






在学知识图谱系列的朋友就知道!
知识图谱+RAG!最大优势:
全局数据关系表示!
相似文本散落在–>不规则+不相邻文本块!
传统RAG只能找到top-k个文本块,一旦文本块过多,超出llm上下文限制,回答质量,堪忧!
想找齐?更靠运!
干好这个活,要花N倍时间编排!知识图谱,轻而易举,干成!
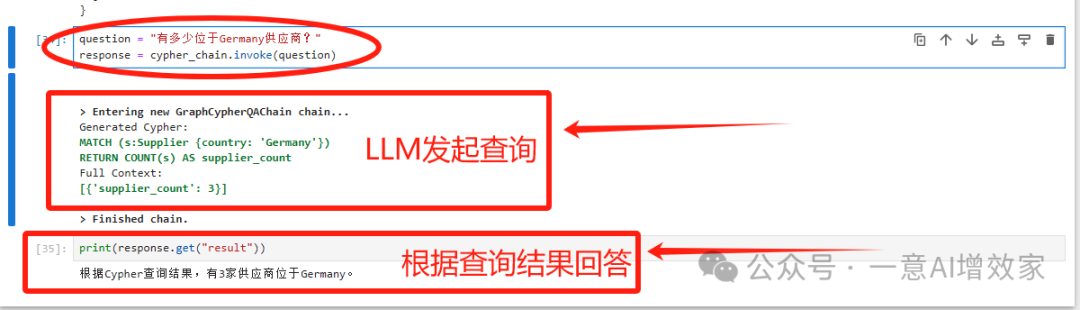
用户提问:“有多少位于Germany供应商?”
LLM看到知识图谱整个背景
回答:根据Cypher查询结果,有3家供应商位于Germany。
雄哥,为了今天,做了4天的准备,从数据准备,到动手做知识图谱!
今天,我要把KG接入到RAG中!
GraphRAG融合!增强RAG,做kg+rag应用!【本篇】
今天!
由浅至深,一边动手,一边学方法论,每个人,都能怀着信心学下去!
人的专注力只有10分钟,那!话不多说!
① 什么是向量?什么是相似文本检索?
② 用neo4j的图空间创建索引!可指定范围!
③ 单次查询!简单找相似性元数据!
④ 精锁查询!筛选锁定更准+精确的数据!
⑤ 做chat应用!RAG+KG真的那么牛?
⑥ 进阶查询!自然语言转Cypher,实时数据对话!
第一部分:什么是向量?相似度检索?
学会这部分,你更能体会到RAG中,为什么难做,雄哥不会深入太多,但每个人都需要懂!
我在知识图谱课程反复强调!
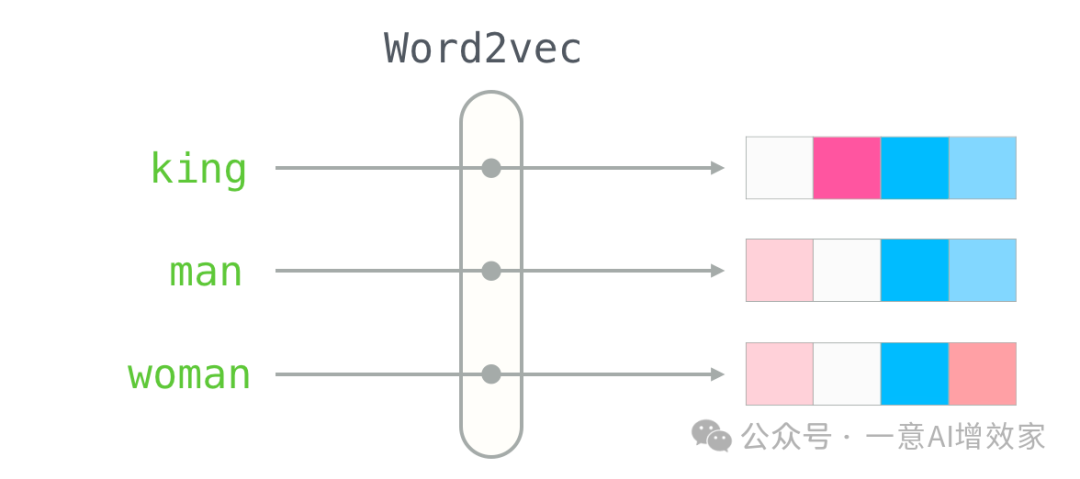
1.1 什么是向量?
