






大家好,我是海鸽。
函数被定义为一段代码,它接受参数,充当输入,执行涉及这些输入的一些处理,并根据处理返回一个值(输出)。当一个函数将另一个函数作为输入或返回另一个函数作为输出时,这些函数称为高阶函数。
map() 、reduce() 和 filter() 都是高阶函数。
函数式编程强调将函数作为头等对象。今天我们解读下 functools 库中用于创建和修改函数的几个高阶函数。
初识 functools 模块
functools模块是Python的标准库的一部分,它是为高阶函数而实现的,用于增强函数功能。
# -*- coding:utf-8 _*-
# __author__:lianhaifeng
# __time__:2024/2/23 22:42
import functools
from loguru import logger
logger.info(functools)
logger.info(functools.__doc__)
logger.info(dir(functools))

这些信息表明 functools 模块提供了一系列用于处理函数和可调用对象的工具。
以下是 functools 模块中包含的主要方法的详细说明:
-
cached_property: 一个装饰器,用于将方法转换为只读属性,第一次访问时计算值并缓存。 -
cmp_to_key: 用于在比较函数中将老式比较函数转换为关键字函数的工具。 -
cache: 一个装饰器,提供了一个带有缓存的函数装饰器,用于缓存函数的结果以提高性能。 -
lru_cache: 一个装饰器,提供了一个带有最近最少使用(LRU)缓存的函数装饰器,用于缓存函数的结果以提高性能。 -
partial: 一个函数,用于部分应用一个函数的参数,并返回一个新的函数,使得可以在原函数的基础上预先设置一部分参数。 -
partialmethod: 与partial类似,但专门用于部分应用类方法的参数。 -
reduce: 一个函数,对序列中的元素进行累积运算,通常与二元函数结合使用。 -
singledispatch: 一个装饰器,用于创建基于单个分派泛型函数的多分派泛型函数,根据不同的参数类型调用不同的函数实现。 -
singledispatchmethod: 与singledispatch类似,但专门用于类方法。 -
total_ordering: 一个类装饰器,可以根据一个类的一组方法(__eq__,__lt__,__le__,__gt__,__ge__,__ne__)自动生成所有比较运算。 -
update_wrapper: 一个函数,用于更新一个函数对象的特性,例如__doc__、__name__和__module__,以便被包装函数更好地模拟原函数。 -
wraps: 一个装饰器,用于将一个装饰器应用到一个函数上,并保留原函数的元数据。
这些工具可以帮助 Python 开发者在处理函数时提高效率和灵活性。
functools.cached_property
这个函数将类的方法转换为一个属性,该属性在第一次计算后会被缓存,并在实例的生命周期内作为常规属性使用。
它类似于 property(),但添加了缓存功能,对于高计算资源消耗的实例特性属性来说,这个函数非常有用,因为它们在其他情况下实际上是不可变的。
# -*- coding:utf-8 _*-
# __author__:lianhaifeng
# __time__:2024/2/23 22:42
from functools import cached_property
from loguru import logger
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n - 1) + fibonacci(n - 2)
class MyClass:
@cached_property
def expensive_calculation(self):
# 这是一个昂贵的计算,我们只希望它执行一次并进行缓存
logger.info('计算 expensive_calculation')
return fibonacci(20)
# 使用:
obj = MyClass()
logger.info(obj.expensive_calculation) # 计算结果将被缓存
logger.info(obj.expensive_calculation) # 计算结果将被缓存
输出结果:

functools.cached_property在 Python 3.8 及更高版本中可用,允许您缓存类属性。评估属性后,将不会再次评估。
functools.cache
functools.cache用作装饰器,能够根据输入缓存函数的返回值。它在 Python 3.9 及更高版本中可用。
缓存大小是无限制的。
from functools import cache
@cache
def fibonacci(n):
if n < 2:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
print(fibonacci(3))
print(fibonacci(10))
functools.lru_cache
functools.lru_cache 允许您将递归函数调用缓存在最近最少使用的缓存中。这可以通过多个递归调用(如斐波那契数列)优化函数。
@lru_cache(maxsize=10) 表示缓存中将只保留 10 个最近使用最少的条目。当新条目到达时,最早的缓存条目将被丢弃。
# -*- coding:utf-8 _*-
# __author__:lianhaifeng
# __time__:2024/2/23 22:42
from loguru import logger
from functools import lru_cache
# 定义一个全局变量来记录函数被调用的次数
call_count = 0
@lru_cache(maxsize=10)
def fibonacci(n):
global call_count # 使用全局变量
call_count += 1 # 每次调用增加计数
if n in [0, 1]:
return n
else:
return fibonacci(n - 1) + fibonacci(n - 2)
logger.info(fibonacci(4))
logger.info(f"Total function called {call_count} times.") # 记录函数被调用的总次数
logger.info("第二次调用 fibonacci(1),此时应该命中缓存")
logger.info(fibonacci(1))
logger.info(f"Total function called {call_count} times.")
