









输入是否需要添加开始标志[bos]、bos等特殊标志?
结论:
开始标志[bos]不需要手动添加,模型自动帮你添加,结束标志[eos]必须添加
具体原因可以往下看
1.输入是否需要添加开始标志[bos]、bos等特殊标志?
在RNN的时代,对于Seq2Seq模型,我们必不可少的要对数据进行处理添加 开始标志[ bos ]和 结束标志[ eos ],这样做的目的是在解码阶段模型进行自回归语言模型时,模型可以收到一个结束标志[ eos ],并且解码的输入开始标志[ bos ],以确保模型不看到第一个真实的词。
比如,我们输入一句话: 你 是 谁 ?
首先把它处理为如下格式: [ bos ] 你 是 谁 ? [ e o s]
这样的认知和习惯被我们沿用到现在。
但是 Transformer库提供的预训练模型需要你手动进行这样的操作吗?
2.以Bart模型为例
我们在 源码的 forward部分的第一行 就发现了这一的代码
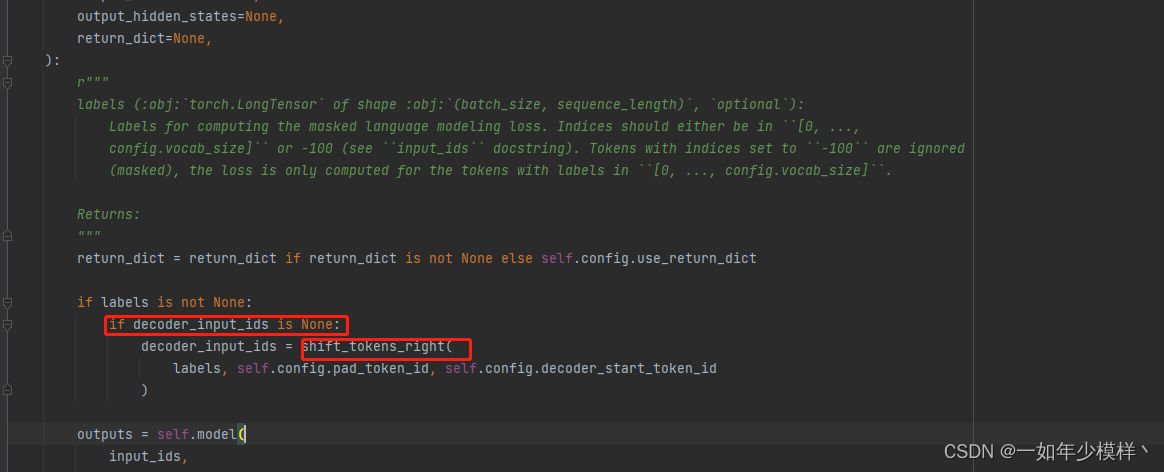
继续点击去:
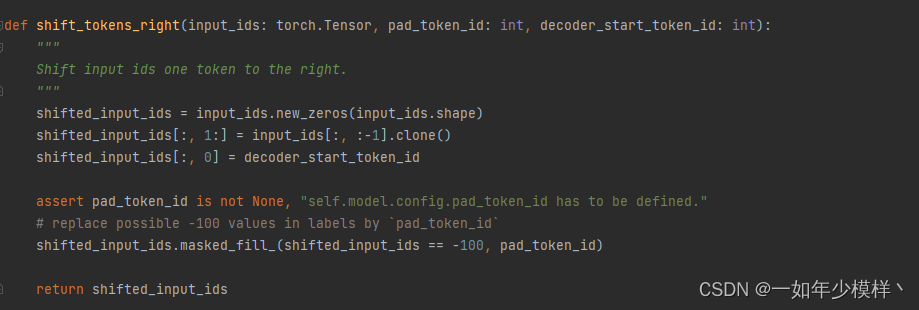
我们会发现,我们可以不用 传入 decoder_input_ids这个参数,模型会帮你自动生成,它的来源 是 labels的向右移动 并在开头添加 开始标志,在这里开始标志模型是下标为2
手动测试下这个方法

果然模型为我们自动添加了开始标志。
所以我们在进行数据处理时候,不用手动添加 开始标志,否则会造成 开始标志的重复,影响模型的预测。
值得注意的 我们要添加 结束标志 [ e o s ] ,模型并不会自动添加,不添加的话会导致在解码时,不知道什么才能结束。















 4406
4406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