机器学习中,通常将现实世界的对象和概念表示为一组连续数字,称为向量嵌入。
这种非常巧妙的方法使我们能够将我们感知到的物体之间的相似性转换为向量空间
它们的语义相似性由向量在空间中的接近程度来表示,因此,我们要看的是对象向量之间的距离
这些量表示(嵌入)通常是由训练模型根据输入数据和任务创建的。Word2Vec、GLoVE、USE 等是从文本数据生成嵌入的流行模型,而 VGG 等 CNN 模型通常用于创建图像嵌入;
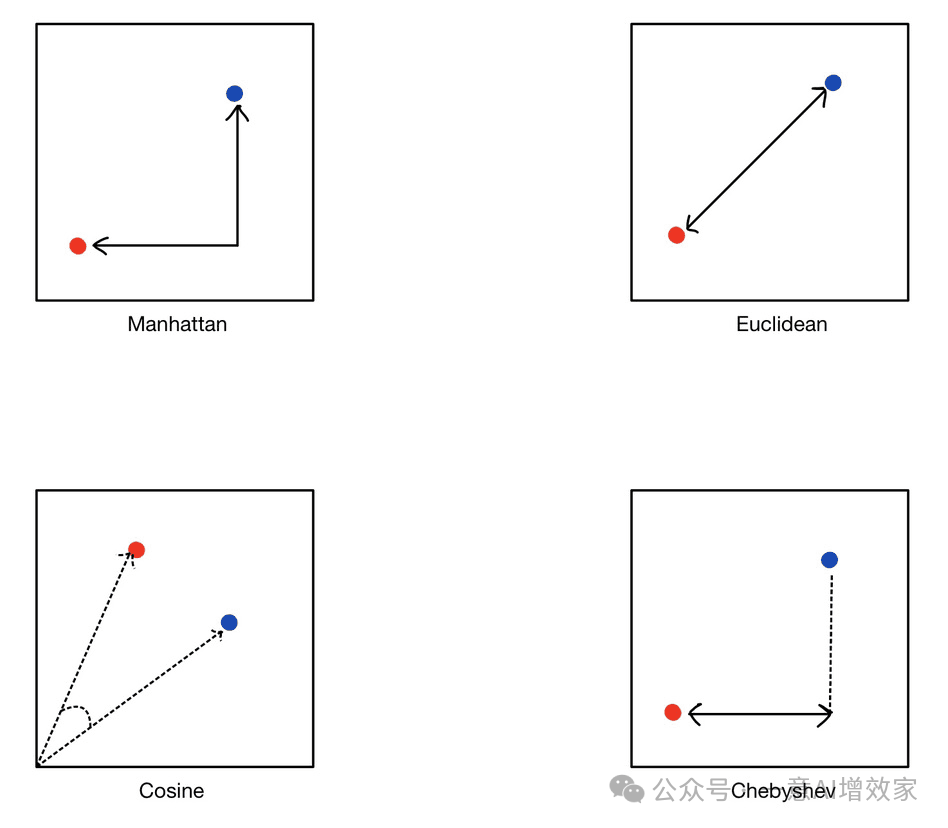
1.2 向量的距离=相似度?
通过计算对象向量之间的距离来判断对象之间相似性
我们可以根据最适合我们问题的距离度量来计算向量空间中这些向量之间的距离。
一些常用的距离指标有:ML、Euclidean、Manhattan、Cosine、 、Chebyshev;
下图帮助我们理解这些方法背后原理:
当然有更多衡量指标,但这不是今天主场,如果有需要的朋友,评论!
雄哥都会看,需求多的话,再专门做一期!
第二部分:用neo4j的图空间创建索引!可指定节点!
到这,我们要知道怎样创建索引,把neo4j的数据,存到rag应用中的!
