







Redis 教程
Redis特性
Redis可以做什么
缓存;排行榜系统;计数器应用;社交网络:点赞,喜好,推送;消息队列。
Redis为什么这么快
1.通过内存访问数据
2.采用非阻塞IO,不在网络IO上浪费过多时间
3.单线程避免了线程切换和多线程竞争资源的问题
Redis与Memcahce比较
1.Redis为单线程系统,memcache为多线程
2.Redis支持持久化,memcache不支持
3.Redis天然支持主从复制,memcache需要自己实现
4.Redis内存分配临时申请空间,存在碎片;memcache使用预分配内存池的方法,可以省去内存分配的空间
5.数据量大时redis会通过swap把冷数据读到硬盘中,mencache不会
6.Redis的数据类型比mencache多,因此应用场景更广
终上所诉:追求高可用,项目业务比较复杂时建议用redis,追求读写速度用memcahce
Redis 数据类型与API
redis数据类型与内部编码

字符串
字符串类型的实际值可以是字符串,数字(整数,浮点),二进制图片,但最大值不超过512MB
常用命令
1.设置值:set key value [ex seconds] [px milliseconds] [nx|xx]
ex seconds:设置秒级过期时间(对应快捷键setex)
px milliseconds:设置毫秒级过期时间
nx:key不存在才设置成功(对应快捷键setnx)
xx:key存在才设置成功
2.批量设置值:mset key value [key value …]
3.获取值:get key
4.批量获取值:mget key [key …]
5.计数:incr key
值需要是整数,否则返回错误
每次操作自增+1
Key不存在按照值为0自增,返回1
内部编码
int:8个字节的长整型
embstr:小于等于39个字节的字符串
raw:大于39个字节的字符串
哈希
类似map或者对象的结构,适合存储对象信息
常用命令
1.设置值:hset key field value
2.获取值:hget key field
3.删除field:hdel key field
4.计算filed个数:hlen key
5.批量设置:hmget key field [key field …]
6.批量获取: hmget key field [field …]
7.判断field是否存在:hexists key field
8.获取所有field: hkeys key
9.获取所有value:hvals key
10.获取所有field-value:hgetall key
内部编码
当元素个数小于hash-max-ziplist-entries(默认512个),所有值小于hash-ziplist-value(默认64字节)时,使用ziplist,否则用hashtable;ziplist内存小,hashtable读写速度快
列表
可以用来存储多个字符串,列表最多存储2^32-1个元素;
使用场景:lpush+lpop=栈,lpush+rpop=队列,lpush+ltrim=有限集合,lpush+brpop = 消息队列。
常用命令
1.从右边插入元素:rpush key value [value …]
2.从左边插入元素:lpush key value [value …]
3.向某个元素前面或者后买插入元素:linsert key before|after pivot value
4.查找指定范围的元素: lrange key start end
5.获取指定下标的元素:lindex key index
6.获取列表长度:llen key
7.从左侧删除元素:lpop key
8.从右侧删除元素:rpop key
9.删除指定元素:lrem key count value
count>0从左到右删除count个元素
count<0从右到左删除count个元素
Conut=0删除所有
10.按照索引范围删除:ltrim key start end
11.修改指定下标元素:lset key index newValue
12.阻塞式弹出:blpop|brpop key [key …] timeout
timeout为阻塞时间,单位秒,为0时如果无对应数据会一直阻塞可用于实现消息队列
集合
可以保存多个字符串对象,与列表区别在于集合为无序的不能通过下标查询元素,集合不允许有重复对象;
使用场景:sadd = 标签,spop/srandmember = 生成随机数,sadd+sinter = 社交需求
常用命令
1.添加元素:sadd key element [element …]
2.删除元素:srem key element [element …]
3.计算元素个数:scard key
4.判断元素是否在集合中: sismember key element
5.随机返回指定个数元素:srandmember key [count]
默认为1个
6.从集合中随机弹出一个元素:spop key
弹出后集合元素会减少
7.获取所有元素:smembers key
8.求集合交集:sinter key [key …]
9.求集合差集:sdiff key [key …]
10.求集合并集:suinon key [key …]
11.保存交集,差集,并集结果:sinterstore|suionstore|sdiffstore destion key [key …]
其中destion 为新集合的key
内部编码
当元素数量小于set-max-inset-entries(默认512个)时用inset否则用hashtable
有序集合
有序集合与集合类似,区别在于给每个元素增加了一个分数,做为排序的依据。
使用场景:zadd+zincrby = 排行榜系统
常用命令
1.添加成员:zadd key score member [score member]
2.计算成员个数:zcard key
3.计算某个成员的分数:zscore key member
4.计算成员的排名从低到高:zrank key member
5.计算成员的排名从高到低:zrevrank key member
6.删除成员:zrem key member
