










Spark机器学习第六章实现
加载数据集
path = "hdfs:///user/yy/Bike-Sharing-Dataset/hour_noheader.csv"
raw_data = sc.textFile(path)
num_data = raw_data.count()
records = raw_data.map(lambda x: x.split(","))
records.cache()
first = records.first()
print first
print num_data[u'1', u'2011-01-01', u'1', u'0', u'1', u'0', u'0', u'6', u'0', u'1', u'0.24', u'0.2879', u'0.81', u'0', u'3', u'13', u'16']
17379
为线性回归模型准备数据集
# 将特征映射到二元编码向量的映射函数
def get_mapping(rdd, idx):
return rdd.map(lambda fields: fields[idx])\
.distinct()\
.zipWithIndex()\
.collectAsMap()# 查看映射字典结构
print "Mapping of first categorical feature column: %s" % get_mapping(records, 2)Mapping of first categorical feature column: {u'1': 0, u'3': 1, u'2': 2, u'4': 3}
# 建立将特征映射到二元编码向量的映射字典
mappings = [get_mapping(records, i) for i in range(2, 10)]
cat_len = sum(map(len, mappings))
num_len = len(records.first()[11:15])
total_len = num_len + cat_len
print "Feature vector length for categorical features: %d" % cat_len
print "Feature vector length for numerical features: %d" % num_len
print "Total feature vector length: %d" % total_lenFeature vector length for categorical features: 57
Feature vector length for numerical features: 4
Total feature vector length: 61
from pyspark.mllib.regression import LabeledPoint
import numpy as np
# 用于建立二元编码的特征向量
def extract_features(record):
cat_vec = np.zeros(cat_len)
i = 0
step = 0
for field in record[2:9]:
m = mappings[i]
idx = m[field]
cat_vec[idx+step] = 1
i += 1
step += len(m)
num_vec = np.array([float(field) for field in record[10:14]])
return np.concatenate((cat_vec, num_vec))
def extract_label(record):
return float(record[-1])# 对每条记录提取特征向量(使用二元编码)和标签
data = records.map(lambda r: LabeledPoint(extract_label(r), extract_features(r)))# 查看使用了二元编码的训练样本结构
first_point = data.first()
print "Raw data: " + str(first[2:])
print "Label: " + str(first_point.label)
print "Linear Model feature vector:\n" + str(first_point.features)
print "Linear Model feature vector length: " + str(len(first_point.features))Raw data: [u'1', u'0', u'1', u'0', u'0', u'6', u'0', u'1', u'0.24', u'0.2879', u'0.81', u'0', u'3', u'13', u'16']
Label: 16.0
Linear Model feature vector:
[1.0,0.0,0.0,0.0,0.0,1.0,0.0,1.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0,0.0,1.0,0.0,0.0,0.0,0.0,0.24,0.2879,0.81,0.0]
Linear Model feature vector length: 61
为决策回归树准备数据集
# 决策回归树不需要将类型数据用二元编码表示
def extract_features_dt(record):
return np.array(map(float, record[2:14]))# 对每条记录提取特征向量(未使用二元编码)和标签
data_dt = records.map(lambda r: LabeledPoint(extract_label(r), extract_features_dt(r)))# 查看未使用二元编码的训练样本结构
first_point_dt = data_dt.first()
print "Label: " + str(first_point_dt.label)
print "Decision Tree feature vector: " + str(first_point_dt.features)
print "Decision Tree feature vector length: " + str(len(first_point_dt.features))Label: 16.0
Decision Tree feature vector: [1.0,0.0,1.0,0.0,0.0,6.0,0.0,1.0,0.24,0.2879,0.81,0.0]
Decision Tree feature vector length: 12
线性回归和决策回归树的帮助文档
from pyspark.mllib.regression import LinearRegressionWithSGD
from pyspark.mllib.tree import DecisionTreehelp(LinearRegressionWithSGD.train)Help on method train in module pyspark.mllib.regression:
train(cls, data, iterations=100, step=1.0, miniBatchFraction=1.0, initialWeights=None, regParam=0.0, regType=None, intercept=False, validateData=True) method of __builtin__.type instance
Train a linear regression model using Stochastic Gradient
Descent (SGD).
