







实验任务
这里我选择 A 类的迭代深入搜索和 A*算法两种搜索算法求解八数码问题的解,并比较两种方式。
八数码问题是:在 3 × 3 九宫棋盘上,放置数码为 1 - 8 的 8 个棋牌,剩下一个空格(用 0 代替),只能通过棋牌向空格的移动来改变棋盘的布局。要求找到一种从给定初始布局(即初始状态)到目标布局(即目标状态)的移动方法。
比如我们可以让初始状态为:
1 | 2 | 3 |
4 | 5 | 6 |
7 | 0 | 8 |
目标状态为:
1 | 2 | 3 |
4 | 0 | 6 |
7 | 5 | 8 |
只需要交换 5 和 0 ,即可实现。
解决方案
我们将一种可能的 3 × 3 九宫棋盘,用一个 Node 类(下面我都称之为节点)来表示:包含 9 个数字的排列方式(即 data ),到达这个节点的步数(即 step ),当前节点是从哪个节点来的(即 parent )和每个节点的启发值。
# 创建Node类 (包含当前数据内容,父节点,步数)
class Node:
f_loss = -1 # 启发值
step = 0 # 初始状态到当前状态的距离(步数)
parent = None, # 父节点
# 用状态和步数构造节点对象
def __init__(self, data, step, parent):
self.data = data # 当前状态数值,是一个数组
self.step = step # 当前的步数
self.parent = parent # 当前节点的父节点
self.f_loss = cal_wcost(data) + step # 计算启发值A*算法
属于启发式搜索的一种,意思是说每次走到一个节点,我们就计算一下这个节点的启发值,如果节点的启发值越低,我们就把它的优先级设置的越高。启发值计算公式如下: f(n) 表示初始节点到当前节点的耗费,h(n) 表示当前节点到目标节点的预测耗费。
f(n) = g(n) + h(n) 对于此题,我们可以用当前节点和目标节点的不同的个数来当作预测值,如果 9 个数字各不相同则预测值为 9 。预测值计算函数如下:
def cal_wcost(num):
'''计算此时的不同程度'''
con = 0
# 遍历整个九宫格
for i in range(3):
for j in range(3):
tmp_num = num[i][j]
compare_num = end_data[i][j]
if tmp_num != 0:
# 不等,则加一
con += (tmp_num != compare_num)
return con接下来我们来看看 A* 算法的实现。类似 BFS 算法,我们用队列 opened 来存储入队的节点,用 closed 列表标记是否访问。队列不为空,那么出队,将 0 (空位)四周可以与之交换的与之交换,如果交换后的节点没有访问过,就入队。上面都是和 BFS 一样的操作。入队时,我们需要判断队列中是否有这个节点,有的话,选择启发值较小的更新队列。最后,排序队列,选择队列中启发值最小的出队。
def astar_method_a_function(opened, closed):
'''AStar启发式搜索'''
count = 0
# 队列不为空
while len(opened.queue) != 0:
# 出队
node = opened.get()
# 如果出队节点是目标状态
if (node.data == end_data).all():
print(f'总共耗费{count}轮')
return node
# 将取出的点加入closed表中,标记已经访问
# closed[data_to_int(node.data)] = 1
closed.append(data_to_int(node.data))
# 四种移动方法
for action in ['left', 'right', 'up', 'down']:
# 创建子节点
child_node = Node(swap(node.data, action), node.step + 1, node)
index = data_to_int(child_node.data)
# 没有被访问
if index not in closed:
# 入队,但是要先判断是否在队列里
refresh_open(child_node, opened)
# 根据其中的f_loss值为open表进行排序
# 保证先出队的都是启发值较小的
sorte_by_floss(opened)
count += 1
# 达到搜索上界
if count > 5000:
print("没有搜索到可行解!")
