






3D生成也能支持检索增强(RAG)了。
有了检索到的参考模型之后,3D生成效果更好,还具有极强的泛化性和可控性。
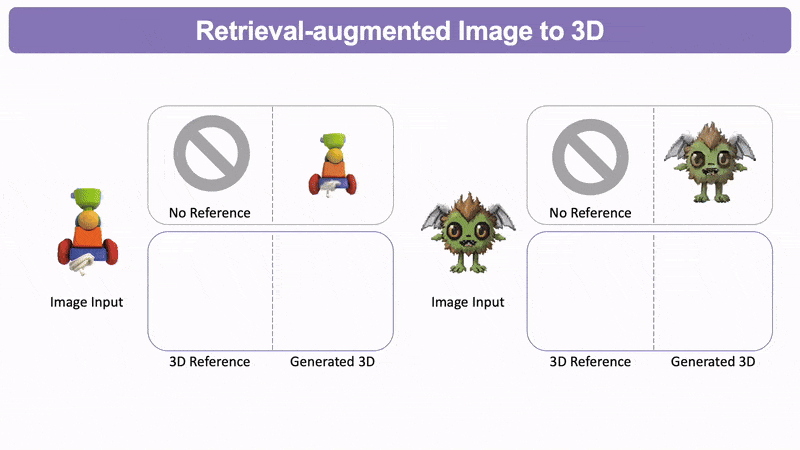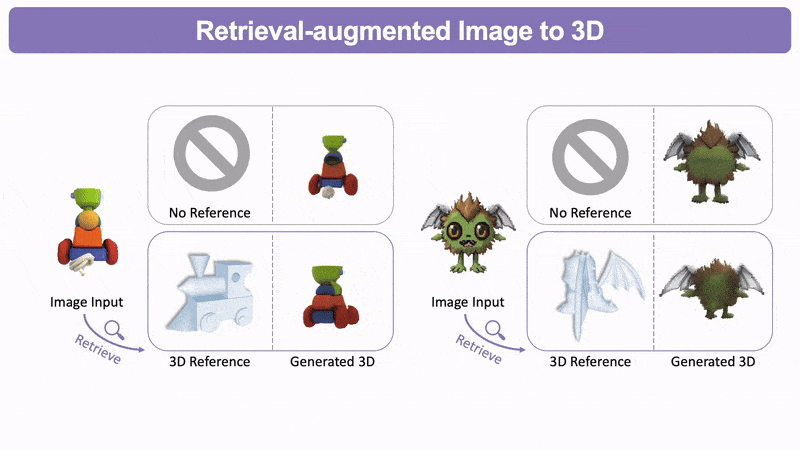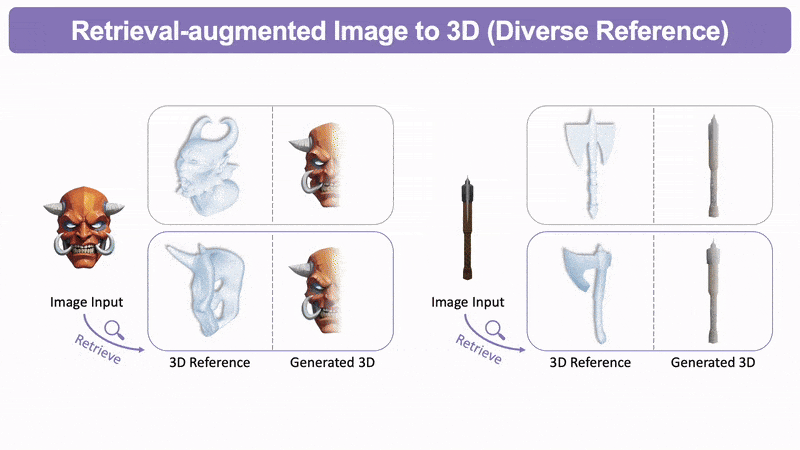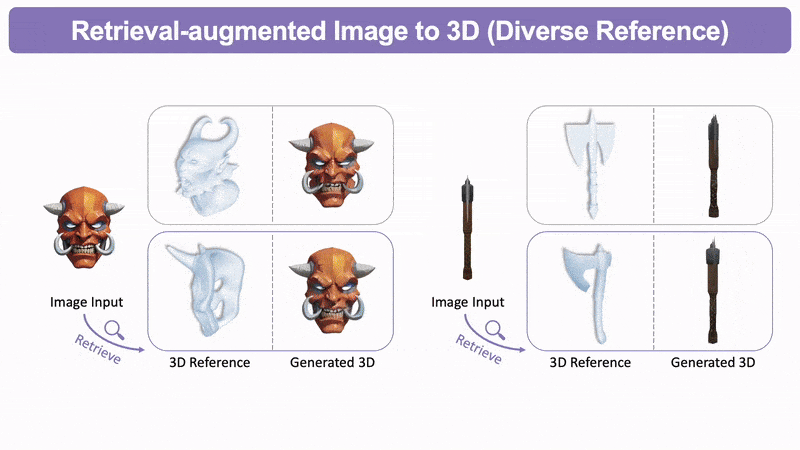
比如像这张,它生成几何质量得到了极大的改善。

还可以实现主题一致的3D到3D生成,仅需自参考输入的3D模型即可支持该功能。之前的相关研究需要约1小时,现在压缩不到10秒。

来自香港城市大学、上海人工智能实验室、香港中文大学和南洋理工大学S-Lab的研究人员提出了一种名为Phidias的新3D生成框架。
该框架将语言和图像生成领域中常见的检索增强生成(RAG)引入3D生成。
Phidias是一种参考增强的扩散生成模型。
该模型统一了文生3D、图生3D和3D到3D生成等任务,其利用检索到的或用户提供的3D参考模型来指导3D生成过程,从而提高了生成质量、泛化能力和可控性。
Phidias包含三个关键组件:
-
1)用于动态调节控制强度的元控制网络(meta-ControlNet);
-
