






Llama 2正式官宣免费用,赶快上手微调一个自己的羊驼吧。
今天,Llama 2宣布正式开源,免费用于研究和商用。

下载地址:https://ai.meta.com/resources/models-and-libraries/llama-downloads/?utm_source=twitter&utm_medium=organic_social&utm_campaign=llama2&utm_content=card
发布不到一周的Llama 2,已经在研究社区爆火,一系列性能评测、在线试用的demo纷纷出炉。
就连OpenAI联合创始人Karpathy用C语言实现了对Llama 2婴儿模型的推理。
既然Llama 2现已人人可用,那么如何去微调实现更多可能的应用呢?
Llama 2微调指南
这两天,来自Brev的创始工程师Sam L’Huillier,就做了一个简易版的Llama 2微调指南。
甚至还一度冲进了Hacker News榜单的前五。
为了制作这个「对话摘要生成器」,作者利用samsum对话摘要数据集对Llama 2进行了微调。
记得准备一个A10、A10G、A100(或其他显存大于24GB的GPU)。如果没有的话,也可以选择线上的开发环境。
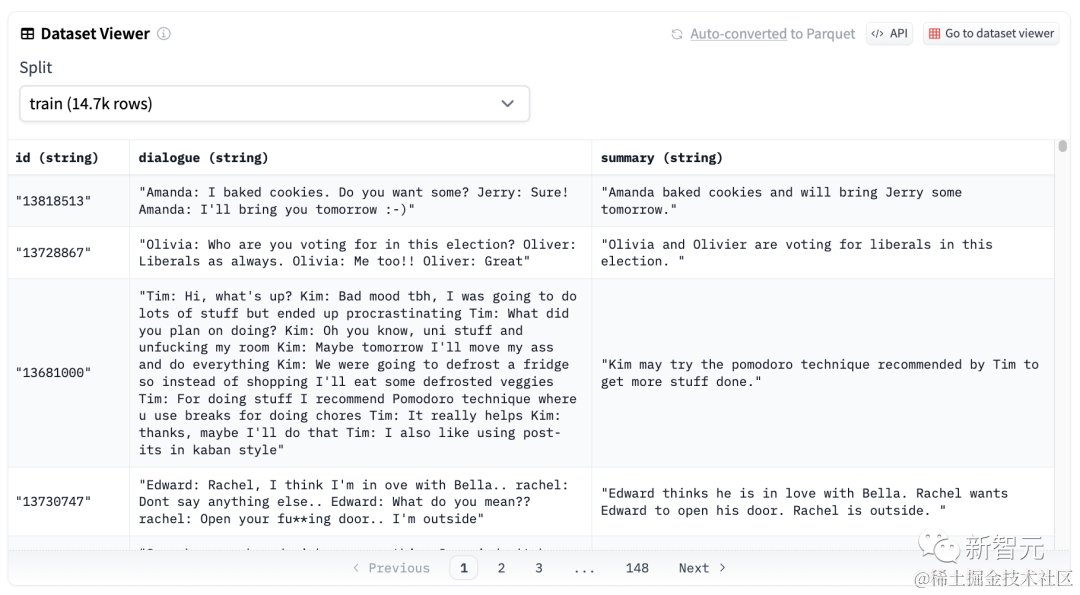
数据集地址:https://huggingface.co/datasets/samsum
- 下载模型
克隆Meta的Llama推理存储库(包含下载脚本):
代码语言:javascript
git clone https://github.com/facebookresearch/llama.git
然后运行下载脚本:
代码语言:javascript
bash download.sh
在这里,你只需要下载7B模型就可以了。
- 将模型转换为Hugging Face支持的格式
代码语言:javascript
pip install git+https://github.com/huggingface/transformerscd transformerspython convert_llama_weights_to_hf.py \ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir models_hf/7B
现在,我们得到了一个Hugging Face模型,可以利用Hugging Face库进行微调了!
- 运行微调笔记本:
克隆Llama-recipies存储库:
代码语言:javascript
git clone https://github.com/facebookresearch/llama-recipes.git
然后,在你喜欢的notebook界面中打开quickstart.ipynb文件,并运行整个notebook。
(此处,作者使用的是Jupyter lab):
代码语言:javascript
pip install
jupyterlabjupyter lab # in the repo you want to work in
为了适应转换后的实际模型路径,确保将以下一行更改为:
代码语言:javascript
model_id="./models_hf/7B"
最后,一个经过Lora微调的模型就完成了。
- 在微调的模型上进行推理
当前,问题在于Hugging Face只保存了适配器权重,而不是完整的模型。所以我们需要将适配器权重加载到完整的模型中。
导入库:
代码语言:javascript
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
from peft import PeftModel, PeftConfig
加载分词器和模型:
代码语言:javascript
model_id="./models_hf/7B"
tokenizer = LlamaTokenizer.from_pretrained(model_id)
model =LlamaForCausalLM.from_pretrained(model_id, load_in_8bit=True, device_map='auto', torch_dtype=torch.float16)
从训练后保存的位置加载适配器:
代码语言:javascript
model = PeftModel.from_pretrained(model, "/root/llama-recipes/samsungsumarizercheckpoint")
运行推理:
代码语言:javascript
eval_prompt = """
Summarize this dialog:
A: Hi Tom, are you busy tomorrow’s afternoon?
