










Generative Adversarial Registration for Improved Conditional Deformable Templates 论文
- 这是一篇21年5月份的配准论文
- 源码链接
- 源码是用
tf2.*版本写的,整体来说可读性可以,就是基于前人的GAN与VXM(都有相关代码),加入了自己的创新以及对自己数据的适配性,但是没有数据。其中的一些细节我会在下面的介绍中加入我的理解
- 源码是用
1. 介绍
在本文中提出通过生成对抗网络来估计带有解剖结构的尖锐模板图像。核心是除了较高的配准精度外,配准后的图像分布尽可能与真实图像分布相似(这部分我理解不到位,这是指直方图吗?)
三个网络:
generator netregistration netdiscriminator net
主要贡献:
- (1) 可变形模板生成和配准的生成对抗方法(也就是用
GAN做的) - (2) 构建不同挑战性数据集的条件模板,包括早产儿和足月新生儿的神经图像、患有和不患有亨廷顿氏症(翻译的,我也没详查什么症状)的成年人以及真实世界的面部图像
- (3) 在中心性和可解释性方面对现有模板构建方法进行改进,并显著增加条件特异性(对应文中一直提到的一个词
conditional)
2. 相关工作
2.1 Generative adversarial networks
对抗正则化(adversarial regularizers)补偿高频细节信息,提高重建的视觉保真度(visual fidelity),对于条件生成网络,与属性向量连接到输入的方法相比,使用学习到的条件比例尺和位移调制每个特征地图可以显著改善图像合成。
2.2 Deformable image registration
目的就是配准,简单介绍了已有的配准框架,主要分为光流配准和微分形态学配准
2.3 Generative adversarial registration (部分没理解)
提到了19年前用GAN做的配准的相关论文,指出本文突出点在于不仅仅是做配准,还有专注于模板(templates),使用GAN网络时考虑协方差,处理3D体素时不进行模拟(这是与18年论文进行对比说的),只关注模板的真实移动。
2.4 Template estimation
总的目的来说是对图像集进行标准化分析。由于对齐图像的图像和形状平均会导致图像的模糊,流行的配准框架使用拉普拉斯锐化执行特殊的模板后处理,这可能会无意中产生难以置信的结构,并且可能仍然无法在高度可变的群体中解析结构。此外,如果给定了感兴趣的协变量,通过将数据集划分为感兴趣的子群体并为每个子群体单独构建模板,特殊分析可能会忽略共享的信息。通过构建时空模板,更有原则的方法明确地解释了年龄和潜在的其他协变量,并已在儿童和成人神经影像中得到广泛验证。(这与文中的数据有关)
整体来说,分为两部分: 无条件的
VXM(VoxelMorph)与有条件的VXM(VoxelMorph)。前者与VXM无区别,后者是引入了属性向量输入卷积解码器生成一个条件模板,然后通过配准网络进行类似的端到端训练。
3. 方法
生成网络((a)和(b))生成一个条件模板,并将其变形为由鉴别器©评估的参考图像。该框架在正则化配准和对抗损失下进行端到端训练,以激励配准的准确性和模板的真实性。

图注释: 模板生成网络(a)用卷积解码器处理一组学习到的参数,卷积解码器从输入条件中学习到特征仿射参数,从而生成一个条件模板。配准网络(b)将生成的模板扭曲成随机采样的固定图像。训练鉴别器©来区分移动的合成模板和随机采样图像,从而激励实际图像和条件特异性。
3.1 Template Generation Sub-network
