







Python 3.10发布了,还需要Ordered Dict吗?
全文2600字,阅读约需6分钟
早些时候,我们在讨论“列表是否可以替代元组”时,“稍微深入”的讨论过Python中列表和元组的区别(参见前文《从一个面试题说开去:有了列表为什么还要元组》)。
其实类似的情况还有很多,比如
-
dictvsset -
dictvsOrderedDict -
其他。。。。
这些数据结构在某些方面具有相似性,在使用时会引起的困惑,今天我们来聊聊 OrderedDict 和 dict,主要涉及几个方面:
- OrderedDict的用法和特点
- OrderedDict和dict的不同之处
- OrderedDict不可替代的应用场景
- Python核心开发对OrderedDict的看法
1. 关于OrderedDict
关于OrderedDict 我们可以用一句话来描述:它是一个有序的字典。
其实在2008年之前是没有OrderedDict的,于是很多开发者自行实现了有序字典,比如:
-
知名的Web框架Django创建了
SortedDict -
pypi上有开发上传了
StableDict,供他人使用
这从侧面说明了Python使用过程中,对”字典有序性“的需求。于是后来有了PEP372提案:由Python标准库提供统一的有序字典(OrderedDict),并于在python 2.7、3.1中发布于collections 模块中。
通常,collections模块中存放了 ** “好用、但不那么常用” ** 的的容器型数据类型,比namedtuple、defaultdict等。可能有些人还不了解OrderedDict,这里来简单介绍一下:
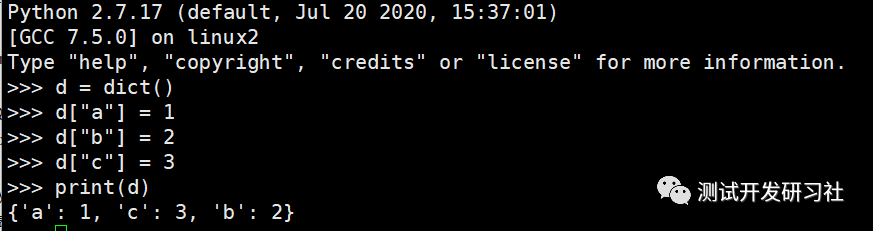
正如前面提到的,OrderedDict位于collections模块中,使用前需要导入
from collections import OrderedDict
d = OrderedDict()
d["a"] = 1
d["c"] = 3
d["b"] = 2
print(d) # 打印OrderedDict
for _ in d: # 遍历OrderedDict
print(_)
OrderedDict([('a', 1), ('c', 3), ('b', 2)])
a
c
b
从执行结果可以看出来,OrderedDict中的数据是稳定有序,数据的排序取决于**“数据加入OrderedDict的顺序”**。
此外,OrderedDict也可接受多个键值对进行创建,以下几个例子的执行结果相同:
d = OrderedDict([("a", 1), ("b", 2)]) # 例子1
d = OrderedDict({"a": 1, "b": 2}) # 例子2
d = OrderedDict(a=1, b=2) # 例子3
例子1中,
[("a", 1), ("b", 2)]表示2个键值对,也可写作[["a", 1], ["b", 2]],这里我们使用了元组表示每个键值对,具体原因可以参考前文(>>>点击这里<<<)例子2中,
{"a": 1, "b": 2}首先会创建字典,然后再传递给OrderedDict,在python3.6之前、之后的版本结果会有不同,具体原因可以参考后文
作为dict的子类,OrderedDict在创建之后,可以采用dict相同的方式进行读写:
print(d["b"]) # 打印内容
del d["a"] # 移除内容
d["b"] = "x" # 修改内容
print(d)
输出
2
OrderedDict([('c', 3), ('b', 'x')])
不过需要提醒的是,作为有序字典,添加和删除数据时,会改变排序,修改数据则不会
2. Python3.7之后的dict
在Python 3.6的时候 , dict采用了新的实现方式,相对于之前(比如Python3.5)内存使用量减少了20% 到 25%。
这种实现方式还有一个细节:会保留key的排序,但同时官方提示:后期可能会变化,所以不应该依赖这一特性。
而在Python 3.7的时候,宣布一个特性正式成为Python语言规范的一部分, 此后所有的Python都会遵循这一特性:
字典的key是有序的
Python 2.7 (无序,输出顺序不可控)
Python 3.7 (有序,输出顺序取决于输入顺序)
3. OrderedDict和dict的不同之处
老规矩,先看看一下两个类型的方法差异:
print(set(dir(d_1)) ^ set(dir(od_1)))
输出结果:
{'move_to_end', '__dict__'}
从这个角度来看, OrderedDict和dict的差别不大,
这也正常,因为OrderedDict是dict的子类,只在有序性上进行了扩展:
-
OrderedDict内的数据有明确的排序
-
move_to_end方法可以将指定的数据,移动到最前或最后, -
popitem方法可以选择从最前或最后,移除并返回一个项数据
我把OrderedDict和dict的区别做成一个表格,这样看起来更直观一些
| 功能 | OrderedDict | dict |
|---|---|---|
| 内存开销 | 高 | 低 |
| 读写速度 | 慢 | 快 |
| 排序敏感 | 是 | 否 |
| 比较速度 | 快 | 慢 |
| 允许附加其他属性 | 是 | 否 |
(基于Python3.10为例,在旧版本中会还有其他差别)
概括来说,OrderedDict通过增加内存开销的方式,提供了的排序的支持,并且通过__dict__属性,提供更灵活的使用方法
4. OrderedDict不可替代的应用场景
说的这里,我们对OrderedDict和dict有了简单的了解
- 3.1,发布OrderedDict ,使字典有序
- 3.6,发布新版dict,使字典有序
而且新版的dict在性能上也有巨大提升,这样看来OrderedDict 似乎应该退出历史舞台了?
