







目录
SINTERSTORE / SUNIONSTORE / DIFFSTORE
Hash 哈希
⼏乎所有的主流编程语⾔都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数
组、映射。
TIPS:哈希类型中的映射关系通常称为:field-value 用于区别Redis整体的键值对key-val的关系
所以在Redis的value中使用hash类型应该是这么表示key - field - val
常用指令
HSET
设置hash中指定的字段field 的值 value
语法:
HSET key field value [field value ...]返回值:添加的字段的个数
示例:
HGET
获取hash中指定字段的值
语法:
HGET key field返回值:字段对应的值或者nil
示例:

HEXISTS
判断hash中是否有指定的字段
语法:
HEXISTS key field返回值:1表示存在,0表示不存在
示例:

HDEL
删除hash中指定的字段
语法:
HDEL key field [field ...]返回值:本次操作删除的字段个数
示例:

HKEYS
获取hash中的所有字段
语法:
HKEYS key返回值:字段列表
示例:
HVALS
获取hash中所有的值
语法:
HVALS key返回值:所有的值val
示例:
HGETALL
获取哈希汇总的所有字段以及对应的值
语法:
HGETALL key返回值:字段和其对应的值
示例:

HMGET
一次获取hash中字段的多个值
语法:
HMGET key field [field ...]返回值:字段对应的值或者nil
示例:

TIPS:在使⽤HGETALL时,如果哈希元素个数⽐较多,会存在阻塞Redis的可能。如果开发⼈员只需要获取部分field,可以使⽤HMGET
内部编码
哈希的内部编码有两种:
1.ziplist(压缩列表):当hash类型元素小于hash-max-ziplist-entries配置(默认512个)、同时所有的值都小于hash-max-ziplist-value(默认64字节),Redis会使用ziplist作为hash的内部实现,zipliost使用更加紧凑的就够实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀
2.hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时的hashlist的读写小会下降,而hashtable的读写时间复杂度为O(1)
Hash类型和关系型数据库
- 哈希类型是稀疏的,⽽关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的field,⽽关系型数据库⼀旦添加新的列,所有⾏都要为其设置值,即使为null
- 关系数据库可以做复杂的关系查询,而Reid社区模拟关系型复杂查询,例如:联表查询、聚合查询等基本不可能,维护成本高
缓存方式对比
现在有三种方法缓存用户信息
1.原生字符串类型 -- 使用字符串类型,每个属性占用一个键
set user:1:name gc
set user:1:age 22
set user:1:sex 男优点: 实现简单,针对个别属性变更也很灵活。
缺点:占⽤过多的键,内存占⽤量较⼤,同时⽤⼾信息在?Redis?中⽐较分散,缺少内聚性,所以这种⽅案基本没有实⽤性
2.序列化字符串类型,例如JSON格式
set user:1 经过序列化后的字符串~~优点:针对总是以整体为操作的信息比较合适
缺点:序列化和反序列化本身需要一定的开销,如果总是操控个别属性的话不方便
3.哈希类型
hmset user:1 name gc age 22 sex 男优点:简单直观且灵活
缺点:需要控制hash在ziplist和hashtable两种内部编码的转换,可能会造成内存开销大
List 列表
列表类型是⽤来存储多个有序的字符串,⼀个列表最多可以存储2^32-1 个元素。在Redis中,可以对列表两端插⼊(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等
入图对列表两端的插入和 弹出操作
特点
- 1. 列表中元素是有序的,是可以使用索引下标获取某个元素或者某个范围的元素列表
- 2. 获取会得到该下标的元素,删除会将列表的长度减小
- 3. 列表的元素允许重复
常用命令
LPUSH
将⼀个或者多个元素从左侧放⼊(头插)到list中
返回值:插⼊后list的⻓度
示例:

LPUSHX
在key存在时,将⼀个或者多个元素从左侧放⼊(头插)到list中。不存在则直接返回
语法:
LPUSHX key element [element ...] 返回值:插⼊后list的⻓度。
示例:

RPUSH
将⼀个或者多个元素从右侧放⼊(尾插)到list中。
语法:
RPUSH key element [element ...]返回值:插⼊后list的⻓度
示例:

