






在使用训练好的LLM进行自回归预测下一个token时,我们会选择预测序列中最后一个token对应的预测tensor,作为解码操作的对象。
# 获取模型的预测结果
with torch.no_grad(): # 关闭梯度计算,加速推理
logits = model(idx_cond) # (batch, n_tokens, vocab_size)
# 只关注最后一个时间步的预测结果
# (batch, n_tokens, vocab_size) 变为 (batch, vocab_size)
logit = logits[:, -1, :]
此时的logit就是用于解码的tensor,batch中的每一个item都对应词汇表长度大小vocab_size的一个向量。
如何对该向量进行解码,得到要预测的下一个单词呢?本文介绍几种不同的解码策略。
一、贪心解码
我们之前的解码策略是直接给logit应用softmax函数,然后使用argmax取概率值最大的数值对应的索引作为预测的下一个token ID,最后根据token ID在词汇表中查找得到预测的下一个单词:
next_token = torch.argmax(logit, dim=-1) # 选择最大值对应的索引
这其实就是贪心解码策略,这种方式确定性强,计算高效,但容易陷入重复模式,生成文本单调,因为模型总是选择概率值最大的。
二、温度缩放+采样
这种解码策略分为两步:首先用温度系数来控制生成的随机性,然后进行概率采样。
-
第一步、温度缩放:将logit除以一个温度系数,得到缩放后的logit,然后应用softmax将其归一化成概率分布
- 第二步、概率采样:使用
torch.multinomial采样得到预测token。其内部原理如下: 1)计算累积概率分布,比如对于probs=[0.1, 0.3, 0.4, 0.2],累积概率分布为:CDF=[0.1, 0.4, 0.8, 1.0], 这意味着:
2)生成一个(0,1]之间的随机数(如果num_samples=1,生成1个随机数),比如rand=0.35 3)rand = 0.35落在 CDF=[0.1, 0.4, 0.8, 1.0] 的 索引 1 处,所以最终返回的采样索引是1。采样值落在 [0.0, 0.1] → 选 索引 0 采样值落在 (0.1, 0.4] → 选 索引 1 采样值落在 (0.4, 0.8] → 选 索引 2 采样值落在 (0.8, 1.0] → 选 索引 3
代码实现如下:
import torch.nn.functional as F
temperature = 0.8 # 设置温度
scaled_logits = logit / temperature # 进行温度缩放
probs = F.softmax(scaled_logits, dim=-1) # 归一化成概率分布
next_token = torch.multinomial(probs, num_samples=1) # 按概率采样,返回的是索引
现在,让我们用一个例子来直观感受一下这种解码策略。
假设使用tokenizer得到的词汇表vocab长度为9,如下:
vocab = {
"closer": 0,
"every": 1,
"effort": 2,
"forward": 3,
"inches": 4,
"moves": 5,
"pizza": 6,
"toward": 7,
"you": 8,
}
inverse_vocab = {v: k for k, v in vocab.items()}
假设模型已经预测的下一个token的logit如下:
next_token_logits = torch.tensor(
[4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]
)
使用不同的温度缩放系数对logit进行缩放,并进行可视化展示:
def softmax_with_temperature(logits, temperature):
scaled_logits = logits / temperature
return torch.softmax(scaled_logits, dim=0)
# 温度值
temperatures = [1, 0.1, 5]
scaled_probas = [softmax_with_temperature(next_token_logits, T) for T in temperatures]
# Plotting
import matplotlib.pyplot as plt
x = torch.arange(len(vocab))
bar_width = 0.15
fig, ax = plt.subplots(figsize=(5, 3))
for i, T in enumerate(temperatures):
rects = ax.bar(x + i * bar_width, scaled_probas[i], bar_width, label=f'Temperature = {T}')
ax.set_ylabel('Probability')
ax.set_xticks(x)
ax.set_xticklabels(vocab.keys(), rotation=90)
ax.legend()
plt.tight_layout()
plt.show()
