







在医学图像分割中,基于注意力机制和卷积神经网络的Transformer在提高性能方面起到了重要作用。然而,早期的模型往往在分割小而形状不规则的肿瘤时表现不佳。
为此,作者提出了一种基于SMA架构(Synergistic Multi-Attention)的高效Transformer模型,用于增强小肿瘤和器官的分割效果。
SMA结构可以同时捕捉局部和全局特征,适合用于医学图像分割。该结构包括两个关键组件。
首先,作者提出了一种具有像素注意力、通道注意和空间注意力的协同多注意力(SMA)Transformer块,用于特征丰富。
其次,为了解决注意力机制转换和特征融合过程中可能出现的信息损失问题,作者设计了一种特征融合调制器。
该模块通过减轻重采样导致的形变信息损耗,来加强通道注意力和空间注意力的整合。
为了评估作者的方法,作者对各种医学图像分割任务进行了广泛实验,包括多器官分割、肝肿瘤和膀胱肿瘤分割,实现了最先进的结果。代码和模型可在https://github.com/CXH-Research/SMAFormer 处找到。
I Introduction
早期肿瘤诊断至关重要,因为晚期癌症通常无法治愈[1]。人工智能(AI),特别是医学图像分割,在早期诊断中发挥着关键作用[2, 3, 4, 5]。然而,准确地分割医学图像,尤其是微小的肿瘤或器官,仍然具有挑战性,因为深度卷积神经网络存在特征损失。
尽管最近基于卷积神经网络(CNN)的方法展示了一定的前景,但它们捕获小物体特征的能力仍然有限。多注意力机制提供了一定的改进,但仍缺乏最佳的集成和性能。
本文提出了SMAFormer,一种高效有效的基于Transformer的医学图像分割模型。受ResUNet [23]启发,SMAFormer将Transformer块与U型残差结构相结合,以增强多分辨率特征学习。
作者的关键贡献包括:
- SMAFormer架构:一种新的残差U型Transformer模型,集成注意力机制、U型架构和残差连接,以实现高效有效的医学图像分割。
- 可学习分割调制器:一种可嵌入的模块,用于多尺度特征融合,增强不同注意力机制之间的协同作用。
- 最先进的性能: extensive的实验表明SMAFormer在各种医学图像分割数据集上实现了最先进的性能,超过了之前基准测试结果,如在LiTS2017和ISICDM2019数据集上的Swin UNETR [24]。
II Related Work
相关工作
近年来,随着人工智能(AI)技术的快速发展,越来越多的研究开始将目光投向了人机交互领域,特别是在自然语言处理、计算机视觉和机器学习等多个领域。本文旨在回顾和评述相关领域中的重要研究成果,并探讨当前研究的挑战和未来发展方向。
