







线性回归与逻辑回归
一. 线性回归 (Linear model)
1. 引入
分类中最直白的就是二分类,而且为线性可分。就以房价预测为例,价格的变动与面积,房间个数有关,那么写出其基本形式:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
h
θ
(
x
)
=
s
∑
i
=
0
n
θ
i
x
i
=
θ
T
x
h_θ(x)=θ_0 + θ_1x_1+θ_2x_2 \qquad h_θ(x)=s \sum^{n}_{i=0}θ_ix_i=θ^Tx
hθ(x)=θ0+θ1x1+θ2x2hθ(x)=si=0∑nθixi=θTx
x
x
x 表示特征,
θ
θ
θ 表示权重,
θ
0
θ_0
θ0 表示偏置
2. 损失函数
任何计算公式都是有误差的,因此我们就要求得最小误差下的
θ
θ
θ,我们把
x
x
x 到
y
y
y 的映射函数
f
f
f 记作
θ
θ
θ 的函数
h
θ
(
x
)
h_θ(x)
hθ(x),定义 损失函数 (cost function) 为 :
J
(
θ
0
,
θ
1
,
⋯
 
,
θ
n
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J(θ_0,θ_1,\cdots ,θ_n) = \frac{1}{2m} \sum^{m}_{i=1}(h_θ(x^{(i)})-y^{(i)})^2
J(θ0,θ1,⋯,θn)=2m1i=1∑m(hθ(x(i))−y(i))2
此函数用来描述
h
θ
(
x
(
i
)
)
h_θ(x^{(i)})
hθ(x(i)) 与对应的
y
(
i
)
y^{(i)}
y(i) 的接近程度,
1
2
\frac{1}{2}
21 只是系数,便于求导,并无影响。目前的问题转换为求满足最小
J
(
θ
)
J(θ)
J(θ) 的
θ
θ
θ
3. 梯度下降
梯度下降是逐步最小化损失函数的过程,我们对
θ
θ
θ 设定一个随机初值
θ
0
θ_0
θ0,然后带入下式进行迭代:
θ
:
=
θ
−
α
d
d
θ
J
(
θ
)
θ : \ =θ-α \frac{d }{d θ}J(θ)
θ: =θ−αdθdJ(θ)
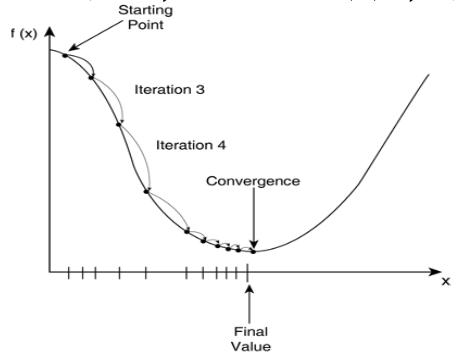
式中 α α α 为学习率,即每一步向下的跨度,学习率可以影响收敛速度,但选取过大容易得到局部最优解。
4. 最小二乘法
最小二乘法是直接利用矩阵运算得到
θ
θ
θ ,假设n个特征(变量)
x
n
x_n
xn,用矩阵表示
X
X
X,结果为
y
⃗
\vec{y}
y,可以得出
θ
=
(
X
T
X
)
−
1
X
T
y
⃗
θ=(X^TX)^{-1}X^T\vec{y}
θ=(XTX)−1XTy
详细推导请查看 最小二乘法求
θ
θ
θ。现实的数据中
X
T
X
X^TX
XTX 往往不是满秩矩阵,此时可解出多个
θ
θ
θ 使得均方误差最小化,选择输出解将由学习算法的归纳偏好决定,常见的做法是引入正则化项。
5. 拟合问题

如果我们特征过多,使得
J
(
θ
)
≈
0
J(θ) ≈0
J(θ)≈0,会对原数据拟合得非常好,但是预测效果会变差。我们引入正则化 (误差分析):
J
(
θ
0
,
θ
1
,
⋯
 