输出结果为:

该装饰器会将不同的调用结果缓存在内存中,因此需要注意内存占用问题。
functools.cmp_to_key()
functools.cmp_to_key 是一个函数,用于将比较函数(cmp函数)转换为一个key函数。在Python 2中,比较函数被广泛用于排序和相关操作,但是在Python 3中,由于删除了cmp参数,比较函数的使用受到了限制。为了在Python 3中仍然能够使用比较函数进行排序,可以使用functools.cmp_to_key 来将比较函数转换为key函数,然后将其传递给排序函数。
比较函数是任何接受两个参数,对它们进行比较,并在结果为小于时返回一个负数,相等时返回零,大于时返回一个正数的可调用对象。
以下是一个示例,演示了如何使用 functools.cmp_to_key:
import functools
# 定义一个比较函数(在Python 2中可以直接用作排序函数)
def custom_cmp(x, y):
return (x > y) - (x < y)
# 将比较函数转换为键函数
key_func = functools.cmp_to_key(custom_cmp)
# 使用转换后的键函数进行排序
sorted_list = sorted([3, 1, 4, 1, 5, 9], key=key_func)
print(sorted_list) # Output: [1, 1, 3, 4, 5, 9]
在这个示例中,custom_cmp 是一个比较函数,它接受两个参数并返回-1、0或1以表示它们的大小关系。然后,使用functools.cmp_to_key将该比较函数转换为一个key函数key_func。最后,通过将key_func传递给sorted函数,可以使用该key函数对列表进行排序。
也就是说,排序时会先对每个元素调用 key 所指定的函数,然后再排序。cmp_to_key函数就是用来将老式的比较函数转化为key函数。用到key参数的函数还有sorted(), min(), max(), heapq.nlargest(), itertools.groupby()等。
functools.total_ordering
total_ordering 装饰器用于定义能够实现各种比较运算的算子类,适用于 numbers.Number 的子类和半数值型类。
functools.total_ordering 是一个装饰器,它允许您在定义类时只定义一小部分比较方法,然后它会自动为您补全其余的比较方法。这样,您可以轻松地定义一个完整的序列化类,而无需手动实现所有的比较方法。
这个装饰器要求类中至少定义了一个 __lt__、__le__、__gt__ 或 __ge__ 中的一个方法,并且还必须定义 __eq__ 方法。
以下是一个示例,演示了如何使用 functools.total_ordering 装饰器:
# -*- coding:utf-8 _*-
# __author__:lianhaifeng
# __time__:2024/2/23 22:42
from functools import total_ordering
from loguru import logger
@total_ordering
class Student:
def __init__(self, name, grade):
self.name = name
self.grade = grade
def __eq__(self, other):
return self.grade == other.grade
def __lt__(self, other):
return self.grade < other.grade
# 使用示例
alice = Student("Alice", 85)
bob = Student("Bob", 75)
logger.info(alice > bob) # True,因为 Alice 的成绩更高
logger.info(alice == bob) # False
在这个示例中,我们定义了一个 Student 类,并使用 total_ordering 装饰器装饰它。我们只定义了 __eq__ 和 __lt__ 方法,而没有定义其他比较方法。然后,total_ordering 装饰器自动为我们补全了 __le__、__gt__ 和 __ge__ 方法。这样,我们就可以使用所有的比较运算符来比较 Student 对象的成绩了。
如果没有定义
__eq__方法,那么无法确定两个对象是否相等,这会导致在使用 total_ordering 装饰器时产生意外行为。因此,为了确保类的行为符合预期,必须提供__eq__方法,不等比较方法__ne__()默认基于__eq__()生成。
functools.partial
它的作用是固定这个函数中的一部分参数。
即一般用于:基于旧函数及其部分参数
生成的新函数
举个简单的例子。
# -*- coding:utf-8 _*-
# __author__:lianhaifeng
# __time__:2024/2/23 22:42
from functools import partial