那么,是什么让OrderedDict保留至今(3.10),是有什么不可替代的场景吗?
还真有!
新的dict,虽然会让key有序,但那是为了提升减少开销性能带来的“额外福利”,
OrderedDict则不同,“排序”,不惜以增加开销的代价,专门跟踪、记录key的排序,并提供的高效的方法进行重新排序,下面我们介绍几个OrderedDict擅长的例子。
1. 严格判断字典之间的相等性
假设有两个排序不一样,但内容相同数据,它们之间应该是相等的关系吗?
-
以两个排序不同的dict为例,执行结果如下
d_1 = dict(a=1, b=2) d_2 = dict(b=2, a=1) print(d_1 == d_2)True这是因为在之前的dict中“顺序”是个不存在的概念,自然也就没有验证顺序的意义
只要两个字典的键值对相同,则认为它们相等
-
再看看OrderedDict 的表现
od_1 = OrderedDict(a=1, b=2) od_2 = OrderedDict(b=2, a=1) print(od_1 == od_2)FalseOrderedDict将“顺序”视为其内容的一部分,两个OrderedDict即使数据内容一样,但排序的不同,也认为它们不相等
-
有一个特殊情况:OrderedDict和dict 比较时
因为OrderedDict是dict的子类,可看作**“两个dict进行”**,排序不同自然也是相等的
print(od_1 == d_1)True
如果在你的某个业务场景,数据排序是一个重要属性,或者有明确的排序需求,那么就应该使用OrderedDict而不是dict,这样不论是字面上还有实际效果上都非常理想的。
2. 构建基于字典的队列
OrderedDict的move_to_end方法和popitem方法提供了在两端进出数据的方式,可以实现LIFO或FIFO队列。
不过,OrderedDict毕竟是字典,在按序返回数据之外,还可以根据key快速的返回数据,这就传统队列不具有的优势。
一个经典的应用是lru_cache:通过有限容量的队列,为函数执行结果进行缓存,节约函数调用时间
import time
from collections import OrderedDict
def lru_cache(func, maxsize=128):
cache = OrderedDict()
def f(*args):
if args in cache: # 如果有缓存
result = cache[args] # 则使用缓存
else:
result = func(*args) # 否则,调用函数获取结果
cache[args] = result # 并放入缓存
# 以上为字典特性, 以下为队列特性
cache.move_to_end(args) # 最近被用的缓存移动到右边
if len(cache) > maxsize:
cache.popitem(last=False) # 如果太多,从左边开始删除
return result
return f
def fibs(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibs(n - 1) + fibs(n - 2)
time1 = time.time()
print("result:", fibs(35))
print(f"times:{time.time()- time1:.2f}s")
我们编写一个递归函数fibs,执行耗时大概2秒
result: 9227465
times:2.17s
然后,将lru_cache作为fibs的装饰器
@lru_cache
def fibs(n):
....
重新执行,耗时不到1秒
result 9227465
0.00s
此处lru_cache函数是为了演示OrderedDict,逻辑比较简单
生产环境中应该进行优化再使用,或者选择python提供的functools.lru_cache
3. 使用属性的方式访问item
从字典中取值时,通常使用成为get item的方式进行,比如这样
d ={"a":1}
print(d['a'])
如果需要使用属性的方式访问,会报错
print(d.a)
Traceback (most recent call last):
print(d.a)
AttributeError: 'dict' object has no attribute 'a'
如果使用OrderedDict,则可以通过修改__dict__属性实现这一效果
d = OrderedDict(a=1)
d.__dict__ = d # OrderedDict:我竟然引用我自己??
print(d.a) # 通过属性读取数据内容
d.xxx = 3 # 通过属性添加新的数据内容
print(d["xxx"])
1
3
严格来说,这个特性和“dict有序”一样,属于实现方式上的额外福利,应用得当就可以产生很多好玩好用的效果
5. Python核心开发者的看法
最后,用Raymond( Python 核心开发者)对OrderedDict的看法作为本文的结尾,这会与会给大家带来更多的收获和思考
让我们一起看看真正的大佬是如何理解OrderedDict的用处的:
我认为将 “内置的紧凑有序的 dict” 代替 “OrderedDict”是错误的:它们服务于不同的cases,并且应该有不同的实现来最好地服务于这些cases。
十年前,当OrderedDict 的PEP 372被接受时,Armin 和我研究了各种实施策略。它归结为“将排序保持在数组中”或”使用双向链表“之间的较量。
选择后者是因为它对于涉及插入和删除的混合工况下具有卓越的算法性能。特别是,它为从任何位置弹出或执行 move_to_front 或 move_to_last 操作提供了恒定时间保证(例如,这有助于实现 LRU 缓存)。
相比之下,新的 Python 内置在字典提出设计时有一个不同的目标:即紧凑存储,排序是一个副作用。
我认为它(OrderedDict)必须与内置 dict 分开发展,并且其实现策略主要集中在“有效维护排序”,以最好地支持通过排序做有趣事情的应用程序(例如使用 OrderedDict 作为循环队列),这是其存在的理由
欢迎关注我的公众号“ 测试开发研习社”,专注Python开发及测试技术


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









