






1.数据
想要了解es,首先要弄清楚,我们日常生活中遇到的数据,大致分为哪几类
从数据结构化的角度来考虑,包括以下两种
- 结构化数据
- 非结构化数据
结构化数据
概念
也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。指具有固定格式或有限长度的数据,如数据库,元数据等。
搜索方式
对于结构化数据,我们通常采用关系型数据库进行数据存储,通过2维表的形式指定数据列对进行数据查询
非结构化数据是
概念
又可称为全文数据,不定长或无固定格式,不适于由数据库二维表来表现,包括所有格式的办公文档、JSON、XML、HTML、Word 文档,邮件,各类报表、图片和咅频、视频信息等。
搜索方式
对于非结构化数据,我们通常采用非关系型数据库来进行存储。包括mongodb,redis,以及即将提到的ElasticSearch。对于非结构化数据,搜索方式包含以下两种:
- 顺序扫描
顾名思义,根据关键词,从头到尾逐个检索每一个数据,直到检索到匹配的关键词即可。可想而知,当数据量达到一定的数目时,顺序检索的效率会十分低下
- 全文检索
全文索引大致包括两步
- 第一步:根据规则,将整个非结构化数据转为便于搜索的结构化数据,通常来说就是根据分词规则建立出全文的倒排索引
- 第二步:通过关键词在结构化数据上进行数据检索,检索出数据并返回
由此可见,全文检索在创建便于搜索的结构化数据时,会耗费部分时间。但是对于大数据量的查询,效率非常高
2.Lucene
介绍
由上文可以得出结论,对于非结构化数据,传统的关系型数据库无法提供完善的数据检索功能
而目前对于非结构化数据支持最好的开源工具包,目前就是Apache 的 Lucene了
Lucene本身并不是一个搜索引擎,只是一个为软件开发人员提供的jar包,以方便的在目标系统中实现全文检索的功能,或者基于lucene建立搜索引擎
目前基于lucene而实现的搜索引擎,主要是 Solr 和 Elasticsearch。
Solr 和 Elasticsearch 都是比较成熟的全文搜索引擎,能完成的功能和性能也基本一样。
但是 ES 本身就具有分布式的特性和易安装使用的特点,而 Solr 的分布式需要借助第三方来实现,例如通过使用 ZooKeeper 来达到分布式协调管理。
倒排索引
原理
lucene能够实现非结构化数据检索的基础,就是我们一直提到的倒排索引技术
下图可以形象的表示倒排索引的概念

如图:
假设当前文档包括两句话
- 1.I like Stephen Curry
- 2.I like Leborn James
那么,根据空格分词法,文档中共包含I、Like、Stephen、Curry、Leborn、James6个单词
其中I、Like两个单词在1,2文档中出现,Stephen、Curry在1文档中出现,Leborn、James在2文档中出现。
那么当我想要查询James时。我只需查询当前的数据结构,即可得知James出现在2文档中,单一结果无需取交集,所以直接获取2文档的全部内容即可
当我想要获取包含I与Curry文档时,可通过当前数据结构得知,I对应1,2文档,Curry对应1文档,结果取交集,即可确定检索结果为1文档,进行获取1文档全部内容
通过以上可了解到,倒排索引机制通过分词获取每个单词对应的文档集合,进而通过结果取交集的形式,快速获取到想要检索的结果集,这就是为什么lucene可以如此快速进行非结构化数据检索结果的原因
基础概念
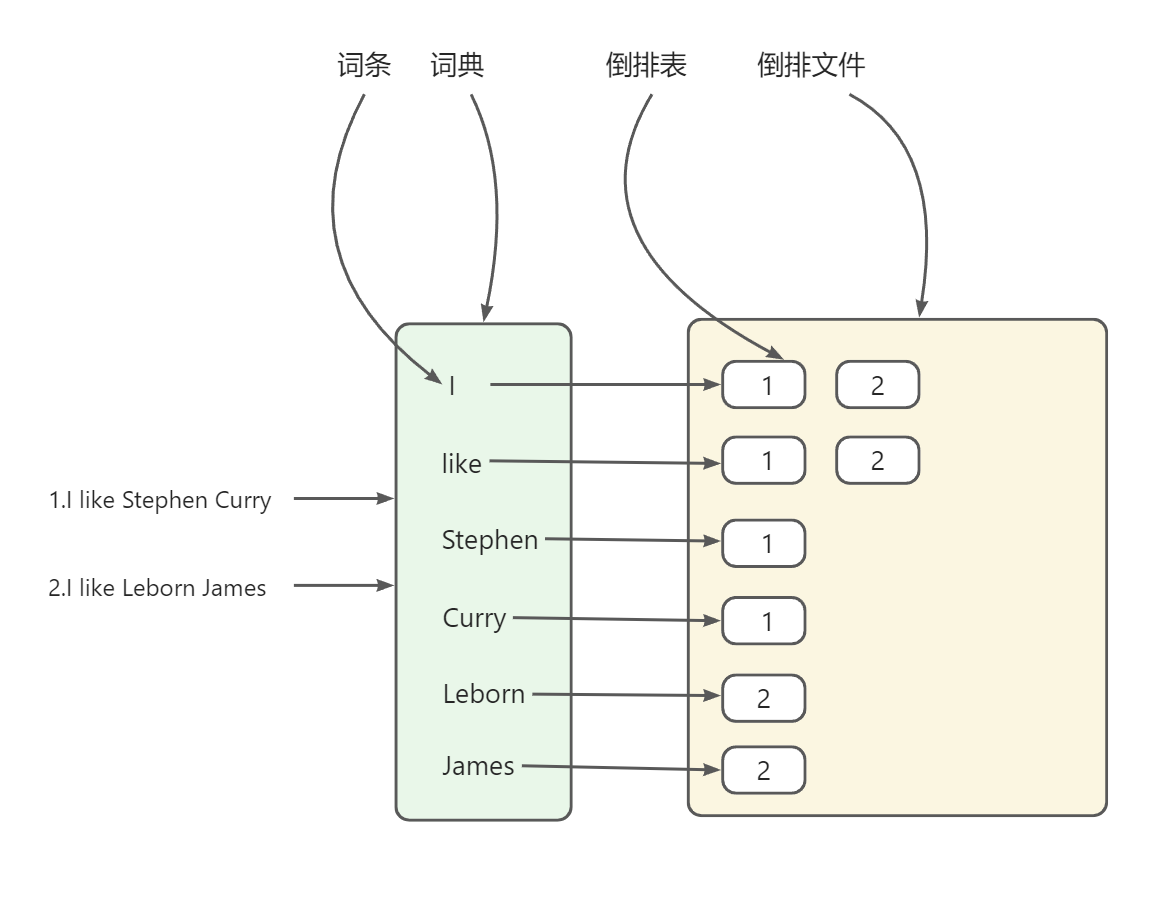
如图:倒排索引中共包含以下主要概念
- 词条(Term): 索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
- 词典(Term Dictionary): 或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