from loguru import logger
def power(base, exponent):
return base ** exponent
# 创建一个新函数,将 exponent 参数预设为 2
square = partial(power, exponent=2)
# 使用新函数
result = square(base=3) # 相当于 power(3, 2),返回 9
logger.info(result)
# 继续创建一个新函数,将 base 参数预设为 2
square_two = partial(power, base=2)
# 使用新函数
result_two = square_two(exponent=3) # 相当于 power(2, 3),返回 8
logger.info(result_two)
partial() 函数主要用于 “冻结” 函数的部分参数,返回一个参数更少、使用更简单的函数对象。
应用场景:函数在执行时,要带上所有必要的参数进行调用,但是有的参数可以在函数被调用之前提前获知,这种情况下,提前获知的函数参数可以提前用上,以便函数能用更少的参数进行调用。
示例:
urlunquote = functools.partial(urlunquote, encoding='latin1')
当调用 urlunquote(args, *kargs),相当于 urlunquote(args, *kargs, encoding='latin1')
很实用的例子:
# -*- coding:utf-8 _*-
# __author__:lianhaifeng
# __time__:2024/2/23 22:42
# 导入必要的模块和函数
import json
import datetime
from functools import partial
# 定义 json_serial_fallback 函数
from loguru import logger
def json_serial_fallback(obj):
"""JSON serializer for objects not serializable by default json code"""
if isinstance(obj, (datetime.datetime, datetime.date)):
return str(obj)
if isinstance(obj, bytes):
return obj.decode("utf-8")
raise TypeError(f"{obj} is not JSON serializable")
# 定义 json_dumps 函数
json_dumps = partial(json.dumps, default=json_serial_fallback)
# 创建一个包含日期时间和字节串的字典
data = {
"timestamp": datetime.datetime.now(),
"binary_data": b"example binary data"
}
# 将字典转换为 JSON 格式的字符串
json_string = json_dumps(data)
logger.info(json_string) # {"timestamp": "2024-02-24 11:16:25.016089", "binary_data": "example binary data"}
functools.partialmethod
functools.partialmethod 是 Python 标准库中的一个函数,用于创建可部分应用的方法。它与 functools.partial 类似,不同之处在于它用于部分应用方法而不是函数。
部分应用是一种函数式编程的概念,允许你在调用函数时固定一部分参数,从而创建一个新的函数,这个新函数会在后续调用中使用这些固定的参数。functools.partialmethod 在面向对象编程中扮演着同样的角色,但是它是用于部分应用方法的。
以下是 functools.partialmethod 的一个简单示例:
import functools
class Greeter:
def __init__(self, greeting):
self.greeting = greeting
def greet(self, name, *args):
return f"{self.greeting}, {name} {''.join(args)}"
# 创建一个部分应用的方法
greet_hello = functools.partialmethod(greet, 'Hello')
# 创建一个 Greeter 实例
greeter = Greeter('Bonjour')
# 正确调用部分应用的方法
print(greeter.greet_hello("Alice!")) # 输出: Bonjour, HelloAlice!
