







爬虫之 JS(返回非 json 数据)的爬取
写在前面的话: 查资料,看到常用浏览器的 user-agent 参考对照表,因为之前爬取百度文库的时候用到手机的请求头,所以就想把这些所有请求头爬下来,结果遇到一系列问题,进而解决,从而记录下来。
一. 爬取内容
简介:该对照表整理了时下流行的浏览器User-Agent大全,User Agent也简称UA。它是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。并悬浮提示来访者的user-agent信息。
下面是要爬取的内容
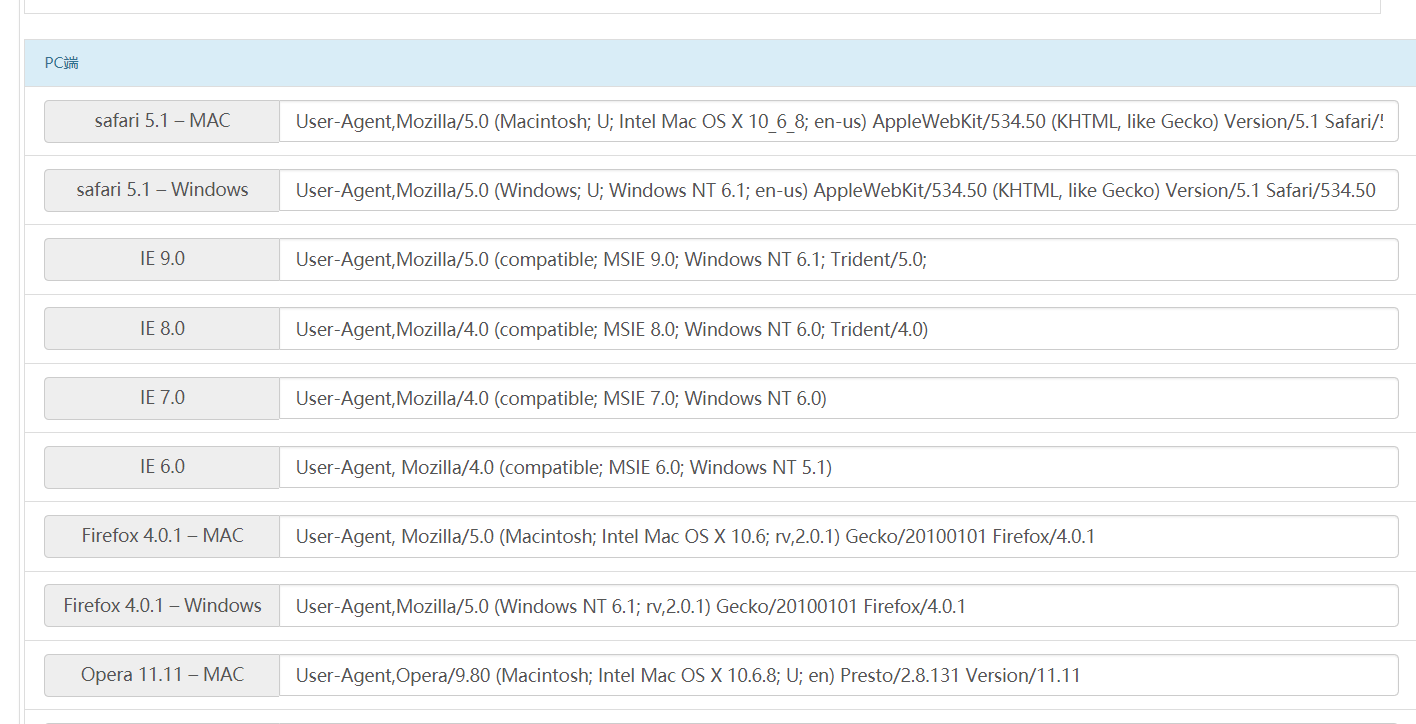
查找元素,发现可以找到!数据这么规整会以为很容易啊!但是用xpath去提取总是空白的,去查看网页源代码,可达鸭眉头一皱,发现事情没有这么简单。