7.增加成员分数:zincrby key increment member
increment 为增加的分值
8.返回指定排名范围的成员从低到高:zrange key start end [withsorce]
9.返回指定排名范围的成员从高到低:zrevrange key start end [withsorce]
10.返回指定分数范围的成员从低到高:zrangebyscore key min max [withsorce]
min取-inf代表无限小,max 取+inf代表无限大
11.返回指定分数范围的成员从高到低:zrevrangebyscore key min max [withsorce]
12.删除指定排名的升序元素:zremrangebyrank key start end
13.删除指定分数范围的成员:zremrangebyscore key min max
14.交集:zinterstroe destination numkeys key [key …] [weights weight [weight …]] [aggregate sum|min|max]
numkeys:需要做交集的个数
weights weight 每个键的权重
Aggregate sum|min|max 交集后分值汇总方式
15.并集:zuniontroe destination numkeys key [key …] [weights weight [weight …]] [aggregate sum|min|max]
内部编码
当元素个数小于zset-max-ziplist-entries(默认128个),同时zset-max-ziplist-value(默认64)时用ziplist否则用skiplist(跳表)
键管理
1.删除键:del key
2.重命名:rename key newkey
3.随机返回一个键:randomkey
4.设置键在seconds秒后过期: expire key seconds
5.键在秒级时间戳timestamp后过期:expireat key timestamp
6.遍历键:keys pattern
7.渐进式遍历键: scan cursor [match pattern] [count number]
cursor 为上一个游标,从0开始,每次遍历产生新的cursor,遍历完所有键后cursor返回0
match pattern 匹配参数
count number 每次遍历个数
渐进式相比普通遍历,不会造成阻塞,但是在遍历时如果键有变化不保证能遍历所有键
8.清除所在数据库数据所有的键:flushdb
9.清除所有的键:flushall
info 命令详解
server
一般 Redis 服务器信息,包含以下域:
redis_version : Redis 服务器版本
redis_git_sha1 : Git SHA1
redis_git_dirty : Git dirty flag
os : Redis 服务器的宿主操作系统
arch_bits : 架构(32 或 64 位)
multiplexing_api : Redis 所使用的事件处理机制
gcc_version : 编译 Redis 时所使用的 GCC 版本
process_id : 服务器进程的 PID
run_id : Redis 服务器的随机标识符(用于 Sentinel 和集群)
tcp_port : TCP/IP 监听端口
uptime_in_seconds : 自 Redis 服务器启动以来,经过的秒数
uptime_in_days : 自 Redis 服务器启动以来,经过的天数
lru_clock : 以分钟为单位进行自增的时钟,用于 LRU 管理
clients
已连接客户端信息,包含以下域:
connected_clients : 已连接客户端的数量(不包括通过从属服务器连接的客户端)
client_longest_output_list : 当前连接的客户端当中,最长的输出列表
client_longest_input_buf : 当前连接的客户端当中,最大输入缓存
blocked_clients : 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
memory
内存信息,包含以下域:
used_memory : 由 Redis 分配器分配的内存总量,以字节(byte)为单位
used_memory_human : 以人类可读的格式返回 Redis 分配的内存总量
used_memory_rss : 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致。
used_memory_peak : Redis 的内存消耗峰值(以字节为单位)
used_memory_peak_human : 以人类可读的格式返回 Redis 的内存消耗峰值
used_memory_lua : Lua 引擎所使用的内存大小(以字节为单位)
mem_fragmentation_ratio : used_memory_rss 和 used_memory 之间的比率
mem_allocator : 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc 。
在理想情况下, used_memory_rss 的值应该只比 used_memory 稍微高一点儿。
当 rss > used ,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。
内存碎片的比率可以通过 mem_fragmentation_ratio 的值看出。
当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。
Because Redis does not have control over how its allocations are mapped to memory pages, high used_memory_rss is often the result of a spike in memory usage.