以及学会如何只存想存的,为什么要指定!
2.1 为什么指定索引节点?
之前,雄哥只是在neo4j中创建了知识图谱,是数据!
但数据还未索引到雄哥环境中!
这个环节就是,把图数据库,索引到langchain中!
但也不能全部索引!
图数据库太大了!我们演示,只需要一部分!
oh!!~
可以指定!索引哪些节点!
这个操作,同样适合你公司内部,不同的部门,应用到不同的数据!
比如财务部的知识图谱/数据,不可能让销售部随便查询到!
技术研发部的数据,不能让非本部门的人员查询!
否则,数据泄密!
明白没?
明白了,跟着雄哥进入实操部分!
2.2 开始实操
老规矩,先进入环境!
如果你还不知道怎样创建环境,返回前面内容!
激活conda环境!
这个环境还是一开始那个!
conda activate medkg
进入jupyter实操!
会自动跳转到浏览器!
jupyter notebook
检查自己的key!
打开.env文件,检查自己的key,确保都填写正确!
打开实操代码!
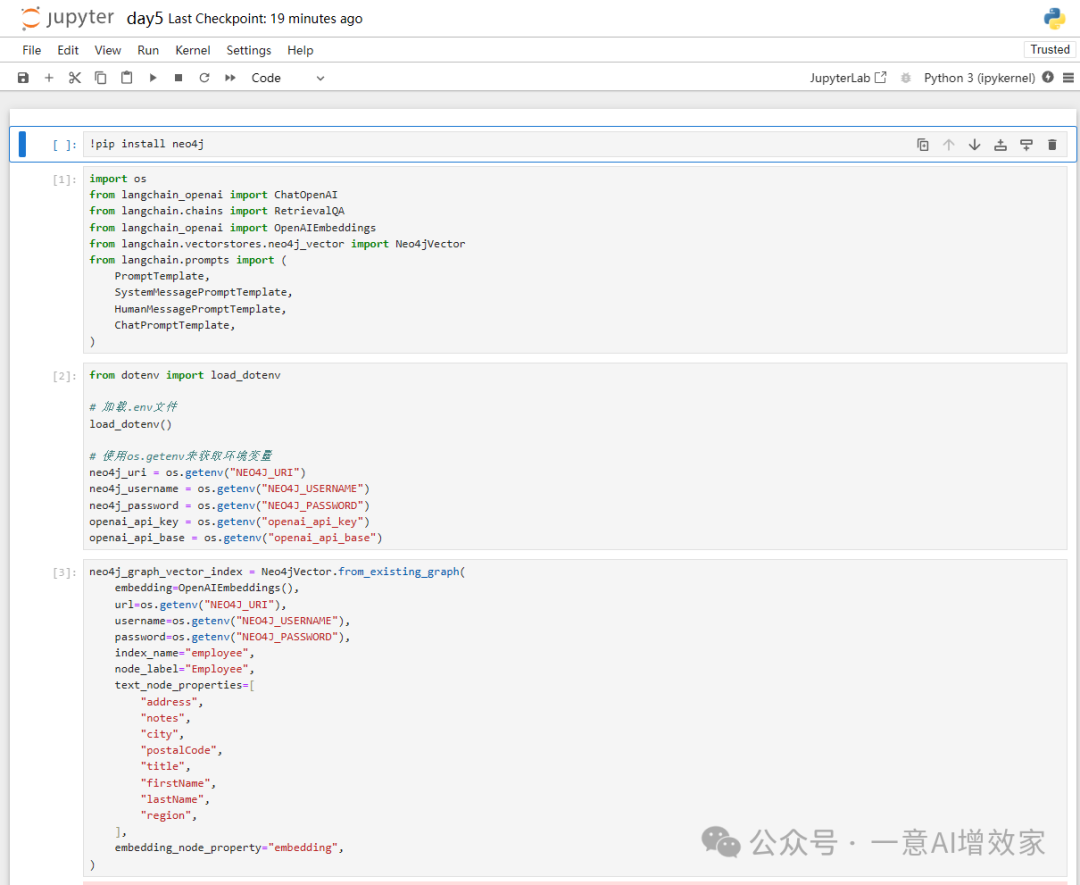
2.3 实操索引指定数据
先加载.env文件中的key!
