






实际上这是一篇拖了很久才写出来的文章,算是对自己前段时间对于爬虫学习的总结吧。
速度: ☆☆☆ #速度较快。免费代理池在深夜最高速度可达8000 items / min,正常速度约为800~1200 items/min左右,且没有做代理复用操作。在一定程度上缓存并复用代理将会在一定程度上提升性能。
数据完整性: ☆☆ #完整性较差。无法保证数据完整写入。在扫尾工作时随机丢失大量数据,试了各种方法后均无法解决。
本机性能开销: ☆☆☆☆☆ #开销极大。运行时使用了10P*16T运行爬虫,可完全跑满7700HQ@3.4gHz(大量操作用于和Redis操作,等待Redis反馈等。)
最终数据量:约200,000 / 24h
原先使用的方式是Docker+Splash解析b站用户空间,但Splash对性能消耗极大,实际运行速度只有约150items / min(对比直接访问api:800~1200items / min),遂采用直接访问ajax的方式获取数据。数据展示:

行数1382231,截止uid同样为1382231,但数据并不完整,丢失数据集中在结尾处,我通过设置起止UID反复运行爬虫来补全数据。
前期准备:
分析网页个人信息首页可以得到B站关于用户信息的API(截止2019.4可用):
生日,ID,签名,等级,大会员状态 = "https://api.bilibili.com/x/space/acc/info?mid={uid}"
收藏夹状态 = "https://api.bilibili.com/medialist/gateway/base/created?pn=1&ps=10&up_mid={uid}"
关注数,粉丝数 = "https://api.bilibili.com/x/relation/stat?vmid={uid}"
直播间信息 = "https://api.live.bilibili.com/room/v1/Room/getRoomInfoOld?mid={uid}"
投稿信息 = "https://api.bilibili.com/x/space/navnum?mid={uid}"
总计播放量 = "https://api.bilibili.com/x/space/upstat?mid={uid}"
视频信息 = "https://api.bilibili.com/x/web-interface/archive/stat?aid={aid}"
通过av号获取作者 = "https://api.bilibili.com/x/tag/archive/tags?aid={aid}"接着,创建格式如下的数据库,并设置uid字段为唯一主键:
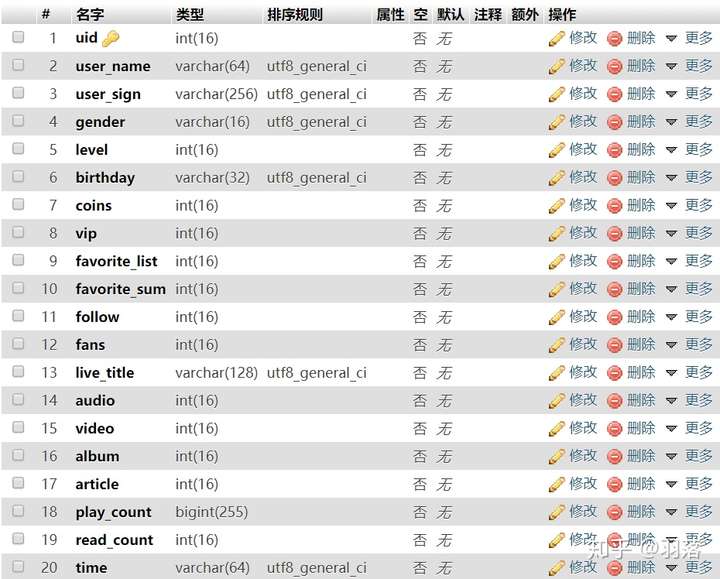
在DataBaseSettings.ini中以json格式写入数据库配置:
{
"default": {
"HOST": "***.***.***.***",
"PORT": 10060,
"DB": "bilibili_user_info",
"USER": "bili_user_Robot",
"PASSWORD": "PASSWORD",
"CHARSET": "utf8"
}
}并在settings.py中写入读取语句:
import json
with open("DataBaseSettings.ini","r") as fp:
sqlsetting = json.loads(fp.read())["default"]由于使用了Redis来进行代理暂存和请求分发,所以还需要写入Redis地址:
REDIS_HOST = "192.168.229.128"
REDIS_PORT = 6379模块划分:
- MainProcess.py:主模块。负责启动并维护所有子进程,负责请求生成和请求速度控制、请求计数、维护数据完整性、控制所有进程存活状态检测和退出等。
- CrawlProcess.py:主要的工作进程。负责启动并维护所有子线程,监控子线程工作状态,子线程执行数据爬取,数据格式化,并将格式化完成的数据提交给数据存储进程,由数据存储进程统一插入数据库。