B: I’m pretty sure I am. What’s up?
A: Can you go with me to the animal shelter?.
B: What do you want to do?
A: I want to get a puppy for my son.
B: That will make him so happy.
A: Yeah, we’ve discussed it many times. I think he’s ready now.
B: That’s good. Raising a dog is a tough issue. Like having a baby ;-)
A: I'll get him one of those little dogs.
B: One that won't grow up too big;-)A: And eat too much;-))
B: Do you know which one he would like?
A: Oh, yes, I took him there last Monday. He showed me one that he really liked.
B: I bet you had to drag him away.
A: He wanted to take it home right away ;-).
B: I wonder what he'll name it.
A: He said he’d name it after his dead hamster – Lemmy - he's a great Motorhead fan :-)))
---
Summary:
"""
model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda")
model.eval()
with torch.no_grad():
print(tokenizer.decode(model.generate(**model_input, max_new_tokens=100)[0], skip_special_tokens=True))
LLM Engine微调更便捷
如果你想用自己的数据对Llama 2微调,该如何做?
创办Scale AI初创公司的华人CEO Alexandr Wang表示,自家公司开源的LLM Engine,能够用最简单方法微调Llama 2。

Scale AI的团队在一篇博文中,具体介绍了Llama 2的微调方法。
代码语言:javascript
from llmengine import FineTune
response = FineTune.create(
model="llama-2-7b",
training_file="s3://my-bucket/path/to/training-file.csv",
)
print(response.json())
数据集
在如下示例中,Scale使用了Science QA数据集。
这是一个由多项选择题组成的流行数据集,每个问题可能有文本上下文和图像上下文,并包含支持解决方案的详尽解释和讲解。
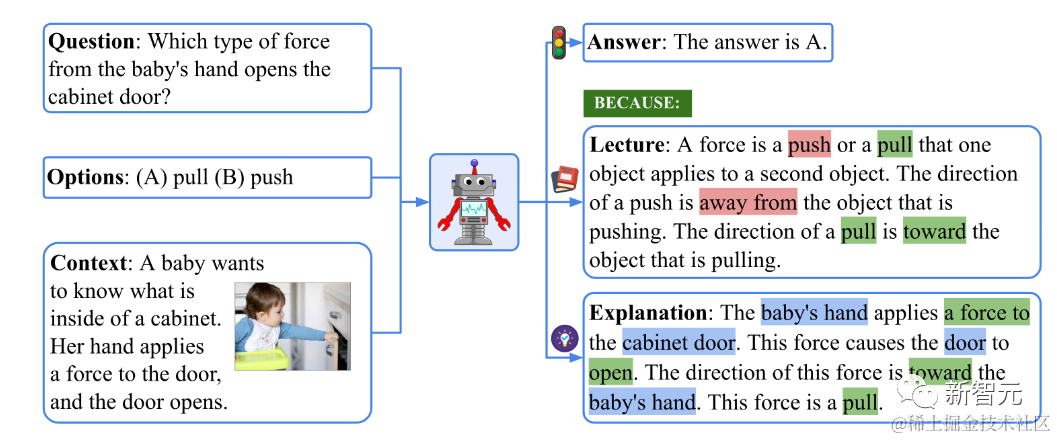
Science QA的示例
目前,LLM Engine支持对「提示完成对」进行微调。首先,需要将Science QA数据集转换为支持的格式,一个包含两列的CSV:prompt和response 。
在开始之前,请安装所需的依赖项。
代码语言:javascript
pip install datasets==2.13.1 smart_open[s3]==5.2.1 pandas==1.4.4
可以从Hugging Face加载数据集,并观察数据集的特征。
代码语言:javascript
from datasets import load_dataset
from smart_open import smart_open
import pandas as pd
dataset = load_dataset('derek-thomas/ScienceQA')
dataset['train'].features
提供Science QA示例的常用格式是:
代码语言:javascript
Context: A baby wants to know what is inside of a cabinet. Her hand applies a force to the door, and the door opens.
Question: Which type of force from the baby's hand opens the cabinet door?
Options: (A) pull (B) push
Answer: A.