2)用于减轻输入图像和3D参考模型冲突的动态参考路由模块(dynamic reference routing);
-
3)用于支持高效自监督学习的自我参考增强模块(self-reference augmentation)。

01 首个检索增强3D生成模型
本文主要贡献包括:
-
提出了首个基于3D参考的、3D感知的多视图扩散生成模型。
-
提出了三个关键组件以增强算法的性能。
-
本文用单个算法统一了可控的文生3D、图生3D和3D到3D生成等任务,支持各种可控3D生成的下游任务。
-
大量实验表明,本文提出的算法在定量和定性的比较评估中都显著优于已有算法。

Phidias通过两阶段来生成3D模型:1)基于参考增强的多视图生成;2)基于稀疏视角的3D重建。
给定一张概念图,Phidias利用额外的3D参考模型来缓解3D生成过程中存在的3D不一致和几何不确定性等问题。
基于不同的应用场景,算法所使用的3D参考模型可以由用户提供,也可以从大型3D数据库中获取。
第一阶段: 基于参考增强的多视图生成
在第一阶段,Phidias的目标是将额外的3D参考模型引入预训练的多视图生成模型,以提高多视图生成的3D一致性、泛化性和可控性。为了将3D参考模型集成到扩散模型的去噪过程中,研究人员将其转化成多视图正则坐标图(Canonical Coordinate Maps, CCMs)来约束扩散模型。CCM将3D参考模型表面点的3D位置坐标保存为RGB,仅保留了参考模型的几何信息而移除了纹理信息。
