







 本文介绍了人工智能的基本概念,包括机器学习、特征工程和深度学习,并深入讲解了神经网络的训练过程、主要概念,如向量、权重、线性回归模型。通过Python实现,介绍了如何构建和训练第一个神经网络,包括使用NumPy处理输入、计算预测误差、应用链式法则和反向传播。最后讨论了训练神经网络的策略,如避免过拟合,并简要提到了添加更多层以提升网络表达能力的重要性。
本文介绍了人工智能的基本概念,包括机器学习、特征工程和深度学习,并深入讲解了神经网络的训练过程、主要概念,如向量、权重、线性回归模型。通过Python实现,介绍了如何构建和训练第一个神经网络,包括使用NumPy处理输入、计算预测误差、应用链式法则和反向传播。最后讨论了训练神经网络的策略,如避免过拟合,并简要提到了添加更多层以提升网络表达能力的重要性。
人工智能概述
从根本上讲,使用人工智能的目标是让计算机像人类一样思考。这似乎是新事物,但该领域诞生于 1950 年代。
想象一下,您需要编写一个使用 AI解决数独问题的 Python 程序。实现这一点的一种方法是编写条件语句并检查约束以查看是否可以在每个位置放置一个数字。好吧,这个 Python 脚本已经是 AI 的应用程序了,因为您编写了一台计算机来解决问题!
机器学习 (ML)和深度学习 (DL)也是解决问题的方法。这些技术与 Python 脚本之间的区别在于 ML 和 DL 使用训练数据而不是硬编码规则,但它们都可以用于使用 AI 解决问题。在接下来的部分中,您将详细了解这两种技术的区别。
学习资源汇总腾讯文档-在线PDF https://docs.qq.com/pdf/DR1doYmNBYUZ3RVNX
https://docs.qq.com/pdf/DR1doYmNBYUZ3RVNX
机器学习
机器学习是一种训练系统解决问题的技术,而不是对规则进行显式编程。回到上一节中的数独示例,要使用机器学习解决问题,您需要从已解决的数独游戏中收集数据并训练统计模型。统计模型是一种数学形式化的近似现象行为的方法。
一个常见的机器学习任务是监督学习,其中您有一个包含输入和已知输出的数据集。任务是使用此数据集来训练一个模型,该模型根据输入预测正确的输出。下图展示了使用监督学习训练模型的工作流程:
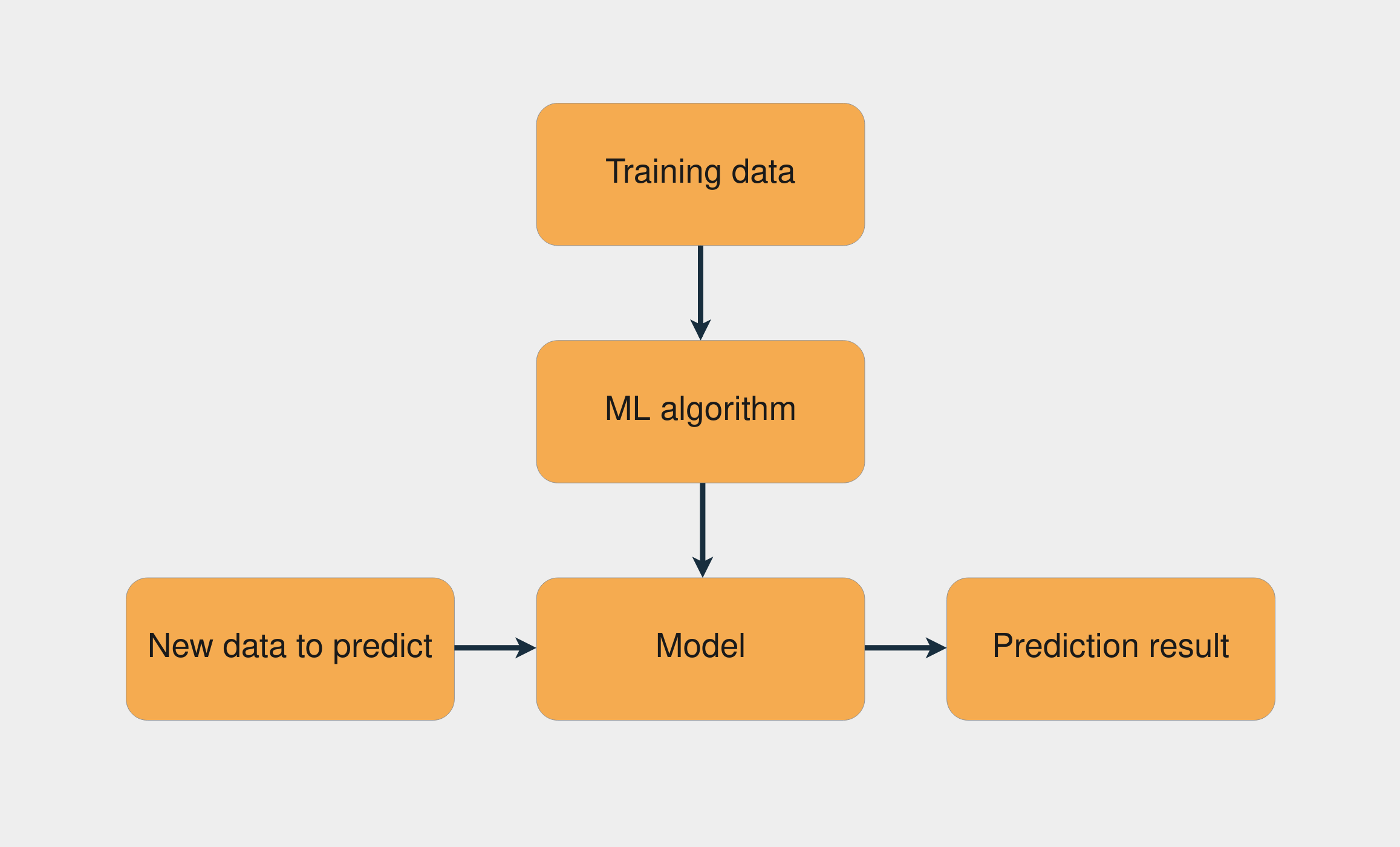
训练机器学习模型的工作流
训练数据与机器学习算法的结合创建了模型。然后,使用此模型,您可以对新数据进行预测。
注意: scikit-learn是一个流行的 Python 机器学习库,它提供了许多有监督和无监督的学习算法。要了解更多信息,请查看使用 scikit-learn 的 train_test_split() 拆分您的数据集。
监督学习任务的目标是对新的、看不见的数据进行预测。为此,您假设这些看不见的数据遵循与训练数据集分布相似的概率分布。如果将来此分布发生变化,则您需要使用新的训练数据集再次训练模型。
