







爬取目标
网址:百度文库

工具使用
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests,re
重点学习内容
-
获取网址数据
-
正则提取数据
-
保存文本数据
项目思路解析
找到自己需要的文库资料
这篇文章主要介绍的如何处理复制限制的问题

在做一个爬虫项目之前首先要知道数据的来源,以及数据的加载方式
当前网页数据为加载得到的数据
需要通过抓包的方式提取对应数据
打卡抓包工具进行数据找寻

数据来自一个json文件保存的数据采c字段里面
找到目标数据之后在找寻数据资源地址的加载方式
要知道数据是从哪里加载过来的
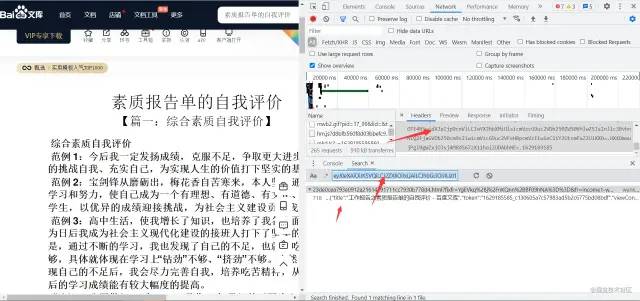
通过搜索关键字的方式找到数据的来源
通过搜索到数据其实是前端页面自带的
加载之后的数据
需要从文章页面提取出所有的数据下载地址

对文章首页发送网络请求
通过正则的方式提取出所有的数据下载地址
def get_url(self):url = "https://wenku.baidu.com/view/d19a6bf4876fb84ae45c3b3567ec102de3bddf82.html"headers = {'Accept': 'text/html,application/xhtml+xm
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1978
1978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