当 Redis 释放内存时,分配器可能会,也可能不会,将内存返还给操作系统。
如果 Redis 释放了内存,却没有将内存返还给操作系统,那么 used_memory 的值可能和操作系统显示的 Redis 内存占用并不一致。
查看 used_memory_peak 的值可以验证这种情况是否发生。
其他信息
persistence :RDB 和 AOF 的相关信息
stats : 一般统计信息
replication : 主/从复制信息persistence
cpu : CPU 计算量统计信息
commandstats : Redis 命令统计信息
cluster : Redis 集群信息
keyspace : 数据库相关的统计信息
除上面给出的这些值以外,参数还可以是下面这两个:
all : 返回所有信息
default : 返回默认选择的信息
Redis 超级对象
Bitmaps(位图)
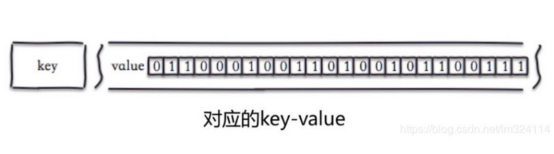
使用场景:取日期为key,可以做日活分析。用户数量很大(活跃用户比重较大时适合做)

常用命令
1.设置值:setbit key offset value
offset 为位置取整数
value 为值取0或者1
2.获取值: getbit key offset
3.获取某个key元素的个数: bitcount key [start] [end]
4.bitop op destkey key [key …]
op 取 and(交集)|or(并集)|not(非)|xor(异或)
destkey 为新key名称
5 . 计算第一个值为targetbit的偏移量:bitops key targetBit [start] [end]
HyperLogLog
可以用极小的内存空间完成独立总数的统计。但是存在一定误差率,误差率约为0.81%。
使用场景:计算独立用户数,百万用户相比时,内存空间要比set小几千倍。
常用命令
1.添加元素:pfadd key element [element …]
2.计算元素数目:pfcount key [key …]
3.合并: pfmerge destkey sourcekey [sourcekey]
destkey 为新key名称
Sourcekey为被合并的key
合并后相同元素算一个元素
GEO
实现地理信息定位的功能。
使用场景:附近的位置,摇一摇
常用命令
1.增加地理信息:geoadd key longitude latitude member [ longitude latitude member …]
longitude latitude member分别为经度,纬度,成员
2.获取地理信息geopos key member [key member …]
3.获取两个地理位置的距离:geodist key member1 member2 [m|km|mi|ft]
4.根据某经纬度为中心指定范围内的地理信息位置集合:georadius key longitude latitude radius m|km|ft|mi [withcoord] [withdist] [withhash] [asc|desc] [store key] [storedist key]
withdist:在返回位置元素的同时,将位置元素与中心之间的距离也一并返回.距离的单位和用户给定的范围单位保持一致。
withcoord:将位置元素的经度和纬度也一并返回。
withhash:以52位有符号整数的形式,返回位置元素经过原始geohash编码的有序集合分值。这个选项主要用于底层应用或者调试,实际中的作用不大。
命令默认返回未排序的位置元素。通过以下两个参数,用户可以指定被返回位置元素的排序方式:
asc:根据中心的位置,按照从近到远的方式返回位置元素
desc:根据中心的位置,按照从远到近的方式返回位置元素。
store key: 将返回结果保存在指定键
storedist key:将距离中心的距离保存到指定键
5.根据某成员为中心指定范围内的地理信息位置集合:georadiusbymember key member radius m|km|ft|mi [withcoord] [withdist] [withhash] [asc|desc] [store key] [storedist key]
操作同georadius
6.获取geohash(地理位置对应的hash字符串):geohash key member
GEO数据类型为zset,地理位置以geohash保存在zset中。
字符串越长代表位置越精确。
两个字符串越相似,代表地理位置月近。
Geohash可以与经纬度互相转换。
Redis 常用功能
Pipeline
可以将一组redis命令组装,一次性传给redis进行处理,从而减少反复交付的次数。Pipeline使用要避免数据量过大,否则会增加客户端等待时间,造成网络阻塞
Lua
通过multi命令开启任务,discard暂停任务,exec执行任务。执行完任务后才完成事物。如果在执行任务时,事物中的key有被修改。任务将不执行。可在multi前执行watch key命令,防止key被修改。
Redis 持久化
RDB
把当前数据生成快照保存到硬盘。
触发机制
1.手动触发:执行save或者bgsave命令
2.自动触发:
使用配置save m n 在m秒n次修改时触发save
从节点全量复制主节点时执行bgsave
执行debug reload 时触发save
执行shutdown时触发save
save与bgsave
save 命令会阻塞当前Redis服务器,bgsave是对save阻塞问题做的优化,bgsave流程:
1.执行bgsave命令
2.fork开启子进程
3.子进程生成RDB文件
4.告知父进程已完成,父进程更新统计信息
AOF
以日志形式实现数据的实时持久化,是现在持久化的主流方式
工作流程
1.Redis所有写入命令会追加到aof_buf(缓冲区)
2.根据文件同步策略同步数据到aof文件
3.当文件太大时对aof文件进行重写
4.Redis重启时加载aof文件恢复数据
文件同步
1.always:每次命令写入都同步
2.everysec:每秒执行一次
3.no:同步操作交给操作系统负责,通常同步周期最长为30秒
AOF文件重写触发机制
手动触发:执行bgrewriteaof命令
自动触发:在aof文件大小超过auto-aof-rewrite-min-size,且文件大小-上次重写时文件大小
/上次重新时文件大小>auto-aof-rewrite-percentage 时触发
AOF文件重写流程

1.执行aof重写请求
2.Fork子进程
3-1 完成fork后有新的写入继续写入aof_buf缓冲区
3-2 为了防止fork后的数据丢失,fork后的数据写入aof_rewrite_buf 重写缓冲区
4. 子进程根据内存快照,按照合并规则写入到新aof文件
5-1 通知父进程,记录info persistence信息
5-2 把重写缓冲区的数据写入新aof文件
5-3 用新aof文件替换旧aof文件
重启加载机制
如果开启aof,加载aof文件;
如果未开启aof或者aof文件不存在则使用rdb,加载rdb文件
如果rdb文件不存在,就不加载任何文件直接重启
RDB与AOF比较
1.RDB比AOF文件小
2.Redis恢复数据时加载RDB比AOF快很多
3.RDB没有办法实时持久化
4.RDB版本用二进制文件保存版本兼容没AOF好
问题定位与优化
fork操作
问题原因:fork操作是重量级操作,会复制父进程的空间内表页(理论上需要复制与父进程同样的内存,但是linux有写时复制机制,父子进程贡献相同的物理内存页,实际会小很多,10G大概只需要20MB)
问题定位: 通过info stats 统计排查 lastest fork查看最近一次的fork的耗时
优化方法:
1.Xen虚拟机对fork操作支持不好,因避免使用
2.控制Redis实列最大内存,线上建议10GB以内
3.合理配置linux内存?
