






前言
通过本文,你将了解并深刻理解什么是 KNN算法。
当然,阅读本文前,你最好会点python,这样阅读起来才会没有障碍噢
春节后的第一篇文章,在这里祝大家新的一年工作顺心!心想事成!新年又有新高度!
什么是 KNN近邻算法?
通常我们都知道这么一句话 “近朱者赤近墨者黑” ,KNN算法就是这句话的完美诠释了。
我们想要判断某个东西属于哪个分类,那么我们只需要找到最接近该东西的 K 个邻居,这些邻居中哪种分类占比最大,那么我们就认为该东西就属于这个分类!
KNN近邻算法 实践
这里我们会使用到 sklearn 和 numpy 两个库,当然就算你不熟悉也没关系,这里主要就是为了直观的感受一下 KNN 算法。
- 导入数据
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets
#这里我们采集的是 sklearn 包里面自带的 鸢尾花 的数据
digits = datasets.load_iris()
# 鸢尾花的种类 用 0,1,2 标识
y = digits.target
# 鸢尾花的 特征,为了可视化的需求,我们这里只取前两个特征
x = digits.data[:,:2]
# 在2d平面上画出鸢尾花的分布情况
#为了方便显示,我们这里只取标识为 0 和 1 两种鸢尾花的数据
plt.scatter(x[y==0,0],x[y==0,1],color='r')
plt.scatter(x[y==1,0],x[y==1,1],color='b')
plt.show()
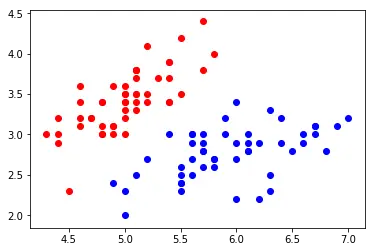
- 拆分数据
# 将数据拆分为 测试数据 和 训练数据
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
# 显示如下图
plt.scatter(x_train[y_train==0,0],x_train[y_train==0,1],color='r')
plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1],color='b')
# 测试数据我们用 黄色显示
plt.scatter(x_test[y_test==0,0],x_test[y_test==0,1],color='y')
plt.scatter(x_test[y_test==1,0],x_test[y_test==1,1],color='y')
plt.show()
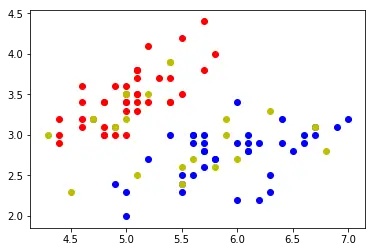
- 预测 和 校准 数据
from sklearn.neighbors import KNeighborsClassifier
# 使用 sklearn knn算法模型进行训练和预测
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
y_predict = knn.predict(x_test)
# 真实数据分布情况
plt.scatter(x[y==0,0],x[y==0,1],color='r')
plt.scatter(x[y==1,0],x[y==1,1],color='b')
plt.show()
# 预测数据分布情况
plt.scatter(x_train[y_train==0,0],x_train[y_train==0,1],color='r')
plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1],color='b')
plt.scatter(x_test[y_predict==0,0],x_test[y_predict==0,1],color='r')
plt.scatter(x_test[y_predict==1,0],x_test[y_predict==1,1],color='b')
plt.show()
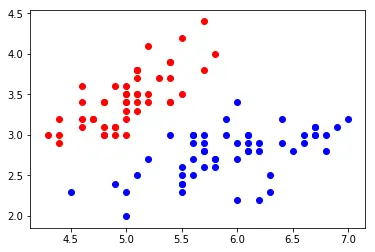
从图中我们很明显的看到 左下角的一个点预测错误,其余都正确 ,这里我们很直观的就可以感受到 KNN 算法的整个流程,其中最关键的还是在 预测数据那块,那么接下来我们就来剖析下 KNN 的原理吧
KNN算法 手写实现
-
思路
首先我们理一下,knn的几个关键因素:
① neighbors,我们该选取几个邻居作为目标分类的依据。
② 和邻居之间的距离怎么计算- neighbors 很简单,我们让调用者自己传入就好了
- 和邻居之间的距离,我们采用简单的
欧拉距离公式计算, 如下:
当然,真正要写好 KNN算法 肯定不是我们考虑的这么简单,但是主要思路是这样,所以我们根据这个思路先来把简单的 KNN 实现一下吧。
- 实现
有了上面的思路,我们直接来看代码吧!
