



开发背景:
ahp 又名层次分析法,是一个多因素多层次的决策算法。为了将层次分析算法的流程简易化,将算法的作用生活化,于是我在一个夜深人静的晚上准备抽空做这个软件。网络上有十分专业的ahp算法分析软件,其结构类似于SPSS,不管是输入还是输出都十分规范,过程中用到的矩阵明明白白,但唯一的缺点就是,想使用这个软件必须得亲手建立矩阵,而生活中没有谁会因为要做一个简单的决策去写枯燥的矩阵,去学习层次分析,因此我用python的tkinter做GUI,以点击的方式,自动为用户生成多个选择框,无需频繁构建矩阵。
开发工具:
编程语言:python,所用模块:tkinter,matplotlib,numpy,PIL,seaborn。操作系统:windows。
算法简介:
层次分析法(Analytic Hierarchy Process,简称AHP)是美国运筹学家、匹兹堡大学T. L. Saaty教授在20世纪70年代初期提出的, AHP是对定性问题进行定量分析的一种简便、灵活而又实用的多准则决策方法。它的特点是把复杂问题中的各种因素通过划分为相互联系的有序层次,使之条理化,根据对一定客观现实的主观判断结构(主要是两两比较)把专家意见和分析者的客观判断结果直接而有效地结合起来,将一层次元素两两比较的重要性进行定量描述。而后,利用数学方法计算反映每一层次元素的相对重要性次序的权值,通过所有层次之间的总排序计算所有元素的相对权重并进行排序。该方法自1982年被介绍到我国以来,以其定性分析与定量分析相结合地处理各种决策因素的特点,以及其系统灵活简洁的优点,迅速地在我国社会经济各个领域内,如能源系统分析、城市规划、经济管理、科研评价等,得到了广泛的重视和应用。
实现方法:
层次分析法(ahp)需要输入两个层次,分别为方案层,准则层。最终返回一个层次,目标层。
为了不麻烦用户去输入矩阵,而是通过简单的选择我们后台帮助用户补全矩阵,仔细观察ahp算法中的方案层和准则层,他们实际上都是对称矩阵,只需要得到‘一半’的矩阵,后续用python实现它的对称即可,而这‘一半’的矩阵,又都是两两因素层的因素,或者准则层的准则的比值,这一点完全可以靠多个选择题来收集数据。
得到数据后,将其加工成准则层和方案层的矩阵,按照ahp算法的流程:建立层次结构模型,构造比较判别矩阵,计算单排序向量和一致性检测,总的排序选优。这部分我写了完整的分析流程。
import numpy as np
class Ahp_method(object):
def __init__(self,array_rule,list_item):
if array_rule.shape[0] != array_rule.shape[1]:
raise Exception('你的准则层矩阵不够方')
for i in list_item:
if i.shape[0] != i.shape[1]:
raise Exception('你的方案层某矩阵不够方')
self._array_rule = array_rule # 准则层矩阵
self._lsit_item = list_item # 包含多个方案层矩阵的列表
