






1. 实现SRN
(1)使用Numpy

import numpy as np
inputs = np.array([[1., 1.],
[1., 1.],
[2., 2.]]) # 初始化输入序列
print('inputs is ', inputs)
state_t = np.zeros(2, ) # 初始化存储器
print('state_t is ', state_t)
w1, w2, w3, w4, w5, w6, w7, w8 = 1., 1., 1., 1., 1., 1., 1., 1.
U1, U2, U3, U4 = 1., 1., 1., 1.
print('--------------------------------------')
for input_t in inputs:
print('inputs is ', input_t)
print('state_t is ', state_t)
in_h1 = np.dot([w1, w3], input_t) + np.dot([U2, U4], state_t)
in_h2 = np.dot([w2, w4], input_t) + np.dot([U1, U3], state_t)
state_t = in_h1, in_h2
output_y1 = np.dot([w5, w7], [in_h1, in_h2])
output_y2 = np.dot([w6, w8], [in_h1, in_h2])
print('output_y is ', output_y1, output_y2)
print('---------------')
 需要注意的一点是h1,h2的值分别给a1,a2,作为下一次的“输入之一”还有就是dot函数的使用。,不同时间的输入是由for循环得到的。
需要注意的一点是h1,h2的值分别给a1,a2,作为下一次的“输入之一”还有就是dot函数的使用。,不同时间的输入是由for循环得到的。
改变了一下序列顺序,两个序列在顺序改变之后记忆单元中的元素也改变了,确实是最后结果不同

(2)在1的基础上,增加激活函数tanh

import numpy as np
inputs = np.array([[1., 1.],
[1., 1.],
[2., 2.]
]) # 初始化输入序列
print('inputs is ', inputs)
state_t = np.zeros(2, ) # 初始化存储器
print('state_t is ', state_t)
w1, w2, w3, w4, w5, w6, w7, w8 = 1., 1., 1., 1., 1., 1., 1., 1.
U1, U2, U3, U4 = 1., 1., 1., 1.
print('--------------------------------------')
for input_t in inputs:
print('inputs is ', input_t)
print('state_t is ', state_t)
in_h1 = np.tanh(np.dot([w1, w3], input_t) + np.dot([U2, U4], state_t))
in_h2 = np.tanh(np.dot([w2, w4], input_t) + np.dot([U1, U3], state_t))
state_t = in_h1, in_h2
output_y1 = np.dot([w5, w7], [in_h1, in_h2])
output_y2 = np.dot([w6, w8], [in_h1, in_h2])
print('output_y is ', output_y1, output_y2)
print('---------------')

这个的区别就是加完激活函数在去送去输出,送给a1,a2,加了激活函数,增加非线性。
(3)使用nn.RNNCell实现(具体总结见问题4)
import torch
batch_size = 1
seq_len = 3 # 序列长度
input_size = 2 # 输入序列维度
hidden_size = 2 # 隐藏层维度
output_size = 2 # 输出层维度
# RNNCell
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
# 初始化参数 https://zhuanlan.zhihu.com/p/342012463
for name, param in cell.named_parameters():
if name.startswith("weight"):
torch.nn.init.ones_(param)
else:
torch.nn.init.zeros_(param)
# 线性层
liner = torch.nn.Linear(hidden_size, output_size)
liner.weight.data = torch.Tensor([[1, 1], [1, 1]])
liner.bias.data = torch.Tensor([0.0])
seq = torch.Tensor([[[1, 1]],
[[1, 1]],
[[2, 2]]])
hidden = torch.zeros(batch_size, hidden_size)
output = torch.zeros(batch_size, output_size)
for idx, input in enumerate(seq):
print('=' * 20, idx, '=' * 20)
print('Input :', input)
print('hidden :', hidden)
hidden = cell(input, hidden)
output = liner(hidden)
print('output :', output) 
(4)使用nn.RNN实现
import torch
batch_size = 1
seq_len = 3
input_size = 2
hidden_size = 2
num_layers = 1
output_size = 2
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)#默认是tanh
for name, param in cell.named_parameters(): # 初始化参数,named_parameters()返回参数名称及参数
if name.startswith("weight"):
torch.nn.init.ones_(param)#把参数设为全1
else:
torch.nn.init.zeros_(param)#把参数设为全0
# 线性层
liner = torch.nn.Linear(hidden_size, output_size)
liner.weight.data = torch.Tensor([[1, 1], [1, 1]])#Weight:(out_features,in_features)
liner.bias.data = torch.Tensor([0.0])
inputs = torch.Tensor([[[1, 1]],
[[1, 1]],
[[2, 2]]])
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)
print('Input :', inputs[0])
print('hidden:', 0, 0)
print('Output:', liner(out[0]))#光靠rnn到不了最终输出,还得过一下线性层
print('--------------------------------------')
print('Input :', inputs[1])
print('hidden:', out[0])
print('Output:', liner(out[1]))
print('--------------------------------------')
print('Input :', inputs[2])
print('hidden:', out[1])
print('Output:', liner(out[2]))
2. 实现“序列到序列”
观看视频,学习RNN原理,并实现视频P12中的教学案例
观看视频收获:
线性层的复用,同一线性层反复运算,本质就是一个线性层
权重共享
h0先验知识
循环神经网络喜欢用tanh