- 倒排表(Post list): 一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储了词频等信息。
- 倒排文件(Inverted File): 所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
从上图我们可以了解到倒排索引主要由两个部分组成:词典,倒排文件
词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,其中词典又可以分为前缀索引和后缀词条。词典文件存储在内存中,而倒排文件存储在磁盘上。
3.什么是ElasticSearch
说到ES,要先了解下The Elastic Stack
Elastic Stack是由ELK演化而来,ELK是三种软件的简称,分别是Elasticsearch、logstash、kibana组成,在发展的过程中,又有新成员Beats的加入,形成了Elastic Stack。
也就是ELK在兼并Beats后形成的新联盟–ELKB是Elastic Stack。
大致架构如下:
Beats
Beats是elastic公司开源的一款用于采集系统监控数据的代理agent,在被监控服务器上以客户端形式运行的数据收集器的统称。可以直接把数据发送给Elasticsearch或通过Logstash发送给Elasticsearch,然后进行后续的数据分析活动。
Logstash
Logstash基于Java,是一个开源的用于收集,分析与存储日志的工具。可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如将数据提供给 Elasticsearch 使用。
Kibana
Kibana基于nodejs,也是一个开源的工具。可以为 ElasticSearch 提供友好的日志分析 Web 界面,可以帮助用户汇总、分析和搜索重要数据日志。
ElasticSearch
ElasticSearch是一个有java语言编写,基于分布式部署,基于文档存储,扩展性极高,可实现近实时查询的数据分析引擎
ElasticSearch底层基于lucene实现对于非结构化数据的存储和查询,通过对 Lucene 的封装,隐藏了Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
ElasticSearch虽然在逻辑架构层面与关系型数据库相匹配,但其本身的功能和作用更倾向于数据的查询和分析。如果那些需要频繁进行数据更新的数据,并不适合录入到ElasticSearch中
4.ElasticSearch中的核心概念
Index
ElasticSearch会默认为所有数据建立索引。
Index作为es的逻辑架构最基础数据,可以类比为关系型数据库中的库,需要注意的是,每个Index的名字必须小写
Type
类型,type概念用于在一个索引内,给文档进行逻辑上的过滤和区分。可以类比为关系型数据库中的表
根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。需要注意的是,一个 type 命名可以是大写或者小写,但是不能以下划线或者句号开头,不应该包含逗号, 并且长度限制为256个字符
Document
文档,es与mongo类似,也是一个面向文档存储的分布式数据库。数据的最小单位就是一个文档,并且文档以Json的形式进行存储。理论上来说,一个索引中的文档格式可以完全不同,但是为了查询效率高,还是建议统一一个索引中的文档格式
文档形式如下示例:
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}Mapping