在这个示例中,Greeter 类定义了一个 greet 方法,用于向给定的名字打招呼。然后使用 functools.partialmethod 创建了一个部分应用的方法 greet_hello,将 'Hello' 作为固定参数传递给 greet 方法,从而创建了一个新的方法。当调用 greeter.greet_hello('Alice') 时,实际上是调用了 greeter.greet('Hello', "Alice!"),因此会输出 Bonjour, Hello Alice!。
functools.reduce
函数的作用是将一个序列归纳为一个输出reduce(function, sequence, startValue)
from loguru import logger
from functools import reduce
alist = range(1, 50)
logger.info(reduce(lambda x, y: x + y, alist)) # 1225
注意functools.reduce方法初始值的重要性
设置初始值的方式对于 map()函数和
reduce()函数都非常重要。
初始值在使用 functools.reduce 函数时具有重要性,特别是在处理空序列时。让我们通过一个例子来说明其重要性:
假设我们有一个列表,我们想计算列表中所有元素的累积乘积。
from functools import reduce
numbers = [1, 2, 3, 4, 5]
# 计算累积乘积
result = reduce(lambda x, y: x * y, numbers)
print(result)
在这个例子中,我们没有提供初始值,reduce 函数将使用列表的第一个元素作为初始累积值。因此,计算过程如下:
- 初始化累积值为列表的第一个元素:
accumulator = 1 - 对于列表中的每个元素,将其乘以累积值:
accumulator = 1 * 2 = 2 - 继续对剩余元素进行累积乘积:
accumulator = 2 * 3 = 6,accumulator = 6 * 4 = 24,accumulator = 24 * 5 = 120
因此,最终的结果为 120。
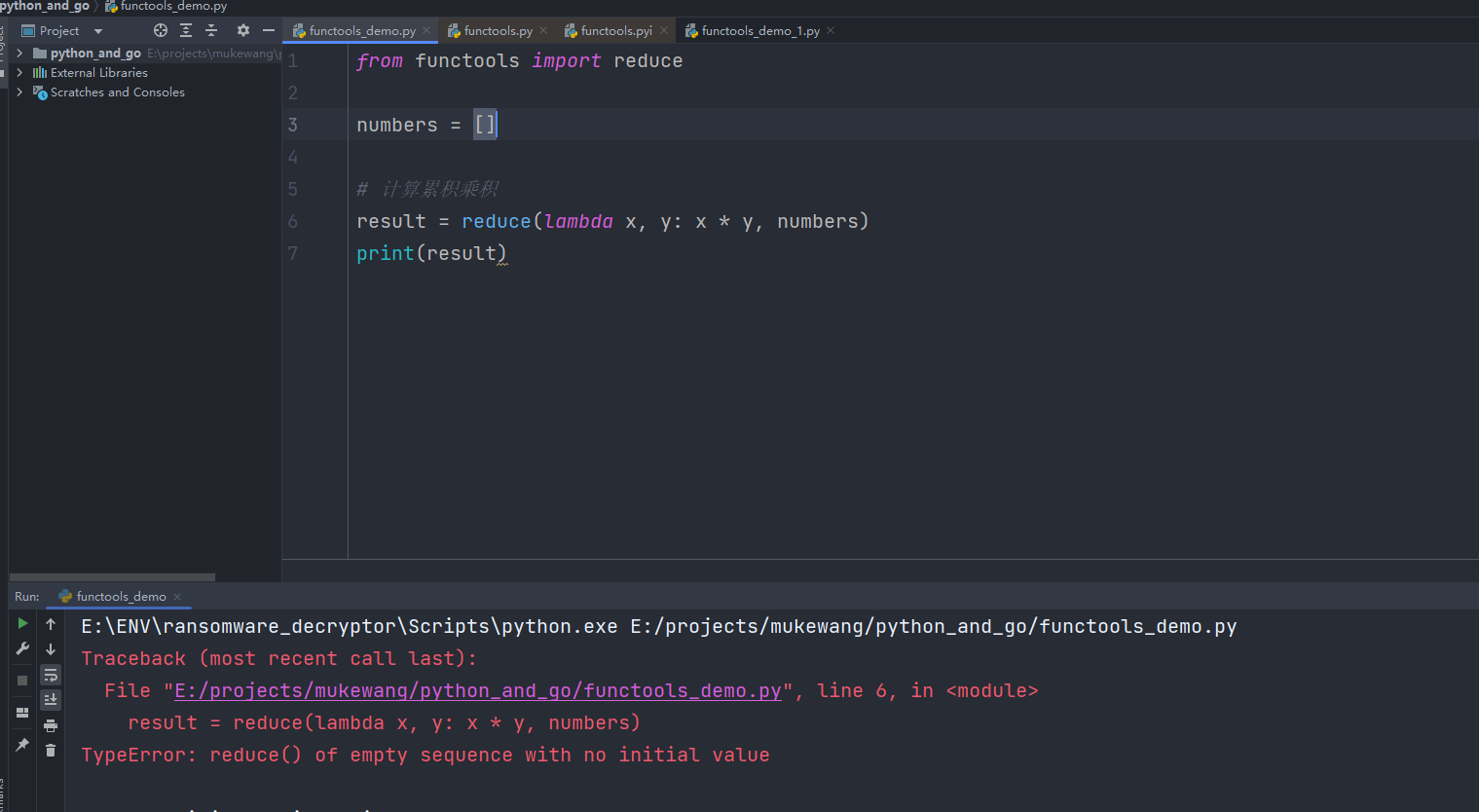
现在,让我们考虑一个情况,当我们有一个空列表时会发生什么。
from functools import reduce
numbers = []
# 计算累积乘积
result = reduce(lambda x, y: x * y, numbers)
print(result)