break迭代深入搜索
迭代深入搜索( IDS ),本质上就是深度优先搜索, IDS 结合了 DFS 的空间优势与 BFS 的时间优势。对搜索的深度进行了限制,使得在搜索到限制深度后必须开始新的搜索路径。以至于看上去像是广搜(总是完成第 n 的所有节点搜索,再开始第 n + 1 的节点的搜索)。放在这里的话, n 指的就是当前的限制深度。
意思就是说我们本质上还是 DFS 算法。而且不需要维持一个队列了,可以减少空间消耗,也能像广度优先搜索一样得到最佳解。每次 DFS 的时候都有一个最大的搜索深度。由此,对于我们这个求解八数码问题我的想法是:
首先设定查找深度为 count ,然后进行深度优先搜索;没有找到的话, count + 2, 继续深度优先搜索。重复上述步骤,直到找到目标节点或者搜索深度达到设定的最大值。具体代码如下:
con = 0 # 全局变量,记录查找次数
def dfs(node, closed, depth, count):
'''dfs搜索,最大深度为count'''
# 达到最大深度了,就返回
if depth == count:
return []
# 计数
global con
con += 1
# 四个方向分别查找
for action in ['left', 'right', 'up', 'down']:
child_node = Node(swap(node.data, action), node.step + 1, node)
# 如果查找到了,那么就返回
if (child_node.data == end_data).all():
print(f'总共耗费{con}轮')
return child_node
# 得到此时九宫棋盘对应的唯一数字
index = data_to_int(child_node.data)
# 如果没有标记过
if index not in closed:
# 标记
closed.append(index)
# dfs搜索下一个节点
a = dfs(child_node, closed, depth + 1, count)
# 如果返回值不是 [] ,说明找到了
if a != []:
return a
return []
def ids_method_a_function(start_node):
'''迭代深入搜索'''
if (start_node.data == end_data).all():
return start_node
# count表示查找深度,这里我让查找深度从2增加到100,每次增加2
for count in range(2, 101, 2):
# 标记列表
closed = []
# 标记起始节点
closed.append(data_to_int(start_node.data))
# dfs搜索
a = dfs(start_node, closed, 0, count)
# 搜索到了
if a != []:
return a
print("没有搜索到可行解!")程序框架
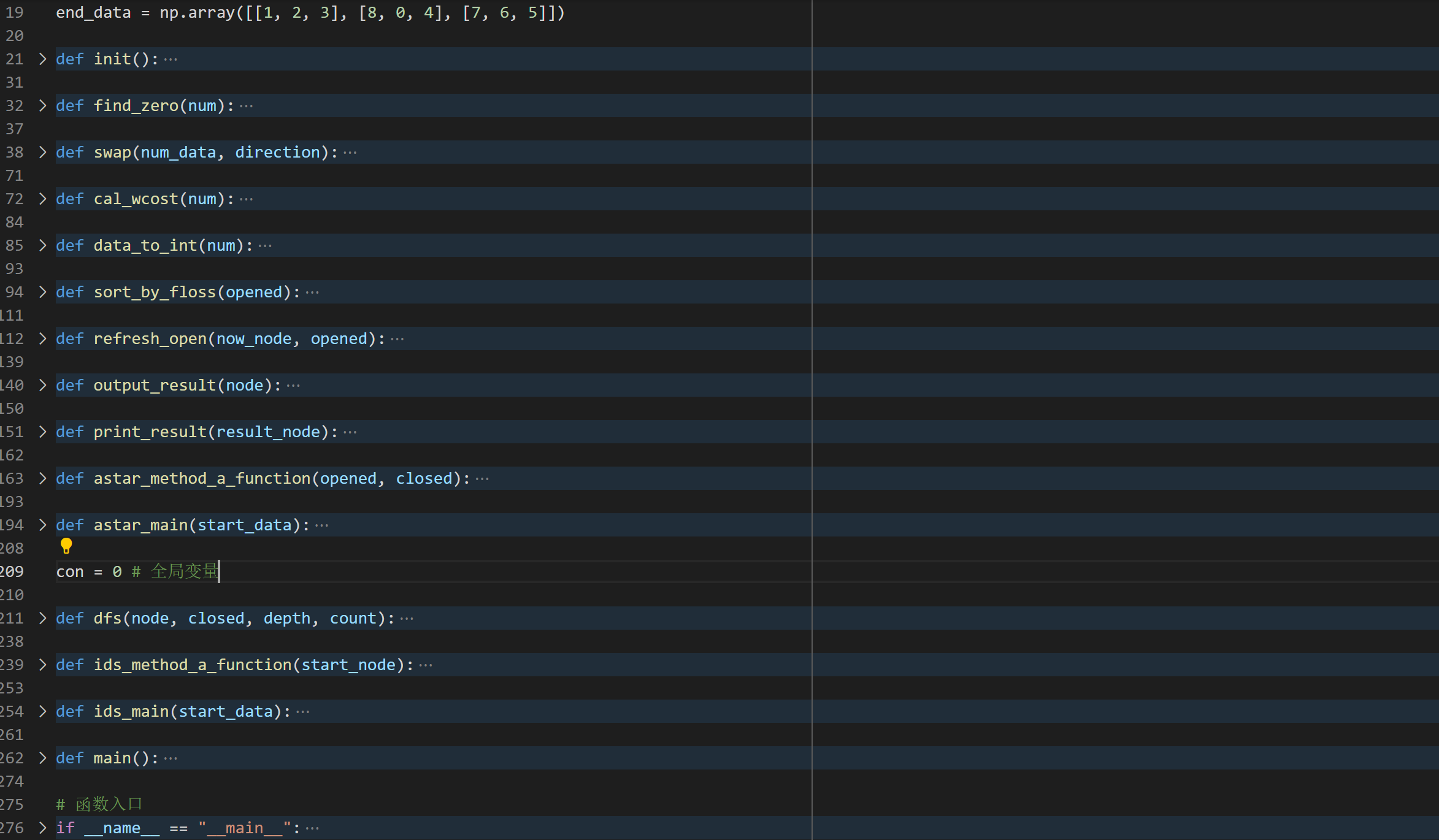
对比分析
测试案例
这里初始输入为 1 2 3 4 0 6 7 5 8
目标状态设置为 1 2 3 4 0 5 6 7 8
A* 算法运行结果如下图:
总共耗费279轮
+------+-----------+--------+
| step | data | f_loss |
+------+-----------+--------+
| 0 | [[1 2 3] | 3 |
| | [4 0 6] | |
| | [7 5 8]] | |
| --- | -------- | --- |
| 1 | [[1 2 3] | 4 |
| | [4 5 6] | |
| | [7 0 8]] | |
| --- | -------- | --- |
| 2 | [[1 2 3] | 4 |
| | [4 5 6] | |
| | [0 7 8]] | |
| --- | -------- | --- |
| 3 | [[1 2 3] | 6 |
| | [0 5 6] | |
| | [4 7 8]] | |
