







链表
删除链表节点
Write a function to delete a node (except the tail) in a singly linked list, given only access to that node.
Supposed the linked list is 1 -> 2 -> 3 -> 4 and you are given the third node with value 3, the linked list should become 1 -> 2 -> 4 after calling your function.
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
// 方法一
void deleteNode(struct ListNode* node) {
node->val = node->next->val;
node->next = node->next->next;
}
// 方法二
void deleteNode(struct ListNode* node) {
*node = *node->next; // ->优先级高于*
}
// 方法三(方法二的变体)
void deleteNode(struct ListNode* node) {
*node = *(*node).next; // .优先级高于*
}直接给链表当前节点结构体赋值,而不是操作结构体指针。
Delete Node in a Linked List
翻转链表
struct ListNode* reverseList(struct ListNode* head) {
struct ListNode *prev = NULL, *next = NULL, *current = head;
while(current){
next = current->next;
current->next = prev;
prev = current;
current = next;
}
return prev;
}代码可读性如此之强,思路都不用写了。刚开始做链表的题,我有点糊涂,不得不再复习一下对赋值语句的理解, 如:
a = b;
把a,b理解为两个名字分别叫做a,b的盒子,赋值即把b盒子里的东西复制一份并放到a盒子里。
删除值为n的节点
ExampleGiven: 1 –> 2 –> 6 –> 3 –> 4 –> 5 –> 6, val= 6
Return: 1 –> 2 –> 3 –> 4 –> 5
C语言
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val) {
if(!head) return head;
while(head && head->val == val){
head = head->next;
}
if(!head || !head->next) return head;
struct ListNode *last = head;
struct ListNode *current = head->next;
while(current){
if(current->val == val){
last->next = current->next;
current = last->next;
} else{
last = current;
current = current->next;
}
}
return head;
}利用指针的指针(牛人的):
struct ListNode* removeElements(struct ListNode* head, int val) {
ListNode **p = &head;
while(*p != NULL)
{
if((*p)->val == val)
*p = (*p)->next;
else
p = &((*p)->next);
}
return head;
}双指针与链表的关系如下图:
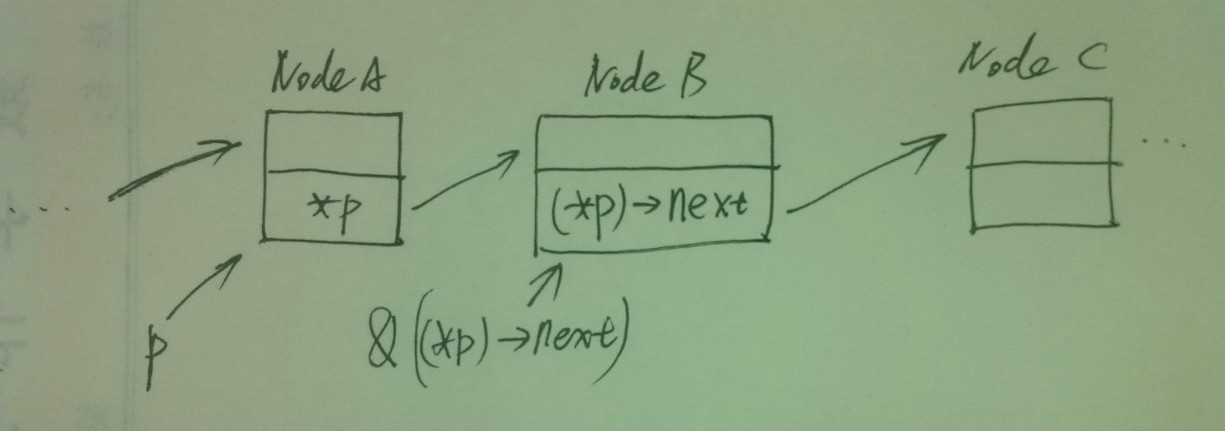
这么做确实能很好地处理删除头节点的问题,明显地减少了代码量。
节点B的地址即*p, 那么*p的接引p就是上一个节点的next域地址。这么一来,使用双指针可以在遍历过程中轻易地读写前一个节点的next域。如删除正在遍历的结点*p, 只需*p = (*p)->next; 同时以*p遍历链表,遍历的方式就是p = &((*p)->next); 。
Remove Linked List Elements
删除重复的节点
For example,
Given 1->1->2, return 1->2.
Given 1->1->2->3->3, return 1->2->3.
