








 本文介绍了如何使用Python解决游戏《戴森球计划》中的生产规划问题,通过建立资源、工厂和产品类,以及动态规划算法,解决复杂的生产线配置和产量计算。文中展示了从单一资源到多种产品的生产链计算,并提供了实际代码示例。
本文介绍了如何使用Python解决游戏《戴森球计划》中的生产规划问题,通过建立资源、工厂和产品类,以及动态规划算法,解决复杂的生产线配置和产量计算。文中展示了从单一资源到多种产品的生产链计算,并提供了实际代码示例。
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以点击下方链接自行获取
目录
- 如何用Python解决《戴森球计划》中的生产规划问题
- Python基础定义
- 算法背景
- 第一步:流水线匹配
- 第二步:链式的解决流水线
1.如何用Python解决《戴森球计划》中的生产规划问题
《戴森球计划》是一款国人工作室(他们只有五个人)出品的游戏,1月22日在Steam上线进入EA(抢先体验阶段)以来,45分钟即占领了销量榜,并创下了1周销量45万的好成绩。

这个游戏的背景很简单:《戴森球计划》的名字来源于戴森球,指的是科技高度达到一定水平的未来世界,这个世界会有能力制作一个包裹住整个恒星的球壳,来收集恒星的全部能量。

在游戏里,你作为主人公机器人,搭载着科技和工程的知识,在一颗行星着陆,你可以在这个行星上采集资源点,排布熔炉和工厂,建立起一套完整的工业体系,最终建立起一个覆盖整个恒星的戴森球。
为什么好玩,这要从游戏的基本元素开始讲起。在这个异世界搭建简化的工业体系,基础元素只有两个:1、自然资源 2、工业制成品。而自然资源可以通过工厂制作成工业制成品。
总共三个概念,这样简单的概念为什么好玩呢?好玩就好玩在这个体系的关系可以发展得非常复杂。我们以一个游戏的实例作为演示:
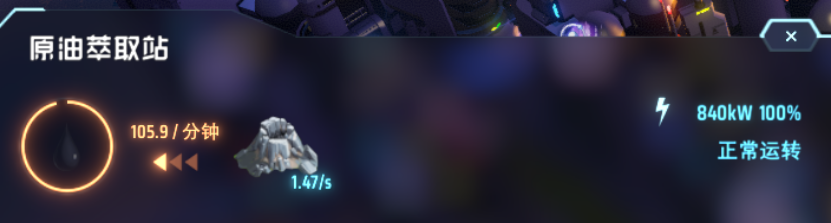
资源点石油,可以采集“原油”,原油的产量如图所示,是105.9每分钟(如果电力充足,产量还可以提高)
而原油可以被原油精炼厂加工,2个单位的原油,可以产出2个单位的精炼油和1个单位的氢:

同样的工厂,也可以继续加工精炼油,公式是:2个单位的氢和1个单位的精炼油,可以生成3个单位的氢和1个单位的高能石墨,每分钟产量是15即 45个单位的氢:

这样一路传递下去的工业链条,就充满了复杂性。我们先从简单的小学应用题开始:每分钟100产量的原油,可以产出多少精炼油和氢?答案是100个精炼油和50个氢。
第二题:如果不产出精炼油,最多可以产出多少氢和多少高能石墨?这就需要比比划划一下才能计算明白了:
看上面两个图的公式,可以注意到,原油-精炼油-高能石墨的关系正好是1:1:1,答案是每分钟100个高能石墨,再反推:本来生产了高能石墨同时产出了300个氢,生产流水线中,意味着上游一定输入了200个氢,从产出中扣除,还有是原油裂解产出的50个氢,最终的答案就是150个氢。
第三题:如果我们需要在产出的时候,保证高能石墨的数量和精炼油是1:2,那么此时需要安排几个工厂?(这题亦不难,留待读者后续自行回答)。1个资源,4种产物。
上述仅仅涉及了1种资源,4种工业制品,如果工业链条更长了,那计算就会更加复杂了。
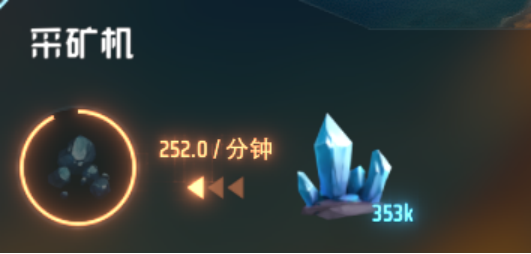
举一个目前笔者的产业链的产品,超级磁场环为例:

那么需要的链条是:
1. 1个高能石墨,3个磁铁,2个电磁涡轮=1个超级磁场环。每分钟产量20个
2. 2个电动机,2个磁线圈=1个电磁涡轮。每分钟产量30个
3. 1个铜板,2个磁铁=1个磁线圈。每分钟产量60个
4. 1个铁矿=1个磁铁。每分钟产量40个
5. 1个铜矿=1个铜板。每分钟产量60个
6. 1个磁线圈,1个齿轮,2个铁板=1个电动机。每分钟产量30个
7. 1个铁矿=1个铁板。每分钟产量60个
8. 1个铁板=1个齿轮。每分钟产量60个
9. 上面说过的1单位原油刚好能产出1单位高能石墨
里面涉及了3种资源:原油、铁矿、铜矿,公式也只有9个,意味着最简单我只需要安排8个工厂,遵循上下游关系就好,但是问题就在于:这每个工厂的输入和产出并不是完全对等的,需要把流水线安排合理,才能达到最大的产量。
第四题:如果要使得超级磁场环产量达到每分钟20个,那么我需要多少资源产量,如何安排上述流水线?
还需要手动计算吗?不,我要用Python来解决这个问题!
2.Python基础定义
首先从游戏的基本概念定义起
1. 资源。不妨直接定义资源的产量
2. 工厂。工厂输入产品或者资源,经过一个流水线,输出产品
3. 产品。
在Python中,我们可以通过类与继承关系完成这样的代码。我们的开发环境是Python3.6,使用的也是Python的基础语法,不涉及第三方库。
首先从资源和产品开始,因为他们都可以作为工厂的输入,不妨让资源成为一个类

上述代码展示了定义一个类、定义类的初始化函数__ init __和魔法方法__ str __,这个魔法方法可以让类转换为字符串时,构造出一个字符串来方便展示。
运行代码可以得到:

和游戏中的铁矿采集等同:
工厂类的定义则需要思考:输入的每种产品,对应的数量是消耗的数量,而输出的产品,数量对应的即出产的数量。工厂的名称无关紧要,我们其实只关心流水线的输入和输出。

上面的代码主要涉及了Python的知识点:
-
列表推导式
["%sx%s" % (p.name,num) for p,num in input_products]
直接构造出了一个列表 -
字符串格式化,join的内置方法,和%s format
那么定义一个流水线的结果如下:


这样看起来非常漂亮。上述的第四题,我们可以用一个列表数据结构,来表达我们第四题说到的流水线了
用一长串文本来定义上面的流水线,
定义:英文冒号:用来区分名称和数量,英文逗号用来分割多个产品,英语句号.用来分割输入输出,

运行代码的结果如下:

有了工厂的定义,接下来就是开始流水线的计算了,也即:如果我们需要最终产物超级磁场环,那么每个流水线都需要几条?这里主要涉及的是算法的知识。
3.算法背景
在算法领域,像这样的生产规划问题,尤其是这种简单的A-B-C的线性流程规划问题,被定义为动态规划问题.。动态规划问世以来,在经济管理、生产调度、工程技术和最优控制等方面都得到了广泛的应用。例如最短路线、库存管理、资源分配、设备更新、排序、装载等问题,用动态规划方法比用其它方法求解更为方便。
对于复杂的应用场景,动态规划可能会出现许多变形,例如在《戴森球计划》的场景中,不同的流水线可能产出相同的产物,而他们的生产代价显然是不同的。好在我们上面出现的这些流水线,都是简单的流程,因此后面出现的动态规划算法也可以用简单的代价实现。
第一步:流水线匹配
首先来实现一个小型的功能:给定一个产物的数量、已知上述的所有工厂流水线,找到1条流水线,使得产出的数量匹配

定义的函数如上,这里的need_product是所需的产品和数量,类型是一个元组
经过简单的思考,可以想到,这里只需要做一个流水线输出产品到流水线的映射关系就好了,那么通过数据结构dict即可实现。考虑同样的产品,可能由不同的流水线产生,那么我们dict的value应当是一个list,这样用标准库中的defaultdict,可以自带初始化的空列表
样子大概长这样:

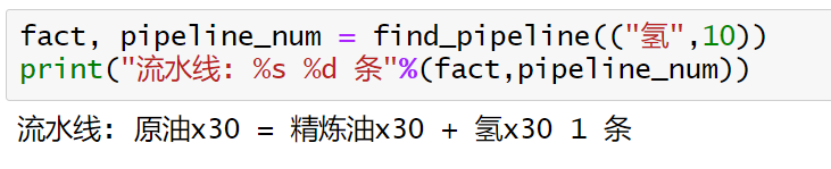
而当我们找到了某条流水线,例如原油x30 = 精炼油x30 + 氢x30 这条好了,流水线的数量和我们需要的产品数量,如何能够完美的匹配起来呢?比如需要氢40个的时候。我们其实有两种策略:1、寻找满足要求的最少的流水线倍数,这会使得需求的资源更为节省 2、寻找最小公倍数,这样尽可能会使得资源不会剩余。
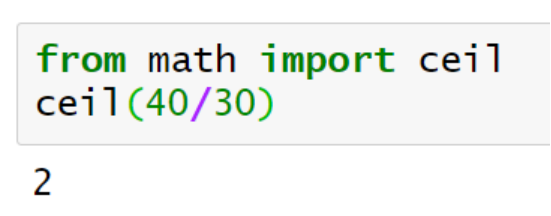
本期我们实现的是第一种。需求的流水线倍数,即为需求量除以产出量,整数向上取整。用到的是标准库的ceil函数
综上,我们可以把“获得单条产品”所需的流水线数量,和产物的数量得到了,实现的代码如下:

关于产品映射关系的product_map,放在了函数外面,也就是初始化一次即可
结果:
第二步:链式的解决流水线
有了第一步作为基础,接下来的工作也就很简单了,如果我们要一路往上寻找,直到所有的流水线的需求都被满足,那么应当遵循以下原则。
1. 输入所需的产品和数量,加入“需求池”
2. 如果需求池不为空,那么1、看需求池能否从供给池直接扣减 2、寻找需求池中需要被满足的产品,如果需求池内所有的产品都已经是最基本的资源了,表达都被满足了,那么返回结果,否则往下走
3. 寻找能输出这个产品的流水线,会返回所需流水线的数量
4. 对于第3步找到的流水线,首先将流水线的输出,从需求池中扣除,如果还有多余的,加入“供给池”
5. 流水线的输入,加入“需求池”,继续回到第二步的循环
按照我们上面的例子,需要的产物是超级磁场环,它进一步需要磁铁,那么流水线数量*磁铁的数量加入需求池,继续寻找磁铁的依赖关系。
那么加入一点点细节:
from collections import Counter
basic_resources = {"铁矿", "铜矿", "原油"}
def filter_pool(pool):
# 过滤掉数量为0的,即为所需要的真正的产品
return {key: value for key, value in pool.items() if value}
def all_need_is_resources(pool):
pool = filter_pool(pool)
return all(map(lambda prod:prod in basic_resources, pool.keys()))
def fine_link(need_product):
require_pool = Counter() #需求的产品: 数量
provide_pool = Counter() #现有流水线产出的产品: 数量
pipeline_count = Counter()
# fact, pipeline_num, product_num = find_pipeline(need_product)[0] # 如果寻找到多条流水线,就用第一条
product_name,number =need_product
require_pool[product_name]+=number
while 1:# 循环条件:如果需要的池子都已经是资源了,那么退出循环
# # 特别的逻辑:
require_pool = Counter(filter_pool(require_pool))
provide_pool = Counter(filter_pool(provide_pool))
# 需求池不为空,那么遍历需求池
for product_name, number in list(require_pool.items()):
if product_name in basic_resources: #如果所需的是基础资源,那么直接加就好,不需要寻找流水线
require_pool[product_name] += number
elif number:
fact, pipeline_num = find_pipeline((product_name,number))
# 找到流水线之后:流水线的所有输出乘以数量后 放入供给池
for output_prod, output_num in fact.outputs:
provide_pool[output_prod.name] += (pipeline_num * output_num)
pipeline_count[str(fact)] += pipeline_num
# 流水线的所有输入乘以数量后 放入需求池
for input_prod, input_num in fact.inputs:
require_pool[input_prod.name] += (pipeline_num * input_num)
# 供给池如果有能满足需求池的,那么需求池减掉供给池
for provide_key,provide_num in provide_pool.items():
if provide_key in require_pool:
require_num = require_pool[provide_key]
require_pool[provide_key] -= min(provide_num, require_num)
provide_pool[provide_key] -= min(provide_num, require_num)
if all_need_is_resources(require_pool):
break
require_pool = Counter(filter_pool(require_pool))
provide_pool = Counter(filter_pool(provide_pool))
return require_pool,provide_pool,pipeline_count
做好啦:


















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