自然语言处理
自然语言处理(NLP)是AI的一个重要子领域,它主要关注计算机如何理解和生成人类语言。在最近几年中,NLP领域取得了许多突破性的进展,包括自然语言处理模型的深度学习、自然语言生成和理解、语义分割和知识图谱等方面。其中,深度学习作为一种高效的机器学习方法,已经成为了NLP研究的热点之一。最近的一些研究表明,深度学习在文本分类、命名实体识别和情感分析等任务上取得了比传统机器学习方法更好的性能。此外,深度学习还可以通过预训练模型和迁移学习技术来解决数据集不平衡和数据匮乏等问题。
计算机视觉
计算机视觉(CV)是AI的另一个重要子领域,它主要关注计算机如何处理和理解图像和视频数据。在计算机视觉领域,深度学习也取得了很多重要的进展。深度神经网络模型已经成为计算机视觉任务中的标准模型,如卷积神经网络(CNN)和生成对抗网络(GAN)。此外,深度学习还促进了图像和视频生成、视频分割、目标检测和跟踪等领域的发展。最近的一些研究表明,深度学习还可以通过半监督学习和强化学习技术来提高图像和视频处理的效率。
机器学习
机器学习是AI的核心技术之一,它基于数据和经验自动改进算法,以达到预测和分类等目标。最近几年中,机器学习中的一些重要进展包括深度学习、集成学习和强化学习等。其中,深度学习作为一种高效的机器学习方法,已经成为了机器学习领域中的热点之一。最近的一些研究表明,深度学习还可以通过预训练模型和迁移学习技术来解决数据集不平衡和数据匮乏等问题。此外,机器学习还可以通过半监督学习和强化学习技术来提高预测和分类的效率。
Medical Image Segmentation
医学图像分割涉及到将医学图像分割成不同的区域。U-Net架构[25]因其提取详细特征的同时保持上下文信息而广泛受到认可,其衍生品如ResUNet[23]将U-Net与ResNet[26]相结合。ResNet的余弦连接有助于通过确保平滑的信息流动来防止梯度消失,从而显著提升了分割性能。
ResUNet利用了残差连接和跳跃连接以实现有效信息传输和特征集成,使其在各种分割任务上具有高度的效果。UNet++[27]通过引入中间节点进一步改善了U-Net,以实现更好的内层通信。作者的SMAFormer将跳跃和残差连接相结合以优化分割结果。
Vision Transformer
Transformer (Transformers)通过全局自我注意力机制,在捕捉图像中的长程依赖性方面表现出色,这一点由视觉 Transformer (ViT)[28]得到证实。这种架构在图像分类方面超过了传统的卷积神经网络(CNNs),并被应用于医学图像处理,Swin Transformer [29]等模型因其受欢迎而得到了应用。混合模型如ResT[30]将ResNet和 Transformer 结合,以提高性能。