特征工程
当您使用不同类型的数据作为输入时,预测问题变得更加困难。数独问题相对简单,因为您直接处理数字。如果你想训练一个模型来预测句子中的情绪怎么办?或者,如果您有一个图像,并且想知道它是否描绘了一只猫,该怎么办?
输入数据的另一个名称是特征,特征工程是从原始数据中提取特征的过程。在处理不同类型的数据时,您需要找出表示这些数据的方法,以便从中提取有意义的信息。
特征工程技术的一个例子是词形还原,您可以在其中删除句子中单词的屈折变化。例如,动词“watch”的屈折形式,如“watches”、“watching”和“watched”,将被简化为它们的引理或基本形式:“watch”。
如果您使用数组来存储语料库的每个单词,那么通过应用词形还原,您最终会得到一个不太稀疏的矩阵。这可以提高某些机器学习算法的性能。下图展示了使用词袋模型进行词形还原和表示的过程:

使用词袋模型创建特征
首先,每个词的屈折形式都归结为它的引理。然后,计算该词的出现次数。结果是一个包含文本中每个单词出现次数的数组。
深度学习
深度学习是一种让神经网络自行确定哪些特征重要的技术,而不是应用特征工程技术。这意味着,通过深度学习,您可以绕过特征工程过程。
不必处理特征工程是件好事,因为随着数据集变得越来越复杂,这个过程变得越来越困难。例如,你将如何提取数据来预测一个人的情绪,给她一张脸的照片?使用神经网络,您无需担心,因为网络可以自行学习特征。在接下来的部分中,您将深入研究神经网络,以更好地了解它们的工作原理。
神经网络:主要概念
神经网络是一个通过以下步骤学习如何进行预测的系统:
- 获取输入数据
- 做出预测
- 将预测与所需输出进行比较
- 调整其内部状态以正确预测下一次
向量、层和线性回归是神经网络的一些构建块。数据存储为向量,使用 Python 可以将这些向量存储在数组中。每一层都会转换来自前一层的数据。您可以将每一层视为特征工程步骤,因为每一层都提取了先前数据的一些表示。
神经网络层的一个很酷的事情是相同的计算可以从任何类型的数据中提取信息。这意味着您使用的是图像数据还是文本数据并不重要。两种情况下,提取有意义信息和训练深度学习模型的过程是相同的。
在下图中,您可以看到一个具有两层的网络架构示例:

一个两层的神经网络
每一层都通过应用一些数学运算来转换来自前一层的数据。
训练神经网络的过程
训练神经网络类似于反复试验的过程。想象一下,您是第一次玩飞镖。在您的第一次投掷中,您尝试击中飞镖板的中心点。通常,第一次拍摄只是为了了解手的高度和速度如何影响结果。如果你看到飞镖高于中心点,那么你调整你的手把它扔得低一点,依此类推。
这些是尝试击中飞镖板中心的步骤:
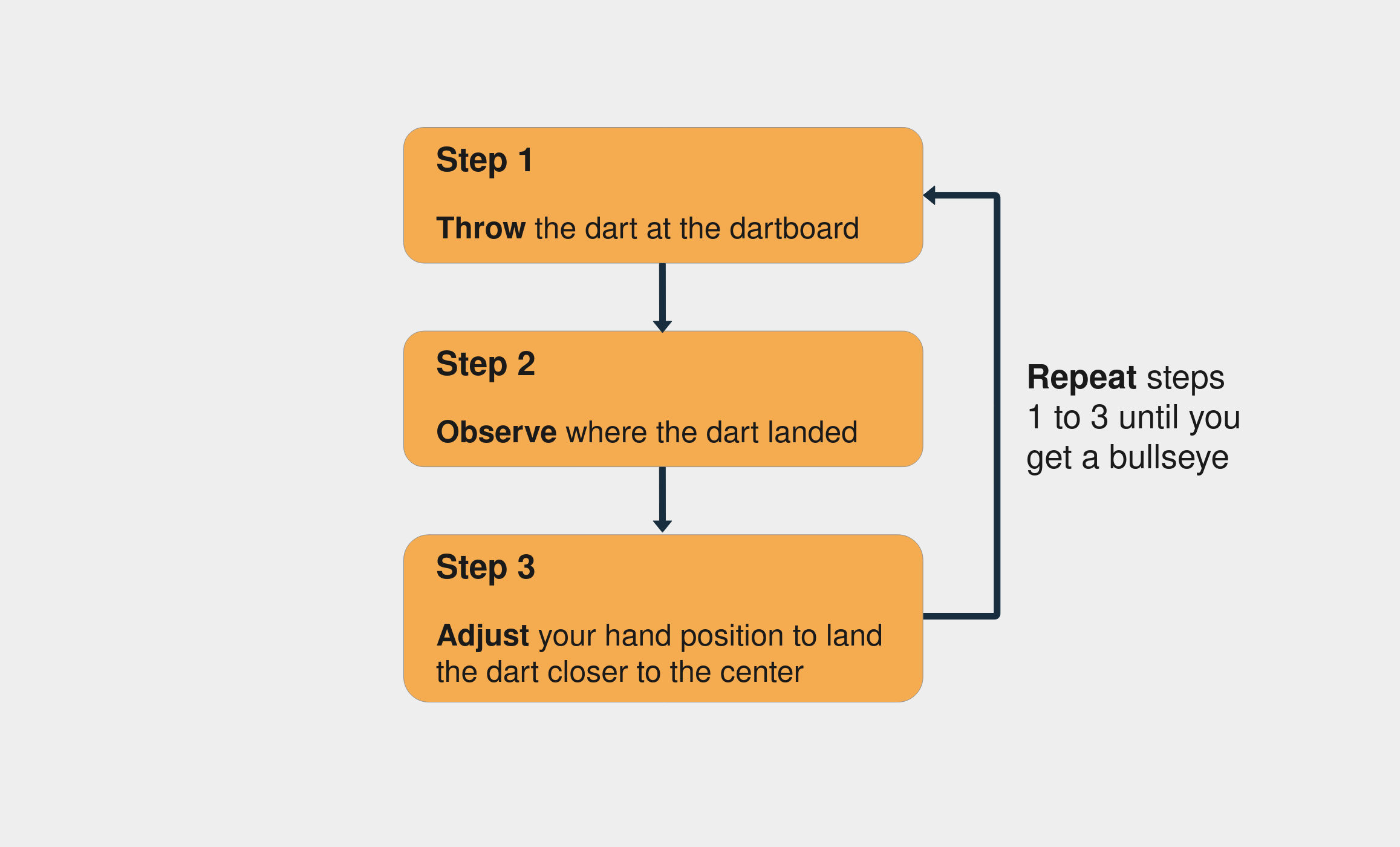
击中飞镖板中心的步骤
请注意,您通过观察飞镖落下的位置来不断评估错误(第 2 步)。你继续前进,直到你最终击中飞镖板的中心。