这里的banch_first设为true了,输入的数注意一下banch_size放在第一位就好了。(其实这个API维度对应好,剩下就直接用了)
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell=torch.nn.RNN (input_size= input_size ,hidden_size= hidden_size ,num_layers= num_layers ,batch_first= True)
inputs=torch.randn(batch_size ,seq_len,input_size )
hidden=torch.zeros(num_layers ,batch_size ,hidden_size )
out,hidden =cell(inputs,hidden)
print('Outputs size:',out.shape)
print('Output:',out)
print('Hidden size:',hidden.shape)
print('Hidden:',hidden)
一个词对应一个向量,弄成数,根据字符构造一个词典,给每个词分配索引,先变索引在弄成向量,有多少个词向量有多少维(弄成独热向量),x的输入就是4维了
输出长度为四的向量,接softmax分类

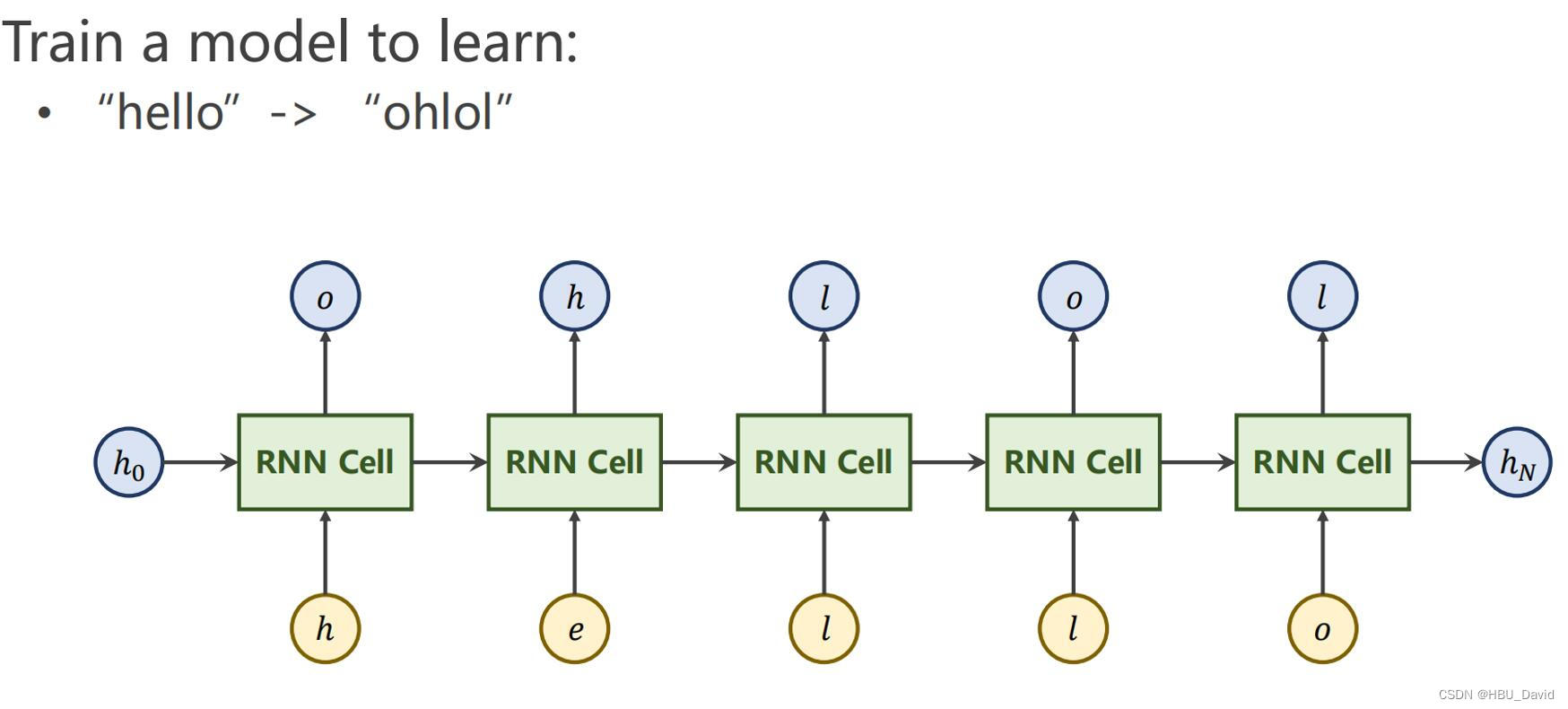
代码是依据视频中内容写的,但有两处我觉得改成这样更好一些
并且注意targrt不用换成独热码
labels=torch.LongTensor (y_data ).view(-1,batch_size )s=[idx2char[i] for i in idx]最后代码
使用RNNCell
import torch
batch_size = 1
num_layers=1
input_size = 4
hidden_size = 4
seq_len=5
idx2char=['e','h','l','o']
x_data=[1,0,2,2,3]
y_data=[3,1,2,3,2]
one_hot_lookup=[[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot=[one_hot_lookup[x] for x in x_data ]