选择CCM作为3D表示主要出于两点原因:
- 1)相比于3D网格和体素,多视图图片自带与输出图片相同的相机角度,因此将其作为2D扩散模型的输入条件具有更好的效能和兼容性;
- 2)3D参考模型通常与概念图在几何结构上相似,但在纹理上不同。
为了充分利用预训练的多视图生成模型,研究人员将预训练网络参数冻结,仅需训练用于处理参考模型CCMs的条件网络。该阶段的一大挑战是:3D参考模型在大部分情况下并不严格对齐于概念图片,尤其是在局部细节上会有很大不同。
而传统的ControlNet被设计用于严格对齐的图像到图像生成任务,并不适用于本文中基于3D参考的生成任务。
为了解决该问题,研究人员提出了三个关键组件来提升模型性能:
1)用于自适应控制强度的元控制网络(meta-ControlNet);
2)用于动态调整3D参考模型的动态参考路由模块(dynamic reference routing);
3)用于支持高效自监督学习的自我参考增强模块(self-reference augmentation)。

△元控制网络(Meta-ControlNet)示意图
Meta-ControlNet由两个协作的子网络构成,即一个基础控制网络(Base ControlNet)和一个额外的元控制器(Meta-Controller)。
基础控制网络具有原始ControlNet的结构,其以参考模型的CCMs作为输入来产生指导预训练扩散模型的控制信号。元控制器具有跟基础控制网络相似的结构,但参数不同。它的工作机制是作为基础控制网络的“开关”,动态地根据概念图和3D参考模型的相似度来调节控制信号强度。
元控制器的输入是概念图和3D参考的正面CCM,其输出在两方面控制基础控制网络:1)基础控制网络的多尺度下采样块;2)基础控制网络最终的输出信号。

△参考路由模块示意图
参考模型通常在粗略形状上与概念图大致对齐,但在局部细节上存在显著差异。由于生成过程同时依赖于概念图和参考模型,他们之间的局部不一致性可能会导致混淆和冲突。
如上图所示,为了解决该问题,研究人员提出了动态参考路由策略,其核心是基于扩散模型的去噪时间步,动态调整参考模型的分辨率。低分辨率的CCMs提供了较少的细节,但与概念图的不一致性较低。通过在初始去噪阶段(高噪声水平)运用低分辨率的CCMs,可以保证参考模型被用于辅助生成3D对象的全局结构,而不会产生重大冲突。之后,随着去噪过程进入中、低噪声水平,研究人员逐渐提高参考CCMs的分辨率,从而帮助细化3D对象的局部细节,例如,尾巴随去噪过程从直变弯。这种设计选择可确保在多视角图像生成过程中有效利用概念图和3D参考,同时避免因冲突而导致生成质量下降。
