







在httpServlet中用到了很多跟编码有关的方法,在这里缕一缕
servlet中,我们是站在服务器的角度写的程序,那么下面就以服务器的视角来看。
首先说明下,自己对客户端/服务器数据传输的理解。
1.其实B/S模型也和C/S模型一样,也可以说B/S模型他属于C/S模型的一个子集。C/S模型他讲的是客户端-服务器:就比如说qq ,他对应的就是腾讯qq客户端与腾讯服务器;B/S呢,他讲的是浏览器和服务器:客户端不变,我用的火狐浏览器,那他就是火狐客户端,服务器呢,我输入什么网址,他对应的就是什么服务器。那我是不是可以这样来看,浏览器他就C/S模型中的那个超级浏览器,怎么个超级法呢?输入谷歌的网址,他就是谷歌的客户端;输入百度的网址,他就是百度的客户端。所有的浏览器都遵循了一套标准,以至于不管用的是哪家的浏览器,我服务器发过去的信息基本上都能够被他解析成差不多的页面显示给用户。
2.上面提到了B/S与C/S中的模型其实原理是一样的,那么我就能够利用在javase中学习到的网络编程的知识来写出一个简易的服务器,还有客户端。我们已经知道了http协议他是基于tcp/ip协议的,那么正好,我们可以用tcp协议来手动实现一下服务器。用什么呢?就用ServerSocket、Socket这几个熟悉的类,具体怎么写,网络编程里,相信大家以前都写过,和以前写的一样一样的。写服务器只要知道一个东西就够了,那就是我要开放的端口号,浏览器默认就是80,那我开80端口就行了。这里假设一个十几行的服务器代码我们已经写好了,或者说所有的代码都已经写在了心里了。-------------这里服务器写完了,客户端呢,那就不写了把(要再写个客户端的话就和以前网络编程练得tcp练习是一模一样的了),客户端就用浏览器,一个现成的写好的,顺便我还能看看经过他的这个客户端的封装,到底往服务器发送了些什么东西。
3.之前我们写代码我们从来没有出现过编码或者说是乱码的问题?为什么呢,因为我们之前写的是纯java语音,java中他默认的全都是utf-8,这当然不会出错。但是现在呢,javaee涉及到了3部分东西:java、浏览器、tomcat。而除了java外他们默认的都是iso885i9-1,假定我们不用中文,那当然没问题,就用他默认的就行。现在我们就是要改变他设置的编码格式,让他能够显示中文,而且不乱码,重点是这个。怎么防止乱码呢,只要抓住一点:用什么方式编的码,就用什么方式解码。下面用一张图先简单说明一下:
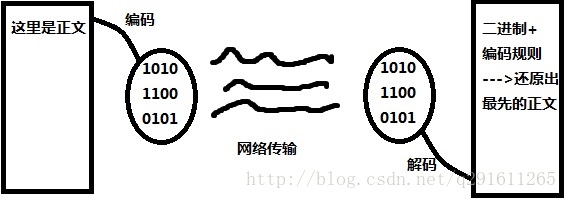
假如我编码用的是gbk,解码时用的是utf-8,那么最后还原出来的正文肯定不是原来的那份,但是那份101000的二进制数是没错的,只是解码时用的方法不对。
下面谈谈我对B/S模型中用到编码的对应方式:
首先是客户端向服务器发送了一个请求(这里我们只讲servlet,指的是访问servlet)1,在2这个地方,服务器得到了客户端发送过来的二进制数据(自己写程序肯定能够发现这里我读到的肯定是byte数组,使用了BufferedReader readLine读到的String那也是java方法中使用了默认的utf-8编码得到的)。通过javaee中的httpServlet类中doGet()/doPost方法,可以发现request对象中的所有的数据都是对socket.getInputStream得到的流,然后从流中读到的各种数据进行的封装。而response对应的就是你到时候对response怎么操作的,框架他就把你的操作落实到能够看得见摸得着的数据,然后通过socket.getOutputStream得到输入流返还给客户端。
所以说,图中的1.2应该这样理解:在客户端(浏览器)重男有一个编码格式,比如说我要向服务器提交一个表单,我肯定不能直接把表单的字符串直接传过去,肯定要通过编码,变成二进制,然后传递过去,服务器再接收到,以与浏览器一致的编码格式来解析二进制,这样就不会出错了。

1.浏览器的编码格式怎么看呢?在<head></head>中有个的<meta contentType="text/html;charset=utf-8"/>这样我就指定了浏览器中编码格式是utf-8。就是跟浏览器说,等下要发送这些信息的时候,这些信息都以我刚才给你指定的utf-8来编码啊。
2.现在二进制发送到了服务器,服务器得解码了。我们用的应该就是response.getParameter("")方法,得到的就是字符串,这里会出乱码,为何?因为我们这用的是tomcat容器,什么意思?也就是说现在的 tomcat== 我们之前写的那个服务器 。其实tomcat他得到的也是二进制,你调用getParameter方法的时候,他查了一下编码,一看你没给他设置,那就用默认的,他默认的是iso8859-1,这个必须出问题啊,所以在取数据前 ,先设置与浏览器那边一致的编码,就用request.setCharacterEncoding()方法来设置(假想他的request中有一个encode属性,每次解码的时候去找这个属性,我这个方法改变了下这个属性的值)
3.服务器向客户端写数据:
怎么写的?这样写的:response.getWriter().print("content");
下面这句话是从文档里拷贝过来的
This method may be called repeatedly to change content type and character encoding. This method has no effect if called after the response has been committed. It does not set the response's character encoding if it is called after getWriter has been called or after the response has been committed.
在response对象中有2个有关字符编码的方法,一个是setContentType,一个是setCharacterEncoding里面都有以上这几句话,什么意思呢?就是提醒我们要先设置好这个编码,然后再getWriter,不然会失效,这时候我们就能够猜测,到时候写的时候,他们还是以我们指定的编码格式写的。
也就是说,我用utf-8的格式,将我要发送给客户端的内容打成了二进制,然后传送了过去,客户端那边怎么处理这里数据,我们再来讨论4
4.客户端解析服务器发送过来的二进制:
还是通过<head></head>中的<meta contentType="text/html;charset=utf-8"/>,这个怎么指定的,response.setContentType就能指定。














 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









