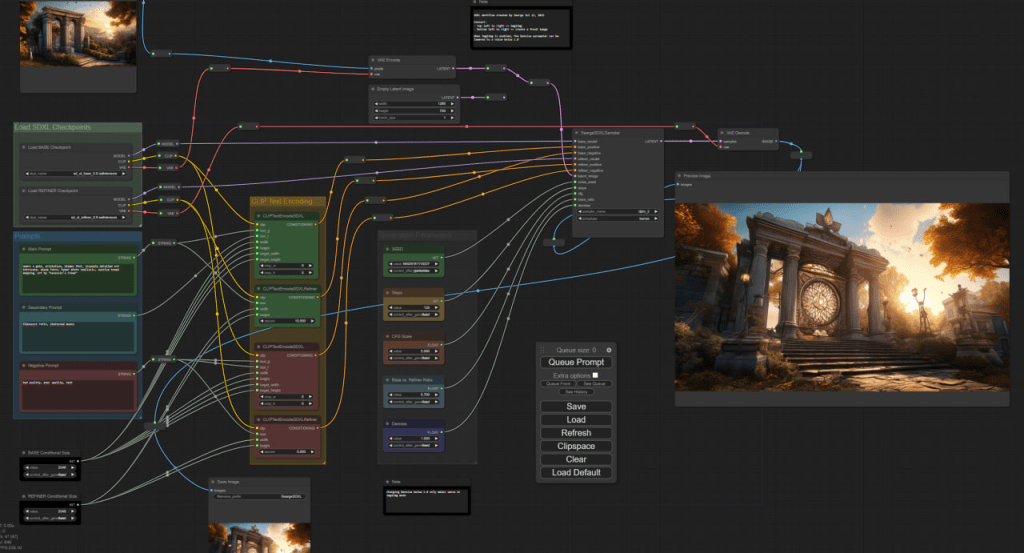
ComfyUI 和我们脑子里面想的敲敲文本就能调用的文生图 AI 差异很大,感觉更像是一个低代码平台,为什么?
因为在工业界需要追求精确控制,纯粹用提示词是无法准确表达精确控制的语义的,必须得用 GUI 才能表达出来。
比如上面这个图,其实里面做的事情就是把一个建筑物换成另外一个建筑物,并且尽可能不要改变其他东西,这种精确控制对于模型这种本质依靠数学概率驱动的东西来说是非常困难的,所以才搞得这么复杂。
那么问题来了,上面这种 UI 是一段弯路吗?
其实我乍一看我也觉得这个太离谱了,如果让我用 Photoshop 或者醒图类似的事情应该也能做,而且 UI 应该没有复杂,但是细想之后我认为这个东西非常有价值。
我认为如果把这种 UI 给到用户,这肯定是一段弯路,但是如果我们把上面这个操作包装成一个场景,给用户的就是让用户上传两张图这样的动作,这不就是一个最简单的产品了吗?
也就是说我上面说的,醒图和 PhotoShop 的功能,其实以后完全是可能用这样的 UI 搭建出来然后包装给用户的。
所以上面的 UI 是完全可以提供给专业用户的,这样的 UI 可以变成一个引擎,产品内成千上百的功能都可以通过这么一个元引擎被源源不断地生产出来。
这就是大模型真正的价值,这是生产力成百倍的提升。
5.5、大模型真正的价值是什么?
如果大模型既不能给交互带来质的变化,又不是一个万能的许愿机,甚至连端到端生成 Feed 流都做不到,那么大模型真正的价值是什么呢?
大模型真正的价值在于给产品经理和工程师这样具备非凡创造力的人一个增幅器。
这是一个不需要训练的万能模型,而且大概率比专属模型更强。
这意味着产品经理和工程师只要能想清楚 SOP,想清楚哪些问题可以用大模型来解决,就一定能以比较低的成本解决,原本一些需要训练自己私有模型的事,现在依靠公有模型就可以解决了。
很多原本像高山一样的成本,现在也是可以逾越的,金钱和数据量不再是训练模型的拦路虎,你只需要会写 prompt ,会搭工作流就可以了。
06.
对产品经理的工作方法
启示是什么?
6.1、业务!业务!业务!数据!数据!数据!
新鲜的数据和能持续产生新鲜数据的业务,是一个大模型的生命力所在。
一个 RAG 做的再牛逼,如果数据库很糟糕,结果就是很糟糕的。
一个模型再挫,只要数据足够好,照样是一个好工具。
在 AI 时代,数据的问题只会被放的更大,AI 搜索如果在一堆屎山数据里面做搜索,充其量不过是又造了一根搅屎棍。
任何时候,能持续生产真实交易数据和优秀内容的业务都比大模型本身重要。
6.2、看论文不是产品经理避免 FOMO 的最佳途径,动手尝试可以避免 FOMO
我认为一个比较清晰的事实是,目前工业界短期内一定高估了大模型的作用。
前段时间我写了一个段子:每一个 App 都值得思考是否能用 AI 重做一遍,然后就会发现值得重做的只有 10%。
短期内的资源投入很大程度上是源自于投资人和大厂决策者的 FOMO 心态,这种心态某种角度来说是不健康的。这种 FOMO 的心态也会传导给产品经理,于是很多产品经理都开始看论文(比如本文作者),但在我看来产品经理看论文其实没什么用,图一乐的作用更大。
论文都是锤子,但是对于 PM 来说更重要的是钉子在哪里。所以与其关心最新的学术界又发了什么,不如关心一下 Product Hunt 上面哪些 AI 产品又登上了当日第一,并且赚钱了。
与其 FOMO,不如动手多用用,以前移动互联网刚刚兴起的时候,大部分产品经理手机里面不得装小几百个 App,天天研究来研究去的。去用一下市面上最好的应用,并且尝试逆向它,会有多很收获。
写这篇文章,写接近 2 万字,发现大模型那么多的坑,而且每个坑都能找到一些关联的论文。不是因为闲的蛋疼去看论文,而是因为一直在捣鼓 AI,然后发现这也有问题那也有问题,不得已去搜索,搜到了论文。
原来大家都有这个问题,有的人就是有钻研精神,发现了问题还会深入研究,然后写一篇论文。哎,人比人真的气死人。
如果仔细看就会发现我看的大部分论文都是工程师论文而不是算法论文,因为就像我强调的,大模型的弱点需要工程弥补,工程是研发和产品经理共同搭建的,看不懂算法的论文不打紧,看不懂工程师的论文可能真的得反思一下。
6.3、产品经理必须要学会自己调用 API
正如文提到的,未来 AI 产品团队的能力,不取决于谁家模型更强,反正开源模型一定最终会变得最强,而取决于谁家能用好 AI 模型。
而谁能用好 AI 模型,又取决于哪个团队做实验的本里强,谁能更快的做完更多的实验,谁就牛逼。
有的人可能会问,我用 coze 或者是 KimiChat 行不行,我的答案是不行。
因为这两个本身就已经是 AI 产品了,和 AI 的 API 差距很大,给 KimiChat 传个 PDF,人家解读的又快又好,你怎么知道它解读的好是因为模型牛逼,还是因为 PDF 格式转 MD 数据清理的好呢?