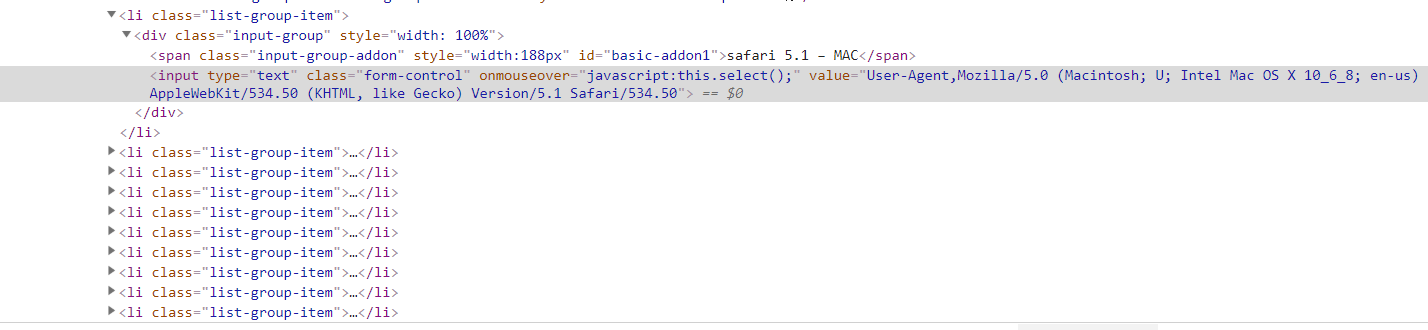
放入最基本的代码
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"
}
url = 'http://tools.jb51.net/table/useragent'
html = requests.get(url, headers=headers)
html.encoding = 'utf-8'
text = html.text
二. 网页原理
看图片
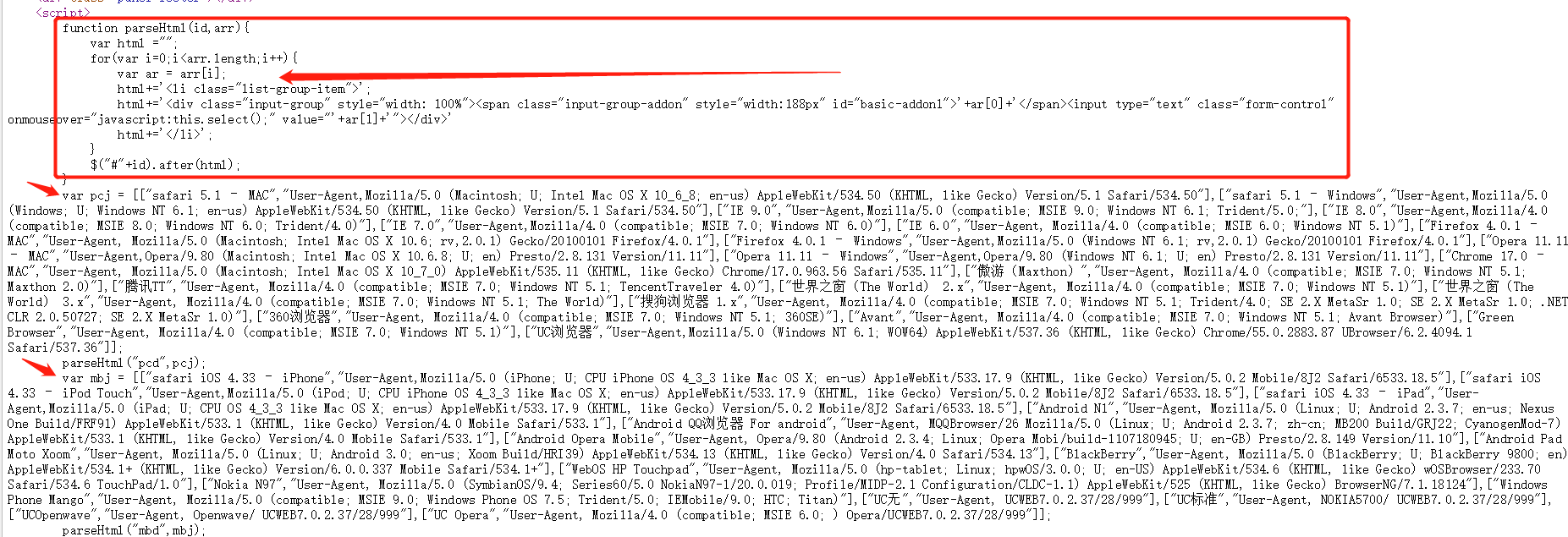
这是用 js 代码加进去的,并不能通过网页元素查到,所以xpath直接提取是不行喽,而且返回不到 json 数据,那就得想想办法了。
最简单的正则,用来用去,掀起小板凳,砸掉电脑,pass!