,
θ
n
)
=
1
2
m
[
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
J(θ_0,θ_1,\cdots ,θ_n) = \frac{1}{2m} [\sum^{m}_{i=1}(h_θ(x^{(i)})-y^{(i)})^2+λ\sum^{n}_{j=1}θ_j^2]
J(θ0,θ1,⋯,θn)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]
注意: λ λ λ 是需要自己设定得参数,太小容易过拟合,太大基本上不会拟合出决策边界。
二. 逻辑斯特回归
1. logistic回归
强调: logistic回归是本质仍然是线性回归,但它一种分类算法,因为有些连续值是根据阈值而分开,因此引入一个函数映射——sigmoid函数。
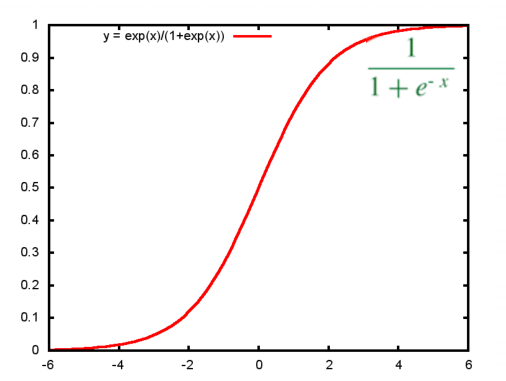
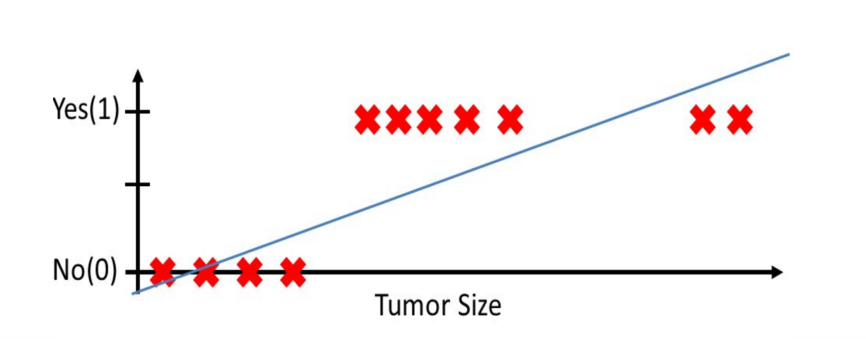
2. 逻辑斯特回归假设
h θ ( x ) = g ( θ T x ) g ( z ) = 1 1 + e − z h_{\theta}(x) = g(\theta^{T}x) \quad g(z)=\frac{1}{1+e^{−z}} hθ(x)=g(θTx)g(z)=1+e−z1
def sigmoid(z):
return(1 / (1 + np.exp(-z)))
这个函数在很多集成库中已有,尤其是在框架中直接调用 (正在学习tensorfow)
损失函数:
J
(
θ
)
=
1
m
∑
i
=
1
m
[
−
y
(
i
)
 
l
o
g
 
(
h
θ
 
(
x
(
i
)
)
)
−
(
1
−
y
(
i
)
)
 
l
o
g
 
(
1
−
h
θ
(
x
(
i
)
)
)
]
J(\theta) = \frac{1}{m}\sum_{i=1}^{m}\big[-y^{(i)}\, log\,( h_\theta\,(x^{(i)}))-(1-y^{(i)})\,log\,(1-h_\theta(x^{(i)}))\big]
J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]
向量化的损失函数 (矩阵形式):
J
(
θ
)
=
1
m
(
(
 
l
o
g
 
(
g
(
X
θ
)
)
T
y
+
(
 
l
o
g
 
(
1
−
g
(
X
θ
)
)
T
(
1
−
y
)
)
J(\theta) = \frac{1}{m}\big((\,log\,(g(X\theta))^Ty+(\,log\,(1-g(X\theta))^T(1-y)\big)
J(θ)=m1((log(g(Xθ))Ty+(log(1−g(Xθ))T(1−y))
def costFunction(theta, X, y):
m = y.size
h = sigmoid(X.dot(theta))
J = -1*(1/m)*(np.log(h).T.dot(y)+np.log(1-h).T.dot(1-y))
if np.isnan(J[0]):
return(np.inf)
return(J[0])
梯度
∂
J
(
θ
)
∂
θ
j
=
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\frac{\partial J(\theta)}{\partial\theta_{j}} = \frac{1}{m}\sum_{i=1}^{m} ( h_\theta (x^{(i)})-y^{(i)})x^{(i)}_{j}
∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))xj(i)
向量化的梯度
∂
J
(
θ
)
∂
θ
j
=
1
m
X
T
(
g
(
X
θ
)
−
y
)
\frac{\partial J(\theta)}{\partial\theta_{j}} = \frac{1}{m} X^T(g(X\theta)-y)
∂θj∂J(θ)=m1XT(g(Xθ)−y)
def gradient(theta, X, y):
m = y.size
h = sigmoid(X.dot(theta.reshape(-1,1)))
grad =(1/m)*X.T.dot(h-y)
return(grad.flatten())
3. 岭回归
带正则化项的损失函数
J
(
θ
)
=
1
m
∑
i
=
1
m
[
−
y
(
i
)
 