这里,我们要用到neo4j,以及OpenAI key!当然可以本地,雄哥都有代码实践示例的,自己找了!
为了让本地无资源的朋友,都能跑起来,雄哥用key!

索引指定的部分数据节点!
要索引的数据,我们在前面的内容中,都演示过如何存进去了!现在,雄哥直接用这些数据创建索引!
用于相似性搜索!

-
Neo4jVector.from_existing_graph: 创建向量索引的开始,它基于一个已有Neo4j图数据库。 -
embedding=OpenAIEmbeddings(): 指定了一个嵌入函数,使用OpenAI的模型来生成文本数据的向量表示 -
url=os.getenv("NEO4J_URI"): 从环境变量中获取Neo4j数据库的URI(Uniform Resource Identifier),这是数据库连接地址 -
username=os.getenv("NEO4J_USERNAME")和password=os.getenv("NEO4J_PASSWORD"): 分别从环境变量中获取用于连接Neo4j数据库的用户名+密码 -
index_name="employee": 设置索引的名称为"employee"。 -
node_label="Employee": 指定这个索引将应用于Neo4j数据库中标记为"Employee"的节点 -
text_node_properties=[...]: 列表,列出要索引的节点属性。这些属性将使用OpenAI的转换成向量,存储在数据库中。列出属性包括地址、备注、城市、邮政编码、职位、名字、姓氏和地区 -
embedding_node_property="embedding": 设置一个属性名称,这个属性将用于存储由OpenAI模型生成的向量。在Neo4j数据库中,每个"Employee"节点都会有一个名为"embedding"的属性,用来存储该节点的向量表示。
第三部分:发起查询!找相似性元数据!
数据索引需要时间!
执行完之后,跟着雄哥!继续往下!
可以对索引的数据,做检索了!
这里,我们的检索策略可以根据任务目标做查询颗粒度分解!
如何才能做好?
雄哥在知识图谱课程中有更详尽策略分解
而今天,我们不展开,就最简单的单次查询开始!
单次查询节点!
这里,雄哥直接查询图数据库中,"Andrew"员工的这个节点!
result = neo4j_graph_vector_index.similarity_search("Andrew", k=1)
-
neo4j_graph_vector_index.similarity_search("Andrew", k=1): 函数调用是在Neo4j图数据库中执行一个相似性搜索。参数"Andrew"是搜索的查询字符串,k=1指定返回最相似的1个节点。 -
"Andrew": 搜索查询字符串,表示要搜索与"Andrew"最相似的节点。 -
k=1: 指定返回最相似节点的数量为1。 -
result: 这个变量存储了相似性搜索的结果。由于k=1,result是一个列表,其中包含最相似的一个节点。 -
result[0]: 这是列表中的第一个元素,代表最相似节点。

有没有想过,一个公司中,存在两个同名员工!
一个在美国,一个在英国!
这时,怎么办?
情况,举一反三,有很多类似的!
这时,要加筛选条件!
第四部分:精锁查询!筛选锁定更准+精确的数据!
我们要解决多重合数据!
或者希望找到任何,图数据库中的复杂节点数据!
这里,我们要上条件!
比如,雄哥只要查询到国家=UK的节点!