用bs大法……与xpath一样无从下手,pass!
经查资料,发现有个解析 js 的库 —— js2xml
开始尝试,具体的使用方法还请耐心往下看
import js2xml
- pip install js2xml 即可安装
当然,先要获取js代码段,也就是 script 标签内的内容,为什么是取第3个,自然是根据网页来定了,我要的内容在第3个元素里,自然取它了!
lx = etree.HTML(text)
scripts = lx.xpath("//script/text()")[3]
三. 解析JS代码
重点就在于 js2xml.parse(scripts) 方法
parsed = js2xml.parse(scripts)
xml_file = js2xml.pretty_print(parsed)
print(xml_file)
重点: 这个方法得到了什么内容,让我们查看一下,发现就是规整的xml文件,但上述的 xml_file 是 str 类型,我们完全可以用 xpath 或 bs 去获取我们想要的了!是不是很简单?
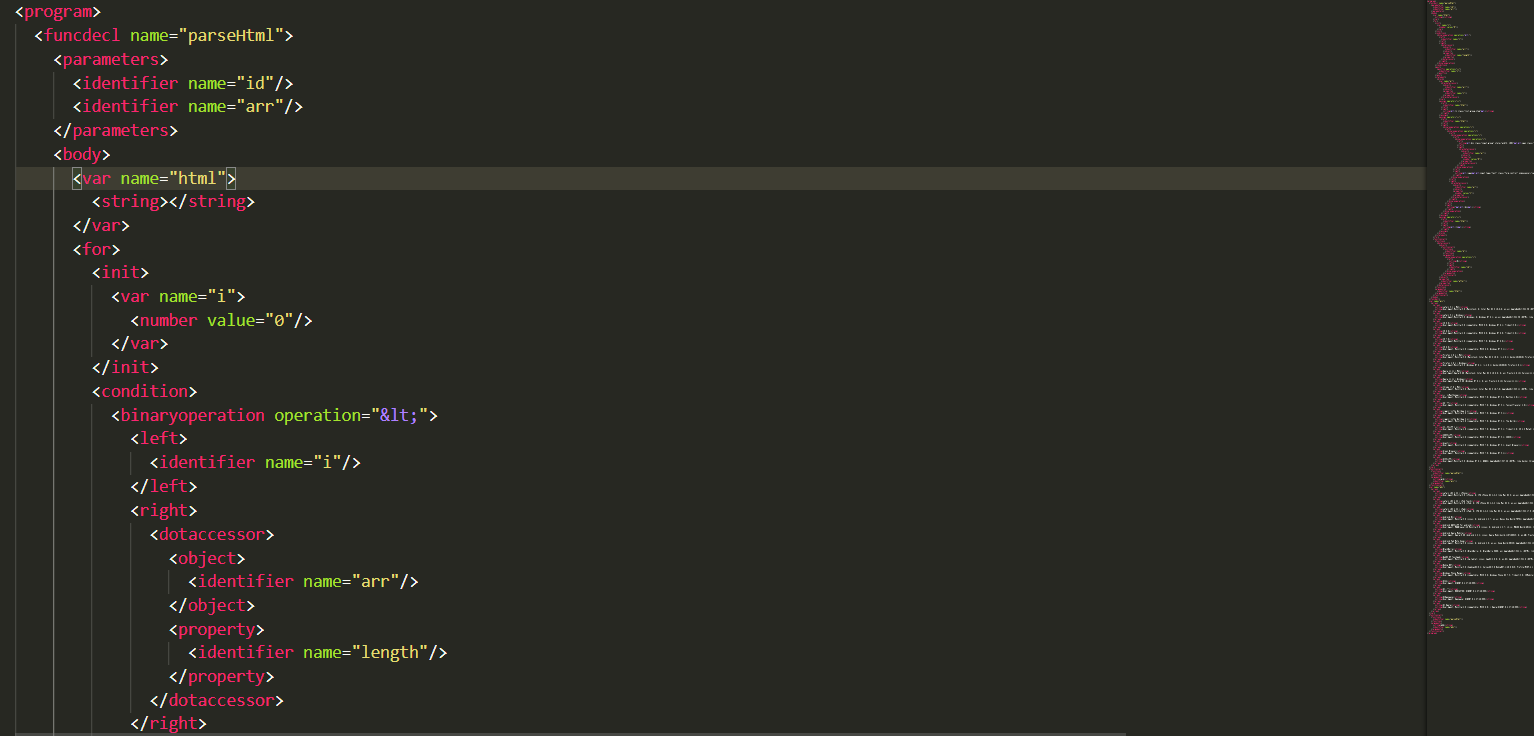
四. 爬取内容
在这里用了 xpath
names1 = script.xpath("//var[@name='pcj']//text()")
names2 = script.xpath("//var[@name='mbj']//text()")
infos1, infos2 = [], []
for name in names1:
if name:
infos1.append(name)
for name in names2:
if name:
infos2.append(name)
dic1, dic2 = {}, {}
for i in range(1, len(infos1)):
if i % 2 != 0:
s = infos1[i].split('User-Agent,')[1]
dic1[infos1[i-1]] = s
for i in range(1, len(infos2)):
if i % 2 != 0:
s = infos2[i].split('User-Agent,')[1]
dic2[infos2[i-1]] = s
五. 完整代码
中间有部分数据处理的过程,比如去掉字符串中的 “User-Agent”,通过分析数据格式来存储,个人习惯用pandas做存储,也可以直接分析嘛,毕竟数据量小,不需要用安全队列去搞
# -*- encoding: utf-8 -*-
# user_agent.py
# @Time : 2019/05/07 17:13:11
# @Author: 小木
# @email : hunt_hak@outlook.com
# here put the import lib
import pandas as pd