在这个例子中,由于列表为空,reduce 函数将无法确定初始累积值。如果没有提供初始值,将会导致 TypeError: reduce() of empty sequence with no initial value 错误。
为了避免这个错误,我们可以提供一个初始值,例如 1,以确保在处理空列表时也能够正常工作:
from functools import reduce
numbers = []
# 计算累积乘积,初始值为 1
result = reduce(lambda x, y: x * y, numbers, 1)
print(result) # 输出:1
在这个例子中,我们提供了初始值 1,即使列表为空,reduce 函数也可以正确地返回初始值作为结果。这说明了在使用 reduce 函数时提供初始值的重要性,特别是在处理空序列时。
如果不设置初始值, reduce()函数
使用序列的第一个值作为初始值,这个值就不会传递给卷积函数,导致计算错误。
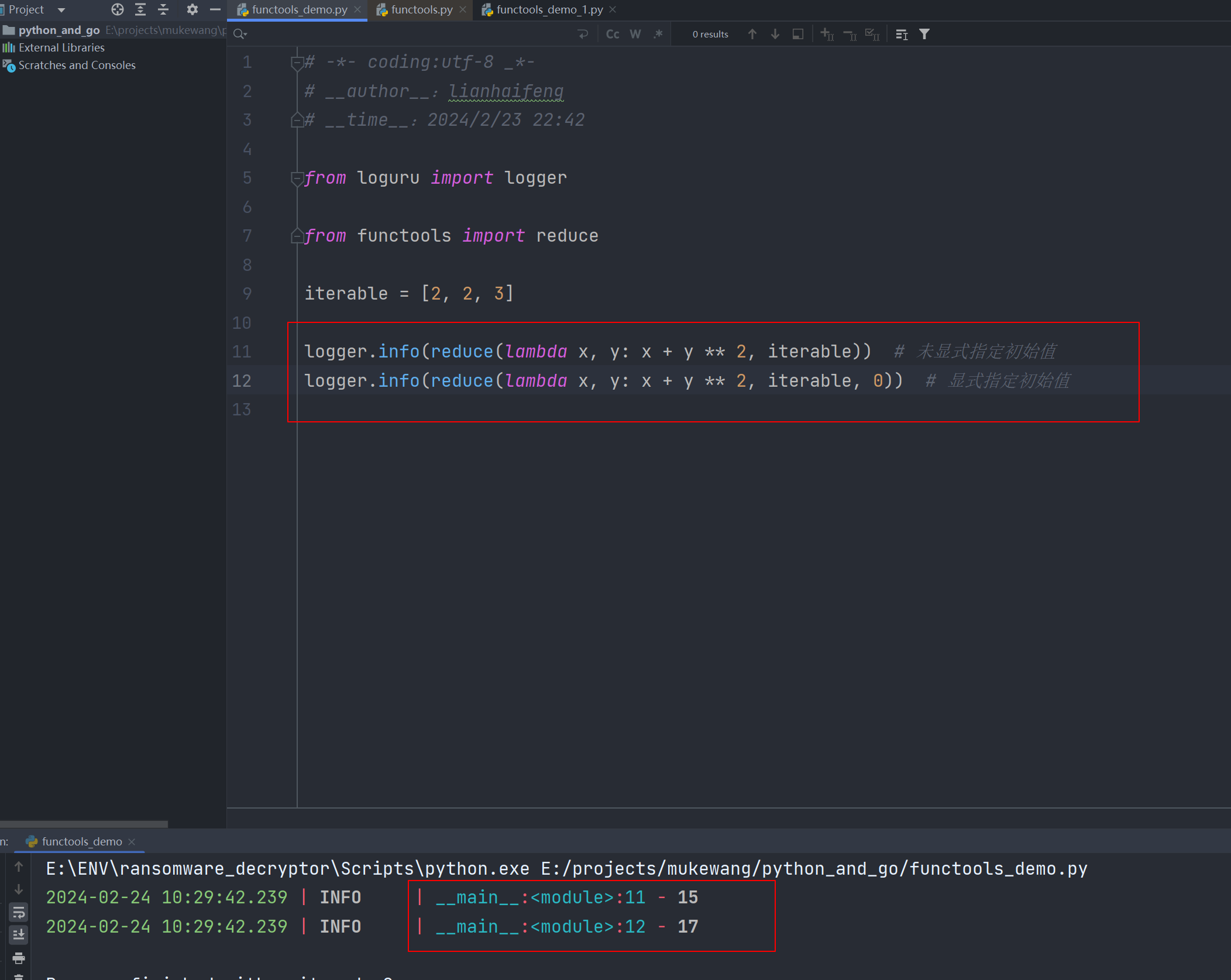
下面通过 reduce()高阶函数定义一些内置的归约函数。
# -*- coding:utf-8 _*-
# __author__:lianhaifeng
# __time__:2024/2/23 22:42
from typing import Callable, Any, Union
from loguru import logger
from functools import reduce
# 示例数据列表
data = [1, 2, 3, 4, 5]
data2 = []
# 计算平方和
sum_of_squares: Callable[[Any], int] = lambda iterable: reduce(lambda x, y: x + y ** 2, iterable, 0)
logger.info(f"Sum of squares: {sum_of_squares(data)}") # 输出: Sum of squares: 55
logger.info(f"Sum of squares: {sum_of_squares(data2)}") # 输出: Sum of squares: 0
# 计算总和
total_sum: Callable[[Any], int] = lambda iterable: reduce(lambda x, y: x + y, iterable, 0)
logger.info(f"Total sum: {total_sum(data)}") # 输出: Total sum: 15
logger.info(f"Total sum: {total_sum(data2)}") # 输出: Total sum: 0
