







scrapy框架中Spider源码解析
一、scrapy架构
在讲解spider类之前,我们先来了解下scrapy这个框架的整体架构
请看下面scrapy工作流程图
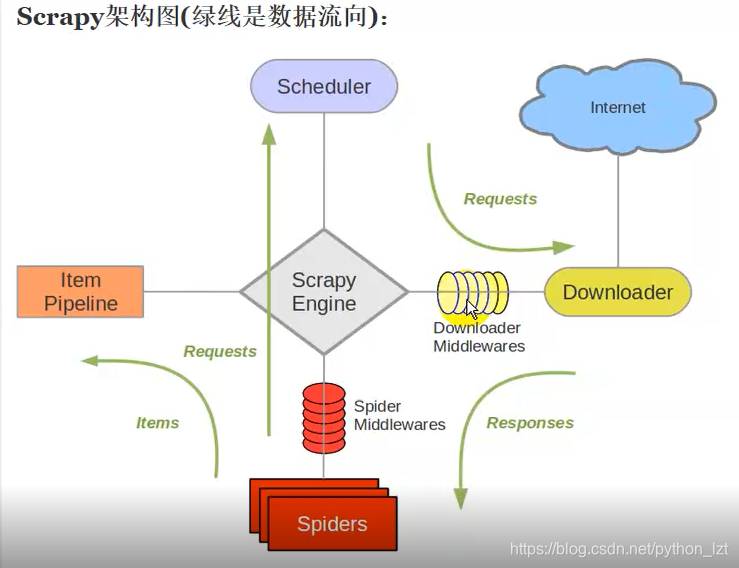
1.scrapy引擎(Scrapy Engine)
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。
2.调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎
3.下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
4.蜘蛛(Spiders)
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
5.管道(Item Pipeline)
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)
6.下载器中间件(Downloader Middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response(也包括引擎传递给下载器的Request)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
7.spider中间件(Spider Middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
scrapy架构工作流程(数据流向)
Scrapy中的数据流由执行引擎控制,其过程如下:
1.引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
2. 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
3. 引擎向调度器请求下一个要爬取的URL。
4. 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5. 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6. 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7. Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
8. 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
二、spider源码解析
Spider是最基本的类,所有爬虫必须继承这个类。
Spider类主要用到的函数及调用顺序为:
(1)init()方法: 初始化爬虫名字和start_urls列表。
注:这里爬虫名称是必须的,而且必须是唯一的
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not g`在这里插入代码片`etattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
self.__dict__.update(kwargs)
if not hasattr(self, 'start_urls'):
self.start_urls = []
(2)start_requests()方法:spider发起请求时会调用make_requests_from_url()生成Requests对象交给Scrapy下载并返回Response对象交给解析函数处理。
注:start_requests()方法只调用一次
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
def make_requests_from_url(self, url):
""" This method is deprecated. """
return Request(url, dont_filter=True)
(3)parse()方法:解析下载器返回的response,并返回Item或Requests(需指定回调函数)。Item传给Item pipline进行数据的持久化存储,Requests交由Scrapy下载,并由指定的回调函数处理,一直进行循环,直到处理完所有的数据为止。
重点:这个内容需要我们自己去写。parse()是默认的Request对象回调函数,解析返回的response对象, 注意回调函数的写法,是函数地址(callback=parse或者callback=None)。
def parse(self, response):
raise NotImplementedError
三、spider全部源码展示及详情解析
"""
Base class for Scrapy spiders
See documentation in docs/topics/spiders.rst
"""
import logging
import warnings
from scrapy import signals
from scrapy.http import Request
from scrapy.utils.trackref import object_ref
from scrapy.utils.url import url_is_from_spider
from scrapy.utils.deprecate import create_deprecated_class
from scrapy.exceptions import ScrapyDeprecationWarning
from scrapy.utils.deprecate import method_is_overridden
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
"""Base class for scrapy spiders. All spiders must inherit from this
class.
"""
#1、定义spider名字的字符串。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#2、name是spider最重要的属性,而且是必须的。一般做法是以该网站的域名来命名spider。例如我们在爬取豆瓣读书爬虫时使用‘name = "douban_book_spider"’
name = None
custom_settings = None
#初始化爬虫名字和start_urls列表。上面已经提到。
def __init__(self, name=None, **kwargs):
#初始化爬虫名字
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
self.__dict__.update(kwargs)
#初始化start_urls列表,当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一,后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
@property
def logger(self):
logger = logging.getLogger(self.name)
return logging.LoggerAdapter(logger, {'spider': self})
def log(self, message, level=logging.DEBUG, **kw):
"""Log the given message at the given log level
This helper wraps a log call to the logger within the spider, but you
can use it directly (e.g. Spider.logger.info('msg')) or use any other
Python logger too.
"""
self.logger.log(level, message, **kw)
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = cls(*args, **kwargs)
spider._set_crawler(crawler)
return spider
def set_crawler(self, crawler):
warnings.warn("set_crawler is deprecated, instantiate and bound the "
"spider to this crawler with from_crawler method "
"instead.",
category=ScrapyDeprecationWarning, stacklevel=2)
assert not hasattr(self, 'crawler'), "Spider already bounded to a " \
"crawler"
self._set_crawler(crawler)
def _set_crawler(self, crawler):
self.crawler = crawler
self.settings = crawler.settings
crawler.signals.connect(self.close, signals.spider_closed)
#该方法将读取start_urls列表内的地址,为每一个地址生成一个Request对象,并返回这些对象的迭代器。
#注意:该方法只会调用一次。
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
#1、start_requests()中调用,实际生成Request的函数。
#2、Request对象默认的回调函数为parse(),提交的方式为get。
def make_requests_from_url(self, url):
""" This method is deprecated. """
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。这个类需要我们自己去实现。
def parse(self, response):
raise NotImplementedError
@classmethod
def update_settings(cls, settings):
settings.setdict(cls.custom_settings or {}, priority='spider')
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
@staticmethod
def close(spider, reason):
closed = getattr(spider, 'closed', None)
if callable(closed):
return closed(reason)
def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
BaseSpider = create_deprecated_class('BaseSpider', Spider)
class ObsoleteClass(object):
def __init__(self, message):
self.message = message
def __getattr__(self, name):
raise AttributeError(self.message)
spiders = ObsoleteClass(
'"from scrapy.spider import spiders" no longer works - use '
'"from scrapy.spiderloader import SpiderLoader" and instantiate '
'it with your project settings"'
)
# Top-level imports
from scrapy.spiders.crawl import CrawlSpider, Rule
from scrapy.spiders.feed import XMLFeedSpider, CSVFeedSpider
from scrapy.spiders.sitemap import SitemapSpider
作者:小怪聊职场
链接:https://www.jianshu.com/p/d492adf17312
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
注:某些内容参考自csdn部分大佬博客

















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