在医学图像分割中,注意力机制已经被集成到U-Net架构中,出现了U形 Transformer 如TransUNet[31],它们将CNN和 Transformer 结合,用于编码全局上下文。然而,许多现有的模型,包括TransUNet[31]并未充分利用 Transformer 的潜力。为解决这一问题,作者提出了一种基于残差U形 Transformer 的结构,有效地将注意力机制融合在一起,以提高分割性能。
III Method
Overview
图1所示的SMAFormer采用了一种分层U型架构,类似于ResU-Net [32, 33],在其中编码器和解码器之间通过跳跃连接和残差连接实现信息有效传播。
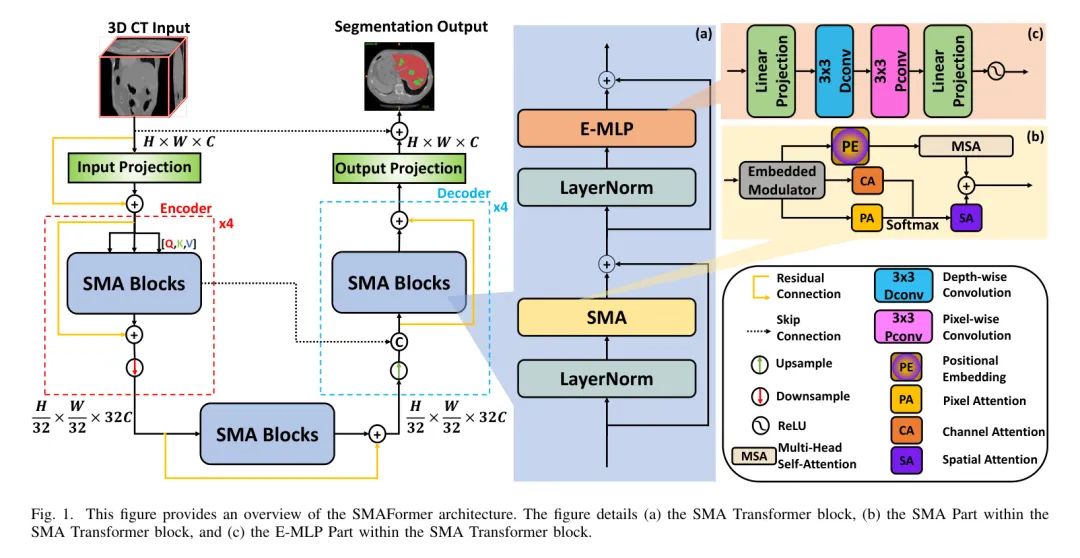
给定一张3D医学影像I∈R^{3×H×W},SMAFormer首先通过一个包含3×3卷积和ReLU激活的初始投影层提取底层特征。提取的特征经过一个四阶段的编码器处理,模仿U-Net结构。每个编码器阶段都包含一排SMA Transformer块(详见第III-B节),用于捕捉多尺度特征,随后是一个降采样层。
降采样层执行两个关键操作。首先,它在嵌入调制器(讨论在第三节-C中的部分)内记录位置信息。其次,它使用了一个由三个3×3卷积构成的残差卷积块,步长为2,来降低特征图的空间维度,同时增加通道数。通过残差连接进行降采样过程的丰富,使得长程依赖性得到保留。具体来说,给定输入特征图,第i个编码器阶段的输出是,其中表示卷积特征,代表残差连接的特征。
模仿编码器,解码器包含四个对称阶段。每个阶段都以一个2×2转置卷积开始,将特征图上采样,有效将通道数减半,将空间维度加倍。随后,上采样的特征与相应的编码器特征通过跳跃连接进行拼接,从而促进高阶语义信息的融合与低阶空间细节。最后,一个输出卷积层处理拼接后的特征,生成分割预测。
SMA Transformer Block
直接将传统Transformer[34]应用于医学图像分割,面临着两个主要挑战:
(1)难以分配注意与相关区域:特别是在不需要针对医学图像进行微调的情况下,Transformer往往难以将注意力集中在具有医学意义的区域,这会阻碍其在多器官或多肿瘤分割任务中的表现。
(2)局部上下文捕获有限:在准确分割诸如器官或肿瘤等小型结构时,局部上下文起着关键作用。具有全局接收区域的传统Transformer往往无法充分捕获这种局部信息。