4.降低fork频率,适当放宽aof触发时机
子进程
问题原因:子进程负责重写操作,需要消耗cpu,内存和硬盘的资源
问题定位:
info persistence 查看当多个Redis实例部署在一台服务器时的重写状态
查看重写时的cpu消耗
查看重写时的redis 日志输出观察内存消耗状态
优化方法:
cpu:
1.把内存数据写入文件会消耗大量cpu,因此尽量不要用单核cpu;
2.一台机器如果多个实例,尽量保证不同时重写
内存:
1.同cpu尽量保证多个实列不同时重写
2.设置no-appendfsync-on-rewrite yes避免在大量写入时重写
硬盘:
1.将文件写入硬盘时,会造成比较多的硬盘压力,因此不要和其他高硬盘操作放在一起。如:存储服务,消息队列
2.设置no-appendfsync-on-rewrite yes避免在大量写入时重写
3.开启aof功能时且流量高时,尽量不要用普通机械盘
4.单机开启多个实例,可以把文件分盘存储
AOF追加阻塞
问题原因:常用的同步策略为everysec,此时当Redis有大量写入时,会导致fsync和重写同时发生,此时对比上次fsync时间有可能大于2秒,如果超过2秒主线程将堵塞,直到同步完成。
问题定位:每次阻塞 aof_delayed_fsync指标会累加,通过info persistence 查看 aof_delayed_fsync指标
优化方法:同子进程硬盘优化
相关配置与命令
1.指定RDB保存文件名:dbfilename
2.动态更改RDB文件名:执行config set dbfilename {newfilename}
3.动态更改RDB保存目录:config set dir {newDir}
4.是否采用LZF压缩RDB文件:config set rdbcompression {yes|no},默认开启,建议开启,方便传输和保存到硬盘
5.开启AOF持久化:appendonly yes
6.设置AOF文件名:appendfilename 默认为appendonly.aof
7.设置AOF文件同步方式:appendfsync 默认everysec
8.重新AOF文件:执行bgrewriteaof
9.AOF文件重写体积:auto-aof-rewrite-min-size 默认64MB
10.AOF文件重写子进程根据内存快照每次批量写入新AOF文件的数据大小:aof-rewirte-incremental-fsync 默认大小为32MB
11.在AOF重写期间是否执行fysnc(把缓存信息写入aof文件):no-appendfsync-on-rewrite
Redis主从复制
为Redis配置副本,实现故障的恢复和负载均衡
建立复制
一共有三种方式建立复制:
1.从节点配置文件 中加入slaveof {masterHost} {masterPort}
2.在redis-server 启动命令后加入 --slaveof {masterHost} {masterPort}
3.执行slaveof {masterHost} {masterPort}
断开复制
在从节点上执行slaveof no one,从节点与主节点断开链接,并保留断开前的数据
切换主节点
对断开复制的节点,重新执行建立复制,实现切换主节点的操作,此时:
从节点会清空数据,然后复制新主节点的数据
拓扑
一主一从
主要用于故障转移,可只打开从节点的AOF功能,以提高主节点性能,但此时重启时从节点要断开与主节点的复制关系,以免清空数据。
一主多从
主要用于读占比比较大的场景,用从节点分摊主节点的读写压力
树状结构
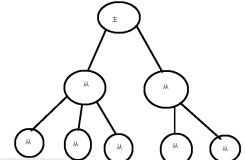
通过引入中间层,降低主节点负载
数据同步
复制偏移量
每次写入命令主从节点都会增加复制偏移量
复制积压缓存区
当主节点响应写命令时,不但把命令发送给从节点,页把命令写入复制积压缓存区
全量复制流程
1.一般在第一次建立链接和重启主节点导致主节点运行id发生变化后引起,如果是debug reload,运行id不会发生变化
2.第一次建立链接后,因为从节点没有复制偏移量和主节点的运行id,会进行全量复制,并保存主节点此时的运行id和复制偏移量
3.主节点执行bgsave保存rdb文件到本地,并将rdb文件发送给从节点,需要注意传输的总时间不能超过 repl-timeout(默认 60秒),否则从节点清空rdb文件,复制失败。
4.在从节点接受rdb文件期间,主节点会将此时的写命令写入复制积压缓冲区,并累积偏移量
5.从节点清空自身数据,加载RDB文件,加载完成后,如果开启AOF就马上重写
部分复制流程
1.一般在主从节点网络断开时间超过repl-timeout(默认60秒)时发生
2.断开后主节点依然把数据写入复制积压缓存区(默认大小为1MB)
3.重新链接后把复制积压缓存区的信息传输给从节点
心跳
1.主节点默认每隔repl-ping-slave-period (默认10)秒发送ping命令检验从节点是否链接正常
2.从节点每隔一秒发送replconf ack {offset}命令,主动上报主节点自己的复制偏移量,检查数据是否丢失,如果丢失就从主节点的复制积压缓存区中拉取数据
异步复制流程
1.主节点接受处理命令
2.命令结束后返回结果
3.异步发送命令给从节点,从节点执行复制的命令
问题定位与优化
主从配置不一致
1.从节点内存溢出,数据丢失:maxmemory与比主节点配置小造成,应该配置一致。
全量复制
1.全量复制消耗大,尽量在低峰时进行
2.节点运行ID不匹配:主节点故障重启造成,可以升级从节点为主节点,防止从节点以为链接了新的节点而造成的全量复制