RPUSHX
在key存在时,将⼀个或者多个元素从右侧放⼊(尾插)到list中
语法:
RPUSHX key element [element ...] 返回值:插入之后的list长度
示例:

LRANGE
获取从start到end区间的所有元素,左闭右闭
语法:
LRANGE key start stop 返回值:指定区间内的元素
如果start为0,stop为-1就是遍历所有
示例:

LPOP / RPOP
lpop 从list左侧取出元素(即头删)
rpop从list右侧取出元素(即尾删)
语法:
LPOP key
RPOP key返回值:取出的元素或者nil
示例:

LINDEX
获取从左数第index位置的元素
语法:
LINDEX key index 返回值:取出的元素或者nil
示例:

LINSERT
在特定位置插⼊元素。
语法:
LINSERT key <BEFORE | AFTER> pivot element 返回值:插入之后的list长度
示例:

阻塞(BLOCK)版本的命令
blpop和brpop是lpop和rpop的阻塞版本,和对应⾮阻塞版本的作⽤基本⼀致
但是阻塞版本会有如下特殊:
- 在列表中有元素的情况下,阻塞和⾮阻塞表现是⼀致的。但如果列表中没有元素,⾮阻塞版本会理解返回nil,但阻塞版本会根据timeout,阻塞⼀段时间,期间Redis可以执⾏其他命令,但要求执⾏该命令的客⼾端会表现为阻塞状态
- 命令中如果设置了多个键,那么会从左向右进⾏遍历键,⼀旦有⼀个键对应的列表中可以弹出元素,命令⽴即返回
- 如果多个客⼾端同时多⼀个键执⾏pop,则最先执⾏命令的客⼾端会得到弹出的元素
内部编码
列表类型的内部编码有两种:
1.ziplist(压缩列表):当hash类型元素小于hash-max-ziplist-entries配置(默认512个)、同时所有的值都小于hash-max-ziplist-value(默认64字节),Redis会使用ziplist作为hash的内部实现,zipliost使用更加紧凑的就够实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀
2.linkedlist(链表):大哥你列表无法满足ziplist条件的时候,Redis会使用linkedlist作为列表内部实现
使用场景
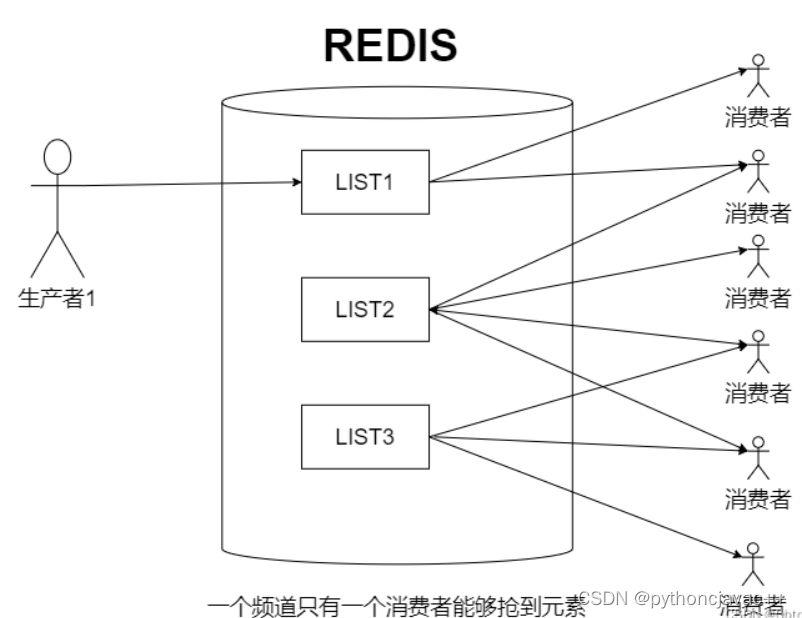
消息队列
Redis可以使⽤lpush+brpop命令组合实现经典的阻塞式⽣产者-消费者模型队列,⽣产者客⼾端使⽤lpush从列表左侧插⼊元素,多个消费者客⼾端使⽤brpop命令阻塞式地从队列中"争抢"队⾸元素。通过多个客⼾端来保证消费的负载均衡和⾼可⽤性