由于Hugging Face数据集中options的格式是「可能答案的列表」,需要通过添加枚举前缀,将此列表转换为上面的示例格式。
代码语言:javascript
choice_prefixes = [chr(ord('A') + i) for i in range(26)] # A-Z
def format_options(options, choice_prefixes):
return ' '.join([f'({c}) {o}' for c, o in zip(choice_prefixes, options)])
代码语言:javascript
现在,编写格式化函数,将这个数据集中的单个样本转换为输入模型的prompt和response 。
代码语言:javascript
def format_prompt(r, choice_prefixes):
options = format_options(r['choices'], choice_prefixes)
return f'''Context: {r["hint"]}\nQuestion: {r["question"]}\nOptions:{options}\nAnswer:'''
def format_response(r, choice_prefixes):
return choice_prefixes[r['answer']]
最后,构建数据集。
请注意,Science QA中的某些示例只有上下文图像。(如下演示中会跳过这些示例,因为Llama-2纯粹是一种语言模型,并且不能接受图像输入。)
代码语言:javascript
def convert_dataset(ds):
prompts = [format_prompt(i, choice_prefixes) for i in ds if i['hint'] != '']
labels = [format_response(i, choice_prefixes) for i in ds if i['hint'] != '']
df = pd.DataFrame.from_dict({'prompt': prompts, 'response': labels})
return df
LLM Engine支持使用「预训练和验证数据集」来进行训练。假如你只提供训练集,LLM Engine会从数据集中随机拆分10%内容进行验证。
因为拆分数据集可以防止模型过度拟合训练数据,不会导致在推理期间实时数据泛化效果不佳。
另外,这些数据集文件必须存储在可公开访问的URL中,以便LLM Engine可以读取。对于此示例,Scale将数据集保存到s3。
并且,还在Github Gist中公开了预处理训练数据集和验证数据集。你可以直接用这些链接替换train_url和val_url 。
代码语言:javascript
train_url = 's3://...'
val_url = 's3://...'
df_train = convert_dataset(dataset['train'])
with smart_open(train_url, 'wb') as f:
df_train.to_csv(f)
df_val = convert_dataset(dataset['validation'])
with smart_open(val_url, 'wb') as f:
df_val.to_csv(f)
现在,可以通过LLM Engine API开始微调。
微调
首先,需要安装LLM Engine。
代码语言:javascript
pip install scale-llm-engine
接下来,你需要设置Scale API密钥。按照README的说明获你唯一的API密钥。
高级用户还可以按照自托管LLM Engine指南进行操作,由此就不需要Scale API密钥。
代码语言:javascript
import os
os.environ['SCALE_API_KEY'] = 'xxx'
一旦你设置好一切,微调模型只需要一个API的调用。
在此,Scale选择了Llama-2的70亿参数版本,因为它对大多数用例来说已经足够强大了。
代码语言:javascript
from llmengine import FineTune
response = FineTune.create(
model="llama-2-7b",
training_file=train_url,
validation_file=val_url,
hyperparameters={
'lr':2e-4,
},
suffix='science-qa-llama'
)
run_id = response.fine_tune_id
通过run_id ,你可以监控工作状态,并获取每个epoch的实时更新指标,比如训练和验证损失。
Science QA是一个大型数据集,因此训练可能需要一两个小时才能完成。
代码语言:javascript
while True:
job_status = FineTune.get(run_id).status
# Returns one of `PENDING`, `STARTED`, `SUCCESS`, `RUNNING`,
# `FAILURE`, `CANCELLED`, `UNDEFINED` or `TIMEOUT`
print(job_status)
if job_status == 'SUCCESS':
break
time.sleep(60)
#Logs for completed or running jobs can be fetched with
logs = FineTune.get_events(run_id)
推理与评估
完成微调后,你可以开始对任何输入生成响应。但是,在此之前,确保模型存在,并准备好接受输入。
代码语言:javascript
ft_model = FineTune.get(run_id).fine_tuned_model
不过,你的第一个推理结果可能需要几分钟才能输出。之后,推理过程就会加快。
一起评估下在Science QA上微调的Llama-2模型的性能。
代码语言:javascript
import pandas as pd
#Helper a function to get outputs for fine-tuned model with retries
def get_output(prompt: str, num_retry: int = 5):
for _ in range(num_retry):
try:
response = Completion.create(
model=ft_model,
prompt=prompt,
max_new_tokens=1,
temperature=0.01
)
return response.output.text.strip()
except Exception as e:
print(e)
return ""
#Read the test data
test = pd.read_csv(val_url)
test["prediction"] = test["prompt"].apply(get_output)
print(f"Accuracy: {(test['response'] == test['prediction']).mean() * 100:.2f}%")
微调后的Llama-2能够达到82.15%的准确率,已经相当不错了。
那么,这个结果与Llama-2基础模型相比如何?