inputs=torch.Tensor(x_one_hot ).view(seq_len ,batch_size ,input_size )
labels=torch.LongTensor (y_data ).view(-1,batch_size )
class Model(torch.nn.Module ):
def __init__(self,input_size,hidden_size,batch_size):
super(Model ,self).__init__()
self.batch_size =batch_size
self.input_size=input_size
self.hidden_size=hidden_size
self.rnncell=torch.nn.RNNCell (input_size= self.input_size ,hidden_size= self.hidden_size )
def forward(self,input,hidden):
hidden=self.rnncell(input,hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size,self.hidden_size )
net=Model(input_size,hidden_size,batch_size )
criterion=torch.nn.CrossEntropyLoss ()#交叉熵
optimizer=torch.optim.Adam (net.parameters() ,lr=0.1)#优化器
for epoch in range(15):
loss=0
optimizer.zero_grad()
hidden=net.init_hidden()
print('Predicted string:',end='')
for input,label in zip(inputs,labels):
hidden=net(input,hidden)
loss+=criterion(hidden,label)
_, idx = hidden.max(dim=1)
s=[idx2char[i] for i in idx]
print(s,end='')
loss.backward()
optimizer.step()
print(',Epoch [%d/15] loss=%.4f'%(epoch +1,loss.item()))

