







定义
正则表达式就是为了处理大量的文本|字符串而定义的一套规则和方法
对于系统管理员来讲,正则表达式贯穿在我们的日常运维工作中,无论是查找某个文档,抑或查询某个日志 文件分析其内容,都会用到正则表达式 Linux中的正则表达式,常应用正则表达式的命令是grep(egrep),sed,awk。
接下来我们主要讲解grep的用法
grep主要参数
-c:只输出匹配行的计数。
-I:不区分大 小写(只适用于单字符)。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及 行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
-w:匹配指定字符串
正则表达式主要参数:
\: 忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行。
$: 匹配正则表达式的结束行。
\<:从匹配正则表达式的行开始。
\>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求 。
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
. :所有的单个字符。
* :前面的一个字符重复0到多次
' ' :强引用,引号内的内容不变
" " :弱引用,变量会替换
6项常用特殊符号
[[:alnum:]] :代表英文大小写字符及数字,即 0-9, A-Z, a-z
[[:alpha:]] :代表任何英文大小写字符,即 A-Z, a-z
[[:space:]] :任何会产生空白的字符,包括空白键, [Tab] 等等
[[:digit:]] :代表数字,即 0-9
[[:lower:]] :代表小写字符,即 a-z
[[:upper:]] :代表大写字符,即 A-Z
接下来我们用一些测试题来举例grep的具体用法
1.显示/etc/passwd文件中不以/bin/bash结尾的行
也可用代码:cat /etc/passwd | grep -v “:/bin/bash$”
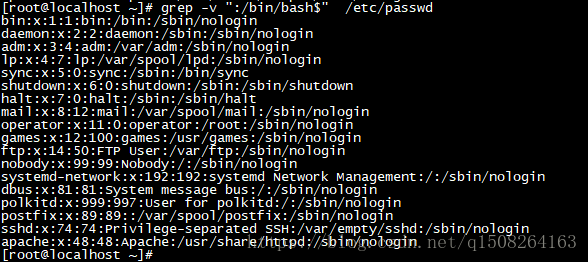
2.显示用户zgs默认的shell程序

3.找出/etc/passwd用户名 和shell同名的行

其中,正则表达式"\(^.*\)\>.*\/\$"。该题用到了后向引用。一定要注意,后向引用引用的是前
面的“()”中匹配到的字符。 并不是“()”中的模式。
\(^.*\)表示匹配以任意字符串为行首的字符串;
\(^.*\)\>.*表示匹配以任意字符串为行首,并且后面为任意字符(除了\n);
\1表示“\(^.*\)”匹配到的字符串;
\1$表示匹配以“\(^.*\)”匹配到的字符串为行尾;
\/表示一个“/”;
\(^.*\)\>.*\/\1$表示行首行尾相同,并且,行尾所匹配的字符串前面还有一个“/”
4.找出ifconfig命令结果中的1-255之间的数字

5.显示ifconfig命令结果中所有IPv4地址
或
grep -E == egrep
egrep为grep的扩展正则表达
扩展正则表达式就是在基本正则表达式的基础上,增加了一些元数据


| 元数据 | 意义和范围 |
|---|---|
| + | 重复前面字符1到多次 |
| 匹配god,good,goood等字符串,grep -nE go+d’ file | |
| ? | 匹配0或1次前面的字符 |
| 匹配gd,god,grep -nE ‘go?d’ file | |
| l | 或or的方式匹配多个字符串 |
| 匹配god或者good,grep -nE’god | |
| () | 匹配整个括号内的字符串,原来都是匹配单个字符 |
| 搜索good或者glad,grep -nE 'g(oo | |
| * | 前面的字符重复0到多次 |
扩展:
sort 以行为单位对多行数据进行排序:
常用参数及意义
-n: 数值排序
-r :降序
-t :字段分隔符
-k :以哪个字段为关键字进行排序
-u :排序后相同的行只显示一次
-f :排序时忽略字符大小写














 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