result = neo4j_graph_vector_index.similarity_search(
"Employee details", filter={ "country": "UK" })
-
neo4j_graph_vector_index.similarity_search("Employee details", filter={ "country": "UK" }): 函数调用在Neo4j图数据库中执行一个相似性搜索,搜索与字符串"Employee details"最相似的节点,应用一个过滤条件 -
"Employee details": 搜索查询字符串,表示要搜索与"Employee details"最相似的节点。 -
filter={ "country": "UK" }: 过滤条件,表示只返回那些其"country"属性值为"UK"的节点 -
result: 这个变量存储了执行过滤后的相似性搜索结果。它将是一个列表,包含了所有满足过滤条件且与查询字符串最相似的节点
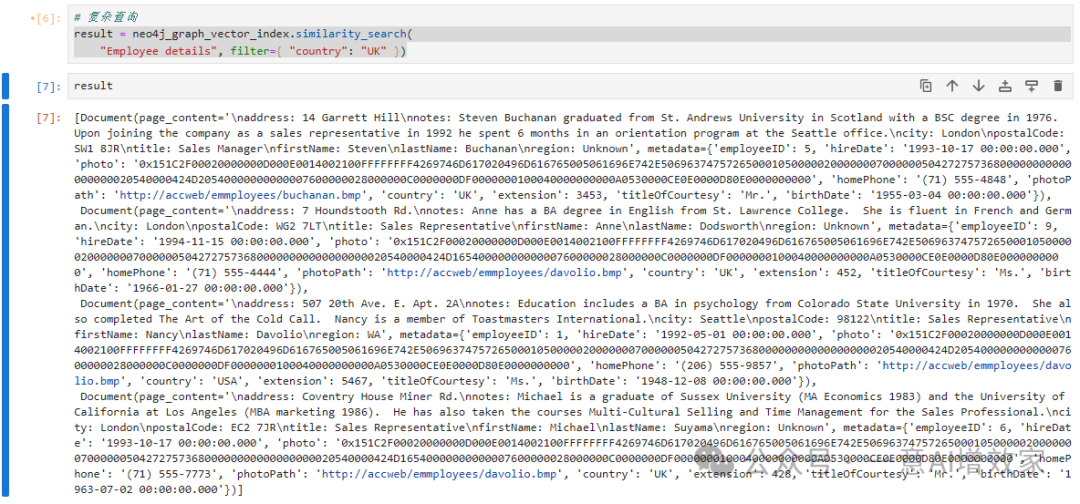
但,雄哥也在想,除了他们,还有多少员工在UK上班呢?
总共4个!信息是这样的
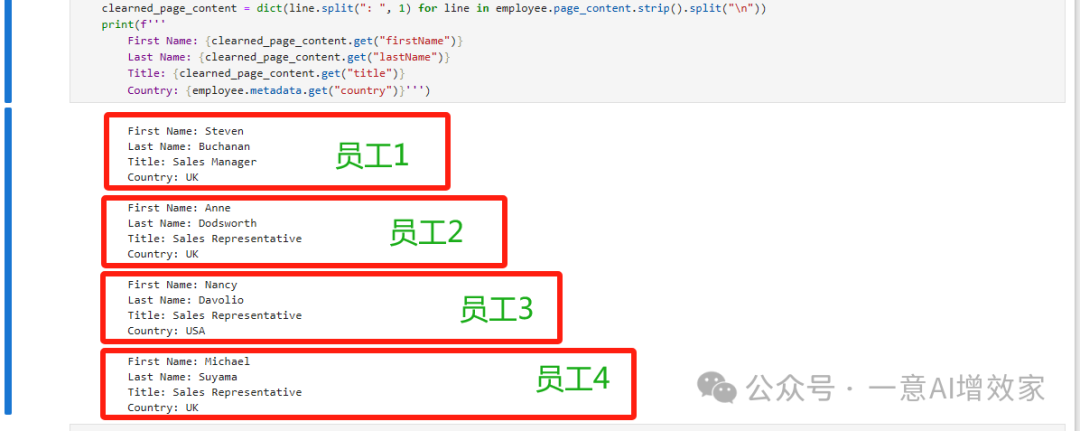
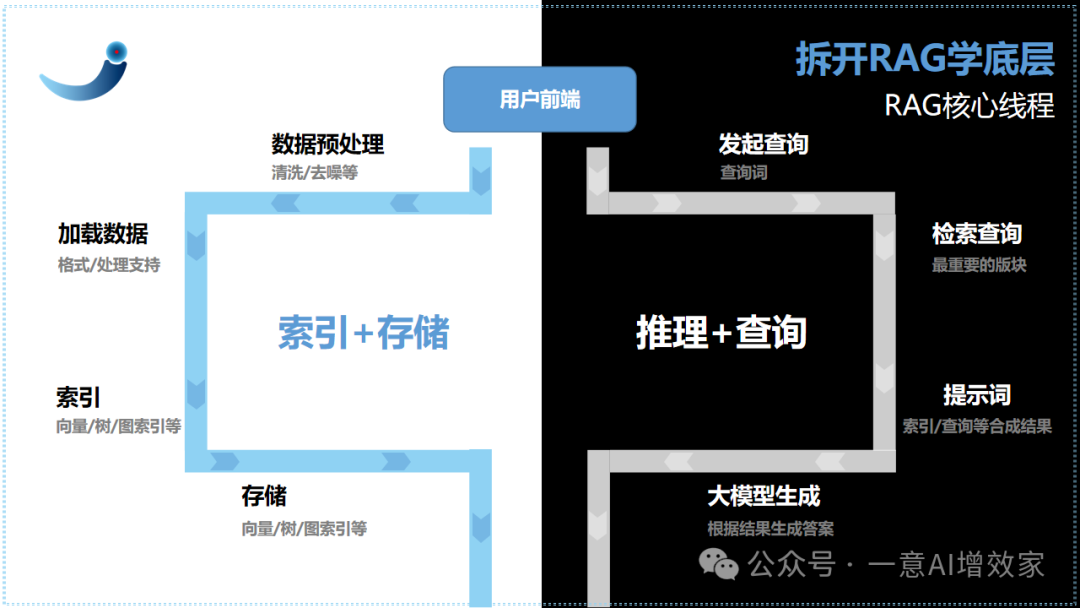
要明白,索引+查询,是整个RAG真重要的两个组件!
不管哪个组件,一旦拆开,讲1天都讲不完!
第五部分:做chat应用!RAG+KG真的那么牛?
掌握了上面的策略之后!
来吧!
我们用这些数据,做一个chat应用!
继续在这个环境!
无需切换!
做图数据库的chat应用,还是老3步!
定义提示词–>创建查询引擎–>发起查询
5.1 定义提示词
告诉大模型,如果不知道的内容,不要乱答!
employee_details_chat_template_str = """
