






你正在阅读的是 大模型炼丹术 系列文章中的第五篇。
在前面的4篇文章中,我们已经完成了整个数据流向所需的模块构建,包括tokenizer,embedding,注意力机制,并串联得到了GPT2这个LLM架构。
现在,是时候准备开始训练我们的LLM了。相比于前面发布的4篇文章,本文将更加偏重于代码实战。
一、准备自回归预训练数据集
在开始编写训练脚本之前,我们需要先构建训练所需数据集。这里使用the-verdict.txt,这是在本系列一开始就作为示例使用的一本书。
import os
import urllib.request
file_path = "the-verdict.txt"
url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt"
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode('utf-8')
with open(file_path, "w", encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
现在有了原始数据,还需要用tokenizer进一步编码成token ID序列的形式。先把我们之前定义好的tokenizer搬过来:
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
total_characters = len(text_data)
total_tokens = len(tokenizer.encode(text_data))
print("Characters:", total_characters)# 20479
print("Tokens:", total_tokens)# 5145
可以看到,这本书很小,总共包含20479个字符,使用BPE进行编码后,总共得到5145个token。
定义基本的编码解码函数:
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0) # remove batch dimension
return tokenizer.decode(flat.tolist())
同样,我们在之前已经定义好了数据加载器,这里也直接搬过来:
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# Tokenize the entire text
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
# 这里的max_length就是上面所讲的滑动窗口的大小context_size
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader_v1(txt, batch_size=4, max_length=4,
stride=128, shuffle=True, drop_last=True,
num_workers=0):
# Initialize the tokenizer
tokenizer = tiktoken.get_encoding("gpt2")
# Create dataset
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
# Create dataloader
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader
配置文件粘过来:
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 256, # Shortened context length (orig: 1024)
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-key-value bias
}
调用数据加载器来定义训练/验证loader:
# Train/validation ratio
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],# 不设置重叠token区域
drop_last=True,
shuffle=True,
num_workers=0
)
val_loader = create_dataloader_v1(
val_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],# 不设置重叠token区域
drop_last=False,
shuffle=False,
num_workers=0
)
确保训练/验证集中至少包含一个样本(长度为context_size):
# Sanity check
if total_tokens * (train_ratio) < GPT_CONFIG_124M["context_length"]:
print("Not enough tokens for the training loader. "
"Try to lower the `GPT_CONFIG_124M['context_length']` or "
"increase the `training_ratio`")
if total_tokens * (1-train_ratio) < GPT_CONFIG_124M["context_length"]:
print("Not enough tokens for the validation loader. "
"Try to lower the `GPT_CONFIG_124M['context_length']` or "
"decrease the `training_ratio`")
查看数据集:
print("Train loader:")
for x, y in train_loader:
print(x.shape, y.shape)
print("\nValidation loader:")
for x, y in val_loader:
print(x.shape, y.shape)
print(len(train_loader))
print(len(val_loader))
输出:
Train loader:
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
Validation loader:
torch.Size([2, 256]) torch.Size([2, 256])
9
1
由此可知,在batch_size设置为2,context_length设置为256时,总共得到10个样本,这是一个相当小的数据集。
二、准备模型架构与损失函数
直接把我们在上一篇文章中定义的GPT2架构搬过来:
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
model = GPTModel(GPT_CONFIG_124M)
model.eval(); # Disable dropout during inference
使用交叉熵作为损失函数:
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
logits = model(input_batch)
print(logits.shape,target_batch.shape)# torch.Size([2, 256, 50257]) torch.Size([2, 256])
loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches isNone:
num_batches = len(data_loader)
else:
# Reduce the number of batches to match the total number of batches in the data loader
# if num_batches exceeds the number of batches in the data loader
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batches
在开始训练之前,可以先查看一下整体的训练和验证集的loss:
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print(f"Using {device} device.")
model.to(device) # 对于 nn.Module 类的对象来说,model.to(device) 会直接修改原始的 model 对象,使其移动到指定的设备,而这个操作是就地修改的,不需要重新赋值给 model。
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)
print("Training loss:", train_loss)# Training loss: 10.988969696892632
print("Validation loss:", val_loss)# Validation loss: 10.964568138122559
三、编写LLM自回归预训练循环
这部分代码也遵循PyTorch深度学习中的经典训练循环形式,代码非常简单,这里不再细说。
def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
for epoch in range(num_epochs):
model.train()
for input_batch, target_batch in train_loader:
optimizer.zero_grad()
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward()
optimizer.step()
tokens_seen += input_batch.numel() # Returns the total number of elements (or tokens) in the input_batch.
global_step += 1
# Optional evaluation step
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
# Print a sample text after each epoch
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
def generate_and_print_sample(model, tokenizer, device, start_context):
model.eval()
context_size = model.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_context, tokenizer).to(device)
with torch.no_grad():
token_ids = generate_text_simple(
model=model, idx=encoded,
max_new_tokens=50, context_size=context_size
)
decoded_text = token_ids_to_text(token_ids, tokenizer)
print(decoded_text.replace("\n", " ")) # Compact print format
model.train()
def generate_text_simple(model, idx, max_new_tokens, context_size):
# idx 是 (batch, n_tokens) 形状的张量,表示当前上下文中的 Token 索引
for _ in range(max_new_tokens):
# 如果当前上下文长度超过模型支持的最大长度,则进行截断
# 例如,如果 LLM 只能支持 5 个 Token,而当前上下文长度是 10
# 那么只保留最后 5 个 Token 作为输入
idx_cond = idx[:, -context_size:]
# 获取模型的预测结果
with torch.no_grad(): # 关闭梯度计算,加速推理
logits = model(idx_cond) # (batch, n_tokens, vocab_size)
# 只关注最后一个时间步的预测结果
# (batch, n_tokens, vocab_size) 变为 (batch, vocab_size)
logits = logits[:, -1, :]
# 通过 Softmax 计算概率分布,后续文章将介绍其他方式
probas = torch.softmax(logits, dim=-1) # (batch, vocab_size)
# 选择概率最高的 Token 作为下一个 Token
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # (batch, 1)
# 将新生成的 Token 追加到序列中
idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)
return idx # 返回完整的 Token 序列
现在使用定义好的训练循环函数开始执行训练:
model = GPTModel(GPT_CONFIG_124M)
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)
num_epochs = 10
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context="Every effort moves you", tokenizer=tokenizer
)
训练日志如下:
Ep 1 (Step 000000): Train loss 9.817, Val loss 9.924
Ep 1 (Step 000005): Train loss 8.066, Val loss 8.332
Every effort moves you,,,,,,,,,,,,.