self._character : float # 最大特征值
self._dr : int = self._array_rule.shape[0] # 准则层层矩阵的维度
self._di : int # 方案层矩阵的维度
self.CI : float # 一致性指标
self.CR : float # 一致性比率
self.CR_RULE = [0,0,0,0.58,0.90,1.12,1.26,1.32,1.41,1.45,1.49,1.52,1.54]
def get_character(self):
'''计算特征值'''
self._character = np.round(max(np.linalg.eig(self._array_rule)[0]),3)
return self._character
def get_CI(self):
self.CI = (self._character - self._dr) / (self._dr - 1)
return self.CI
def get_CR(self):
self.CR = self.get_CI()/self.CR_RULE[self._dr]
return self.CR
@staticmethod
def get_ar(lst):
'''
输入一维列表, 返回转换成对称矩阵后的维度
:param lst:
:return:n:维度
'''
l,v,d = len(lst),1,1
while True:
if v == l:
return d + 1
if v > l:
raise Exception('传入的矩阵存在错误')
v += d + 1
d += 1
@staticmethod
def ret_np(ori, roun:int=3):
'''
:param ori:ret value()返回的字典
:param n: 维度
:return: array
'''
n = Ahp_method.get_ar(ori)
lst, res = [], []
for v in ori:
lst.append(v)
ind = 0
for i in range(n):
inner = []
for j in range(n):
if i == j:
inner.append(1)
elif i < j:
inner.append(lst[ind])
ind += 1
elif i > j:
inner.append(round(1 / res[j][i], roun))
res.append(inner)
return np.array(res)
def get_one(self,array):
'''得到某个矩阵的标准化特征向量'''
d = array.shape[0]
lst_root = []
for i in range(d):
lst_root.append(Ahp_method.multi(array[i])**(1/d)) # 每行乘积的d次方根
lst_sum = sum(lst_root)
final = np.array([np.round(i/lst_sum,3) for i in lst_root])