此外,研究人员还提出自参考增强,以有效利用3D参考模型进行自监督训练。该方案使用3D模型的渲染作为概念图,并使用原3D模型本身作为参考模型和目标模型。
研究人员通过对原3D模型进行增强来模拟参考模型和概念图之间未对齐的情况,并设计了渐进式的课程学习策略来训练模型。这种方法解决了基于检索的训练集中参考模型与目标模型差异过大导致的学习困难问题,同时避免了直接使用自监督训练无法模拟未对齐情况的问题。一旦训练完成,本文的扩散生成模型在使用各种参考模型时都表现良好,即使是那些不太相似的来自检索的参考模型。
第二阶段:基于稀疏视角的3D重建
在第一阶段生成的多视图图像的基础上,本文通过基于稀疏视角的3D重建来获得最终的3D模型。该阶段可以建立在任意的稀疏视图重建方法上。
02 更多效果
检索增强的图生3D

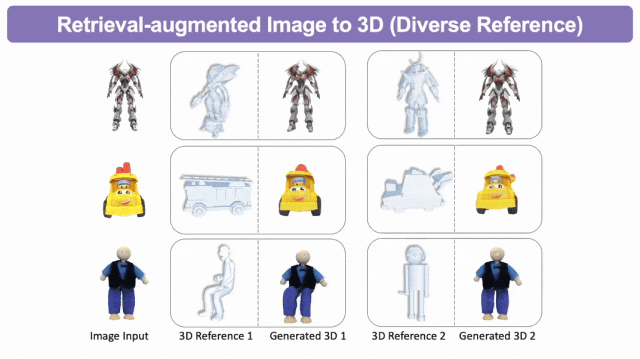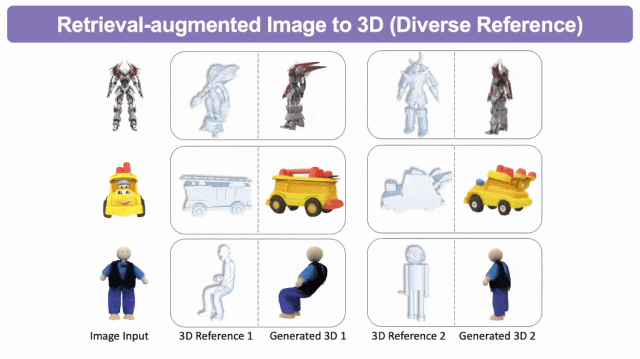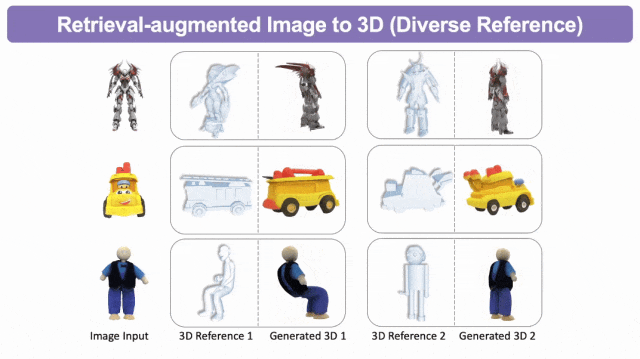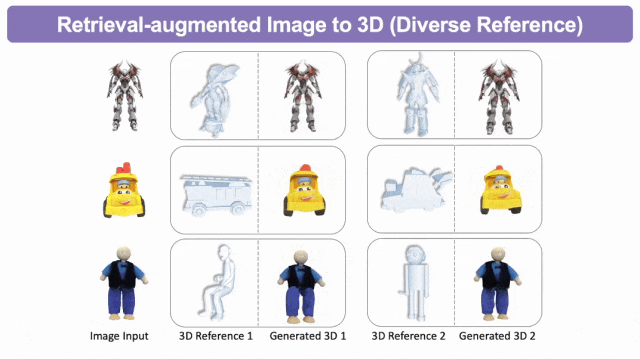
检索增强的文生3D

主题一致的3D到3D生成