Ep 2 (Step 000010): Train loss 6.619, Val loss 7.042
Ep 2 (Step 000015): Train loss 6.046, Val loss 6.596
Every effort moves you, and,, and, and,,,,, and, and,,,,,,,,,,, and,, the,, the, and,, and,,, the, and,,,,,,
Ep 3 (Step 000020): Train loss 5.524, Val loss 6.508
Ep 3 (Step 000025): Train loss 5.369, Val loss 6.378
Every effort moves you, and to the of the of the picture. Gis.
Ep 4 (Step 000030): Train loss 4.830, Val loss 6.263
Ep 4 (Step 000035): Train loss 4.586, Val loss 6.285
Every effort moves you of the "I the picture. "I"I the picture"I had the picture"I the picture and I had been the picture of
Ep 5 (Step 000040): Train loss 3.879, Val loss 6.130
Every effort moves you know he had been his pictures, and I felt it's by his last word. "Oh, and he had been the end, and he had been
Ep 6 (Step 000045): Train loss 3.530, Val loss 6.183
Ep 6 (Step 000050): Train loss 2.960, Val loss 6.123
Every effort moves you know it was his pictures--I glanced after him, I had the last word. "Oh, and I was his pictures--I looked. "I looked. "I looked.
Ep 7 (Step 000055): Train loss 2.832, Val loss 6.150
Ep 7 (Step 000060): Train loss 2.104, Val loss 6.133
Every effort moves you know the picture to me--I glanced after him, and Mrs. "I was no great, the fact, the fact that, the moment--as Jack himself, as his pictures--as of the picture--because he was a little
Ep 8 (Step 000065): Train loss 1.691, Val loss 6.186
Ep 8 (Step 000070): Train loss 1.391, Val loss 6.230
Every effort moves you?" "Yes--quite insensible to the fact with a little: "Yes--and by me to me to have to see a smile behind his close grayish beard--as if he had the donkey. "There were days when I
Ep 9 (Step 000075): Train loss 1.059, Val loss 6.251
Ep 9 (Step 000080): Train loss 0.800, Val loss 6.278
Every effort moves you?" "Yes--quite insensible to the fact with a laugh: "Yes--and by me!" He laughed again, and threw back the window-curtains, I saw that, and down the room, and now
Ep 10 (Step 000085): Train loss 0.569, Val loss 6.373
Every effort moves you?" "Yes--quite insensible to the irony. She wanted him vindicated--and by me!" He laughed again, and threw back his head to look up at the sketch of the donkey. "There were days when I
我们给定的start_context是Every effort moves you
在最开始,模型只会输出Every effort moves you,,,,,,,,,,,,.
而到了最后一个epoch,模型输出了语法基本正确的句子:Every effort moves you?" "Yes--quite insensible to the irony. She wanted him vindicated--and by me!" He laughed again, and threw back his head to look up at the sketch of the donkey. "There were days when I
你可能会疑惑,预设的max_tokens不是50吗,这两次的测试输入都是Every effort moves,可是为什么输出的句子长度却不一样呢?
因为max_tokens=50指的是生成的token数量上限,而不是句子的字数或单词数。一个token可能是:
-
一个单词(例如 "donkey")
-
一个子词(例如 "sketch" 可能被拆分为 ["sk", "etch"])
-
一个标点符号(例如 ","、"." 可能单独算作 token)
随着训练的进行,模型的语言能力增强:
-
早期:模型可能随机输出大量逗号、"and" 等低信息量的 token,使得句子看起来短而混乱。
-
后期:模型学会了输出完整的单词、短语和句子,因此即使 max_tokens限制为50,生成的文本可能更连贯、信息密度更高,看起来更长。
最后来看一下loss:
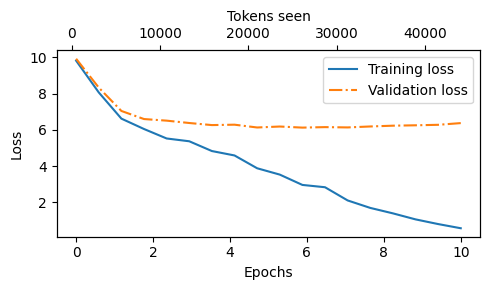
可以看到,整体的训练loss是下降的,但存在过拟合(验证集loss后期上升),这是因为我们所使用的数据集比较小,仅仅用于演示。
到这里,我们完成了LLM的预训练。模型已经掌握了基本的语言模式,但如何让它更好地生成高质量文本,还需要合理的解码策略。
在下一篇文章中,我们将深入探讨LLM的一些解码策略,并对这些策略的优缺点进行详细分析。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