使用RNN
import torch
batch_size = 1
num_layers=1
input_size = 4
hidden_size = 4
seq_len=5
idx2char=['e','h','l','o']
x_data=[1,0,2,2,3]
y_data=[3,1,2,3,2]
one_hot_lookup=[[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot=[one_hot_lookup[x] for x in x_data ]
inputs=torch.Tensor(x_one_hot ).view(seq_len ,batch_size ,input_size )
labels=torch.LongTensor (y_data )
class Model(torch.nn.Module ):
def __init__(self,input_size,hidden_size,batch_size,num_layers=1):
super(Model ,self).__init__()
self.num_layers=num_layers
self.batch_size =batch_size
self.input_size=input_size
self.hidden_size=hidden_size
self.rnn=torch.nn.RNN (input_size= self.input_size ,hidden_size= self.hidden_size ,num_layers= num_layers )
def forward(self,input):
hidden=torch.zeros(self.num_layers ,self.batch_size ,self.hidden_size )
out,_=self.rnn(input,hidden)
return out.view(-1,self.hidden_size )
def init_hidden(self):
return torch.zeros(self.batch_size,self.hidden_size )
net=Model(input_size,hidden_size,batch_size ,num_layers )
criterion=torch.nn.CrossEntropyLoss ()#交叉熵
optimizer=torch.optim.Adam (net.parameters() ,lr=0.1)#优化器
for epoch in range(15):
optimizer.zero_grad()
outputs=net(inputs )
loss=criterion (outputs ,labels )
loss.backward()
optimizer.step()
_,idx=outputs .max(dim=1)
idx=idx.data.numpy()
print('Predicted :',''.join([idx2char [x]for x in idx]),end='')
print(',Epoch [%d/15] loss=%.4f'%(epoch +1,loss.item()))

从结果来看,两者都在第6轮得到了ohlol,效果相差不大,但是RNN比RNNcell写起来更简单一些。
这个与RNNCell相比,里面过程少了个循环,直接内置了,不用自己写了

每一时刻输入(字母)都有对应的输出(概率),这个与上面那道题的区别就是有一个把词转换成张量的步骤,最后由查表换成词。其他的在定义数的时候注意一下维度就可以了。
3. “编码器-解码器”的简单实现

seq2seq 是由 google 团队提出的一种序列到序列的模型,它是一种 encoder-decoder 结构,即编码器-解码器结构,它将输入和输出分成两个部分来处理,首先 encoder 负责编码 input ,输出一个中间向量 w ,然后将 w 作为 decoder 的输入进行解码,输出一个序列 output 。
输出是希望出现的下一个字符:

下边这个是两份输入,一份输出

import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as Data
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
letter = [c for c in 'SE?abcdefghijklmnopqrstuvwxyz']#S是开始符号,E是结束符号,?表示不够的加的<pad>
letter2idx = {n: i for i, n in enumerate(letter)}
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
# Seq2Seq Parameter
n_step = max([max(len(i), len(j)) for i, j in seq_data]) # max_len(=5)不够补pad
n_hidden = 128
n_class = len(letter2idx) # classfication problem,实际上是每个字符分类问题
batch_size = 3
def make_data(seq_data):
enc_input_all, dec_input_all, dec_output_all = [], [], []
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + '?' * (n_step - len(seq[i]))
enc_input = [letter2idx[n] for n in (seq[0] + 'E')] # ['m', 'a', 'n', '?', '?', 'E']
dec_input = [letter2idx[n] for n in ('S' + seq[1])] # ['S', 'w', 'o', 'm', 'e', 'n']
dec_output = [letter2idx[n] for n in (seq[1] + 'E')] # ['w', 'o', 'm', 'e', 'n', 'E']
enc_input_all.append(np.eye(n_class)[enc_input])#转换成独热码 大小[6,n_step+1,n_class]
dec_input_all.append(np.eye(n_class)[dec_input])
dec_output_all.append(dec_output) # not one-hot
# make tensor
return torch.Tensor(enc_input_all), torch.Tensor(dec_input_all), torch.LongTensor(dec_output_all)
enc_input_all, dec_input_all, dec_output_all = make_data(seq_data)
class TranslateDataSet(Data.Dataset):
def __init__(self, enc_input_all, dec_input_all, dec_output_all):
self.enc_input_all = enc_input_all
self.dec_input_all = dec_input_all
self.dec_output_all = dec_output_all
def __len__(self): # return dataset size
return len(self.enc_input_all)
def __getitem__(self, idx):
return self.enc_input_all[idx], self.dec_input_all[idx], self.dec_output_all[idx]
loader = Data.DataLoader(TranslateDataSet(enc_input_all, dec_input_all, dec_output_all), batch_size, True)
# Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.encoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # encoder
self.decoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # decoder
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, enc_input, enc_hidden, dec_input):
enc_input = enc_input.transpose(0, 1)#把banchsize放在第二位
dec_input = dec_input.transpose(0, 1)
_, h_t = self.encoder(enc_input, enc_hidden)
outputs, _ = self.decoder(dec_input, h_t)
model = self.fc(outputs)
return model
model = Seq2Seq().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(5000):
for enc_input_batch, dec_input_batch, dec_output_batch in loader:
h_0 = torch.zeros(1, batch_size, n_hidden).to(device)
(enc_input_batch, dec_intput_batch, dec_output_batch) = (
enc_input_batch.to(device), dec_input_batch.to(device), dec_output_batch.to(device))
pred = model(enc_input_batch, h_0, dec_intput_batch)
pred = pred.transpose(0, 1)
loss = 0
for i in range(len(dec_output_batch)):
loss += criterion(pred[i], dec_output_batch[i])
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Test
def translate(word):
enc_input, dec_input, _ = make_data([[word, '?' * n_step]])
enc_input, dec_input = enc_input.to(device), dec_input.to(device)
hidden = torch.zeros(1, 1, n_hidden).to(device)
output = model(enc_input, hidden, dec_input)
predict = output.data.max(2, keepdim=True)[1]
decoded = [letter[i] for i in predict]
translated = ''.join(decoded[:decoded.index('E')])#包含原始decoded字符串中的所有字符,直到第一个'E'字符的出现。它不包含'E'字符本身。
return translated.replace('?', '')
print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('up ->', translate('up'))

看起来效果很好,但是测试时用没给他喂过的单词就不行了

输出的不是zhang,而是boy
4.简单总结nn.RNNCell、nn.RNN(关于banch_size和num_layers具体理解可以看最后补充)
总体来看就是这个

再深入理解一下:
nn.RNN
实例化:
torch.nn.RNN(self, input_size, hidden_size, num_layers=1, nonlinearity='tanh')
input_size指的是输入的神经元个数,hidden_size是指隐藏层的神经元个数,num_layers指堆叠了多少rnn

前向传播的输入:
input:when batch_first=False:句子长度(多少个时刻),多少个banch(多少个rnn一块),一个词多大的向量表示。
h_0:那些个隐藏层的初始值(因为初始没有上一时刻的输入):层数,批数,每个隐藏层的个数
返回值:
h是最后一个时间戳上面的所有memory的状态(就是每一批每一层的隐藏层每一个神经元的输出值)
out是所有时间戳上面最后一个memory的状态(每个时间每一批最后面那层的隐藏层的神经元的输出值)

RNNCell
torch.nn.RNNCell(input_size, hidden_size, bias=True, nonlinearity='tanh', device=None, dtype=None)