为了解决这些问题,作者提出了合成多注意力(SMA)Transformer块,如图1所示。这个块综合利用了三种不同的注意力机制和多头自注意力,实现强大的、精确的分割。
Iii-B1 Synergistic Multi-Attention (SMA)
与限制在局部窗口内的自注意力方法不同,SMA采用了一种结合了通道注意力、空间注意力和像素注意力的协同方法,并与多头自注意力相结合。这种协同方法使得模型能够有效地捕获多尺度特征,并处理医学图像中可能存在的变形,如图1(b)所示。给定特征图,SMA首先将其分成 patch 并 flatten 通道。然后将平行的特征通过矩阵乘法传递给三个注意力分支(通道注意力、像素注意力和空间注意力)进行并行处理。接下来,像素注意力和通道注意力的输出通过矩阵乘法与空间注意力分支的输出相加,进一步处理。最后,所有三个分支的输出进行融合以生成最终的注意力图。
Iii-B2 Enhanced Multi-Layer Perceptron (E-MLP)
识别标准自回归网络(FFNs)在捕获局部上下文方面的局限性[35, 36],作者在Transformer块内的E-MLP中通过引入深度维和像素维卷积[37, 38, 39]进行增强。如图1(c)所示,E-MLP首先使用线性层将输入标记投影至更高维空间。然后,这些投影的标记被 Reshape 为2D特征图,并经历一个3x3像素维卷积以及一个3x3深度维卷积,有效捕捉局部上下文信息。然后,这些特征被 Reshape 为标记并再次投影至原始的通道维,过程中应用另一个线性层。最后,使用GELU激活函数[40]引入非线性。
在SMA Transformer块内计算可以数学表示如下:
其中表示第i个块的输入特征向量,和分别是 和 模块的输出, 表示层归一化。
在每个Transformer块中,SMA与E-MLP之间的协同交互使得SMAFormer有效捕获全局和局部上下文信息,从而提高分割性能。
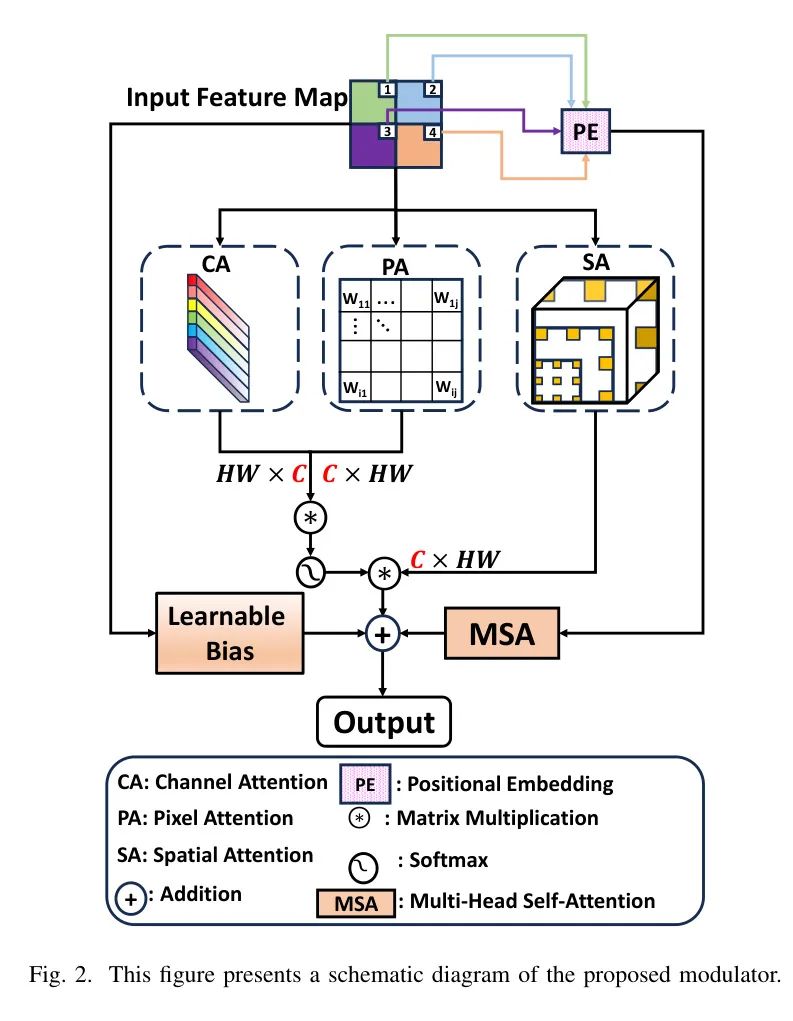
Multi-Scale Segmentation Modulator
为了进一步增强SMAFormer捕捉细微细节的能力并促进协同多注意力,作者提出了多尺度分割调制器,如图2所示。
Objective Function
作者使用全二进制交叉熵(BCE)损失 和 Dice 损失 结合的二者的优点来训练 SMAFormer,即二进制差异(BD)损失 [41]:
(2)
其中 表示真实分割 Mask , 表示预测的分割 Mask , 是图像中的像素数。BCE 损失惩罚预测标签分布和真实标签分布之间的差异,而 Dice 损失鼓励预测和真实分割区域之间的重叠。这个组合损失函数鼓励既有准确的像素级分类,又有强大的边界划分。