- requests_api.py:包装requests.get,以简单的方式通过代理访问网站。
- mysql_api.py :以子进程方式启动。负责接收数据并缓存,缓存满或接收EXIT时存储至MySQL。
- settings.py:保存项目的配置信息,例如进程数/线程数、MySQL配置、Redis配置、代理池配置等。
问题分析:
在多进程/多线程、高负载的情况下,如何保证数据的完整性?
- 开启进程管道,多个进程统一将爬取到的数据通过管道传递给数据库进程,由数据存储进程负责执行数据插入。(但事实证明并不需要这么做。单机MySQL可以轻松应对每秒130+的数据插入。证明对SQL的认识存在不足。
搭建免费代理池,如何保证代理可用性?
- 很遗憾,免费代理的可用性是无法保证的。即便是Github上大量代理池实现采用的打分制,也依旧无法代理的质量。我采用的方式是开启大量线程(大量>128)对库中存在的线程进行验证,当不可用代理达到一定比例时立刻开始下一轮验证,否则等待一次循环时间。
在有大量子进程,如何保证所有子进程正常退出?
- 我采用的方式是通过管道发布EXIT信号,子进程在接收到EXIT信号后,将等待所有子线程执行完当前正在处理的请求,将所有请求提交至管道后退出自身,主进程等待数据库插入完毕,存储Redis中剩余的请求队列,展示统计信息,最后退出进程。
如何对请求计数?
- 我采用的方式是每个进程每秒向主进程汇报一次工作状态,由主进程统一收集计数并打印统计信息。
如何处理不存在的用户?
- 为了方便统计,在遇到不存在的用户时,直接生成一个所有数据项为-404、生日为1970-01-01的错误数据项插入数据库。
退出时如何保证数据插入完毕?
- 我采用的方式非常粗暴:
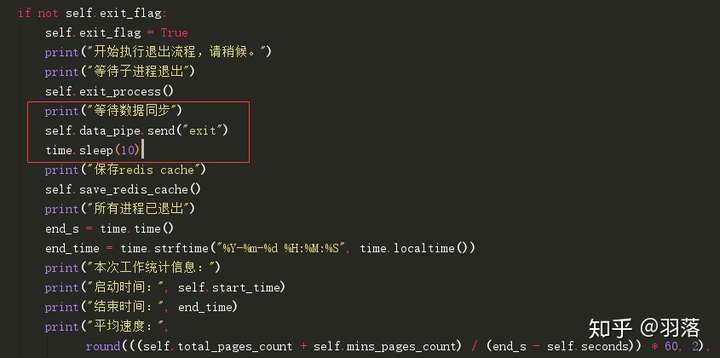
对数据存储进程发布exit信息,然后等待10秒。
实际上有更优雅的实现方式,例如在插入完成后通过回调对 指定端口发送消息。
重难点:
- 多进程/多线程、高负载情况下的数据同步问题:实际上到最后我也没能完全解决这个问题,在程序结束时依旧会出现大量数据丢失的情况。
- 对于代理池的维护问题:由于代理池没有使用统一的api,而是直接从Redis中获取,因此无法解决多个进程使用同一个代理地址导致代理快速被ban、多个进程使用同一个失效代理导致浪费大量时间等问题。这个问题可以通过搭建一个统一、成熟的API来解决。例如常见的通过轻量级http服务器提供对代理池的访问。
- 空数据、无效数据处理:前文提到,直接生成404数据项插入数据库。
- 脏数据数据:由于要访问5个不同的api才能拼接成一条数据,所以如果代理中途失效,就会出现脏数据。我的解决方案是每次都重新获取一个代理,直到访问成功为止(更好的办法是,存储使用的代理,直到代理失效时才重新获取)。
性能瓶颈:
最大的性能瓶颈就是对Redis的反复访问。

简单粗暴没有任何优化的访问方式
可以看到在while True这里,仅仅只是粗暴的get_proxy后立即访问,捕获访问异常并重试,直到访问成功为止,没有做代理保存复用等操作,性能开销极大。
代理质量也是原因之一。
由于免费代理的质量非常低下,访问成功率可能不足20%。在10c*16t下正常速度只能达到1k/min左右的访问速度(每条数据由5个url组成,实际上应该*5),相当于每个线程均摊下来访问速度只有可怜的10s/条,这样导致的不断获取代理并重试是消耗计算性能的罪魁祸首。
当然,作为一个学习性质的练手项目(划重点:一分钱没花),没有adsl拨号主机/高质量代理池,这样的速度已经足够了(原计划5kw数据)。
额外的:
由于腾讯云没有提供大数据库的导出/备份下载功能,我编写了数据库导出为csv的脚本,源码同样附在下方。
在OrsPced的Github,你能阅读到项目的源码。
在export文件夹下,你能看到数据库导出为csv的脚本。
在Result文件夹下,你能看到最终生成的csv文件。每50w行分页,最终有三个csv文件,每个的大小约为48m。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