print('final',final)
return final
@staticmethod
def multi(n):
result = 1
for i in n:
result = result * i
return result
def check(self):
'''准则层向量的一致性检验'''
self.get_character()
cr = self.get_CR()
if not cr < 0.1:
return 0,f'未通过一致性检验,检验结果为{self.CR}>0.1'
else:
return 1,f'一致性检验结果为{self.CR},小于0.1'
'''得到所有矩阵的标准化特征向量'''
def get_all(self):
self._array_rule_character = self.get_one(self._array_rule)
self._list_item_character = []
for i in range(len(self._lsit_item[0][0])):
buf = []
for j in [self.get_one(i) for i in self._lsit_item]:
buf.append(j[i])
self._list_item_character.append(np.array(buf[:]))
buf.clear()
def get_final(self):
'''最终排序权值'''
self.res = [i.dot(self._array_rule_character.T) for i in self._list_item_character]
return self.res
def process(self):
print(self.check())
self.get_all()
return self.get_final()这一部分依靠numpy库可以轻松实现,numpy不只支持数组,它更支持矩阵,求逆,求特征向量,求矩阵运算都有十分强大的api,此处不做赘述。
得到总的排序选优结果后,用matplotlib+seaborn实现柱状图的显示和结果的美化,将输出的结果储存到本地,用tkinter打开,优化用户体验。(其实用户就是我,就我自己用。。。)
细节回顾:
整个流程看起来非常简单,在我第一天做这东西的时候,我预计是一个晚上做完,由于这个原因,我就当他是个小demo,根本没准备维护他,或者想到要解耦,架构什么的更没有想到,所以就是一口气顺着往下写,再加上tkinter不是非常专业的GUI工具,前后端分离性较差,写着写着就有了屎山代码的味儿,尽管我第一天是各种注释各种写class封装。
然后悲剧来了,有时候遇到小麻烦不说,主要变量不好找,才七百行的代码就分了仨文件,硬着头皮给他干完了。
在写这个小软件的过程中也有些珍贵的东西:
1.循环中为容器添加多参数的匿名函数函数名,容易出现bug。见第一篇博
2.pyinstaller打包exe,在其他操作系统运行时,程序中matplotlib用到的字体找不到,这个的解决方法是直接将自己做图表用到的字体复制到根目录,用相对路径的方式导入字体。