# 计数
count_elements: Callable[[Any], Union[int, Any]] = lambda iterable: reduce(lambda x, y: x + 1, iterable, 0)
logger.info(f"Count of elements: {count_elements(data)}") # 输出: Count of elements: 5
logger.info(f"Count of elements: {count_elements(data2)}") # 输出: Count of elements: 0
# 找出最小值
minimum_value: Callable[[Any], Any] = lambda iterable: reduce(lambda x, y: x if x < y else y,
iterable) if iterable else None
logger.info(f"Minimum value: {minimum_value(data)}") # 输出: Minimum value: 1
logger.info(f"Minimum value: {minimum_value(data2)}") # 输出: Minimum value: None
# 找出最大值
maximum_value: Callable[[Any], Any] = lambda iterable: reduce(lambda x, y: x if x > y else y,
iterable) if iterable else None
logger.info(f"Maximum value: {maximum_value(data)}") # 输出: Maximum value: 5
logger.info(f"Maximum value: {maximum_value(data2)}") # 输出: Maximum value: None
functools.update_wrapper
functools.update_wrapper 是一个函数,用于手动更新一个包装器函数的特性以匹配被包装函数的特性。它通常与自定义装饰器一起使用,以确保包装器函数与原始函数的行为和元数据一致。
下面是一个示例,演示了 functools.update_wrapper 的用法:
# -*- coding:utf-8 _*-
# __author__:lianhaifeng
# __time__:2024/2/23 22:42
import functools
def another_decorator(func):
def wrapper(*args, **kwargs):
print("Another thing is happening before the function is called.")