l
o
g
 
(
h
θ
 
(
x
(
i
)
)
)
−
(
1
−
y
(
i
)
)
 
l
o
g
 
(
1
−
h
θ
(
x
(
i
)
)
)
]
+
λ
2
m
∑
j
=
1
n
θ
j
2
J(\theta) = \frac{1}{m}\sum_{i=1}^{m}\big[-y^{(i)}\, log\,( h_\theta\,(x^{(i)}))-(1-y^{(i)})\,log\,(1-h_\theta(x^{(i)}))\big] + \frac{\lambda}{2m}\sum_{j=1}^{n}\theta_{j}^{2}
J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
向量化的损失函数
J
(
θ
)
=
1
m
(
(
 
l
o
g
 
(
g
(
X
θ
)
)
T
y
+
(
 
l
o
g
 
(
1
−
g
(
X
θ
)
)
T
(
1
−
y
)
)
+
λ
2
m
∑
j
=
1
n
θ
j
2
J(\theta) = \frac{1}{m}\big((\,log\,(g(X\theta))^Ty+(\,log\,(1-g(X\theta))^T(1-y)\big) + \frac{\lambda}{2m}\sum_{j=1}^{n}\theta_{j}^{2}
J(θ)=m1((log(g(Xθ))Ty+(log(1−g(Xθ))T(1−y))+2mλj=1∑nθj2
梯度
∂ J ( θ ) ∂ θ j = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j \frac{\partial J(\theta)}{\partial \theta_{j}} = \frac{1}{m}\sum_{i=1}^{m} ( h_\theta (x^{(i)})-y^{(i)})x^{(i)}_{j} + \frac{\lambda}{m}\theta_{j} ∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj
向量化
∂
J
(
θ
)
∂
θ
j
=
1
m
X
T
(
g
(
X
θ
)
−
y
)
+
λ
m
θ
j
\frac{\partial J(\theta)}{\partial \theta_{j}} = \frac{1}{m} X^T(g(X\theta)-y) + \frac{\lambda}{m}\theta_{j}
∂θj∂J(θ)=m1XT(g(Xθ)−y)+mλθj
附上一个完整的逻辑回归代码
import numpy as np
import random
def genData(numPoints,bias,variance):
#产生一个numpoints行,2列的0矩阵
x = np.zeros(shape=(numPoints,2))
#一列0矩阵
y = np.zeros(shape=(numPoints))
for i in range(0,numPoints):
x[i][0]=1
x[i][1]=i
y[i]=(i+bias)+random.uniform(0,1)+variance
return x,y
def gradientDescent(x,y,theta,alpha,m,numIterations):
xTran = np.transpose(x)
for i in range(numIterations):
hypothesis = np.dot(x,theta)
loss = hypothesis-y
cost = np.sum(loss**2)/(2*m)
gradient=np.dot(xTran,loss)/m
theta = theta-alpha*gradient
print ("Iteration %d | cost :%f" %(i,cost))
return theta
x,y = genData(100, 25, 10)
print ("x:")
print (x)
print ("y:")
print (y)
m,n = np.shape(x)
n_y = np.shape(y)
print("m:"+str(m)+" n:"+str(n)+" n_y:"+str(n_y))
numIterations = 100000
alpha = 0.0005
theta = np.ones(n)
theta= gradientDescent(x, y, theta, alpha, m, numIterations)
print(theta)
这是一个sklearn的应用,数据自己带入即可(二分类问题)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
import pandas as pd
import numpy as np
colomns = ['','','','','','','','','']
data = pd.read_csv('',names=colomns)
print(data)
# 对缺失值进行处理
data = data.replace(to_replace='?', value=np.nan)
data = data.dropna()
# 分割数据
x_train, y_train, x_test, y_test = train_test_split(data[colomns[1:10]], data[colomns[10]],test_size=0.25)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 逻辑回归预测
lg = LogisticRegression(C=1.0)
lg.fit(x_train, y_train)
y_predict = lg.predict(x_test)
print(lg.coef_)
print("accuracy: ", lg.score(x_test, y_test))
print("recall: ", classification_report(y_test, y_predict, labels=[2,4], target_names=['','']))
三. 参考链接
[1] 机器学习有监督学习之–回归
[2] 线性回归,逻辑回归 深入浅出
[3] 《机器学习》 周志华
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