3.其他操作系统或电脑打开该GUI布局错乱,解决方法:统一布局方式,不要将pack布局和place混合使用。
4.在其他计算机运行时,tkinter中的字体丢失,目前没找到办法,是个bug。
5.tkinter真滴就自己玩玩好,真想写个让自己心情舒畅的东西,还是用web好。
6.tkinter和matplotlib不大对付,他俩一同时出来好像就要打架,解决方法当然是matplotlib先存储,然后用tkinter打开存储的图片。
软件使用方法:
1.打开抉择.exe。

2.进入首页,run。

3.点击箭头选择准则层数量。
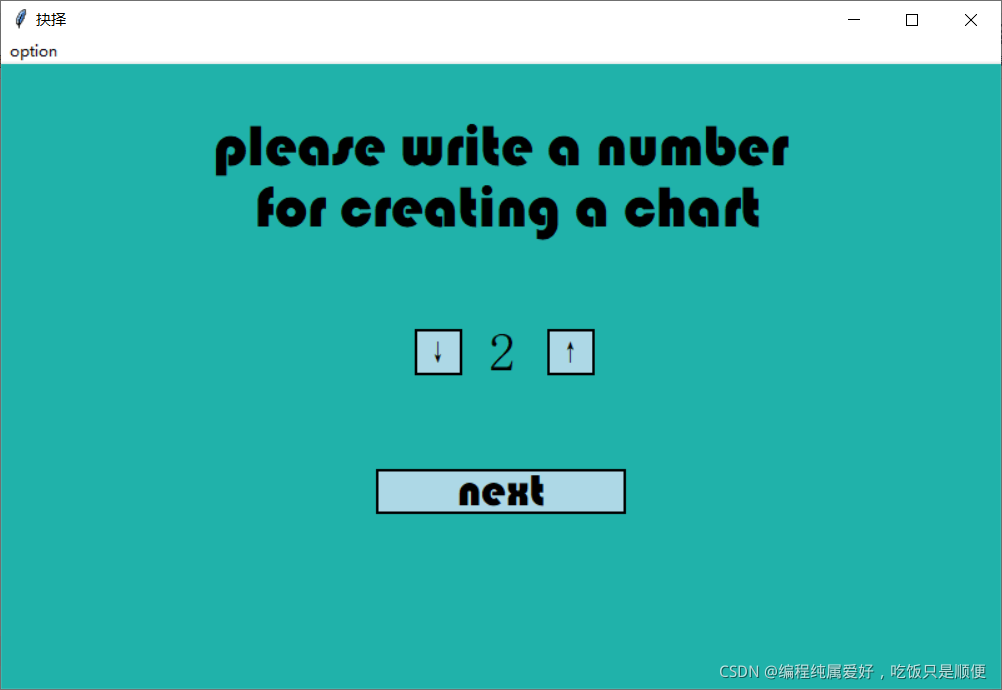
4.填写准则层内容(此处我选择的是对书籍的挑选标准,假如我准备买书关心的是这三个准则),点击NEXT。

5.填写方案层,此处略。
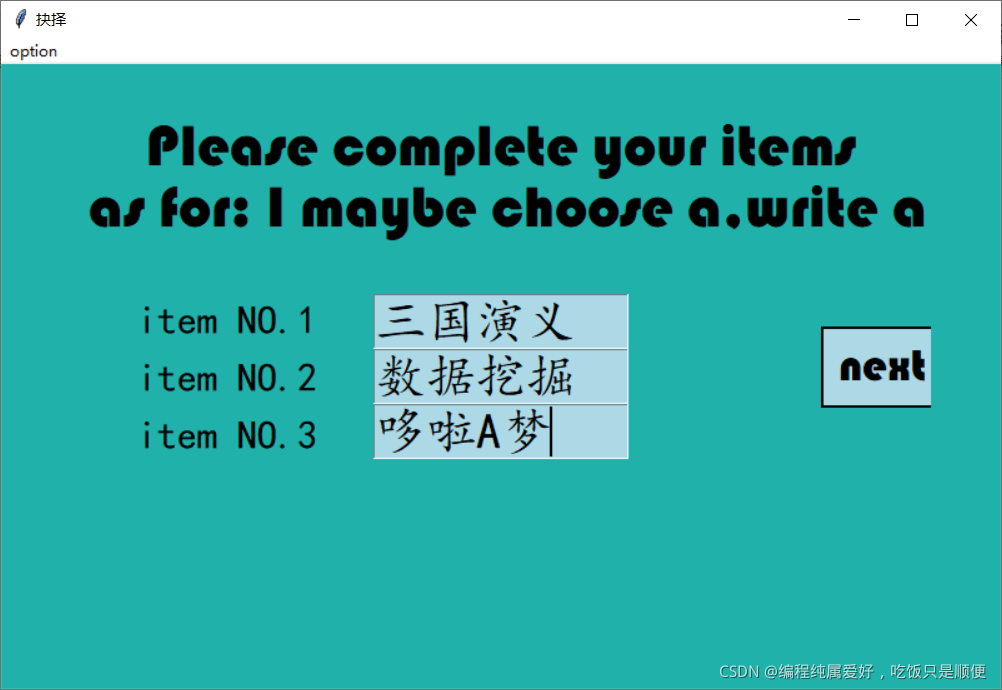
6.按要求填写,按照你的两层输入,系统自动生成一些问题 ,回答后得到结果(此处为准则层的问题),如图,左边为准则层的益处和有趣,你更偏向哪个?就点击哪个,距离中间越远的按钮,表示程度越深,一般不要点击太深,因为这是按照ahp 的标度尺13579做的按钮,一般点蓝色或者淡蓝色即可,除非你梵蒂冈要和美国比GDP,你可点击红色。图中第三行的1/12表示一共有十二个问题,现在是第一个问题。

7.等待进度条,numpy计算起来有多快肯定不用我说,做这个的意义,懂得都懂,嘿嘿,就是好看。tkinter不能直接展示gif,不过可以用canvas容器,PIL打开图像,将其迭代器打开,放在画布里循环展示图片。

8.结果如下,按图中来说哆啦A梦是这三本里最适合我的图书了,不过摸着良心说话,我偏袒它了。
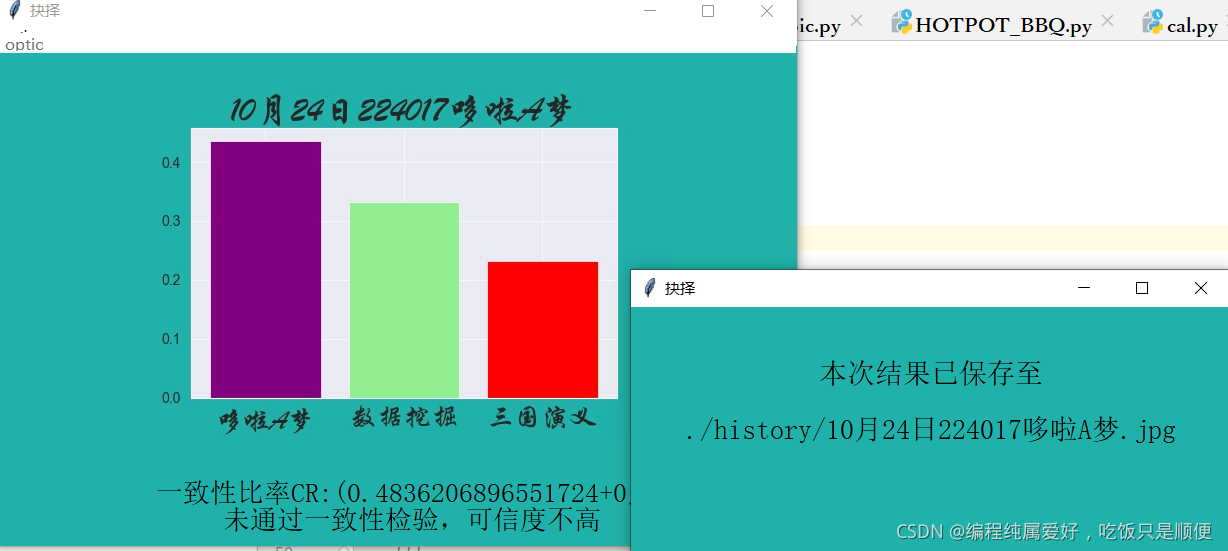
9.一致性比率:小于0.1即为可信,通过一致性检验,他的意义就是,用户输入的数据并不自相矛盾。上图中未通过一致性比率, 是因为我在输入准则层数据的时候做了一个自相矛盾的选择,比如a>b,b>c,但是当比较a和c的时候,我选择了a<c,这样会导致一定程度的不可信,但结局确实比较符合我的心里预期,如果非给我看着三本书,我首选是看会哆啦A梦,然后是数据挖掘,最后是三国演义。
10.额外功能,换肤。
总结:
这是一个python开发,核心算法为ahp,主要价值为简化用户输入,将算法日常化的exe软件,Windows和Ubuntu的平台都可以使用,缺点是在不同的环境中可能出现字体丢失,布局轻微变形的情况,但不影响功能的使用。目前简易实现ahp算法的sdk以及具体资源准备在CSDN上传,过审可能要几天,粗略估计应该只有我一个人会用它,不过我觉得这个东西还是很有意义的。最起码我不用因为选择困难症发愁了。
PS:完整代码就不发了, 因为没有完整解耦的缘故,整个流程看起来会比较枯燥。再简单的项目,都不能想着一口气写完,不然麻烦大大滴。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