result = func(*args, **kwargs)
print("Another thing is happening after the function is called.")
return result
# 使用 update_wrapper 来更新 wrapper 函数的特性以匹配 func 函数的特性
functools.update_wrapper(wrapper, func)
return wrapper
@another_decorator
def say_hello():
"""一个简单的打招呼函数。"""
print("你好!")
say_hello()
print(say_hello.__name__) # 输出:say_hello
print(say_hello.__doc__) # 输出:一个简单的打招呼函数。
say_hello()
print(say_hello.__name__) # Output: say_hello
print(say_hello.__doc__) # Output: 一个简单的打招呼函数。
在这个示例中,another_decorator 是一个装饰器,它没有使用 functools.wraps 装饰器来保留原始函数的元数据。相反,它使用了 functools.update_wrapper 函数来手动更新 wrapper 函数的属性以匹配 func 函数的属性,从而保留了原始函数的元数据。
wraps 函数是为了在装饰器中方便的拷贝被装饰函数的签名,而对 update_wrapper 做的一个包装
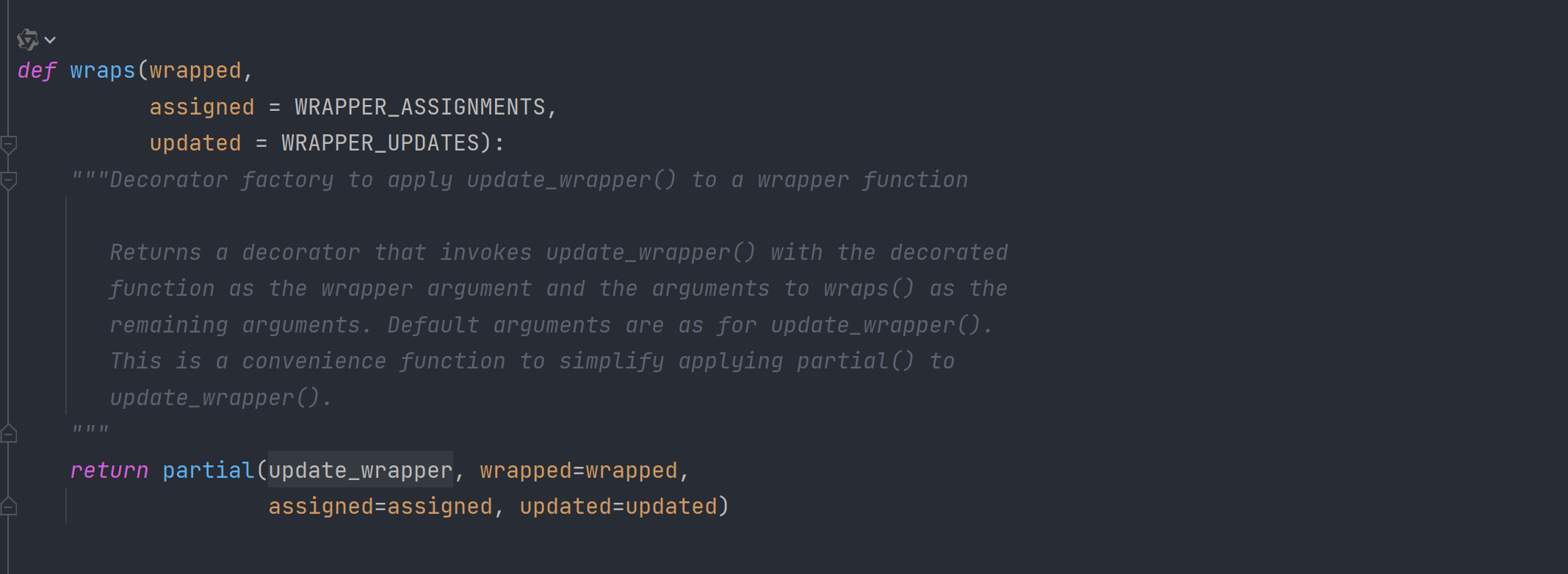
functools.wraps
functools.wraps 是 Python 的 functools 模块中的一个装饰器,用于创建行为良好的装饰器。装饰器是用来修改其他函数或方法行为的函数。当你将装饰器应用到一个函数或方法时,原始函数的元数据,比如名称、文档字符串和参数列表,可能会丢失或被修改。functools.wraps 帮助保留了这些元数据。
以下是 functools.wraps 的使用示例:
import functools
def my_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print("在调用函数之前做一些事情。")
result = func(*args, **kwargs)
print("在调用函数之后做一些事情。")
return result
return wrapper
@my_decorator
def say_hello():
"""一个简单的打招呼函数。"""
print("你好!")