IV Experiments
以下是第IV实验部分的开始。
在本文中,作者介绍了一种基于深度学习的方法,用于解决字符识别任务。实验结果表明,所提出的模型具有良好的识别性能。本节将详细介绍实验方法、实验结果及分析。
Datasets and Implementation Details
本文使用了三个公开的医学图像分割数据集:LiTS2017 [45],ISICDM2019 [46] 和 Synapse [47]。遵循 nnformer [44] 的方法,作者对所有数据集进行了80/15/5的训练/验证/测试划分。输入图像被 Reshape 为512乘512像素。
SMAFormer 实现于 PyTorch 并在一个 NVIDIA GeForce RTX 4090 GPU 上进行训练,使用 SGD [48] 带动量(0.98),权重衰减(),以及余弦衰减的学习率(初始:,最小:)。数据增强包括随机水平翻转和旋转。作者使用来自 [49] 的预训练模型。结果以五倍交叉验证的平均值报告。一些结果来自 [44] 和 [50]。
作者使用两种广泛使用的指标:Dice 系数评分(DSC) 和 平均交点与超交点(mIoU) 来评估分割性能。
Comparisons with State-of-the-Art Methods
本小节对比了SMArt-former的方法性能与最新的方法(表格I和II)。
Iv-B1 Liver Tumor Segmentation (Table I)
SMAFormer在性能上取得了优越的表现(DSC:94.11)。
Iv-B2 Bladder Tumor Segmentation (Table I)
SMAFormer再次展示了优越的性能(DSC: 96.07)。
Iv-B3 Multi-Organ Segmentation (Table II)
"SMAFormer"在Synapse数据集上取得了最先进的性能(平均DSC为86.08%),在八个器官中有五个器官的最高DSC得分。尽管由于任务复杂性,它在几个指标上略有落后,但它的表现仍然显示出它在多器官分割任务中的潜力。
Visualization of Segmentation Results
图3展示了SMAFormer在LiTS2017数据集上的优越性能,准确地分割出其他方法难以处理的微小肿瘤结节。
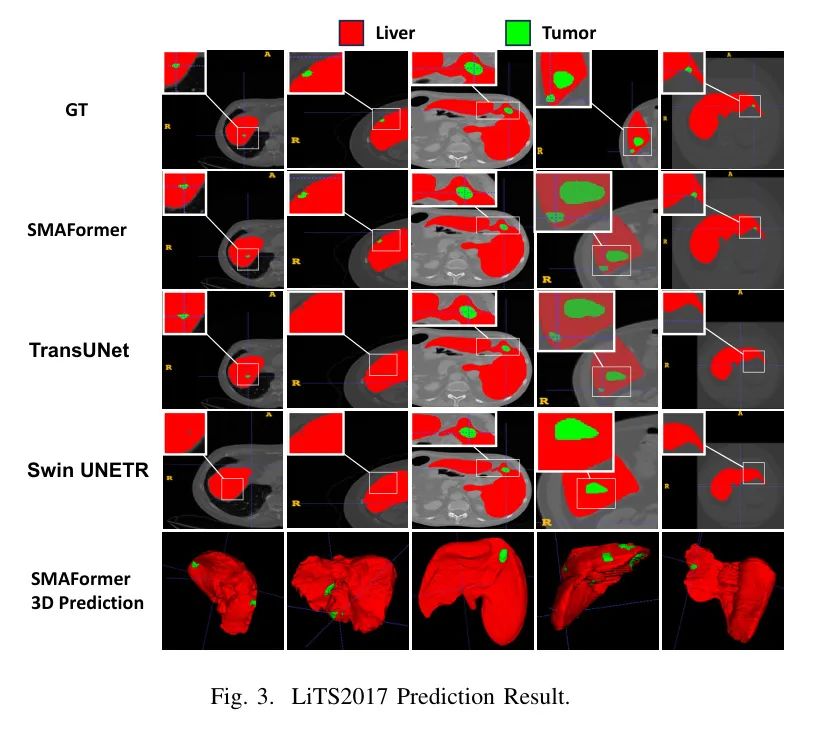
图4说明SMAFormer在具有不规则形状的微小肿瘤病例上的准确分割能力。