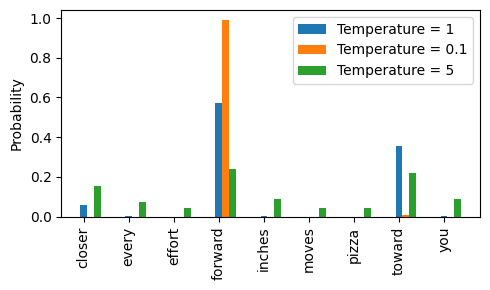
可以看到,当温度值为1时,概率分布保持不变;当温度降低至0.1 时,forward以外的所有备选项的概率几乎降为0,此时进行概率采样时,几乎必然选择forward;而当温度升高到5时,多个备选项的概率趋于相近,使得采样结果更加随机。这正是温度缩放的作用:降低温度增强确定性,提高温度提升多样性。
三、Tok-k采样
上述的温度缩放+采样策略,通过增大温度缩放系数可以提升生成结果的多样性。但是,这会导致某些不符合逻辑的token被采样,从而破坏生成结果。
为了解决这一问题,我们可以把要采样的备选项token按照概率值从大到小排序,只取前k个作为采样对象,这便是Tok-k采样的解码策略。
Top-k采样是一种控制生成文本质量的解码策略,它的核心思想是: 只在最高概率的k个token中进行采样,忽略其他低概率token,从而提高生成文本的连贯性和合理性。
def top_k_sampling(logits, k=10):
# 1️ 计算 softmax 概率
probas = torch.softmax(logits, dim=-1)
# 2️ 取出 top-k 最高概率的 token
top_k_values, top_k_indices = torch.topk(probas, k)
# 3️ 归一化 top-k token 的概率
top_k_probs = top_k_values / top_k_values.sum()
# 4 在 top-k 范围内采样
next_token_id = torch.multinomial(top_k_probs, num_samples=1)
# 5️ 取出最终的 token ID
next_token = top_k_indices[next_token_id]
return next_token.item()
四、Top-k+温度缩放+采样
在执行完Top-k采样后,再执行温度系数缩放+采样的策略,直接上代码:
def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
for _ in range(max_new_tokens):
# 1. 获取logits,shape为[batch_size,vocab_num]
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]# [batch_size,vocab_num]
# 2. 执行top-k采样
if top_k isnotNone:
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
# 把其他未被采样的vocab_num-tok_k个元素置为-inf
logits = torch.where(logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits)
# 3. 执行温度缩放+采样
if temperature > 0.0:
logits = logits / temperature
# Apply softmax 获得概率值
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
# 多项式采样
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
# 如果没有设置温度缩放系数,执行贪婪解码策略
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
if idx_next == eos_id: # 遇到终止符,提前终止生成,即使还没有达到max_new_tokens次
break
# 准备下一个token的预测
idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
return idx
五、Top-p采样
Top-p是一种改进的文本生成采样方法,与Top-k采样相比,它不限制候选token数量,而是动态选择概率总和达到p(累积概率阈值)的token进行采样。
Top-p采样的步骤如下:
1.先对所有logits进行softmax归一化,得到概率probs。
2.按概率值从大到小排序,并计算累积概率cumsum(probs)。
3.只保留累积概率总和≤p的token,其他设为0。
4.重新归一化概率分布,使其总和为1。
5.根据这个筛选后的概率分布进行随机采样。
相应代码如下:
def top_p_sampling(logits, top_p=0.9):
"""
实现 Top-p 采样 (Nucleus Sampling)
:param logits: (batch_size, vocab_size),模型输出的 logits
:param top_p: 保留的累计概率阈值
:return: 采样出的 token ID
"""
# 1️ 计算 softmax 归一化的概率
probs = torch.softmax(logits, dim=-1) # (batch_size, vocab_size)
# 2️ 按概率值降序排序,得到索引和排序后的概率
sorted_probs, sorted_indices = torch.sort(probs, descending=True) # (batch_size, vocab_size)