3.复制积压缓冲区不足时,偏移量会不在主节点的复制积压缓冲区内,而造成全量复制,可以适当加大repl_backlog_size(默认1MB)
单主节点复制风暴
由大量从节点对同一主节点发起全量复制造成:会同时向多个从节点发送rdb文件,网络消耗太大,建议改为原拓扑结构为树状结构
单机器复制风暴
由一台机器部署很多个主节点故障造成:建议每台机器部署的主节点数目尽量少,提供主节点故障转移方案:哨兵,集群等。
相关配置与命令
1.设置复制:slaveof {masterHost} {masterPort}
2.复制命令:slaveof {masterHost} {masterPort}
3.断开复制:slaveof no one
4.设置redis链接密码:requirepass
5.设置节点为只读:slave-read-only 从节点默认为yes
6.传输延迟机制:rep-disable-tcp-nodelay
关闭时,无论产生的命令数据大小都会传给从节点
开启时,会合并较小的tcp数据包从而节省宽带,网络环境差时推荐开启
7.从节点心跳超时时间:repl-timeout默认60秒
8.心跳检验间隔时间:repl-ping-slave-period 默认10秒
9.执行复制:psync {offset} {runId}
10.配置最大内存:maxmemory
11.复制积压缓冲区大小:repl_backlog_size(默认1MB)
Redis 阻塞问题
如何发现问题
1.客户端报JedisConnectionExpection异常
2.使用CacheCloud进行管理
内在原因
API或者数据结构使用不合理解决方案
1.通过慢查询日志slowlog get {n} 查询不合理的命令,改为低算法度的命令代替
2.执行 redis-cli -h {ip} -p {port} --bigkeys 查看大对象,尽量用更合理的数据类型代替
CPU饱和
1.每秒请求次数过多:通过redis -cli --stat 观察requests数量,如果一个redis实例每秒有好几万次请求,建议做水平扩展优化
2.使用了耗时高的命令:通过info commandstats 查看user_per查看命令平均耗时,找出耗时高的命令,把耗时高的命令换成低的命令,或者放宽zipList条件
持久化阻塞
解决方案见 Redis 持久化-问题定位与优化
外在原因
CPU竞争
1.Redis是CPU高密集应用,建议不要和其他CPU密集应用部署在同一台服务器
2.对与开启了持久化或参与复制的主节点,建议不要绑定CPU,让其可以充分利用多核CPU
内存交换
即防止把内存数据换出到硬盘
问题定位:
1.查询Redis进程号:info server | grep process_id
2.根据进程号查询内存交换信息:cat /proc/{process_id}/smaps | grep Swap
问题优化:
1.保证机器内存充足
2.设置正确的redis最大内存maxmemory
3.降低系统使用swap优先级
网络问题
1.网络闪断:尽量避免,异地机房调用
2.Redis链接拒绝:适当增加maxclients最大连接数,尽量采用连接池方式
3.连接溢出too many open files:通过unlimit -n {连接数量},适当增加连接数量
4.backlog队列溢出:适当增加redis backlog的长度(默认511)
5.网络延迟:增加宽带,减少大对象传输
相关配置与命令
查看慢查询日志:执行slowlog get {n} n为查询最近日志的条数
查看大对象:执行 redis-cli -h {ip} -p {port} --bigkeys
Redis 内存详解
内存使用统计
1.利用info memory 查看详见Redis 数据类型与API-info命令详情
2.重点关注:used-memery_rss和used_memery以及他们的比值memory_fragmentation_ratio
3.memory_fragmentation_ratio>1,存在内存碎片
4.memory_fragmentation_ratio<1,存在内存交换
内存消耗划分
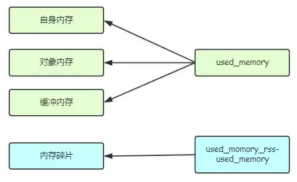
Redis内存知识要点
内存碎片
1.内存碎片定义:采用固定范围的空间存储对象,剩余的空间为内存碎片
2.正常碎片率在1.03左右
3.容易产生内存碎片的行为:频繁更新操作;大量将过期
4.优化内存碎片的方案:数据对齐,尽量用数字类型或者固定长度的字符串;安全重启,重启后内存碎片会得到整理
子进程内存消耗
子进程内存消耗主要在AOF/RDB重写时创建子进程产生。
优化方案:
1.虽然redis的子进程不需要消耗1倍的父进程,但是也要预留一些内存空间
2.设置sysctl vm.overcommit_memory=1,允许内核可以分配所有物理内存
3.查看当前系统是否开启THP,建议关闭,防止copy-on-write期间内存过度消耗
删除过期键策略
1.惰性删除:在客户端读取过期键时把键删除,如果过期键一直没有被访问,内存将得不到及时释放
2.定时任务删除:Redis执行定时任务,默认10秒执行一次,每次随机删除20个键,如果其中超过25%的都过期,循环执行。
内存溢出策略
1.noeviction:默认策略,不删除数据,不再响应写操作,报OOM command not allowed when used memory 异常
2.volatile-lru:根据LRU(最后一次访问时间)算法删除超时的键,如果没有可删除对象,返回noevicition策略