自从看了上一题双指针的解法,这道题也忍不住生搬硬套了一番,增加了对Two Pointers的理解。
struct ListNode* deleteDuplicates(struct ListNode* head) {
if(!head) return NULL;
struct ListNode **p = &(head->next);
int val = head->val;
while(*p){
if((*p)->val == val) *p = (*p)->next;
else{
val = (*p)->val;
p = &((*p)->next);
}
}
return head;
}可谁知,牛人们根本不满足于对双指针的使用,他们又打起了递归的主意,原来链表也是可以用递归做的!!!而且由于计算过程简单,速度竟然比非递归算法还快!(从来就没人说过递归一定要比非递归慢)。
struct ListNode* deleteDuplicates(struct ListNode* h) {
return h && (h->next = deleteDuplicates(h->next))
&& h->next->val == h->val ? h->next : h;
}递归还真是好写one-line algorithm啊~还把参数head改成了h, 真是简(zhuang)洁(bi)到了极致。
不过,这又让我们学到了一种处理链表的新方法:递归!——所以说,我最喜欢看别人装逼了,看牛人装逼能学到好东西,看2B装逼能检查自身,这会让周围的人迅速提升。而那些喜欢故作深沉的绝世高手,只会让绝世武功失传,搞得我中原武林一代不如一代。
这段代码乍一看不太容易明白,我就是没注意优先级搞了好久才明白,优先级== > && > ?:
Remove Duplicates from Sorted List
2个链表的交汇节点
For example, the following two linked lists:
A: a1 → a2
↘
c1 → c2 → c3
↗
B: b1 → b2 → b3
如上图所示,链表A和B从c1节点处开始交汇,c1即为所求。
另外,若无交点就返回null, 要求时间复杂度为O(n),空间复杂度为O(1)。
- 算法1:首先遍历两个链表,记录链表长度,计算长度差,如下表,链表b前端长出的那一块不用去管它,从b2开始和a1对齐比较,遇到的第一个相同结点即为所求。
| 链表 | 长度 | |
|---|---|---|
| 链表a | n | a1->a2->c1->c2->c3 |
| 链表b | m | b1->b2->b3->c1->c2->c3 |
| 同样的尾巴 | c1->c2->c3 |
- 算法2:如下表将上述两个链表(a和b)在逻辑上拼接起来(操作上在遍历的时候遇到null就跳到另一个链表就行了)。看,是不是一样长了,连尾巴也一样。如此一来,从以下两个链表的开头对齐比较,遇到的第一个相同的结点即为所求。
| 拼接后的链表 | 长度 | |
|---|---|---|
| 链表a+b | n+m | a1->a2->c1->c2->c3->b1->b2->b3->c1->c2->c3 |
| 链表b+a | n+m | b1->b2->b3->c1->c2->c3->a1->a2->c1->c2->c3 |
| 同样的尾巴 | c1->c2->c3 |
- 小结:①记录链表长度、②链表拼接,都是解决链表问题时的常用办法。我之前只会用栈和队列来做,实在是舍本逐末。
Intersection of Two Linked Lists
删除倒数第n个节点
For example,
Given linked list: 1->2->3->4->5, and n = 2.
After removing the second node from the end, the linked list becomes 1->2->3->5.
Try to do this in one pass.
My solution using C language:
struct ListNode* removeNthFromEnd(struct ListNode* head, int n) {
struct ListNode *scout = head, *target = head;
int count = 0;
while(scout){
scout = scout->next;
if(count > n) target = target->next;
count++;
}
if(count > n) target->next = target->next->next;
else head = head->next;
return head;
}指针scout是侦察兵,用于探测链表终点,target->next是要删除的那个节点。当count > n时,target开始跟随scout遍历链表,并与链表始终保持距离为n。
我想把target这种指针称为等距随从指针,便于日后讨论。
Remove Nth Node From End of List
合并2个单链表
Merge two sorted linked lists and return it as a new list. The new list should be made by splicing together the nodes of the first two lists.
通过前面那道题目“删除重复的节点”,我学到了用递归解决单链表问题,这道题就拿来练练手。
// C++
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if(!l1) return l2;
if(!l2) return l1;
if(l1->val > l2->val) swap(l1, l2);
l1->next = mergeTwoLists(l1->next, l2);
return l1;
}
# Ruby
def merge_two_lists(l1, l2)
if l1 and l2 then
l1, l2 = l2, l1 if l1.val > l2.val
l1.next = merge_two_lists(l1.next, l2)
end
l1 or l2;
end递归真是解决单链表问题的一大利器啊。
总的想法就是:逻辑上,链表l1是最终合并后的链表。通过交换,始终把头结点值最小的子链表接在l1后边. 子链表是l1, l2后边还没有分配的部分,你可以想象成是l1, l2后面没有处理的子链表整条整条地交换。递归一次,新l1链表就长一个节点,而老的l1, l2就短一个节点,最后老链表里的所有节点被用尽。解释起来真费劲啊,还是看代码理解比较好。
one-pass的非递归解法:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if(!l1) return l2;
if(!l2) return l1;
if(l2->val < l1->val) swap(l1, l2);
ListNode dummy(0);
dummy.next = l1;
ListNode* prev = &dummy;
while(l1) {
if(l1->val > l2->val) {
prev->next = l2;
swap(l1, l2);
}
prev = l1;
l1 = l1->next;
}
prev->next = l2;
return dummy.next;
}遍历时,值在当前节点里,无论是删除当前节点或在当前节点的位置插入都需要当前节点的前一个节点(前节点),获得前节点的方法有2种:
- 跟随指针
- 双指针(指针的指针)
这里使用跟随指针prev记录前节点。
删除链表的头节点和删除中间节点的操作是不一样的,为了简化逻辑和节省代码,也有2种方法把头节点变成中间节点:
- 哑节点
- 双指针
dummy是一个放在l1头节点前的哑节点,当前指针从原头节点开始遍历,prev从哑节点开始遍历,头节点变成了中间节点。
上面是都是细节部分,总体思路上和递归解法是一样,不再赘述。
Merge Two Sorted Lists
回文单链表
确定一个单链表是否是回文(12321、123321、1或NULL),保证O(n)time, O(1)space。
bool isPalindrome(ListNode* head) {
int len = 0;
ListNode *p = head;
// get length of the link
while(p){
len++;
p = p->next;
}
// get next node of middle of link
p = head;
int mid = len / 2;
while(mid--) p = p->next;
if(len % 2 == 1) p = p->next;
// reverse the back of the link
ListNode *prev = NULL, *next = NULL;
while(p){
next = p->next;
p->next = prev;
prev = p;
p = next;
}
// jude palindrome
p = prev;
while(p){
if(head->val != p->val) return false;
head = head->next;
p = p->next;
}
return true;
}这个解法是鹏飞告诉我的,先求得链表的长,再从链表中间位置的下一节点开始,翻转链表的后半部分,再从两段向中间依次比较判断是否是回文。
Palindrome Linked List















 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