这一部分主要是引入 Film机制(Feature-wise Linear Modulation, 特征线性调制),即学习到对特征图进行一个仿射变换,源自论文 FiLM: Visual Reasoning with a General Conditioning Layer
提出该方法的论文是针对于图像问答问题的,在解决 few-shot 的问题上有很好的效果
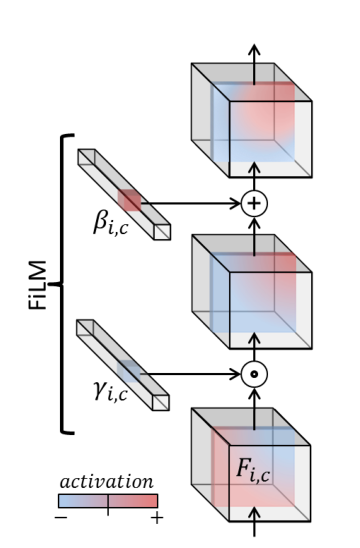
先简单说下其思想,主要就是学习两个参数 γ(z) 和 β(z),分别代表缩放因子和平移因子。计算公式如下:
F
i
L
M
(
h
c
i
)
=
γ
c
i
(
z
)
∗
h
c
i
+
β
c
i
(
z
)
FiLM(h^i_c) = γ^i_c(z) ∗ h^i_c+β^i_c(z)
FiLM(hci)=γci(z)∗hci+βci(z)其中 z 是自己添加的条件张量。对于FiLM这篇论文来说源码中的 z 是问题转换的张量,对于本篇配准论文中 z 是属性张量,源码中是与年龄相关的一个张量。
论文中说这种方式的好处是通过在每一层进行调节(与条件VXM不同,条件的唯一来源是输入),模板网络具有更大的能力来适应具有高可变性的数据集,并合成更合适的模板。条件向量 z 由4层MLP(64通道)处理作为最终的条件张量再输入 FiLM,然后是5个残差模块,经过几个卷积层,然后结合图像,这时候才是 unet 的输入。
个人可以认为人为加入一些特殊张量查看中间特征图的区别,就像一个引导性信息。其表达方式又觉得像是
cGAN中的将类别作为嵌入信息(embedding)与图像输入cat之后作为整体的输入。
3.2 Registration Sub-network
Unet 输出一个配准形变场, STN 对浮动图像进行形变得到配准图像
3.3 Discriminator Sub-network
五层全卷积的判别器,使用了 PatchGAN,就是将一张图像分成多个的小块进行判别,最后对结果取和判断正负(假设最终判别为多个正值和多个负值,加起来如果为正那图像就为真实图像,反之为生成图像),这样能使GAN更加稳定,印象中是 Pix2Pix 提出来的。
在判别器的设计中引入投影法(还真没看过相关文章,也不是很了解)
f
(
x
,
y
;
θ
)
=
y
T
V
φ
(
x
;
θ
Φ
)
+
ψ
(
φ
(
x
;
θ
Φ
)
;
θ
Ψ
)
f(x, y;θ) = y^TV φ(x;θ_Φ) + ψ(φ(x;θ_Φ);θ_Ψ)
f(x,y;θ)=yTVφ(x;θΦ)+ψ(φ(x;θΦ);θΨ)
x x x是网络输入, y y y是条件张量,我的理解是在cGAN中是类别标签的嵌入张量,在本文中是年龄信息。 f ( x , y ; θ ) f(x, y;θ) f(x,y;θ)为预激活判别器输出, θ = { V , θ Φ , θ Ψ } θ=\{V, θ_Φ, θ_Ψ\} θ={V,θΦ,θΨ} 是要学习的参数, V V V 是 y y y 的嵌入矩阵, φ ( x , θ Φ ) φ(x, θ_Φ) φ(x,θΦ)是给定 x x x 条件下的网络输出, ψ ( . , θ Ψ ) ψ(., θ_Ψ) ψ(.,θΨ) 是 φ ( x , θ Φ ) φ(x, θ_Φ) φ(x,θΦ) 的标量函数。
这一公式仅适用于类别属性或连续属性,不适用于两种条件反射类型,这使得它不适用于同时对年龄(连续)和性别(类别)等属性感兴趣的神经成像。但是发现下式可近似这种分析
f ( x , y ; θ ) = y c a t T V c a t φ ( x ; θ Φ ) + y c o n T V c o n φ ( x ; θ Φ ) + ψ ( φ ( x ; θ Φ ) ; θ Ψ ) f(x, y;θ) = y^T_{cat} V_{cat}φ(x;θ_Φ) + y^T _{con}V_{con}φ(x;θ_Φ) + ψ(φ(x;θ_Φ);θ_Ψ) f(x,y;θ)=ycatTVcatφ(x;θΦ)+yconTVconφ(x;θΦ)+ψ(φ(x;θΦ);θΨ)