3.allkeys-lru:根据LRU算法删除键,不过键是否过期
4.allkeys-random:随机删除键,不过键是否过期
5.volatile-random:随机删除过期的键
6.volatile-ttl:删除最近要过期的键,如果没有返回noeviction策略
内存优化
1.缩减键值长度
2.Redis维护着[0-9999]的整数共享对象池,因此尽量使用整数对象(共享对象池设置LRU时无法使用)
3.尽量减少字符串append操作(append操作为了防止不停的append会给一个比较大的内存空间),降低预分配带来的内存碎片话
4.Redis的内部编码类型转换不可逆(只能重启的时候可以),尽量减少内存少的编码到大内存编码的转换
5.当集合(set)类型,元素都是整数,且数量不超过set-max-inset-entries时,内部编码为inset,可以减少内存消耗
6.控制键的数量,可以用hash代替sting,当hash内部编码为ziplist时可以大幅度减少内存,虽然耗时会增加,当value字节小时ziplist耗时逐渐降低
相关配置与命令
动态修改Redis内存上限:执行 config set maxmemory
溢出策略:maxmemory-policy
zipList编码转换控制-最大值:{type}-max-ziplist-value
zipList编码转换控制-最多元素:{type}-max-ziplist-entries
Inset编码转换控制:set-max-inset-entries (元素需都为整数)
Redis sentinel(哨兵)
为什么用redis sentinel
实现主从复制,主节点故障时可以自动检查,并推举它的其中一个从节点做主节点,解决主从复制的高可用问题

故障转移流程
1.主节点发生了故障
2.多个sentinel节点对主节点故障达成一致
3.选出一个sentinel为领导者负责故障转移
4.领导者选取其中一个从节点升级为主节点
安装和部署
部署步骤
1.部署redis主从复制
2.配置sentinel节点:
Sentinel节点可以配置多个,最好配置奇数个,每个节点除了端口号其他配置一样
在redis.conf文件中加入:
sentinel monitor {master-name} {ip} {port} {quorum} #master-name为主节点别名,{ip} {port}为监控的主节点ip和port,quorum代表至少要quorum个sentinel节点同意才判定客观下线,一般sentinel节点数的设一半加1
sentinel down-after-milliseconds {master-name} {times} #用ping的方式判断当redis节点与其余节点是否可达,超过times(单位毫秒)不可达,认定主观不可达
sentinel parallel-syncs {master-name} {nums} #每次有nums从节点对新主节点进行复制
sentinel failover-timout {master-name} {times} # times为故障转移的超时时间
如果sentinel有多个主节点,在redis.conf继续加入其他主节点就可:
sentinel monitor {master-name-2} {ip} {port} {quorum}
sentinel down-after-milliseconds {master-name-2} {times}
sentinel parallel-syncs {master-name-2} {nums}
sentinel failover-timout {master-name-2} {times}
3.启动sentinel 节点:
使用redis-sentinel {redis.conf} 启动或者使用redis-sever {redis.conf} --sentinel 启动
4.确认启动是否成功:redis-cli -h {sentinel节点ip} -p {sentinel 节点 port} info Sentinel
部署技巧
1.sentinel节点不应该部署在一台机器上
2.部署至少三个奇数个的sentinel节点
3.建议让一套sentinel监控一个业务的多个主节点集合
实现原理
三个定时监控任务
1.每个10秒sentinel向主节点发送info命令,获取主节点的从节点信息
2.每隔2秒sentinel进行交换信息,并通过_sentinel_:hello了解其他节点
3.每个(down-after-milliseconds秒(默认1秒)sentinel节点向其他sentinel节点和主节点,从节点发送ping请求,检查是否可达
主观下线和客观下线
1.主观下线:通过上述3中的定时任务,判断节点是否可达,如果不可达时间超过down-after-milliseconds没有回复,判断为主观下线
2.客观下线:主观下线数量数超过{quorum}(通常为所有sentinel节点的一半)数量,判断主节点为客观下线
领导者sentinel节点选举
1.在判断主节点客观下线后,每个sentinel节点通过sentinel is-master-down-by-addr 询问自己是否可以是领导者
2.通过raft算法(每个节点只能投一张票的算法)决定谁是领导者:
节点收到投票请求后会根据以下情况决定是否接受投票请求(每个 follower 刚成为 Candidate 的时候会将票投给自己):
请求节点的 Term 大于自己的 Term,且自己尚未投票给其它节点,则接受请求,把票投给它;