import requests
import re
import pandas as pd
import js2xml
from lxml import etree
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"
}
html = requests.get(url, headers=headers)
html.encoding = 'utf-8'
text = html.text
return text
def parse_xml(text):
lx = etree.HTML(text)
scripts = lx.xpath("//script/text()")[3]
parsed = js2xml.parse(scripts)
xml_file = js2xml.pretty_print(parsed)
html = etree.HTML(xml_file)
return html
def get_dic(l):
dic = {}
infos = []
names = [i.strip() for i in l]
for i in names:
if i:
infos.append(i)
for i in range(1, len(infos)):
if i % 2 != 0:
s = infos[i].split('User-Agent,')[1]
dic[infos[i-1]] = s
return dic
def save_to_csv(dic, filename):
dic_list = [dic]
datas = pd.DataFrame(dic_list)
datas.to_csv(filename+'.csv', index=None)
if __name__ == "__main__":
url = 'http://tools.jb51.net/table/useragent'
text = get_html(url)
script = parse_xml(text)
names1 = script.xpath("//var[@name='pcj']//text()")
names2 = script.xpath("//var[@name='mbj']//text()")
dic1 = get_dic(names1)
dic2 = get_dic(names2)
# print(dic1, dic2)
save_to_csv(dic1, "PC")
save_to_csv(dic2, "MOBILE")
欢迎批评指正~















 2382
2382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