| --- | -------- | --- |
| 4 | [[1 2 3] | 7 |
| | [5 0 6] | |
| | [4 7 8]] | |
| --- | -------- | --- |
| 5 | [[1 2 3] | 8 |
| | [5 6 0] | |
| | [4 7 8]] | |
| --- | -------- | --- |
| 6 | [[1 2 3] | 10 |
| | [5 6 8] | |
| | [4 7 0]] | |
| --- | -------- | --- |
| 7 | [[1 2 3] | 12 |
| | [5 6 8] | |
| | [4 0 7]] | |
| --- | -------- | --- |
| 8 | [[1 2 3] | 13 |
| | [5 0 8] | |
| | [4 6 7]] | |
| --- | -------- | --- |
| 9 | [[1 2 3] | 14 |
| | [0 5 8] | |
| | [4 6 7]] | |
| --- | -------- | --- |
| 10 | [[1 2 3] | 14 |
| | [4 5 8] | |
| | [0 6 7]] | |
| --- | -------- | --- |
| 11 | [[1 2 3] | 14 |
| | [4 5 8] | |
| | [6 0 7]] | |
| --- | -------- | --- |
| 12 | [[1 2 3] | 14 |
| | [4 5 8] | |
| | [6 7 0]] | |
| --- | -------- | --- |
| 13 | [[1 2 3] | 14 |
| | [4 5 0] | |
| | [6 7 8]] | |
| --- | -------- | --- |
| 14 | [[1 2 3] | 14 |
| | [4 0 5] | |
| | [6 7 8]] | |
+------+-----------+--------+
A*算法耗时 1.5066275596618652 s深入迭代搜索算法运行结果如下图(用的是和上面同样的输出函数,这里的启发值我们忽略即可):
总共耗费1501轮
+------+-----------+--------+
| step | data | f_loss |
+------+-----------+--------+
| 0 | [[1 2 3] | 3 |
| | [4 0 6] | |
| | [7 5 8]] | |
| --- | -------- | --- |
| 1 | [[1 2 3] | 4 |
| | [4 6 0] | |
| | [7 5 8]] | |
| --- | -------- | --- |
| 2 | [[1 2 0] | 6 |
| | [4 6 3] | |
| | [7 5 8]] | |
| --- | -------- | --- |
| 3 | [[1 0 2] | 8 |
| | [4 6 3] | |
| | [7 5 8]] | |
| --- | -------- | --- |
| 4 | [[0 1 2] | 10 |
| | [4 6 3] | |
| | [7 5 8]] | |
| --- | -------- | --- |
| 5 | [[4 1 2] | 12 |
| | [0 6 3] | |
| | [7 5 8]] | |
| --- | -------- | --- |
| 6 | [[4 1 2] | 13 |
| | [6 0 3] | |
| | [7 5 8]] | |
| --- | -------- | --- |
| 7 | [[4 1 2] | 14 |
| | [6 5 3] | |
| 9 | [[4 1 2] | 14 |
| | [0 5 3] | |
| | [6 7 8]] | |
| --- | -------- | --- |
| 10 | [[0 1 2] | 14 |
| | [4 5 3] | |