This solves the least squares regression formulation
f(weights) = 1/n ||A weights-y||^2^
(which is the mean squared error).
Here the data matrix has n rows, and the input RDD holds the
set of rows of A, each with its corresponding right hand side
label y. See also the documentation for the precise formulation.
:param data: The training data, an RDD of
LabeledPoint.
:param iterations: The number of iterations
(default: 100).
:param step: The step parameter used in SGD
(default: 1.0).
:param miniBatchFraction: Fraction of data to be used for each
SGD iteration (default: 1.0).
:param initialWeights: The initial weights (default: None).
:param regParam: The regularizer parameter
(default: 0.0).
:param regType: The type of regularizer used for
training our model.
:Allowed values:
- "l1" for using L1 regularization (lasso),
- "l2" for using L2 regularization (ridge),
- None for no regularization
(default: None)
:param intercept: Boolean parameter which indicates the
use or not of the augmented representation
for training data (i.e. whether bias
features are activated or not,
default: False).
:param validateData: Boolean parameter which indicates if
the algorithm should validate data
before training. (default: True)
help(DecisionTree.trainRegressor)Help on method trainRegressor in module pyspark.mllib.tree:
trainRegressor(cls, data, categoricalFeaturesInfo, impurity='variance', maxDepth=5, maxBins=32, minInstancesPerNode=1, minInfoGain=0.0) method of __builtin__.type instance
Train a DecisionTreeModel for regression.
:param data: Training data: RDD of LabeledPoint.
Labels are real numbers.
:param categoricalFeaturesInfo: Map from categorical feature
index to number of categories.
Any feature not in this map is treated as continuous.
:param impurity: Supported values: "variance"
:param maxDepth: Max depth of tree.
E.g., depth 0 means 1 leaf node.
Depth 1 means 1 internal node + 2 leaf nodes.
:param maxBins: Number of bins used for finding splits at each
node.
:param minInstancesPerNode: Min number of instances required at
child nodes to create the parent split
:param minInfoGain: Min info gain required to create a split
:return: DecisionTreeModel
Example usage:
>>> from pyspark.mllib.regression import LabeledPoint
>>> from pyspark.mllib.tree import DecisionTree