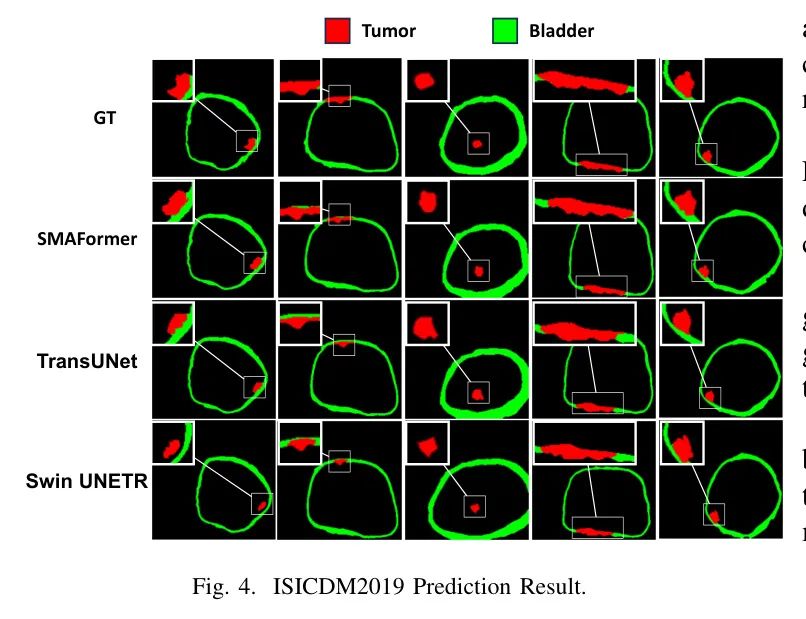
图5展示了SMAFormer在Synapse数据集中对各种腹部器官进行一致和准确的分割,突出了其强大的鲁棒性和泛化能力。
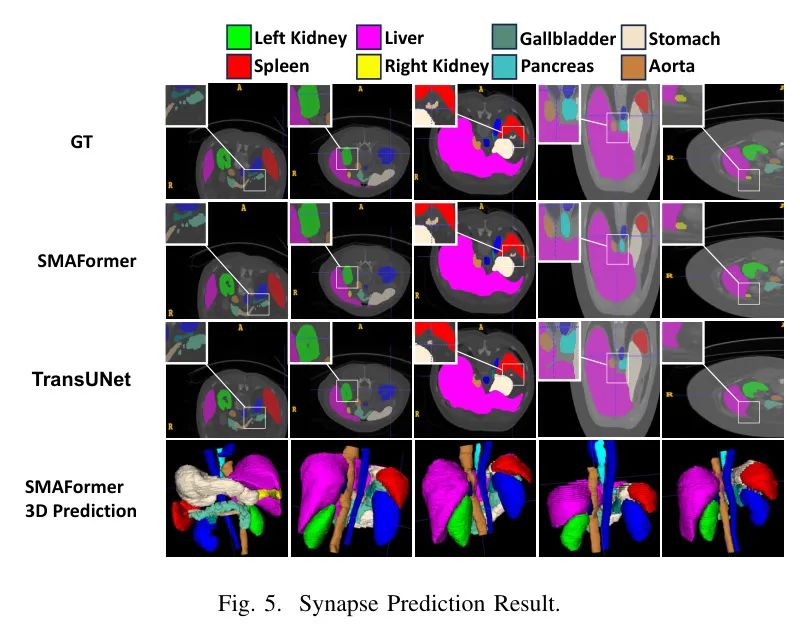
总之,SMAFormer在各种医学图像分割任务上始终优于现有方法。其优越性能归功于SMA变换块、特征融合调制器与E-MLP的协同作用,显示出它可能是医学图像分割的强大工具。
Ablation Study
本小节通过在ISICDM2019和LiTS2017数据集上进行的消融实验(实验设置与第IV-A节相同),考察SMAFormer中的每个组件对性能的影响。表格III总结了结果。
用标准的Transformer块替换SMA块(仅有多头自注意力结构)降低了两个数据集上的性能,突出了在医学图像中集成通道、空间和像素注意力的重要性(表格III)。
同样,用标准的FFN替换E-MLP模块导致性能下降,强调了在E-MLP中深度加权和像素 Level 的卷积的捕获局部上下文的价值(表格III)。
取消多尺度分割调制器也降低了性能,证实了它在促进协同多注意力并增强细微纹理捕捉中的作用。
总之,消融实验表明SMA块、E-MLP模块和多尺度分割调制器对于SMAFormer在医学图像分割方面的优越性能都是必不可少的。
V Conclusion
在本文中,作者提出了 SMAFormer,一种基于 Transformer 的全新医学图像分割架构,旨在实现高效、准确的医学图像分割。
该架构的关键创新在于神经多维协同自注意力(Synergistic Multi-Attention)模块,它有效地将像素、通道和空间注意力机制集成起来,以捕捉局部和全局的上下文信息。
这种神经多维协同方法解决了传统 Transformer 在准确分割医学图像中小型和形状不规则的肿瘤和器官上的限制。此外,引入一种多尺度分割调制器增强了 SMAFormer 在不同尺度上保留显著特征的能力,并进一步促进了多种注意力机制之间的协同作用。
在三个公开可用的医学图像分割数据集上进行的广泛实验表明,SMAFormer 实现了最先进的性能,在准确分割各种器官和肿瘤方面超过了现有方法。
本研究中取得的结果表明,SMAFormer 作为医疗专业行人在诊断、治疗规划和对疾病监测中有望成为一种强大、有效的工作工具。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 52
52

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