其中 cat 和 con 下标分别表示类别属性和连续属性。
3.4 Loss Functions
- G & Restration net
- 常规的GAN网络的G损失
- image matching term
- penalties encouraging deformation smoothness and centrality
- an adversarial term encouraging realism
- LNCC(NCC本来应该是协方差,就是vxm中的cross没有自乘)
# 源码中的损失,这部分我再研究研究源码,搞这么多约束,最后结果还是和adv-vxm差不多
- gan_loss: 常规损失
- smoothness_loss: 平滑损失
- magnitude_loss:
- similarity_loss: 相似度损失
- moving_magnitude_loss:
- tv_loss:
gan_loss, smoothness_loss, magnitude_loss, similarity_loss, moving_magnitude_loss, tv_loss,
- D net
- 常规的GAN网络的D损失
total_loss = 0.5*(gan_fake_loss + gan_real_loss)
L = L L N C C + λ r e g R e g ( ϕ ) + λ G A N L G A N L = L_{LNCC}+λ_{reg}Reg(ϕ)+λ_{GAN}L_{GAN} L=LLNCC+λregReg(ϕ)+λGANLGAN
λ G A N = 0.1 λ_{GAN}= 0.1 λGAN=0.1, λ r e g = [ λ 1 , λ 2 , λ 3 ] = [ 1 , 1 , 0.01 ] λ_{reg}= [λ_1, λ_2, λ_3] = [1,1,0.01] λreg=[λ1,λ2,λ3]=[1,1,0.01]
3.5 GAN Stabilization
- 谱归一化,也就是使得网络中的W参数满足
1-Lipschitz条件,在之前的博文中提到了 - 梯度惩罚,可以查看
WGAN-GP - 可微增强,基于强度的判别器增强(亮度/对比度/饱和度)最终导致神经成像数据集的训练崩溃,但发现可以改善2D RGB人脸数据集的训练。(可能是先拿人脸数据测试的吧,不然谁会去试呐…)
4. 实验
4.1 数据
实验集中于具有挑战性的数据集的不同形态模板构建。所有前景/大脑提取都是通过阈值分割提供的分割标签来执行的。所有神经影像均裁剪成分辨率为160 × 192 × 160的中央视场视图。
- dHCP
- Predict-HD
- FFHQ-Aging, 人脸图像被用作实验载体(论文是这么说的)
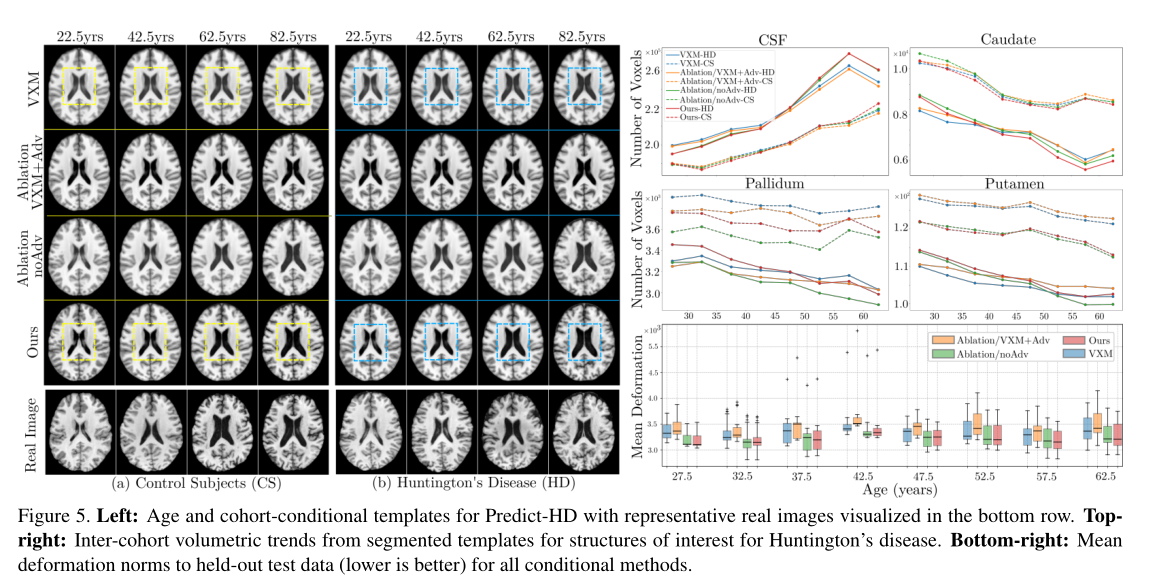
4.2 结果

4.3 分析
从指标上来说,与之前的方法结果无太大区别,但是定性分析的话,从结果图上还是有细微区别的,方法都有明显的优势,这取决于它们的预期用途。
5. 结论
后面还有投影法的推导,完后再细看一下,近期看论文总是缺乏细节,有时候看过就忘了,因此记录一下,如有理解错误和不到位的地方还请指出,不胜感激。整篇论文看完其实能借鉴的地方也就一丢丢,关键是怎么用,现在硕士想毕个业,难,靠配准毕业,感觉更难。都说配准很难,要我说,太**难了,深度学习还是有限的,要想在配准领域有突破,还需要数学上的突破,总之个人是没那个能力。希望配准在医学领域有所发展吧。















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