>>> from pyspark.mllib.linalg import SparseVector
>>>
>>> sparse_data = [
... LabeledPoint(0.0, SparseVector(2, {0: 0.0})),
... LabeledPoint(1.0, SparseVector(2, {1: 1.0})),
... LabeledPoint(0.0, SparseVector(2, {0: 0.0})),
... LabeledPoint(1.0, SparseVector(2, {1: 2.0}))
... ]
>>>
>>> model = DecisionTree.trainRegressor(sc.parallelize(sparse_data), {})
>>> model.predict(SparseVector(2, {1: 1.0}))
1.0
>>> model.predict(SparseVector(2, {1: 0.0}))
0.0
>>> rdd = sc.parallelize([[0.0, 1.0], [0.0, 0.0]])
>>> model.predict(rdd).collect()
[1.0, 0.0]
训练回归模型
# 训练线性回归模型,后面会慢慢改进
linear_model = LinearRegressionWithSGD.train(data, iterations=50, step=0.1, intercept=False)
true_vs_predicted = data.map(lambda p: (p.label, linear_model.predict(p.features)))
print "Linear Model predictions: " + str(true_vs_predicted.take(5))Linear Model predictions: [(16.0, 110.54561916607503), (40.0, 107.92836240337226), (32.0, 107.45239452594706), (13.0, 107.46860142170017), (1.0, 107.19840815670955)]
# 训练决策回归模型,后面会慢慢改进
dt_model = DecisionTree.trainRegressor(data_dt, {})
preds = dt_model.predict(data_dt.map(lambda p: p.features))
actual = data.map(lambda p: p.label)
true_vs_predicted_dt = actual.zip(preds)
print "Decision Tree predictions: " + str(true_vs_predicted_dt.take(5))
print "Decision Tree depth: " + str(dt_model.depth())
print "Decision Tree number of nodes: " + str(dt_model.numNodes())Decision Tree predictions: [(16.0, 54.913223140495866), (40.0, 54.913223140495866), (32.0, 53.171052631578945), (13.0, 14.284023668639053), (1.0, 14.284023668639053)]
Decision Tree depth: 5
Decision Tree number of nodes: 63
评估回归模型
# 几个计算误差的函数
def squared_error(actual, pred):
return (pred - actual) ** 2
def abs_error(actual, pred):
return np.abs(pred - actual)
def squared_log_error(pred, actual):
return (np.log(pred+1) - np.log(actual+1)) ** 2
# 评估函数
def myEvaluation(true_vs_predicted):
mse = true_vs_predicted.map(lambda (t,p): squared_error(t,p)).mean()
mae = true_vs_predicted.map(lambda (t,p): abs_error(t,p)).mean()
rmsle = np.sqrt(true_vs_predicted.map(lambda (t,p): squared_log_error(t,p)).mean())
return (mse, mae, rmsle)# 评估线性回归模型
mse ,mae ,rmsle = myEvaluation(true_vs_predicted)
print "Linear Model - Mean Squared Error: %2.4f" % mse
print "Linear Model - Mean Absolute Error: %2.4f" % mae
print "Linear Model - Root Mean Squared Log Error: %2.4f" % rmsle