# 3️ 计算累积概率
cumulative_probs = torch.cumsum(sorted_probs, dim=-1) # (batch_size, vocab_size)
# 4️ 找到使累积概率 > p 的第一个位置
cutoff_mask = cumulative_probs > top_p # (batch_size, vocab_size)
# 确保至少保留一个 token
cutoff_mask[:, 0] = False
# 5️ 过滤掉累计概率之外的 token(设为 0)
sorted_probs[cutoff_mask] = 0
# 6️ 重新归一化
sorted_probs = sorted_probs / sorted_probs.sum(dim=-1, keepdim=True)
# 7️ 从剩下的 token 中按概率进行随机采样
sampled_index = torch.multinomial(sorted_probs, num_samples=1) # (batch_size, 1)
# 8️ 还原到原始词汇表索引
next_token = sorted_indices.gather(dim=-1, index=sampled_index) # (batch_size, 1)
return next_token
六、Top-k + Top-p + 温度缩放 + 采样
在LLM进行自回归预测时,如何从logits(未归一化的预测值)中采样下一个token直接影响文本的流畅性、创造力和稳定性。
这里,我们结合上面所讲的温度缩放、Top-k采样和Top-p采样,实现一个完整的 高质量文本生成策略。
def sample_next_token(logits, temperature=1.0, top_k=None, top_p=None):
"""
从 logits 中采样下一个 token,结合温度缩放、Top-k 和 Top-p 采样。
:param logits: (batch_size, vocab_size),模型的预测输出
:param temperature: 控制模型输出的随机性,越低越确定,越高越多样化
:param top_k: 仅保留前 k 个最高概率的 token
:param top_p: 仅保留累积概率达到 p 的 token
:return: 采样得到的 token ID
"""
# 1️ 温度缩放:调整 logits
if temperature > 0.0:
logits = logits / temperature # 增加或降低 logits 差距
# 2️ 应用 Top-k 采样(如果指定了 top_k)
if top_k isnotNone:
top_logits, _ = torch.topk(logits, top_k) # 取 top-k 最大的 logits
min_logit = top_logits[:, -1] # 取第 k 大的值
logits[logits < min_logit] = float("-inf") # 低于第 k 大的值全部设为 -inf
# 3️ 应用 Top-p 采样(如果指定了 top_p)
if top_p isnotNone:
# 计算 softmax 概率
probs = torch.softmax(logits, dim=-1)
# 按概率排序
sorted_probs, sorted_indices = torch.sort(probs, descending=True)
# 计算累积概率
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
# 找到累积概率 > top_p 的第一个位置
cutoff_mask = cumulative_probs > top_p
cutoff_mask[:, 0] = False# 确保至少保留 1 个 token
# 过滤掉超过 top_p 的 token
sorted_probs[cutoff_mask] = 0
sorted_probs = sorted_probs / sorted_probs.sum(dim=-1, keepdim=True) # 归一化
# 进行 multinomial 采样
sampled_index = torch.multinomial(sorted_probs, num_samples=1)
next_token = sorted_indices.gather(dim=-1, index=sampled_index)
else:
# 4️ 如果不使用 Top-p,则直接用 softmax 进行 multinomial 采样
probs = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
return next_token # (batch_size, 1)
在本文的最后,我们对上面介绍的LLM解码策略总结如下表:
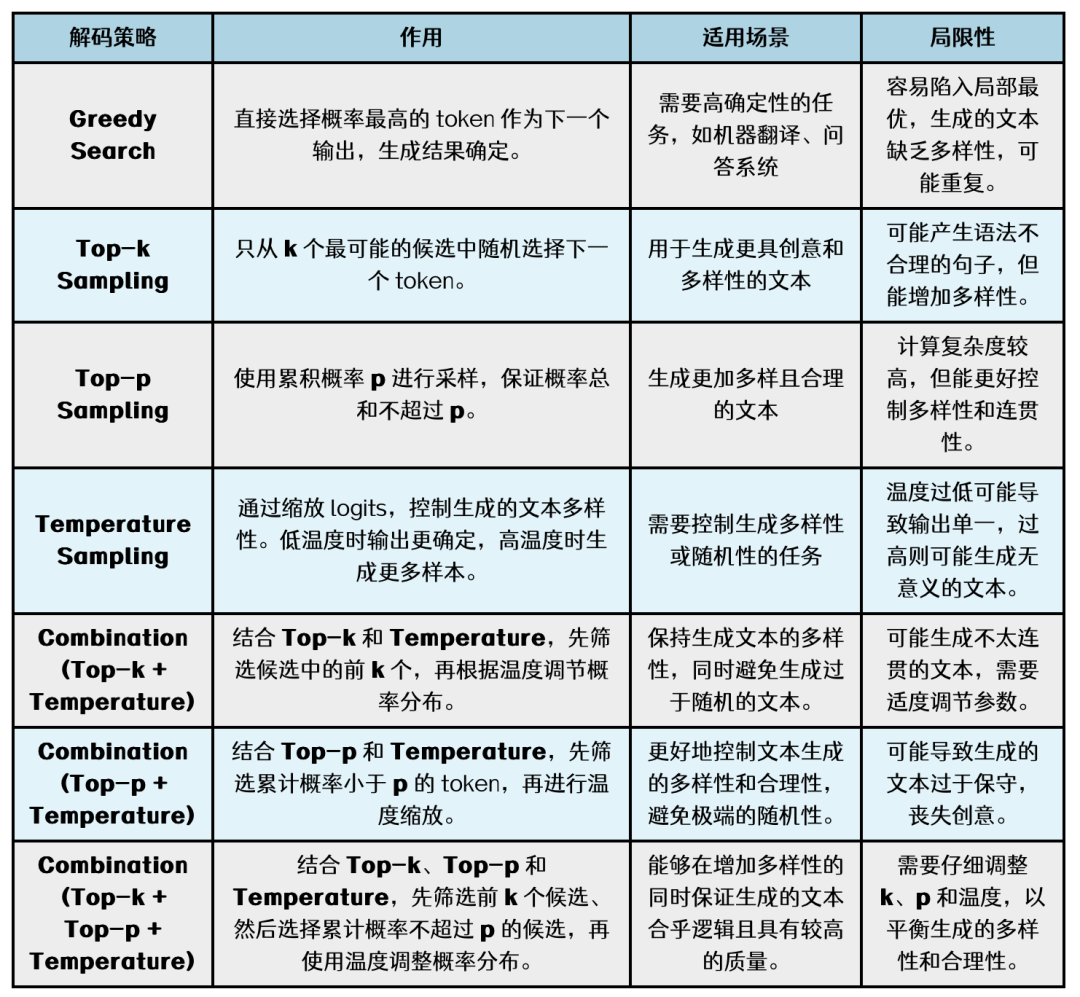
(注:表格中的Top-p+Temperature和本文第四部分Top-k+Temperature类似,因此本文未具体展开)
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