这就需要产品经理必须要具备非常快速的裸调用 API 做实验的能力。
那么不会写代码,怎么快速获得这种能力?用 Dify 或者 n8n 这样的低代码平台来解决。
就我自己来看,我认为 n8n 更靠谱。n8n 是一个 Coze 的开源免费上位替代,一个可视化低代码自动化 Workflow 平台,能够方便的让不会写代码的朋友体验 AI 开发的乐趣和效果。
用它可以轻易的创建很多扣子完成不了的复杂自动化 Workflow。比如 Webhook 触发,比如 1000 多种第三方接入,比如发起自定义的 HTTP Request。
并且因为 n8n 不是从这一轮 AI 浪潮才开始做的,所以它的生态也比这一轮 AI 后才涌现出的 Workflow 工具(比如 Dify)更完善,官方接入的集成服务更多,社区更活跃。
n8n 就是大模型的五官、躯干和四肢,动手又动脑,才能有创造。
在这里我推荐一个 n8n 的中文教程《简单易懂的现代魔法》,这应该是目前市面上最好的 n8n 中文教程。
教程地址:https://n8n.akashio.com/
6.4、几个 AI Agent 实践的建议
6.4.1、设计 Agent 的关键思路
想象一下 20 个实习生帮你干活,你要怎么分配任务?实习生的特点是什么?
- 能执行
- 无法拆解复杂问题
- 执行顺序可能是有问题的,你如果不规定执行顺序,会怎么样?可能会拖慢项目进度
- 记忆力一般,一下子太多任务记不住,可能会忘记
- 可能会出错,所以最好有交叉验证
所以如果你把 AI 视作为一个又一个不知疲倦的实习生,你认为他们能干嘛?当然是设计好 SOP 和产出物标准,让他们去做这些量大且重复性的工作啦。
当然实习生和 AI 有一个比较大的差别,就是 AI 确实比实习生,甚至不少正式员工在解决特定问题的时候强很多。
也贵很多,GPT-4 回答一个问题一个来回 API 的定价可能在 3 美分左右。
人比机器便宜,可能是未来大家不被 AI 淘汰的重要理由(bushi)。
6.4.2、把任务拆小拆细,避免互相影响
把一个复杂问题拆成多个简单问题,然后再让模型处理有两个好处:
第一、正如上文所描述,大模型的不稳定性和它接收的文本规模大小完全是呈正相关的,如果把问题拆小就意味着单词任务模型要处理的文本变少。
第二、一些简单的问题根本没必要用大模型,甚至可以用简单的模型或者是纯逻辑去判断,更便宜、速度更快,甚至效果可能会更好。
6.4.3、区分离线任务和在线任务
以 Graph RAG 架构为例子, 它一共分为三个步骤:
- 将待搜索的知识进行一个三元组抽取(主谓宾),这个抽取的动作需要 LLM 介入,存入图数据库中(可离线处理);
- 将用户提出来的关键词,用 LLM 做一次扩散,扩散出来同义词,近义词等,然后在图数据库进行检索,找到相关文档(必须是在线服务);
- 将查询出来的相关内容作为上下文,和用户提出的问题一起交给大模型来生成内容(必须是在线服务);
其中前两个步骤是离线任务,离线任务意味着可以花费较多的时间对数据做精细化的处理,比如我们可以用一个开源但是性能强悍的大模型,用自己的服务器去跑任务,以此来在保证质量的时候降低成本。
而在线任务则意味着需要较强的时效性,如果在线任务本身复杂度并不高,也可以选择更加轻量级的模型来保证回复速度。
同时离线任务的结果会被存储并且反复调用,用质量更好的模型相当于做了一些固定成本的投入,而在线任务都是和用户交互直接相关的,这些本质上是边际成本。
6.4.4、每一个离线任务都可以考虑用模型来解决
在 Hybrid RAG 中,对 html 转 MD 的工作用的是 Python 库进行的,其实这项工作如果纯粹追求效果的话,完全可以考虑直接用大模型来做。
当然具体是用 Python 库还是用大模型,其实是取决于成本和效果的考量的,这个也需要通过实验来证明。
我自己的经验是这种数据清洗的工作适合用 Python 库做一轮,再用大模型做一轮清洗,效果可能会更好,但是很多时候 Python 库已经足够干净了,中间夹杂一些错误的格式编码其实也不影响后续大模型的判断,这种情况下做不做都是无所谓的。
总而言之大模型在特定环节的工作能力是非常强的,如果不是考虑成本,其实几乎每个环节都可以用大模型解决。
6.4.5、成本和效果要做 Trade off
众所周知,大模型回答有一定的随机性,要怎么解决这个问题呢?当然是一个问题重复问几遍啦。
比如论文《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》中提到的如何测试两种 RAG 方法的效果,用人力标注太麻烦了,所以他们连检查样本的工作都交给大模型来做了,真是牛逼(有钱)。
为了保证结果正确,一个标注要重复做 4-5 遍,成本自然也是 4-5 倍。
对于设计产品的同学来说就非常需要判断成本和效果之间怎么平衡了。