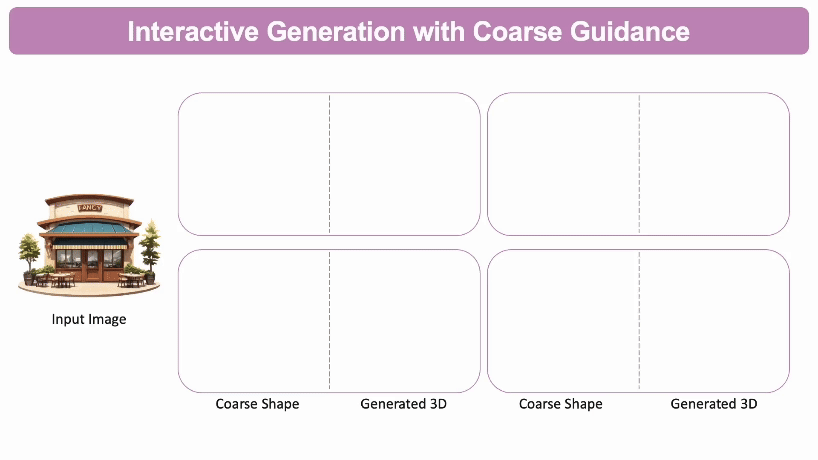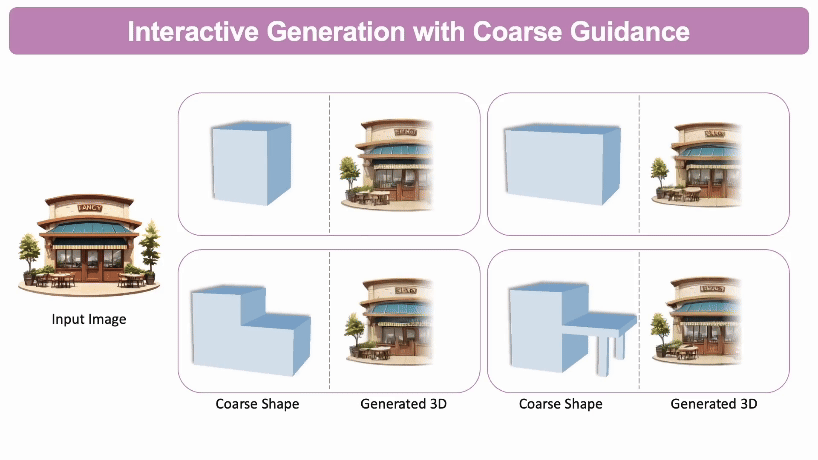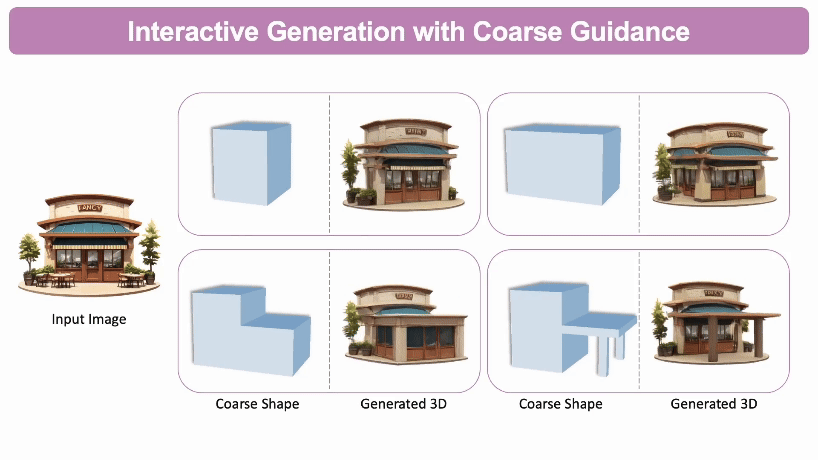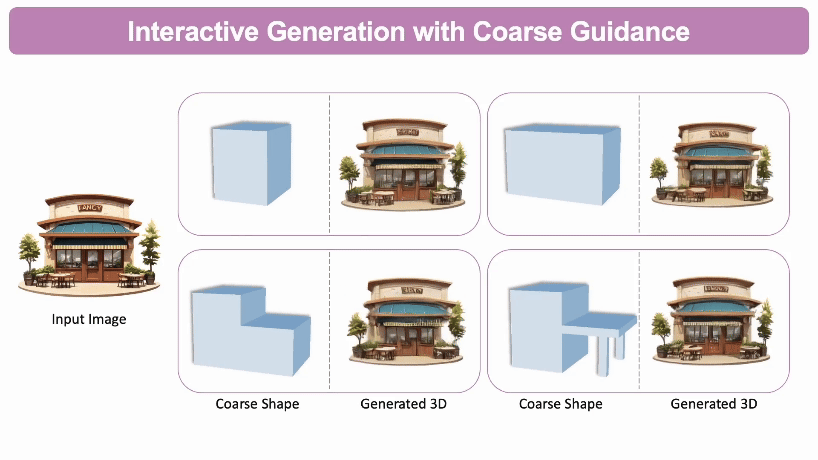
交互式3D生成: 通过自定义的粗略3D形状作为参考,用户可以不断调整所生成的3D模型的几何结构。
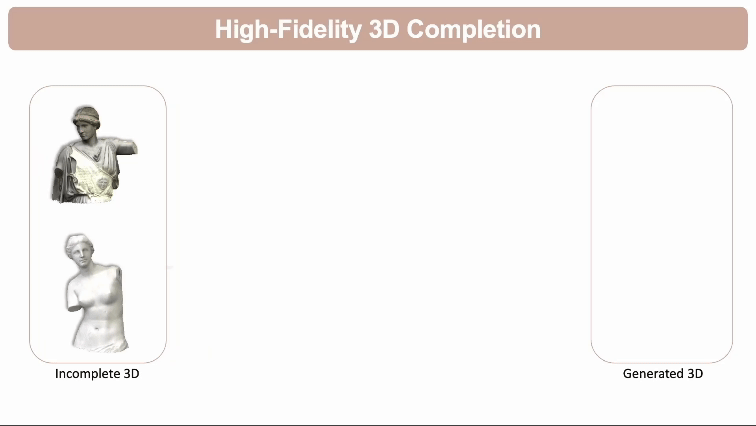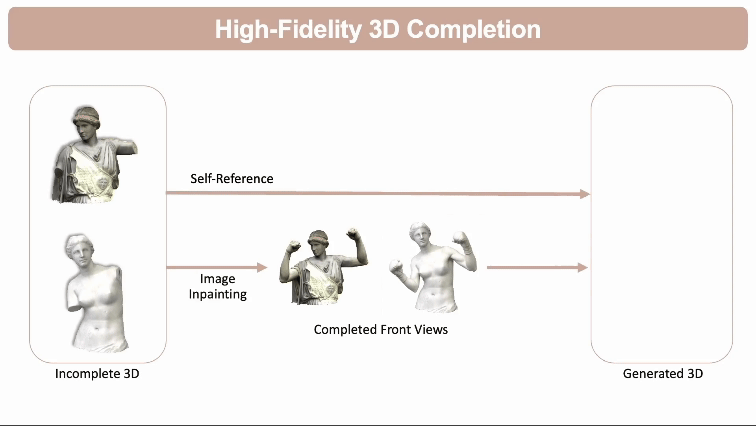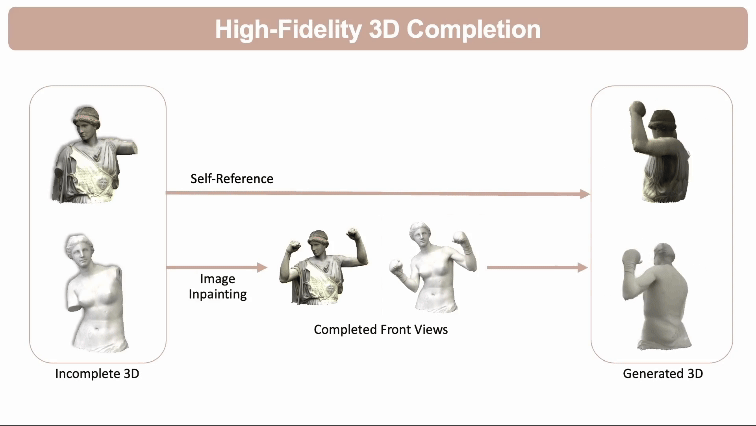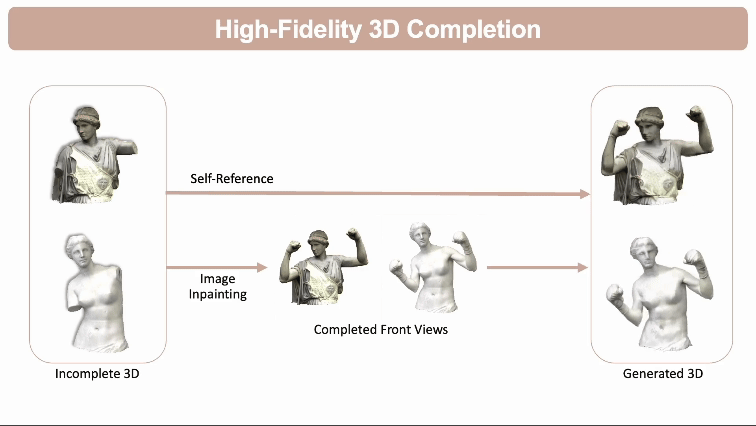
高保真3D模型补全: 预测和填充不完整3D模型的缺失部分,同时通过自参考原始3D模型来保持原有结构的完整性和细节。
项目主页:
https://RAG-3D.github.io/
代码:
https://github.com/3DTopia/Phidias-Diffusion
END
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