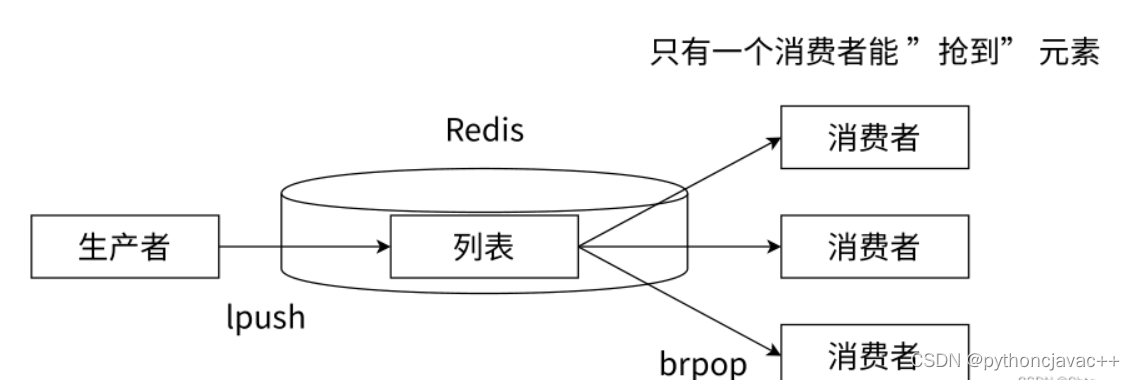
Redis分频道的阻塞队列模型:
微博列表
每个⽤⼾都有属于⾃⼰的Timeline(微博列表),现需要分⻚展⽰⽂章列表。此时可以考虑使⽤
列表,因为列表不但是有序的,同时⽀持按照索引范围获取元素。
1.每篇微博使用哈希结构存储,举例微博有中有三个重要属性,title,content,time
hmset mblog:1 title xx time 1476536196 content xxxxx
...
hmset mblog:n title xx time 1476536196 content xxxxx2.向用户的微博列表添加微博文章,user:uid:mblogs 作为键
其实就是往用户微博列表中,插入微博文章的哈希键
lpush user:1:mblogs mblog:1 mblog:3
...
lpush user:k:mblogs mblog:93.获取用户的微博列表,例如获取用户前1~6篇微博文章
keylist = lrange user:1:mblogs 0 9
for key in keylist{
hgetall key
}这种方案实际可能存在两个问题:
1. 1+n问题,如果每次获取的微博个数较多,需要多次hgetall,此时可以考虑使用pipeline流水线模式批量提交命令
2.分裂获取文章时,lrange在列表两端表现好,获取列表中间元素标签差。此时可以对列表文进行拆分提高效率
Set 集合
1.集合类型也是保存多个字符串类型的元素的,与列表类型不同的是,集合中元素之间是⽆序的
2.集合元素不允许重复,⼀个集合中最多可以存储2^32 -1 个元素。Redis除了⽀持集合内的增删查改操作,同时还⽀持多个集合取交集、并集、差集,合理地使⽤好集合类型,能在实际开发中解决很多问题
常用命令
SADD
将⼀个或者多个元素添加到set中。注意,重复的元素⽆法添加到set中。
语法:
SADD key member [member ...]返回值:本次添加成功的元素个数
示例:

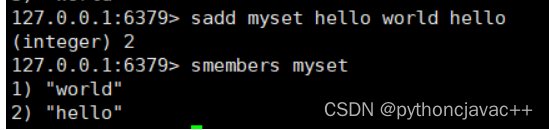
SMEMBERS
获取⼀个set中的所有元素,注意,元素间的顺序是⽆序的。
语法:
SMEMBERS key 返回值:所有元素的列表
示例:
SISMEMBER
判断⼀个元素在不在set中。
语法:
SISMEMBER key member返回值:1表示元素在set中,0则表示不在set中
示例:

SCARD
获取⼀个set的基数(cardinality),即set中的元素个数
语法:
SCARD key返回值:set内的元素个数
示例:

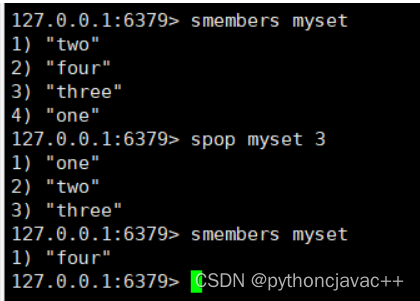
SPOP
从set中删除并返回⼀个或者多个元素。注意,由于set内的元素是⽆序的,所以取出哪个元素实际是未定义⾏为,即可以看作随机的
语法:
SPOP key [count]返回值:取出的元素
示例:
SMOVE
将⼀个元素从源set取出并放⼊⽬标set中。
语法:
SMOVE source destination member 返回值:1表示成功,0表示失败
示例:

SREM
将指定的元素从set中删除。
语法:
SREM key member [member ...] 返回值:本次操作删除的元素个数
示例:

集合的交集、并集、差集
交集(inter)、并集(union)、差集(diff)如图所示

SINTER / SUNION / DIFF
获取sinter交集,sunion并集,diff差集中的元素
语法:
SINTER key [key ...]
SUNION key [key ...]
SDIFF key [key ...]返回值:交集、并集、差集的元素
SINTERSTORE / SUNIONSTORE / DIFFSTORE
获取给定set的交集、并集、差集中的元素并保存到⽬标set中。
语法:
SINTERSTORE destination key [key ...]
SUNIONSTORE destination key [key ...]
DIFFSTORE destination key [key ...]返回值:交集、并集、差集的元素个数
内部编码
集合类型的内部编码有两种:
intset(整数集合):当集合中的元素都是整数并且元素的个数⼩于set-max-intset-entries配置
(默认512个)时,Redis会选⽤intset来作为集合的内部实现,从⽽减少内存的使⽤
hashtable(哈希表):当集合类型⽆法满⾜intset的条件时,Redis会使⽤hashtable作为集合的内部实现。
使用场景
集合类型⽐较典型的使⽤场景是标签(tag)。例如A⽤⼾对娱乐、体育板块⽐较感兴趣,B⽤⼾对历史、新闻⽐较感兴趣,这些兴趣点可以被抽象为标签。有了这些数据就可以得到喜欢同⼀个标签
的⼈,以及⽤⼾的共同喜好的标签 。例如⼀个电⼦商务⽹站会对不同标签的⽤⼾做不同的产品推荐
Zset 有序集合
有序集合相对于字符串、列表、哈希、集合来说会有⼀些陌⽣。它保留了集合不能有重复成员的
特点,但与集合不同的是,有序集合中的每个元素都有⼀个唯⼀的浮点类型的分数(score)与之关联,着使得有序集合中的元素是可以维护有序性的,但这个有序不是⽤下标作为排序依据⽽是⽤这个分数

TIPS:有序集合中的元素是不能重复的,但分数允许重复。类⽐于⼀次考试之后,每个⼈⼀定有⼀个唯⼀的分数,但分数允许相同。
常用命令
ZADD
添加或者更新指定的元素以及关联的分数到zset中,分数应该符合double类型,+inf/-inf?作为正负极限也是合法的。
ZADD的相关选项:
- XX:仅仅⽤于更新已经存在的元素,不会添加新元素
- NX:仅⽤于添加新元素,不会更新已经存在的元素
- CH:默认情况下,ZADD?返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更新的元素的个数。
- INCR:此时命令类似ZINCRBY的效果,将元素的分数加上指定的分数。此时只能指定⼀个元素和分数。
语法:
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member...]返回值:本次添加成功的元素个数。
示例:

ZCARD
获取⼀个zset的基数(cardinality),即zset中的元素个数。
语法:
ZCARD key返回值:zset内的元素个数。
示例:

ZCOUNT
返回分数在min和max之间的元素个数,默认情况下,min和max都是包含的
语法:
ZCOUNT key min max 返回值:满⾜条件的元素列表个数
示例:

ZRANGE
返回指定区间⾥的元素,分数按照升序。带上WITHSCORES可以把分数也返回
语法:
ZRANGE key start stop [WITHSCORES] 此处的[start,stop]为下标构成的区间从0开始,⽀持负数.
返回值:区间内的元素列表
示例:

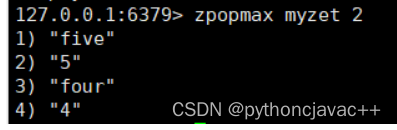
ZPOPMAX
删除并返回分数最⾼的count个元素
语法:
ZPOPMAX key [count]返回值:分数和元素列表
ZRANK
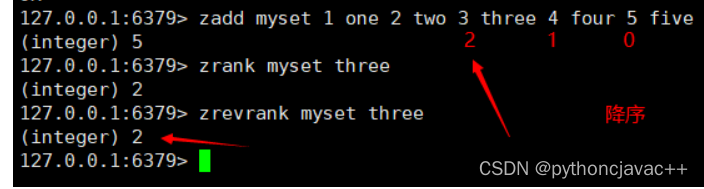
返回指定元素的排名,升序。
语法:
ZRANK key member 示例:

ZREVRANK
返回指定元素的排名,降序
语法:
ZREVRANK key member 示例:
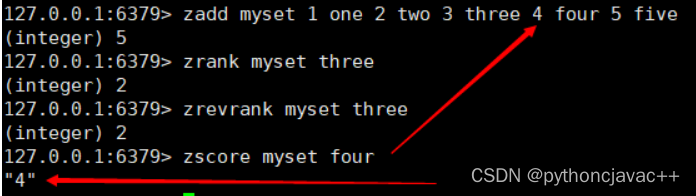
ZSCORE
返回指定元素的分数
语法:
ZSCORE key member 示例:
ZREM
删除指定的元素
语法:
ZREM key member [member ...]返回值: 本次操作删除的元素个数
示例:

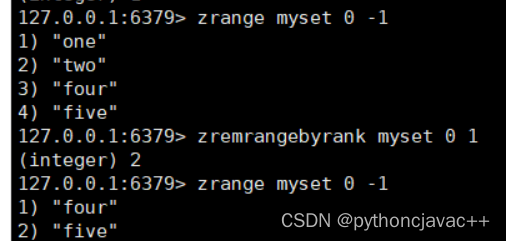
ZREMRANGEBYRANK
按照排序,升序删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYRANK key start stop 返回值:本次操作删除的元素个数。
示例:
ZREMRANGEBYSCORE
按照分数删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYSCORE key min max 返回值:本次操作删除的元素个数
示例:

ZINCRBY
为指定的元素的关联分数添加指定的分数值
语法:
ZINCRBY key increment member返回值:增加后元素的分数
示例:

使用场景
有序集合⽐较典型的使⽤场景就是排⾏榜系统。例如常⻅的⽹站上的热榜信息,榜单的维度可能是多⽅⾯的:按照时间、按照阅读量、按照点赞量。
比如点赞一篇文章,就可以使用有序集合zadd 和 zincrby功能对该文章的点赞数增加
也可以将用户文章删除zrem,以及展示前100最多赞的文章 zrank等~~
渐进式遍历
Redis使⽤scan命令进⾏渐进式遍历键,进⽽解决直接使⽤keys获取键时可能出现的阻塞问题。每次scan命令的时间复杂度是O(1),但是要完整地完成所有键的遍历,需要执⾏多次scan。
- ⾸次scan从0开始
- 当scan返回的下次位置为0时,遍历结束.
SCAN
以渐进式的方式进行键的遍历
语法:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type] 返回值: 下⼀次scan的游标(cursor)以及本次得到的键。
示例:
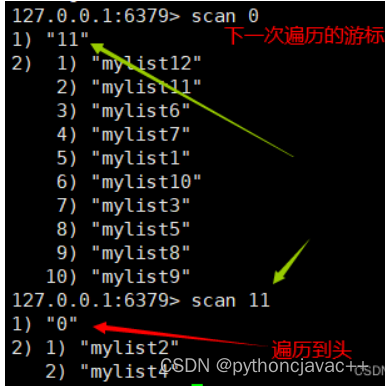
除了scan以外,Redis⾯向哈希类型、集合类型、有序集合类型分别提供了hscan、sscan、zscan命令,它们的⽤法和scan基本类似
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











