







前言
随着互联网和宽带上网的普及, 搜索引擎在中国异军突起, 并日益渗透到人们的日常生活中, 在互联网普及之前, 人们查阅资料首先想到的是拥有大量书籍的资料的图书馆。 但是今天很多人都会选择一种更方便、 快捷、 全面、 准确的查阅方式–互联网。 而帮助我们在整个互联网上快速地查找到目标信息的就是越来越被重视的搜索引擎。
今天学长来向大家介绍如何使用python写一个搜索引擎,该项目常用于毕业设计
1.实现
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
1.1 系统架构
搜索引擎有基本的五大模块,分别是:
- 信息采集模块
- 信息处理模块
- 建立索引模块
- 查询和 web 交互模块
本设计研究的是如何在信息处理分析的基础上,建立一个完整的中文搜索引擎。
所以该系统主要由以下几个详细部分组成:
- 爬取数据
- 中文分词
- 相关度排序
- 建立web交互。
1.2 爬取大量网页数据
爬取数据,实际上用的就是爬虫。
我们平时在浏览网页的时候,在浏览器里输入一个网址,然后敲击回车,我们就会看到网站的一些页面,那么这个过程实际上就是这个浏览器请求了一些服务器然后获取到了一些服务器的网页资源,然后我们看到了这个网页。
请求呢就是用程序来实现上面的过程,就需要写代码来模拟这个浏览器向服务器发起请求,然后获取这些网页资源。那么一般来说实际上获取的这些网页资源是一串HTML代码,这里面包含HTML标签,还有一些在浏览器里面看到的文字。那么我们要提取的一些数据就包含在这些HTML文本里面。我们要做的下一步工作就是从这些文本里提取我们想要的一些信息(比如一段话,一个手机号,一个文字这类的),这就是我们提取的一个过程。提取出来之后呢我们就把提取出来的信息存到数据库啊文本啊这类的。这就是完成了一个数据采集的过程。
我们写完程序之后呢就让它一直运行着,它就能代替我们浏览器来向服务器发送请求,然后一直不停的循环的运行进行批量的大量的获取数据了,这就是爬虫的一个基本的流程。
一个通用的网络爬虫的框架如图所示:
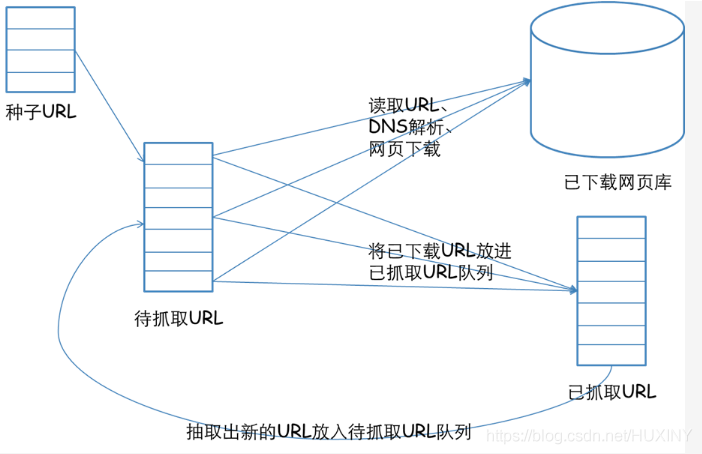
这里给出一段爬虫,爬取自己感兴趣的网站和内容,并按照固定格式保存起来
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1814
1814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









