








 本文探讨了数据库主键选择的三种常见策略:自增ID、UUID和雪花算法。自增ID因顺序性可能引发安全问题和分库分表时的冲突;UUID虽然无序,但会导致B+树频繁调整,降低插入性能;雪花算法结合了两者优点,提供高性能、分布式友好的ID生成方案。文章提供了相关资源链接和Go、Java实现的示例。
本文探讨了数据库主键选择的三种常见策略:自增ID、UUID和雪花算法。自增ID因顺序性可能引发安全问题和分库分表时的冲突;UUID虽然无序,但会导致B+树频繁调整,降低插入性能;雪花算法结合了两者优点,提供高性能、分布式友好的ID生成方案。文章提供了相关资源链接和Go、Java实现的示例。
- 摘自一篇文章开头:
- 讲的很清晰,可以看看概念和对比https://blog.csdn.net/qq_40950903/article/details/108589837

- B站讲解 B树,B+树的视频,还有mysql索引
一: 为啥不用自增id作为用户的id?
- 有两方面的考虑:
- (1)首先: id长度不一,且太具有顺序性!数据安全性差! 轻易就可以知道自己是该站点第几个注册的用户。并且如果是注册的新用户,还可以知道当前站点已经有多少个注册用户! 这是不太好的,信息安全问题。
- (2)其次: 数据量庞大,进行分库分表的时候, 不同库中的用户id可能发生重复。假设第一个库已经有 1亿个用户,那为了保证不重复,第二个机器,或者表,只能从大于 一亿的 位置开始。
且,必须要大于1亿很多,因为第一台机器还会继续增长,可能导致增长过程中重复!
二:为啥不使用uuid?
- 啥是 uuid?来自百度百科的截图。 (我之前写登录时,图形验证码的保存,也用到过 uuid,当做key存储进redis)
- 目前最广泛应用的UUID,是微软公司的全局唯一标识符(GUID),而其他重要的应用,则有Linux ext2/ext3文件系统、LUKS加密分区、GNOME、KDE、Mac OS X等等