# 1.46只达到了kaggle上的平均成绩Linear Model - Mean Squared Error: 27408.1527
Linear Model - Mean Absolute Error: 127.4103
Linear Model - Root Mean Squared Log Error: 1.4847
# 评估决策回归模型
mse_dt ,mae_dt ,rmsle_dt = myEvaluation(true_vs_predicted_dt)
print "Decision Tree - Mean Squared Error: %2.4f" % mse_dt
print "Decision Tree - Mean Absolute Error: %2.4f" % mae_dt
print "Decision Tree - Root Mean Squared Log Error: %2.4f" % rmsle_dt
# 最好成绩是0.2左右,0.6只能算马马虎虎Decision Tree - Mean Squared Error: 11560.7978
Decision Tree - Mean Absolute Error: 71.0969
Decision Tree - Root Mean Squared Log Error: 0.6259
%matplotlib inline
import matplotlib.pyplot as plt
# 通过画直方图来检查目标值的分布情况
def checkTargets(targets):
plt.hist(targets, bins=40, color='lightblue', normed=True)
fig = plt.gcf()
fig.set_size_inches(16,10)目标变量分布
# 对于线性回归模型,当目标变量服从正态分布,误差项满足高斯--马尔科夫条件(零均值、等方差、不相关)时,回归参数的最小二乘估计是一致最小方差无偏估计. 显然这里的响应变量并不服从正态分布
targets = records.map(lambda r: float(r[-1])).collect()
checkTargets(targets)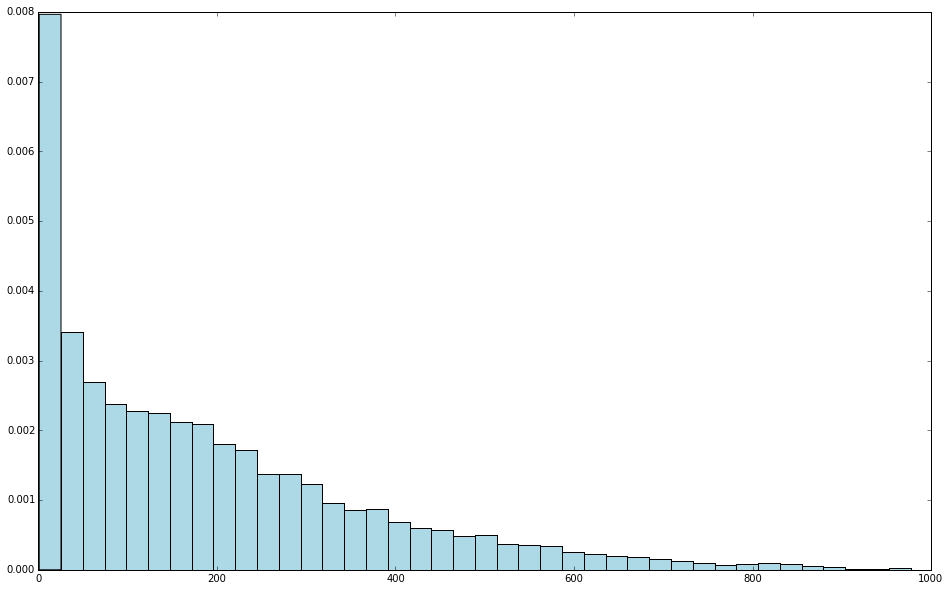
# 对目标值,即响应变量(因变量)进行对数变换,并查看变换后的分布
log_targets = records.map(lambda r: np.log(float(r[-1]))).collect()
checkTargets(log_targets)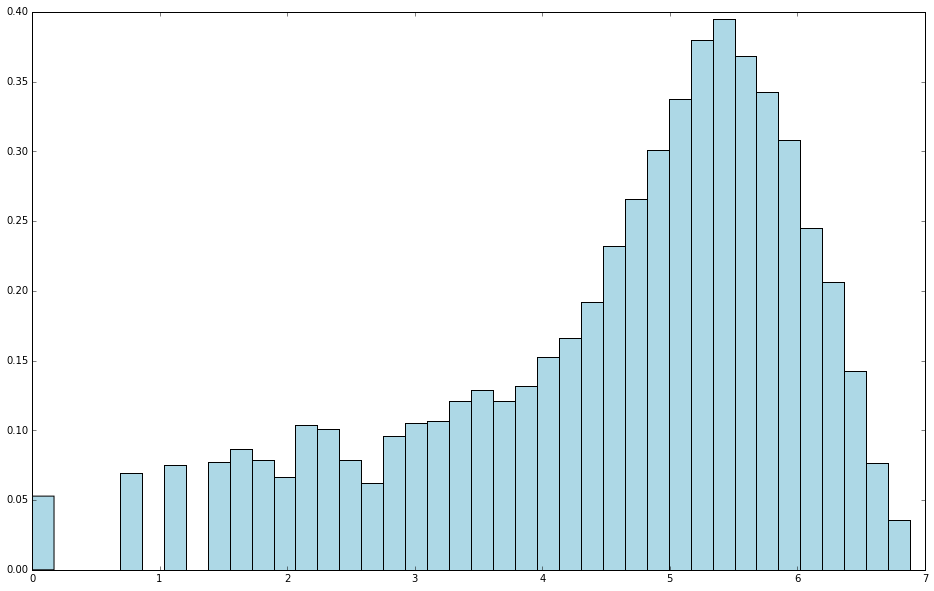
# 对目标值,即响应变量(因变量)进行平方根变换,并查看变换后的分布
log_targets = records.map(lambda r: np.sqrt(float(r[-1]))).collect()
checkTargets(log_targets)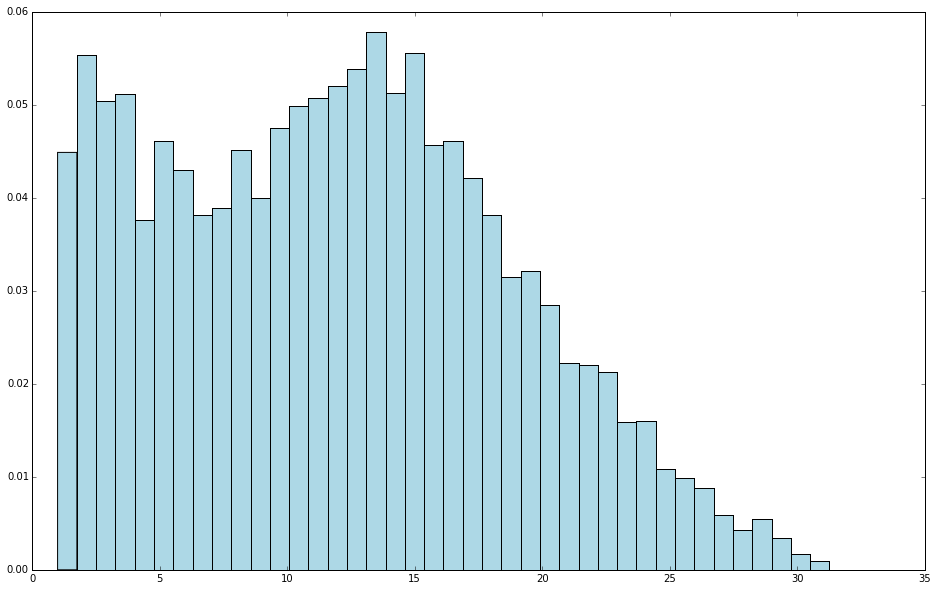
对目标变量作对数变换后重新训练并评估
# 用对数变换后的目标值重新训练线性回归模型
data_log = data.map(lambda lp: LabeledPoint(np.log(lp.label), lp.features))
model_log = LinearRegressionWithSGD.train(data_log, iterations=50, step=0.1)
true_vs_predicted_log = data_log.map(lambda p: (np.exp(p.label), np.exp(model_log.predict(p.features))))# 评估
mse_log, mae_log, rmsle_log = myEvaluation(true_vs_predicted_log)
print "Linear Model - Mean Squared Error: %2.4f" % mse_log
print "Linear Model - Mean Absolute Error: %2.4f" % mae_log
print "Linear Model - Root Mean Squared Log Error: %2.4f" % rmsle_log
print "Non log-transformed predictions:\n" + str(true_vs_predicted.take(3))
print "Log-transformed predictions:\n" + str(true_vs_predicted_log.take(3))Linear Model - Mean Squared Error: 37837.3776
Linear Model - Mean Absolute Error: 133.6572
Linear Model - Root Mean Squared Log Error: 1.3315
Non log-transformed predictions:
[(16.0, 110.54561916607503), (40.0, 107.92836240337226), (32.0, 107.45239452594706)]