mapping则可以作为对一个索引中一个类型的字段的声明,用来声明该类型中字段的类型,字段的名称,字段是否建立索引,字段存储时的分词逻辑以及字段查询时的分词逻辑等
一个 Mapping 是针对一个索引中的 Type 定义的:
- ES 中的文档都存储在索引的 Type 中
- 在 ES 7.0 之前,一个索引可以有多个 Type,所以一个索引可拥有多个 Mapping
- 在 ES 7.0 之后,一个索引只能有一个 Type,所以一个索引只对应一个 Mapping
5.ElasticSearch与同类产品和关系型数据库对比
| ElasticSearch | MongoDb | 关系型数据库 |
| index | database | database |
| type(7.0以后该概念可忽略) | collection | table |
| mapping | N/A | schema |
| document | document | 行数据 |
| key-value | key-value | 字段 |
6.ElasticSearch特点
- 大型分布式集群部署,可扩展性好,可扩展至上百台服务器,处理PB级别数据;
- 近乎实时的存储、查询数据;
- 开箱即用,部署简单,操作简单。使用 restful 风格的 API进行数据的读写操作;
- ES 最核心的功能,查询、统计;
- ES 存储的数据是静态数据,不同于 MySQL 这类需要定期 CRUD 事务操作的数据库;
- ES 不支持频繁的更新;
- ES 不支持事务;
- ES不是很适合存储原始数据,尤其是需要 CRUD 的数据;
总结来说,ES更偏向与数据的查询,如果想用es做数据层的存储,那么要好好考虑下数据的写操作带来的性能影响
7.ElasticSearch应用场景
- 搜索引擎以及搜索推荐
- 电商网站商品检索
- 日志数据分析采集
- 站内搜索,IT/OA等系统的搜索
总的来说,任何基于非结构化数据查询分析的场景,都推荐使用ElasticSearch来实现近实时的数据存储与查询。但是如果想用es来完全实现数据存储的话,那么相对来说不是很推荐
8.ElasticSearch文档关键元字段
_index
标识当前文档属于哪个索引。一个索引中最好存储相同格式的文档数据,避免出现过多的稀疏索引,这样做可以提高查询效率
_type
标识当前文档属于哪个类型。7.0以后类型的概念可以被忽略,因为一个索引中只允许存在一个类型
_id
文档的唯一标识ID,可以自己指定,也可以交给es自己生成。es自动生成的 ID 是 URL-safe、 基于 Base64 编码且长度为20个字符的 GUID 字符串。 这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一 ID ,且互相之间的冲突概率几乎为零
_source
用于存储文档的原始JSON内容,_source字段不会建立索引,但是会被存储。搜索文档时,会默认返回_source字段,但_source字段不能作为查询条件
_source功能默认是开启的, 会产生额外的存储开销, 可以通过配置_source字段的enabled:false来关闭,但是一旦source功能被禁止,将造成大量功能无法使用。
可以在创建index时, 在mapping中通过includes/excludes参数来减少_source字段的内容。移除的字段不会被存储在_source中, 但仍然可以搜索到这些字段.
如果只想获取_source的部分内容, 可以使用_source_includes或_source_excludes参数
_size
source字段占用的字节数
_score
用来标识该文档的评分。评分的作用是用来表示该文档与查询条件的关联性,关联性越高,分数越高















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