| | [6 7 8]] | |
| --- | -------- | --- |
| 11 | [[1 0 2] | 14 |
| | [4 5 3] | |
| | [6 7 8]] | |
| --- | -------- | --- |
| 12 | [[1 2 0] | 14 |
| | [4 5 3] | |
| | [6 7 8]] | |
| --- | -------- | --- |
| 13 | [[1 2 3] | 14 |
| | [4 5 0] | |
| | [6 7 8]] | |
| --- | -------- | --- |
| 14 | [[1 2 3] | 14 |
| | [4 0 5] | |
| | [6 7 8]] | |
+------+-----------+--------+
迭代深入搜索算法耗时 0.2624633312225342 s个人分析
我们可以看到, A* 算法的搜索次数为 279 轮,耗费的时间 1.5066275596618652 s;迭代深入算法搜索次数为 1501 轮,耗费的时间只有 0.2624633312225342 s。
搜索次数分析:
我认为 A* 算法搜索次数较少的原因是运用了贪心的思想,每一步都是向着目标节点的方向前进,因此可以较快的得到结果;而迭代深入搜索算法没有优先级,属于穷举类型。并且,由于结合了广度优先搜索算法,第一次搜索深度为 2 ,第二次深度为 4 这样,就会造成深度较低的节点被重复访问,因此搜索次数多。
搜索时间分析:
A* 算法的耗时更长,我认为原因是 A* 算法元素入队时需要查找是否已经入队,而且入队后为了维持队列按照启发值顺序有需要排序,还有计算节点的启发值等一系列操作,耗时较长;而迭代深入搜索算法虽然搜索次数较多,但是没有上面排序查找等操作。而且很多节点的访问都是重复的, CPU 的 cache 可以加速重复节点的访问,因此耗时较短。
内存消耗分析:
A* 算法需要一个额外的队列,增加了内存开销,迭代深入搜索主要的内存开销是迭代时调用函数栈。同时,二者都需要一个标记列表。
是否为最优路线
A* 算法运用贪心的思想,虽然不能保证是最优解,但是贪心可以保证局部最优;迭代深入搜索兼具 BFS 和 DFS 的优点,我设置的每次搜索深度之差为 2 ,那么可以保证我们得到的路径与最优路径之间的误差在 2 以内。在我测试的几组数据中,二者得到的结果相同。
综合来看,A* 算法的搜索次数较少,但是耗时较长;迭代深入搜索搜索次数较长,但是耗时较短。一般来说,二者都能得到最优路线。
补充测试
增加两组测试:
输入:3 8 2 4 0 1 5 6 7
目标:1 8 7 2 0 6 3 4 5
迭代深入搜索算法耗费7090轮,耗时 1.7389905452728271 s
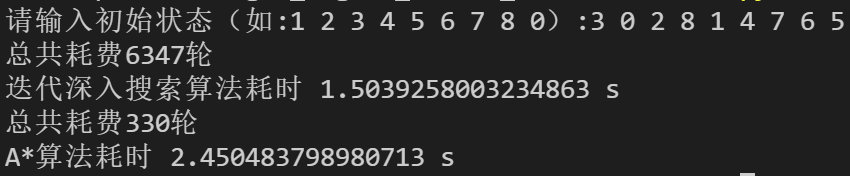
A*算法共耗费834轮,耗时 31.58454418182373 s输入:3 0 2 8 1 4 7 6 5
目标:1 2 3 8 0 4 7 6 5
代深入搜索算法耗费6347轮,耗时 1.4747085571289062 s
A*算法耗费330轮,耗时 2.457353115081787 s运行结果截图
限于篇幅,注释掉了路径的输出。
小结
选择这个题目我认为对我而言是一个很大的收获。首先是学习了 python 的相关操作,尤其的类的思想。其次学习了两种优秀的搜索算法。迭代深入搜索结合了深度优先算法和广度优先算法的优点,在书写代码时,不仅巩固了以往的知识,同样学到了一个性能更好也很常用的算法。对于 A* 算法,同样有了一个深入的了解,启发式搜索在有的时候,性能很好。同样,也有很多的不足,比如我的 A* 算法的启发值可能并没有想到一个最优的计算方法,导致对于一些较为复杂的输入,得不到解答。但总的来看,还是顺利完成了实验。
完整代码https://download.csdn.net/download/pythonyanyan/87394450

















 4285
4285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