- uuid 是一长串用 - 分隔的
字符, 图中介绍描述uuid 有 128长, 32字节表示。并且是无序的!这点很关键。 我在B站上看到讲解 B+树和mysql 索引的文章,其中讲到 页结构,和插入数据的过程
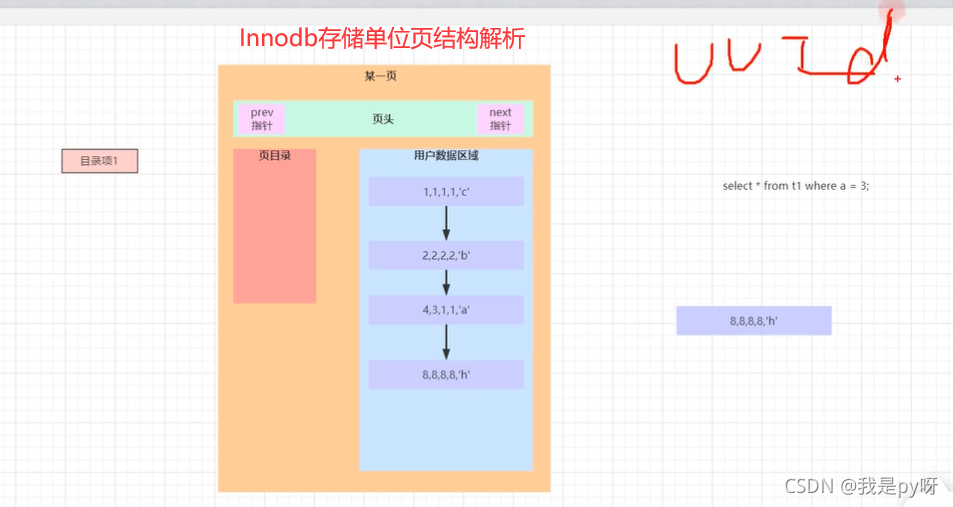
- 默认插入数据会以主键作为索引,建立聚簇索引。 在磁盘中将数据读取是按照页(逻辑单位)进行的。 每一页的大小默认是 16KB。因为作为主键的话,内部插入默认排序。 uuid是无序的,导致每次的插入结果不一定,增加时间开销。 如果是自增id,每次都是在后面进行插入了。
- 每一次UUID数据的插入都会对主键的b+树进行很大的修改,这一点很不好,插入完全无序,不但会导致一些中间节点产生分裂,也会白白创造出很多不饱和的节点,这样大大降低了数据库插入的性能。
- 顺序的插入,总数能不断达到饱和节点,每个节点存储足够多的关键字。 随意插入还需要判断往哪插入,插入的当前页,可能会造成分裂,改变B+树结构。
- 插入效率低。
- 目前最广泛应用的UUID,是微软公司的全局唯一标识符(GUID),而其他重要的应用,则有Linux ext2/ext3文件系统、LUKS加密分区、GNOME、KDE、Mac OS X等等
三:雪花算法(snowflake)
-
雪花算法是Twitter开源的由64位整数组成的分布式ID,性能较高,并且在单机上递增。
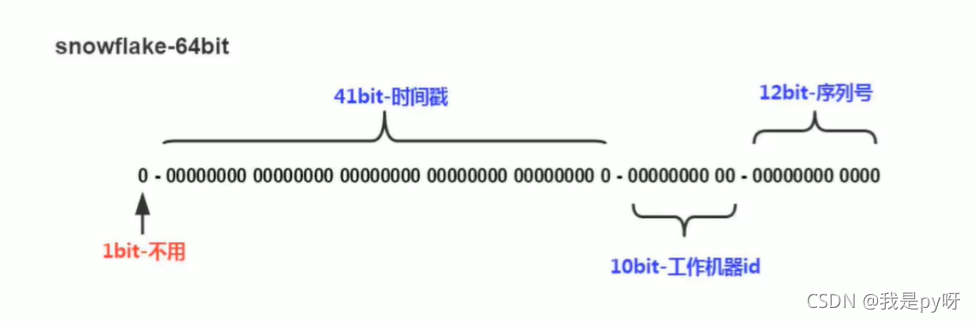
- 全长64位。
- 第一部分,是1bit: 0。该段无意义。因为二进制里第一个bit如果是1,那么都是负数,我们生成的id要求都是正数。
- 第二部分: 时间戳,单位为毫秒,总共可以容纳约69年。这个时间戳不是从1970年开始记起的,因为那样只能用到 2039年。 可以 以项目上线的时间为起点,开始计算。
- 第三部分:5bit表示机房id,剩下5bit表示机器id。一共10位,就是最多容纳 1024个机器。
- 第五部分表示序号:某个机房,某个机器这一毫秒内同时生成的id的序号。一共12位,那么就是一共可以生成 4096个一毫秒。
总计:同一毫秒的ID数量:1024 x 4096 = 3194304个。完完全全滴够用了。
-
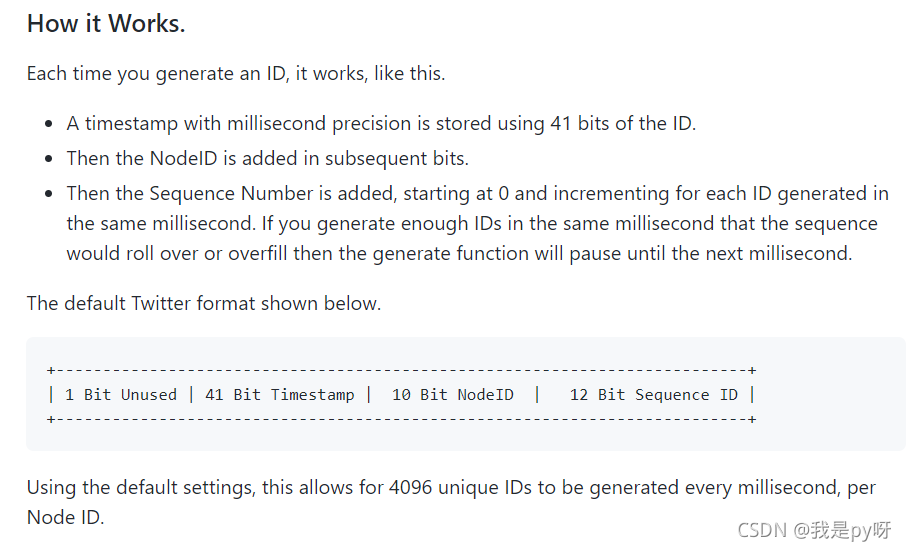
go语言实现的 雪花算法,已经有开源的了,300多行代码:https://github.com/bwmarrin/snowflake/blob/master/snowflake.go这个实现的是和上述描述的基本一致。官方文档截图:
-
给出链接,讲解java版本的 雪花算法实现源码分析(代码都不长,200行左右):https://www.bilibili.com/video/BV1tr4y1C7gi?spm_id_from=333.999.0.0
-
他们的原理都是类似的。通过很多 位运算操作,拼凑出来 ID。 需要注意的点:
- 要注意ID值一毫秒内的数量, 当生成数量大于 一毫秒的最大值时,需要等待到下一毫秒。
- 当前的时间 与上一次获取id相同时,说明是在统一毫秒, 序列(step)递增
- 当小于时,返回错误, 当大于上次时间时,说明不在统一毫秒,更新 序列为 0,表示这一毫秒内重新开始计数。
-
go项目中使用:参照文档, 代码除了解析功能外。也就100多行。每一步都有注释。 初始化一个 node节点对象,然后调用生成相应的ID就可以了,可以是 int64,string等等类型的结果。
package sonwflake // 这个模块封装了 雪花算法生成相应用户ID的方法。 import ( "github.com/bwmarrin/snowflake" "time" ) // 定义一个节点: 通过这个全局的 node,就可以用于制造 ID了。 var node *snowflake.Node // 源码里有很多默认的基本设定,比如开始时间等等, 我们可以改变这些,自己初始化一个 node节点 func Init(startTime string, machineID int64) (err error) { var st time.Time st, err = time.Parse("2006-01-02", startTime) if err != nil { return } // 设置时间 snowflake.Epoch = st.UnixNano() / 1000000 node, err = snowflake.NewNode(machineID) return } // 返回int64位的 id值 func GenID() int64 { return node.Generate().Int64() } -
文档中给出的使用:
package main import ( "fmt" "github.com/bwmarrin/snowflake" ) func main() { // Create a new Node with a Node number of 1 // 生成一个节点 node, err := snowflake.NewNode(1) if err != nil fmt.Println(err) return } // Generate a snowflake ID. // type ID int64 这是id的类型,下面定义了很多方法, 获取Base64呀,或者是打印它的时间戳等 id := node.Generate() // Print out the ID in a few different ways. fmt.Printf("Int64 ID: %d\n", id) fmt.Printf("String ID: %s\n", id) fmt.Printf("Base2 ID: %s\n", id.Base2()) fmt.Printf("Base64 ID: %s\n", id.Base64()) // Print out the ID's timestamp fmt.Printf("ID Time : %d\n", id.Time()) // Print out the ID's node number fmt.Printf("ID Node : %d\n", id.Node()) // Print out the ID's sequence number fmt.Printf("ID Step : %d\n", id.Step()) // Generate and print, all in one. fmt.Printf("ID : %d\n", node.Generate().Int64()) }

















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