对于神经网络,该过程非常相似:您从一些随机权重和偏置向量开始,进行预测,将其与所需的输出进行比较,然后调整向量以在下次更准确地预测。该过程一直持续到预测和正确目标之间的差异最小。
知道何时停止训练以及设置什么样的准确率目标是训练神经网络的一个重要方面,主要是因为过拟合和欠拟合的情况。
向量和权重
使用神经网络包括对向量进行操作。您将向量表示为多维数组。向量在深度学习中很有用,主要是因为一种特殊的操作:点积。两个向量的点积告诉您它们在方向上的相似程度,并按两个向量的大小进行缩放。
神经网络中的主要向量是权重和偏置向量。松散地说,您希望神经网络做的是检查输入是否与它已经看到的其他输入相似。如果新输入与之前看到的输入相似,那么输出也将相似。这就是您获得预测结果的方式。
线性回归模型
当您需要估计一个因变量与两个或多个自变量之间的关系时使用回归。线性回归是一种将变量之间的关系近似为线性的方法。该方法可以追溯到十九世纪,是最流行的回归方法。
注意:甲线性关系是其中有一个自变量和因变量之间的直接关系。
通过将变量之间的关系建模为线性关系,您可以将因变量表示为自变量的加权和。因此,每个自变量将乘以一个名为 的向量weight。除了权重和自变量之外,您还添加了另一个向量:偏差。当所有其他自变量都为零时,它会设置结果。
作为如何构建线性回归模型的真实示例,假设您想要训练一个模型来根据面积和房屋的年龄来预测房屋的价格。您决定使用线性回归对这种关系进行建模。以下代码块显示了如何用伪代码为所述问题编写线性回归模型:
price = (weights_area * area) + (weights_age * age) + bias
在上面的例子中,有两个权重:weights_area和weights_age。训练过程包括调整权重和偏差,以便模型可以预测正确的价格值。为此,您需要计算预测误差并相应地更新权重。
这些是神经网络机制如何工作的基础知识。现在是时候看看如何使用 Python 应用这些概念了。
Python AI:开始构建你的第一个神经网络
构建神经网络的第一步是从输入数据生成输出。您将通过创建变量的加权总和来做到这一点。您需要做的第一件事是用 Python 和NumPy表示输入。
用 NumPy 包装神经网络的输入
您将使用 NumPy 将网络的输入向量表示为数组。但是在使用 NumPy 之前,最好先在纯 Python 中使用向量来更好地理解发生了什么。
在第一个示例中,您有一个输入向量和其他两个权重向量。目标是找到哪个权重与输入更相似,同时考虑方向和大小。如果您绘制它们,这就是向量的外观:

笛卡尔坐标平面中的三个向量
weights_2更类似于输入向量,因为它指向相同的方向并且幅度也相似。那么如何使用 Python 找出哪些向量相似呢?
首先,您定义三个向量,一个用于输入,另外两个用于权重。然后计算input_vector和weights_1的相似程度。为此,您将应用点积。由于所有向量都是二维向量,因此以下是执行此操作的步骤:
- 将 的第一个索引乘以 的第
input_vector一个索引weights_1。 - 将 的第二个索引乘以 的第二
input_vector个索引weights_2。 - 将两个乘法的结果相加。
您可以使用 IPython 控制台或Jupyter Notebook进行操作。每次开始一个新的 Python 项目时都创建一个新的虚拟环境是一个很好的做法,所以你应该先这样做。venv附带 Python 3.3 及更高版本,它对于创建虚拟环境非常方便:
$ python -m venv ~/.my-env
$ source ~/.my-env/bin/activate
使用上述命令,您首先创建虚拟环境,然后激活它。现在是使用pip. 由于您还需要 NumPy 和Matplotlib,因此最好也安装它们:
(my-env) $ python -m pip install ipython numpy matplotlib
(my-env) $ ipython
现在您已准备好开始编码。这是计算的点积代码input_vector和weights_1:
In [1]: input_vector = [1.72, 1.23]
In [2]: weights_1 = [1.26, 0]
In [3]: weights_2 = [2.17, 0.32]
In [4]: # Computing the dot product of input_vector and weights_1
In [5]: first_indexes_mult = input_vector[0] * weights_1[0]
In [6]: second_indexes_mult = input_vector[1] * weights_1[1]
In [7]: dot_product_1 = first_indexes_mult + second_indexes_mult
In [8]: print(f"The dot product is: {
dot_product_1}")
Out[8]: The dot product is: 2.1672
点积的结果是2.1672。现在您知道如何计算点积,是时候使用np.dot()NumPy 了。以下是如何dot_product_1使用计算np.dot():
In [9]: import numpy as np
In [10]: dot_product_1 = np.dot(input_vector, weights_1)
In [11]: print(f"The dot product is: {
dot_product_1}")
Out[11]: The dot product is: 2.1672
np.dot()做你之前做的同样的事情,但现在你只
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