你的任务是使用提供的员工数据来回答关于他们的角色、表现和在公司内的经验的问题。使用以下上下文来回答问题.
请尽可能详细地回答,但不要添加任何上下文之外的信息
如果你不知道答案,就说你不知道.
{context}
"""
定义提示词模板后,合并!
通过将 employee_details_chat_system_prompt 和 human_prompt 放入同一个列表 messages 中,将这两个提示模板合并到对话流程中。
messages = [employee_details_chat_system_prompt, human_prompt]
5.2 创建查询引擎
我们用neo4j创建的索引,以及定义的提示词模板,组成查询引擎!

-
RetrievalQA.from_chain_type: 类方法,创建一个基于检索问答系统 -
llm: 用3.5版本的,上面有定义 -
retriever: 检索器,它负责从数据源中检索相关的信息。neo4j_graph_vector_index.as_retriever()表示检索器是从Neo4j图数据库的向量索引中检索信息。 -
chain_type="stuff": 这定义了问答系统使用的链类型。链类型决定了如何结合语言模型和检索到的信息来生成答案 -
'stuff': 将检索到的所有文档的文本“堆叠”在一起,然后使用语言模型来生成答案。 -
'map_reduce': 首先使用语言模型对每个检索到的文档生成一个答案,然后对这些答案进行汇总或“减少”以生成最终的答案。 -
'refine': 首先生成一个初始答案,然后使用检索到的信息来细化这个答案。 -
'map_rerank': 首先生成答案,然后根据检索到的文档重新排名这些答案。
5.3 发起查询
这个简单应用就这样做起来了!
实际应用肯定不是这么简单的啊!
要根据自己任务来做的!
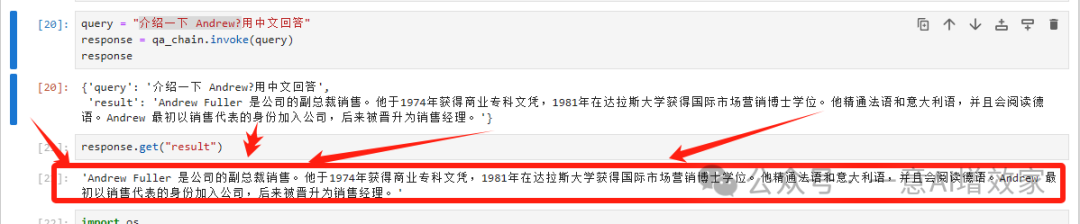
现在,发起查询:
介绍一下 Andrew?