say_hello()
print(say_hello.__name__) # 输出:say_hello
print(say_hello.__doc__) # 输出:一个简单的打招呼函数。
在这个示例中,my_decorator 是一个装饰器,用来装饰函数 say_hello。如果没有使用 functools.wraps,访问 say_hello.__name__ 或 say_hello.__doc__ 将不会得到预期的结果,因为它们会反映 wrapper 函数的元数据,而不是 say_hello 的元数据。但是,通过使用 @functools.wraps(func),原始函数 say_hello 的元数据被保留下来,使得装饰器的行为符合预期。
functools.singledispatch
singledispatch 装饰器用于函数重载,装饰器将函数转换为单调度泛型函数。
调度发生在
第一个参数的类型上
from functools import singledispatch
from loguru import logger
@singledispatch
def func(arg1, arg2):
logger.info(f"default implementation of func - {arg1, arg2}")
@func.register
def func_impl_1(arg1: str, arg2):
logger.info(f"【func_impl_1】with first argument as string - {arg1, arg2}")
@func.register
def func_impl_2(arg1: int, arg2):
logger.info(f"【func_impl_2】with first argument as int - {arg1, arg2}")
func(1.34, "hi")
func("test", "hello")
func(1, "hello")
logger.info(func.registry)
logger.info(func.registry.keys())
我们看些执行结果:

functools.singleDispatchMethod
将方法转换为单个调度泛型函数。
使用 @singledispatchmethod 定义函数时,请注意,调度发生在第一个 non-self 或 non-cls 参数的类型上
from functools import singledispatchmethod
class Sum:
@singledispatchmethod
def sum_method(self, arg1, arg2):
print("Default implementation with arg1 = %s and arg2 = %s" % (arg1, arg2))
@sum_method.register
def sum_method_int(self, arg1: int, arg2: int):
print("Sum with arg1 as integer. %s + %s = %s" % (arg1, arg2, arg1 + arg2))
@sum_method.register
def sum_method_float(self, arg1: float, arg2: float):
print("Sum with arg1 as float. %s + %s = %s" % (arg1, arg2, arg1 + arg2))
s = Sum()
s.sum_method(2, 3)
s.sum_method(2.1, 3.4)
s.sum_method("hi", 3.4)
"""
输出:
Sum with arg1 as integer. 2 + 3 = 5
Sum with arg1 as float. 2.1 + 3.4 = 5.5
Default implementation with arg1 = hi and arg2 = 3.4
"""
重载类方法:
from functools import singledispatchmethod
class Educative:
@singledispatchmethod
@classmethod
def new_print(cls, arg):
print("Default implementation. arg - %s" % (arg,))
@new_print.register(int)
@classmethod
def int_impl(cls, arg: int):
print("Integer implementation. arg - %s" % (arg,))
@new_print.register(bool)
@classmethod
def bool_impl(cls, arg):
print("Boolean implementation. arg - %s" % (arg,))
Educative.new_print(4)
Educative.new_print(True)
Educative.new_print("hi")
"""
Integer implementation. arg - 4
Boolean implementation. arg - True
Default implementation. arg - hi
"""
最后
如果你觉得文章还不错,请大家点赞、分享、关注下,因为这将是我持续输出更多优质文章的最强动力!
参考
更多functools知识请阅读官方文档!
https://docs.python.org/3/library/functools.html
















 4652
4652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