Log-transformed predictions:
[(15.999999999999998, 45.336304060846494), (40.0, 42.455963122588777), (32.0, 41.297013243855893)]
# 用对数变换后的目标值重新训练决策回归树模型
data_dt_log = data_dt.map(lambda lp: LabeledPoint(np.log(lp.label), lp.features))
dt_model_log = DecisionTree.trainRegressor(data_dt_log, {})
preds_log = dt_model_log.predict(data_dt_log.map(lambda p: p.features))
actual_log = data_dt_log.map(lambda p: p.label)
true_vs_predicted_dt_log = actual_log.zip(preds_log).map(lambda (t,p): (np.exp(t), np.exp(p)))# 评估
mse_log_dt, mae_log_dt, rmsle_log_dt = myEvaluation(true_vs_predicted_dt_log)
print "Decision Tree - Mean Squared Error: %2.4f" % mse_log_dt
print "Decision Tree - Mean Absolute Error: %2.4f" % mae_log_dt
print "Decision Tree - Root Mean Squared Log Error: %2.4f" % rmsle_log_dt
print "Non log-transformed predictions:\n" + str(true_vs_predicted_dt.take(3))
print "Log-transformed predictions:\n" + str(true_vs_predicted_dt_log.take(3))Decision Tree - Mean Squared Error: 14781.5760
Decision Tree - Mean Absolute Error: 76.4131
Decision Tree - Root Mean Squared Log Error: 0.6406
Non log-transformed predictions:
[(16.0, 54.913223140495866), (40.0, 54.913223140495866), (32.0, 53.171052631578945)]
Log-transformed predictions:
[(15.999999999999998, 37.530779787154522), (40.0, 37.530779787154522), (32.0, 7.2797070993907287)]
为数据集划分训练集与测试集
# 对用于线性回归的数据集,按2:8划分测试集与训练集
data_with_idx = data.zipWithIndex().map(lambda (k,v): (v,k)) # 给每个样本加上序号,再反转键值对
test = data_with_idx.sample(False, 0.2, 42) # 参数:不重复抽样,抽样20%,随机数种子42
train = data_with_idx.subtractByKey(test) # 从data_with_idx中抽掉(去掉)与test的key(样本序号)相等的样本# 形成可用于训练和测试的
train_data = train.map(lambda (idx,p): p)
test_data = test.map(lambda (idx,p): p)
train_size = train_data.count()
test_size = test_data.count()
print "Train data size: %d" % train_size
print "Test data size: %d" % test_size
print "Total data size: %d" % num_data
print "Train + Test size: %d" % (train_size+test_size)Train data size: 13934
Test data size: 3445
Total data size: 17379
Train + Test size: 17379
# 对用于决策回归的数据集,按2:8划分测试集与训练集
data_with_idx_dt = data_dt.zipWithIndex().map(lambda (k,v): (v,k))
test_dt = data_with_idx_dt.sample(False, 0.2, 42)
train_dt = data_with_idx_dt.subtractByKey(test_dt)
train_data_dt = train_dt.map(lambda (idx,p): p)