大模型会先去查相关的节点,得到:

第六部分:进阶!自然语言转Cypher,实时数据!
上面,是查询索引的数据!
但雄哥说过很多次,索引需要占用大量资源,RAG一个打大优势,就是比微调实时!
如果部门马上有新的数据到neo4j中!
有没有办法?
实现–>实时数据访问+修改!
有的!
在上篇就知道,我们可以用Cypher来做查询和数据的维护!
但在对话中,我们无法人工实时地为客户写查询或修正Cypher 语句啊!
用LLM来写!
但,开始下面内容前,先提醒!
这个策略风险很大!
开始前要分配权限,才能杜绝:LLM莫名的删除、修改、更新图数据库!
知道这个前提!
来吧,动起手来!
连接到neo4j!

教LLM如何写Cypher!
雄哥用到一个Few-Shot Prompting的方法,写了一个提示词!
qa_generation_template_str = """
您是一名助手,负责将Neo4j Cypher查询的结果转化为易于人类阅读的响应。查询结果部分包含了基于用户自然语言问题生成的Cypher查询结果。所提供的信息是权威的;您绝不能质疑它,或者使用您的内部知识去更改它。确保您的回答听起来像是针对问题的回应.
Query Results:
{context}
Question:
{question}
如果提供的信息为空,请通过声明您不知道答案来回应。空信息由以下方式表示: []
如果信息不为空,您必须使用结果来提供答案。如果问题涉及时间长度,请假设查询结果是以天为单位,除非另有说明
当查询结果中提供名称时,例如医院名称,要小心任何包含逗号或其他标点符号的名称。例如,“Jones, Brown and Murray”是一个医院名称,而不是多个医院。确保任何名称列表都清晰地呈现,以避免歧义并使全名易于识别
绝不要在查询结果中有数据的情况下表示你缺乏足够的信息。始终利用提供的数据.
Helpful Answer:
"""
什么是Few-Shot Prompting?
Few-shot Prompting是一种技术,涉及为语言模型提供少量示例以指导其对特定任务的响应。方法介于零样本学习(没有给出示例)和完全监督的微调(需要大量标记数据)之间。
换句话说,Few-shot Prompting 是在 Prompt 本身中为语言模型提供少量演示或示例的过程。这些示例用作指南,向模型展示如何处理和响应特定类型的任务或问题。当你提供这些例子时,你实际上是在对模型说,“在类似情况下,你应该如何应对。
创建链式实例!
通过一个多步的链条式步骤,合成最终结果!

-
top_k=100: 在处理过程中保留前100个最高概率的候选答案。 -
graph=graph: 这里传递了一个名为graph的变量给GraphCypherQAChain,这个变量是图数据库实例。 -
verbose=True: 当这个参数设置为True时,执行过程中会输出更多的日志信息或调试信息。 -
validate_cypher=True: 生成Cypher查询(Neo4j图数据库查询语言)后,会进行验证以确保查询的有效性。 -
qa_prompt=qa_generation_prompt: 这里传递了一个名为qa_generation_prompt的变量,一个字符串,用于指导语言模型生成问答相关的提示。 -
cypher_prompt=cypher_generation_prompt: 类似于qa_prompt,这个参数传递了一个用于指导生成Cypher查询的提示。 -
qa_llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0): 这里定义了一个用于生成问答的语言模型,使用的是OpenAI的ChatOpenAI接口,模型指定为gpt-3.5-turbo,temperature=0表示在生成文本时不会引入随机性,将生成最可能的输出。 -
cypher_llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0): 与qa_llm类似,这个参数定义了一个用于生成Cypher查询的语言模型。

如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。 。















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