由于预训练模型没有在这些数据集上进行微调,因此需要在提示中提供一个示例,以便模型学会遵从我们期望的回复格式。
另外,我们还可以看到与微调类似大小的模型MPT-7B相比的情况。
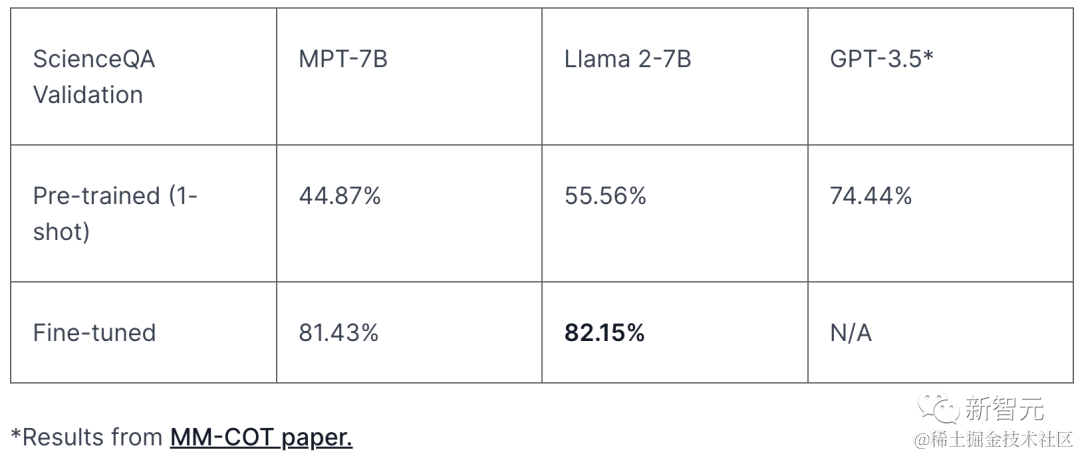
在Science QA上微调Llama-2,其性能增益有26.59%的绝对差异!
此外,由于提示长度较短,使用微调模型进行推理比使用少样本提示更便宜。这种微调Llama-27B模型也优于1750亿参数模型GPT-3.5。
可以看到,Llama-2模型在微调和少样本提示设置中表现都优于MPT,充分展示了它作为基础模型和可微调模型的优势。
此外,Scale还使用LLM Engine微调和评估LLAMA-2在GLUE(一组常用的NLP基准数据集)的几个任务上的性能。
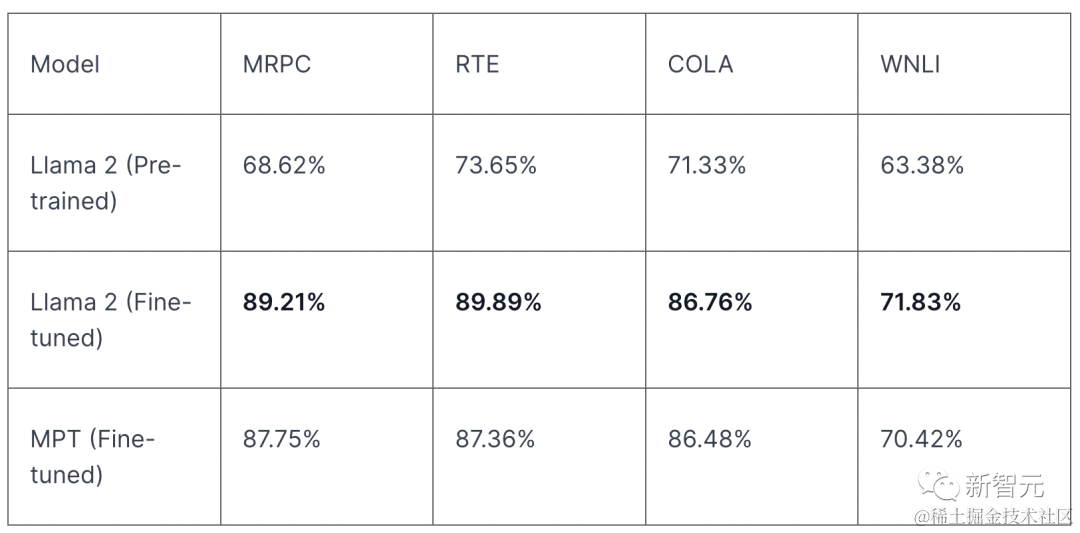
现在,任何人都可以释放微调模型的真正潜力,并见证强大的AI生成回复的魔力。
我发现虽然Huggingface在transformers方面构建了一个出色的库,但他们的指南对于普通用户来说往往过于复杂。
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