这个就是一个计算单元,就是某一时刻的几批数进行一层rnn
同一层共用一个nn.RNNCell,多层的时候就要建立多个nn.RNNCell。
5.谈一谈对“序列”、“序列到序列”的理解
序列:有先后次序的一组(有限或无限多个)数据。
序列到序列模型,也就是课本里的异步的序列到序列模式
seq2seq 是由 google 团队提出的一种序列到序列的模型,它是一种 encoder-decoder 结构,即编码器-解码器结构,它将输入和输出分成两个部分来处理,首先 encoder 负责编码 input ,输出一个中间向量 w ,然后将 w 作为 decoder 的输入进行解码,输出一个序列 output 。
序列到序列任务往往具有以下两个特点:
1. 输入输出时不定长的。比如说想要构建一个聊天机器人,你的对话和他的回复长度都是不定的。
2. 输入输出元素之间是具有顺序关系的。不同的顺序,得到的结果应该是不同的,比如“不开心”和“开心不”这两个短语的意思是不同的。
编码器:将句子编码成一个能够映射出句子大致内容的固定长度的向量。
解码器:解码器节点会使用这个向量作为隐藏层输入和一个开始标志位作为当前位置的输入。得到的输出向量能够映射成为我们想要的输出结果,并且会将映射输出的向量传递给下一个展开的RNN节点。

强调一下关于对解码器的输入
一种是投入正确输出的输入。也被称为teacher force输入,即每一个节点的输入都为上一个节点正确的输出。可以避免前面一个节点出错导致后面连续累计错误。
另一种按照上一个节点输出作为下一个节点输出的训练情况。在实际生成测试的过程中,我们不可能知道正确的数据是什么,因而难以避免这种错误累计的情况。后期加入这种投入的方式。结合二者进行训练,这样可以使得生成的效果更好。
6.总结本周理论课和作业,写心得体会
理论课总结:
(1)

在理论课上着重讲了SRN,(当时说只有一层隐藏层没有感觉,下面就由多层隐藏层的可以看一下),在作业里也用代码实现了一下
(2)应用到机器学习




作业总结:在这次作业里首先实践了一下SRN,主要学习了RNN和RNNCell,然后实现了同步和异步的序列到序列的代码。
视频的最后补充
词转换为向量Embedding

线性层(*里可以填好几个数,那些个数输入输出只要相等即可)

交叉熵损失(前头也可以输入多个维度,最后求和就行)

接下来就是简单介绍LSTM和GRU(这个没咋听懂,估计之后会讲,再好好理解一下)
简单理解就是很多线性层


关于np.dot()函数(之前总结过,在总结一次吧):
np.dot(a, b):
(1)a为一维的向量,b为一维的向量:向量点积(对应相乘再相加)
(2)一个向量和一个矩阵相乘,这个向量会自动转换为一维矩阵进行计算。当其中有一个是矩阵时(包括一维矩阵),dot便进行矩阵乘法运算,一维向量的shape是(5, ), 而一维矩阵的shape是(5, 1)。
(3)a和b都是二维矩阵,进行的矩阵乘法运算
【补充】
多层RNN:
调用nn.rnn时有num_layers,在想怎么,还能不是1,结果真有,多层堆叠在一起:

关于batch_size:想成同时有batch_size个RNN在处理数据

在问题3中,使用的是对每个字母采用独热编码,每个单词是一个序列,在输入的单词里面字母个数不确定的时候,长度设为最长的那个长度,不够的补‘?',在里面使用了两次rnn,并且关注第一个rnn的最后一个h和第二个rnn的out。
但是要注意传数的时候可以看成那么多个rnn,但是如果是参数的话还是想成只有一个。
这些代码的主要步骤,首先弄到合适格式的数据集,上面的例子中大部分用的是独热码,在问题二里,博主也提到了embodding的使用,接下来就是建立模型,定义损失函数,优化器,训练。
感觉这个和全连接神经网络差不多,就是权重多了个。 定义的网络是一块,输入的数是多批多时刻。其实就是定义数的时候想着点哪些维度,剩下的时候就不用想那么多了
最后几步的梳理:通过线性层把他弄成类别个数个,然后是每类的概率,标签直接是那类,不用弄成独热码,直接交叉熵函数求损失
心得体会:
这周感觉学到了很多东西,但与循环神经网络初次相识,还有点陌生,感觉自己还没有梳理的特别系统,就感觉很杂,希望自己“悟得越来越透吧"
参考:
【23-24 秋学期】NNDL 作业9 RNN - SRN-CSDN博客
https://blog.csdn.net/skywalker1996/article/details/82462499















 4391
4391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