请求节点的 Term 小于自己的 Term,且自己尚未投票,则拒绝请求,将票投给自己。

一轮选举过后,正常情况下,会有一个 Candidate 收到超过半数节点(N/2 + 1)的投票,它将胜出并升级为 Leader。然后定时发送心跳给其它的节点,其它节点会转为 Follower 并与 Leader 保持同步,到此,本轮选举结束。
注意:有可能一轮选举中,没有 Candidate 收到超过半数节点投票,那么将进行下一轮选举。

故障转移
1.按步骤选出从节点:过滤ping命令超过5秒没回应,与主节点失联超过down-after-milliseconds*10秒的节点->选择slave-priority高的优先级->选择复制偏移量大的从节点->选择runid最小的从节点
2.升级选出的从节点为主节点
3.原来的主节点恢复联系后将其转为新主节点的从节点
实现高可用读写分离
1.从节点可做主节点的备份,实现故障转移
2.从节点可以拓展主节点的读能力
3.但是sentinel只会对从节点进行主观下线操作,不会做故障转移。因此需要配置多从节点,并实行实时监控来实现高可用的读写分离
相关配置与命令
动态调整sentinel配置:执行sentinel set ,如sentinel set mymaster quorum 2
查询主节点统计信息:sentinel masters
查询指定主节点统计信息:sentinel masters {master-name}
指定主节点的从节点统计信息:sentinel slaves {master-name}
指定主节点的sentinel节点集合:sentinel sentinels {master-name}
指定主节点的ip和端口:sentinel get-master-addr-by-name {master-name}
强制故障转移指定节点:sentinel failover {master-name}
查询当前节点主观下线个数:sentinel ckquorum {master-name}
取消当前sentinel对指定节点的监控:sentinel remove {master name}
设置从节点优先级:slave-priority
Redis cluster(集群)
Redis cluster数据分区
Redis cluster采用虚拟槽分区,所有节点映射到0-16383整数槽内。计算公式:slot=crc16(key)&16383,没个节点维护一部分槽及槽所映射的键值数据:

集群功能限制
1.key批量支持有限,mset,mget无法执行
2.如果key在不同的节点,无法执行事物操作
3.Hash,list等键值不能映射到不同的节点
4.不支持多库
5.主从结构只能支持一层
集群搭建
准备节点
1.划分为三个目录:conf,data,log用来同一存放配置,数据和日志
2.修改redis.conf文件如下:
#节点端口,{port}为端口号
port {port}
#开启集群模式
cluster-enabled yes
#节点超时时间,单位毫秒
Cluster-node-timeout 15000
#集群内部配置文件,第一次启动会生成一份
cluster-config-file “nodes-6379.conf”
3.按照2配置完所有节点后,启动所有节点
节点握手
1.在一个节点下对所有其他节点执行:cluster meet {ip} {port},完成节点握手
2.通过cluster nodes 查看节点是否已经通过握手组成集群
分配槽
1.为每个主节点分配槽:执行cluster addslots 如:
Redis-cli -h 127.0.0.1 -p 6379 cluster addslots {0…5461}
Redis-cli -h 127.0.0.1 -p 6380 cluster addslots {5642…10922}
Redis-cli -h 127.0.0.1 -p 6381 cluster addslots {10923…16383}
为主节点添加从节点
2.在从节点下,通过cluster replicate {nodeId}命令为主节点添加从节点,其中nodeId为主节点的id,可以在主节点下通过cluster nodes 命令查到
使用redis-trib.rb搭建集群
1.下载并安装redis-trib.rb
2.准备节点
3.执行redis-trib.rb create --replicas 1 127.0.0.1:6841 127.0.0.1:6842 127.0.0.1:6843 127.0.0.1:6844 127.0.0.1:6845 127.0.0.1:6846
其中 1 表示为为每个主节点分配1个从节点,按照顺序决定主节点,主节点为前面3个
节点通信
通信流程
Redis集群采用gossip进行通信,流程为:
1.每个节点单独开辟一个tcp接口,端口号为节点来端口加上10000
2.每个节点在固定周期选择几个节点发送ping消息
3.接受到瓶消息后节点发送pong做为响应
Gossip消息
1.Gossip消息分:
meet消息:通知新节点加入。
ping消息:检查节点是否在线,交换彼此信息
pong消息:接收到ping和pong消息是回应pong确认接收到了信息
fail消息:当一个节点下线时发送fail消息,广播其他节点自己已下线
2.节点选择:
ping消息默认每秒执行10次,随机选取5个节点,找出其中最久没有通信的节点进行通信。
如果发现有大于cluster_node_timeout/2的时间没有通信,则立刻发送ping消息。
在redis 集群中节点数量并不是越多越好,因为gossip的消息体包含一定数量的其他节点信息,会增加通信压力。
