







嗨喽~大家好呀,这里是魔王呐 ❤ ~!

python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
环境使用:
-
Python 3.10
-
Pycharm
模块使用:
-
import requests >>> pip install requests
-
import parsel >>> pip install parsel
-
import prettytable >>> pip install prettytable
-
import os
打包exe程序: pyinstaller -> pip install pyinstaller
爬虫基本实现流程
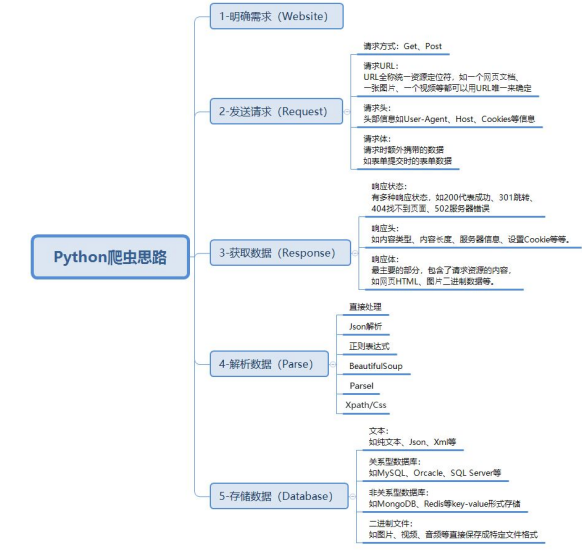
一. 数据来源分析
-
明确需求
明确采集的网站以及数据内容 (实现什么样程序)
程序功能: 通过关键字(歌手/歌名) 进行歌曲搜索, 然后进行对应歌曲内容下载
-
网址: https://www.gequbao.com/
-
数据: 歌曲内容 / 歌曲标题
-
-
抓包分析 (浏览器中进行的操作)
抓包分析: 分析我们需要的数据, 可以请求那个网址能够得到
分析操作: 通过浏览器自带开发者工具
先分析歌曲链接地址 -> 歌曲链接地址从哪里的生成 -> 如何才能实现搜索对应下载功能
-
打开开发者工具: F12
https://www.gequbao.com/music/402856 在网页页面打开开发者工具
-
刷新网页: 让数据内容重新加载一遍
-
快速找到对应歌曲播放地址
https://sy-sycdn.kuwo.cn/af5833d0735b1bba1f86d4ef6c3888d7/65d72918/resource/n
2/70/55/756351052.mp3?from=vip -
通过关键字搜索找到对应数据包位置
爬虫: 批量数据采集
继续分析, 音频链接在那个数据包当中是存在的
关键字: 使用音频链接当中一段参数即可
https://sy-sycdn.kuwo.cn/af5833d0735b1bba1f86d4ef6c3888d7/65d72918/resource/n
2/70/55/756351052.mp3?from=vip比如: 756351052 作为关键字进行搜索
晴天数据包地址: https://www.gequbao.com/api/play_url?id=402856&json=1
阴天数据包地址: https://www.gequbao.com/api/play_url?id=61045&json=1
对比分析: id=xxxx (歌曲ID)
-
晴天ID 402856
-
阴天ID 61045
只要获取到歌曲ID就可以下载对应歌曲内容
-
分析歌曲ID可以请求那个链接获得
搜索链接地址: https://www.gequbao.com/s/%E9%98%B4%E5%A4%A9
- 歌手 / 歌名 / 音乐ID
目的: 根据搜索关键字下载对应歌曲
-
歌曲 -> 专门数据包链接 阴天数据包地址: https://www.gequbao.com/api/play_url?id=xxx&j
son=1 -
获取对应歌曲ID -> https://www.gequbao.com/s/搜索关键字
-
二. 代码实现步骤 (基本四个步骤)
导入的模块
'''
Python学习交流,免费公开课,免费资料,
免费答疑,系统学习加QQ群:926207505
'''
# 导入数据请求模块 (需要安装 pip install requests)
import requests
# 导入数据解析模块 (需要安装 pip install parsel)
import parsel
# 导入制表模块 (需要安装 pip install prettytable)
from prettytable import PrettyTable
# 导入文件操作模块 (无需安装 内置模块)
import os
1. 发送请求
模拟浏览器对于url地址发送请求
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