from math import sqrt
from collections import Counter
class MyKNN:
# 初始化
def __init__(self,n_neighbors=5):
self.n_neighbors = n_neighbors
self.X = None
self.Y = None
def fit(self,x,y):
"""
KNN 算是一个比较特殊的算法,其实它是没有一个训练过程的,
这里简单的将训练数据保存起来就好了
"""
self.X = x
self.Y = y
def _predict(self,x):
"""
预测单个样本的所属分类
"""
# 欧拉距离的计算
distances = [sqrt(np.sum((i-x)**2)) for i in self.X]
# 排序
sort_distances_index = np.argsort(distances)
# 找出最近的 n_neighbors 个邻居
neighbors_index = sort_distances_index[:self.n_neighbors]
neighbors = self.Y[neighbors_index]
# 返回最近邻居中分类占比最大的那个分类标识
return Counter(neighbors).most_common(1)[0][0]
def predict(self, X_predict):
"""
预测多个样本的分类
"""
# 通过单个样本分类直接 预测就 ok了
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
上面这个代码应该是相当简单了,如果你有兴趣,可以把 KNN近邻算法 实践 这一节的 预测代码用我们手写的跑一遍,这里就不重复了,实现的效果大同小异,但是从上面的代码我们也可以看出来,咱们是采用遍历的方式来求所有距离的,如果你和
sklearn中的算法做下对比,会发现我们写的运行效率,那真不是一个速度级的。
KNN 调参
实践了,手写了,不知道现在你对knn是不是有了一个比较深入的了解,嗯,只想说一句,不愧是最简单的算法之一,是真的很简单,完全没有什么高深的东西嘛。。。话虽如此,但是如果你觉得这样就可以用好knn那就有点太想当然了。
这里我们就引入了 KNN的调参,其实在机器学习过程中,调参那也是很大一部分的工作内容了。
- 超参数 K
这个k就是我们上面的选取的邻居的个数,选取数目的不一样,对于我们预测的结果肯定也是有差异的,那么下面我们来寻找一下最优的 K 把- 首先我们得有一个评价标准,这里我们简单的就用正确率来评价这个 k 的好坏把,当然在实际工作中肯定不能是这么简单了.
def score(y_predict,y_true): """ 传入 预测的 y 和 真实的 y ,判断一下他们的正确率 """ return np.sum(y_predict == y_true)/len(y_true)- 寻找最佳的 K 值
best_score = 0 best_k = 0 # 循环 10 以内的 k值进行预测,并且求出最佳的 k 值 for i in range(1,10): knn = MyKNN(n_neighbors=i) knn.fit(x_train,y_train) y_predict = knn.predict(x_test) s = score(y_predict,y_test) if(s>best_score): best_score = s best_k = i print("best_score = ",best_score) print("best_k = ",best_k)
- 和距离有关的超参数
-
权重
什么是权重呢?举个简单的栗子,我有三个朋ABC,其中A喜欢吃苹果,BC喜欢吃梨,我和A的关系非常好,和BC只是普通朋友,那么我是喜欢吃苹果还是梨呢?如果不考虑权重,我肯定是喜欢吃梨,因为我的三个朋友有两个喜欢吃梨,但是如果考虑权重的话,就不一定了,鉴于我和A的关系非常好,那么我喜欢吃苹果的概率可能更大。通过上面的栗子,我们应该知道,关于距离的远近对于预测的结果应该是可以考虑不同权重的,距离越近,那么权重越高,我们上面写的算法那肯定是没有考虑,不管远近权重都是1。但是在
sklearn中你是可以找到weight这个超参数的 -
距离的计算方式
上面我们采用的是欧拉距离作为距离的计算方式,实际上,在 sklearn 中,采用的是另外一种方式,叫做明可夫斯基距离,公式如下:其实仔细观察我们会发现,当
P = 1/2就是我们用到的欧拉距离了,所以这里我们又得到一个可以调节的超参数 P,在sklearn中你是可以找到P这个超参数的当然还有很多距离的计算方式,比如:余弦相似度,皮尔森相似度等
-
这一小节我们主要介绍了另外两个超参数,我们其实可以想一下,当有多个超参数需要调节,我们还采用上面的那个循环遍历一个个去试的话,可能就会有大问题,因为存在的可能性太多了,会导致寻找非常困难,所以这里我们需要另外一个叫做
网格搜索的方式来寻找,这里就不介绍了,感兴趣的可以自行搜索一下噢。
KNN是否可以用于回归算法?
前面我们说了,KNN算法是一个分类算法,但事实上其同样可以用来处理回归问题,思路也很简单,找到相应的邻居,然后根据邻居的打分来求自己的打分,将分类问题就转换成了回归问题了。
最后,我们在总结下 KNN 的优缺点
优点
简单,并且效果还不错
天然适合多分类问题缺点
效率低, 样本越多,维度越多,其执行时间复杂度呈线性增长
高度数据相关性
结果不具有可解释性















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