扩容集群
1.把新节点加入集群在任意节点执行:cluster meet {新节点ip} {新节点port} (线上建议用redis-trib.rb add-node因为cluster meet不会检查新节点是否已经加入)
2.把槽分配给新节点,老节点移出一些槽,达到槽平均分配的目的。这个流程直接执行会比较繁琐建议用 redis-trib.rb rehard 命令执行
收缩集群
1.把要下线的几点的槽分配给其他节点:执行命令redis-trib.rb rehard {被迁移节点ip} {被迁移节点port}
2.忘记节点,停止对要下线节点发送Gossip消息:执行命令 redis-trib.rb del-node {被迁移节点ip:被迁移节点port} {被迁移节点id}
3.下线节点
请求路由
1.键通过crc16(key)&16383计算得到对应槽位
2.通过槽位找到对应节点,如果刚好是当前节点就直接完成操作
3.否则进行重定向,由客户端根据接受到的moved信息再次发送请求,完成操作
故障转移
故障发现
1.主观下线:ping最后一次通信成功时间超过cluster-node-timeout判定为主观下线
2.客观下线:一个节点判定另一个节点主观下线后,将通过gossip向其他节点群发pfail通知
3.其他节点接受到通知后判定节点是否主观下线
4.计算主观下线成立的节点数量,如果超过一半的数量认定主观下线,则客观下线生效(需要在cluster-node-timeout*2的时间内完成,否则客观下线会失败,因此cluster-node-timeout的值不能太小)
5.通知所有节点该节点主观下线
6.通知该节点的从节点触发故障转移流程
故障恢复
1.通过从节点和主节点的断线时间是否超过cluster-node-timeoutcluster-slave-validity-factor判断,从节点是否有资格做故障转移
2.在有资格的节点中,复制偏移量大的节点优先发起选举
3.主节点对从节点点进行投票,每个主节点只有一张票
4.当有一个从节点超过半数主节点投票时(故障主节点的数量也算,集群主节点最好分布在3台物理机以上,防止选不出从节点),选择为主节点;如果在cluster-node-timeout2节点时间内没有选举出从节点,就判断选举失败
5.选出从节点后,该从节点变为主节点
6.主节点的槽被分配到从节点
7.向集群广播该从节点升级为主节点的信息。
集群运维注意事项
1.16384个槽必须全部分配,否则报错
2.Gossip宽带消耗随着节点数而增加,建议控制节点数在1000以内
3.防止数据倾斜:
防止节点与槽分配不均
防止不同槽对应键数差异太大,一般由hash_tag引起(当一个key包含 {} 的时候,就不对整个key做hash,而仅对 {} 包括的字符串做hash。如user:{user1}:ids)
防止集合对象含有大量元素
防止内存相关配置不一致
4.防止请求倾斜
Redis云平台CacheCloud
cacheCloud为redis的监控运营平台,可以实时对redis集群情况进行监控,并实现可视化的redis部署和操作。
详情见:https://blog.csdn.net/xiaofengbuhuimai/article/details/90449779
相关配置与命令
节点握手:执行 cluster meet {ip} {port}
查看节点握手状态情况:执行cluster nodes
查看集群运行情况:cluster info
信息交换频率:cluster-node-timeout(默认为15秒,即主观下线时间,主观下线传播时间<=cluster-node-timeout/2,从节点有效时间cluster-node-timeoutcluster-slave-validity-factor ,p判断客观下线有效时间:cluster-node-timeout2,选举从节点时间:cluster-node-timeout*2)
迁移槽:执行 redis-trib.rb reshard
忘记节点:执行redis-trib.rb del-node {被迁移节点ip:被迁移节点port} {被迁移节点id}
从节点有效因子:cluster-slave-validity-factor (默认10)
Redis 缓存设计
缓存键删除策略
1.在内存过大时,根据maxmemory-policy算法剔除
2.设置键的超时时间剔除
3.根据业务场景,由客户端主动删除
穿透优化
即访问不存在的key,导致直接访问数据库的问题的优化
1.对数据库不存在的key,保存null在redis中,并设置一个较短的过期时间
2.利用bitmaps实现布隆过滤器,把key设置在bitmaps中(由算法工程师实现),对不存在的key实现拦截
无底洞优化
即增加节点也不能达到优化的问题的优化
1.利用pipeline命令,实现多个命令一次执行
2.并行IO
3.利用hash_tag把key强行分配到同一个节点
雪崩优化
即对缓存发生故障的情况进行的优化
1.保证redis的高可用性,多准备备用节点。
2.为redis失败,在业务层面上设计降级方案
3.提前演练
热点key重建优化
即对访问频率特别高的key进行优化
1.互斥锁,只让一个线程去完成查询数据库把值放返回缓存的操作
2.缓存层面设计key不过期,在逻辑层面设计一个key的过期时间,用客户端的一条单独线程去对key进行更新的操作















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