6.4.6、Agent、微调、提示词之间的边界与最佳实践
如果我们把提示词工程、Agent 的建设和模型微调对应到我们给一个人布置任务,就可以这么理解。
- 提示词工程相当于你在布置任务的时候说的很详细。
- Agent 建设相当于你给这个人布置任务的时候,把 SOP 拆清楚,并且告诉他公司里面有哪些工具可以用。
- 模型微调相当于做培训。
所以完成一个任务,可能三种手段都需要用上,但是三种手段的成本是不一样的。
而为了完成一个任务,应该用哪种优化手段,这就是目前工程、算法、产品、学者这几方面都非常模糊的地方,这个就好像是在航海或者挖矿,又像是临床医学,怎么决定用什么手段,本质上是一个“实验”,而不是一个“推理”。
这也就是为什么上面列出来的每一篇论文都需要列非常多的基准测试,因为设计这些 Agent 的人自己都不知道结果到底好不好,需要实验才能验证。
所以我认为,未来哪个团队应用 AI 的能力强,哪个团队应用 AI 的能力弱,其实就取决于:
- 这个团队有没有牛逼的基准测试参考答案;
- 这个团队能不能有一个平台可以更快的验证自己的设计是不是合理的;
谁实验做得快,谁就牛逼,工程化产品化反而是最后一步。
最后我个人建议是能不要微调,就不要微调,因为微调会改变模型的参数层,成本很高而且无法迁移。而且微调的本质是在和大模型团队卷算法,卷数据,内卷在长期来看,是没有意义的。
如何转行/入门AI产品经理?
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,转行/入门AI产品经理,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI产品经理入门手册、AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI产品经理入门手册

三、AI大模型视频教程

四、AI大模型各大学习书籍

五、AI大模型各大场景实战案例

六、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 5161
5161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