test_data_dt = test_dt.map(lambda (idx,p): p)对线性回归模型的参数调优
# 用于在不同参数配置下评估线性回归模型的性能
def evaluate(train, test, iterations, step, regParam, regType, intercept):
model = LinearRegressionWithSGD.train(train, iterations, step, regParam=regParam, \
regType=regType, intercept=intercept)
tp = test.map(lambda p: (p.label, model.predict(p.features)))
rmsle = np.sqrt(tp.map(lambda (t,p): squared_log_error(t,p)).mean())
return rmsle
# 画折线图展示不同参数与RMSLE的关系
def plotting(params, metrics):
plt.plot(params, metrics)
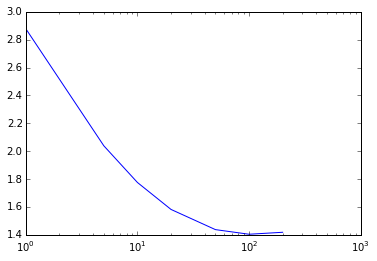
plt.xscale('log')# 评估不同迭代次数对线性回归性能的影响
params = [1,5,10,20,50,100,200]
metrics = [evaluate(train_data, test_data, param, 0.01, 0.0, 'l2', False) for param in params]
print params
print metrics
# 迭代次数与RMSLE的关系
plotting(params, metrics)[1, 5, 10, 20, 50, 100, 200]
[2.8779465130028195, 2.0390187660391499, 1.7761565324837874, 1.5828778102209107, 1.4382263191764473, 1.4050638054019449, 1.4191482045051593]
# 评估不同步长对线性回归性能的影响
params = [0.01,0.025,0.05,0.1,1.0]
metrics = [evaluate(train_data, test_data, 10, param, 0.0, 'l2', False) for param in params]
print params
print metrics
# 步长与RMSLE的关系
plotting(params, metrics)[0.01, 0.025, 0.05, 0.1, 1.0]
[1.7761565324837874, 1.4379348243997032, 1.4189071944747718, 1.5027293911925559, nan]
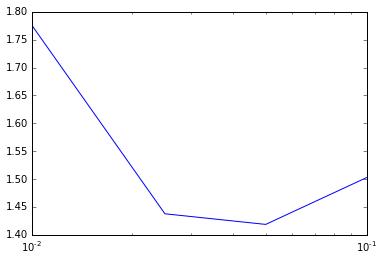
# 评估不同L2正则化参数对线性回归性能的影响,L2正则化既是对过大的模型权重向量2范数进行惩罚
params = [0.0,0.01,0.1,1.0,5.0,10.0,20.0]
metrics = [evaluate(train_data, test_data, 10, 0.1, param, 'l2', False) for param in params]
print params
print metrics
# L2正则化参数与RMSLE的关系
plotting(params, metrics)[0.0, 0.01, 0.1, 1.0, 5.0, 10.0, 20.0]
[1.5027293911925559, 1.5020646031965639, 1.4961903335175231, 1.4479313176192781, 1.4113329999970989, 1.5381692234875386, 1.8279640526059082]
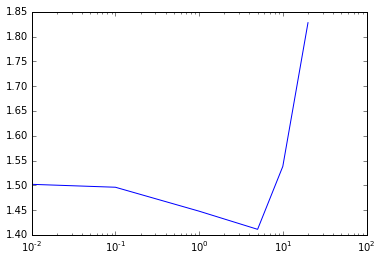
# 评估不同L1正则化参数对线性回归性能的影响
params = [0.0,0.01,0.1,1.0,10.0,100.0,1000.0]
metrics = [evaluate(train_data, test_data, 10, 0.1, param, 'l1', False) for param in params]
print params
print metrics
# L1正则化参数与RMSLE的关系
plotting(params, metrics)[0.0, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
[1.5027293911925559, 1.5026938950690176, 1.5023761634555699, 1.499412856617814, 1.4713669769550108, 1.7596682962964314, 4.7551250073268614]
# 查看线性回归模型在不同的L1正则化参数下权重向量中0的个数
for regParam in [1.0, 10.0, 100.0]:
model = LinearRegressionWithSGD.train(train_data, 10, 0.1, regParam=regParam,\
regType='l1', intercept=False)
print "L1 (%s) number of zero weights: "%regParam + str(sum(model.weights.array == 0))
# L1正则化参数越大,即对模型的L1范数惩罚越大, 那么 权重L1 (1.0) number of zero weights: 4
L1 (10.0) number of zero weights: 33
L1 (100.0) number of zero weights: 58
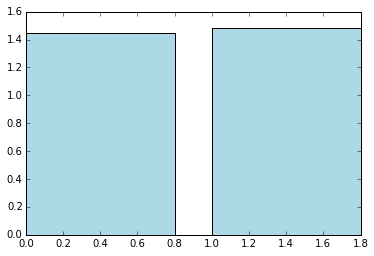
# 评估是否使用截距(intercept)对线性回归性能的影响
params = [False,True]
metrics = [evaluate(train_data, test_data, 10, 0.1, 1.0, 'l2', param) for param in params]
print params
print metrics
# 是否使用截距与RMSLE的关系
plt.bar(params, metrics, color='lightblue')
fig = plt.gcf()
# 使用截距使RMSLE有略微的增加[False, True]
[1.4479313176192781, 1.4798261513419801]
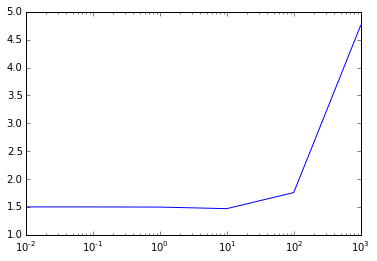
# 用于在不同参数配置下评估决策回归数模型的性能
def evaluate_dt(train, test, maxDepth, maxBins):
model = DecisionTree.trainRegressor(train, {}, impurity='variance', maxDepth=maxDepth, \
maxBins=maxBins)
preds = model.predict(test.map(lambda p: p.features))
actual = test.map(lambda p: p.label)
tp = actual.zip(preds)
rmsle = np.sqrt(tp.map(lambda (t,p): squared_log_error(t,p)).mean())
return rmsle# 评估不同最大树深度对决策回归树性能的影响
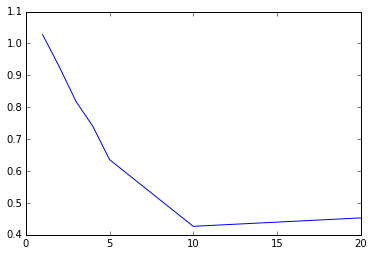
params = [1,2,3,4,5,10,20]
metrics = [evaluate_dt(train_data_dt, test_data_dt, param, 32) for param in params]
print params
print metrics
# 最大树深度与RMSLE的关系
plt.plot(params, metrics)
fig = plt.gcf()[1, 2, 3, 4, 5, 10, 20]
[1.0280339660196287, 0.92686672078778276, 0.81807794023407532, 0.74060228537329209, 0.63583503599563096, 0.42659354467941862, 0.45291736653588244]
# 评估不同最大划分数对决策回归树性能的影响
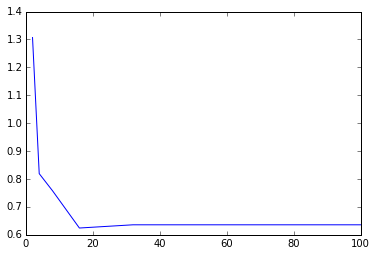
params = [2,4,8,16,32,64, 100]
metrics = [evaluate_dt(train_data_dt, test_data_dt, 5, param) for param in params]
print params
print metrics
# 最大树深度与RMSLE的关系
plt.plot(params, metrics)
fig = plt.gcf()[2, 4, 8, 16, 32, 64, 100]
[1.3069788763726049, 0.81923394899750324, 0.75745322513058744, 0.62430742982038667, 0.63583503599563096, 0.63583503599563096, 0.63583503599563096]
使用IPython的交互插件进行参数调优
需要IPython notebook
from IPython.html.widgets import interact, interactive, fixed
from IPython.html import widgets
def f(param):
metrics = evaluate_dt(train_data_dt, test_data_dt, 5, param)
print param
print metrics
interact(f, param=(10,20)); 














 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









