







重入锁ReentrantLock
与synchronized的比较
- JDK5.0的早期版本,重入锁的性能远高于synchronized,但从JDK1.6开始,因为synchronized的优化,就差不多了
- 重入锁有着显示的操作过程,因此他更灵活
- 重入锁可以连续两次获得通一把锁。只要锁都被unlock就没问题,如:
reentrantLock.lock();
reentrantLock.lock();
try {
i++;
} finally {
reentrantLock.unlock();
reentrantLock.unlock();
}
ReentrantLock使用简单样例:
public class TestReentrantLock implements Runnable {
public static ReentrantLock reentrantLock = new ReentrantLock();
public static int i = 0;
@Override
public void run() {
for (int j = 0; j < 10000; j++) {
reentrantLock.lock();
try{
i++;
}finally {
reentrantLock.unlock();
}
}
}
}
中断响应
中断响应的实现:可以用reentrantLock.lockInterruptibly()方法获取锁,当目标线程调用interrupt()方法后,该线程将响应中断,并抛出中断异常,释放自己获得的锁的同时,如果有正在申请的锁,也会放弃对该锁的申请,从而让其他线程可以获得该锁。从而使得在形成死锁的情况下,有线程可以顺利执行下去。
锁申请等待时间
- reentrantLock.tryLock()尝试获得锁,如果成功返回true,失败返回false,该方法不等待,立即返回
- reentrantLock.tryLock(long timeout, TimeUnit unit)在给定的时间呢尝试获得锁
Condition
Condition condition = reentrantLock.condition()
condition.wait()
用法与wait()差不多,通过condition.signal()唤醒
信号量Semaphore
重复锁一次只允许线程访问一个资源,而信号量可以指定多个,如代码:
public class TestSemaphore implements Runnable {
/**
* 一次允许5个
*/
final Semaphore semaphore = new Semaphore(5);
@Override
public void run() {
try {
semaphore.acquire();
//do sth
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Test
public void testSe() {
ExecutorService executorService = Executors.newFixedThreadPool(20);
final TestSemaphore testSemaphore = new TestSemaphore();
//最终会以5个线程为一组为单位,依次执行
for (int i = 0; i < 20; i++) {
executorService.submit(testSemaphore);
}
}
}
读写锁ReentrantReadWriteLock
如下代码如果两个线程用的都是读写锁的读锁readLock.lock()那么他们就是非阻塞的不需要等待彼此的锁。否则不管是写写的情况,还是读写的情况都是阻塞的。读写锁适用于读场景远远大于写场景的地方
/**
* 读写锁
*/
ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
/**
* 读锁
*/
Lock readLock = reentrantReadWriteLock.readLock();
/**
* 写锁
*/
Lock writeLock = reentrantReadWriteLock.writeLock();
倒计时器CountDownLatch
类似join操作,示例代码:
public class CountDownLatchTest implements Runnable {
static final CountDownLatchTest countDownLatchTest = new CountDownLatchTest();
static final CountDownLatch countDownLatch = new CountDownLatch(5);
@Override
public void run() {
//do sth
countDownLatch.countDown();
}
@Test
public void testCountDownLatch(){
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 5; i++) {
executorService.submit(countDownLatchTest);
}
try {
//阻塞到5个线程都执行完为止
countDownLatch.await();
}catch (InterruptedException e){
e.printStackTrace();
}
//do sth
executorService.shutdown();
}
}
线程阻塞工具类LockSupport
- LockSupport.park()与Thread.suspend()相比,他弥补了由于resume()在前发生,导致线程无法继续执行的情况。因为LockSupport.unpack()的作用是使得许可变为可用,即使unpark()发生在park()之前,他也可以使park()操作立即返回。 同时park()会明确的给出一个watting状态,并标注为park.
- 和Object.wati()相比他不需要获取锁,也不会抛出InterruptedException异常。
代码示例:
public class TestLockSupport {
public static Object o = new Object();
static Thread t1 = new CThread();
static Thread t2 = new CThread();
public static class CThread extends Thread{
@Override
public void run() {
synchronized (o){
//do sth
LockSupport.park();
}
}
}
@Test
public void testLockSupport(){
t1.start();
//do sth
t2.start();
LockSupport.unpark(t1);
LockSupport.unpark(t2);
}
}
线程池
Executor框架提供的各类线程池
Executors.newFixedThreadPool()
固定数量的线程池,当有新任务时,如果有空余线程直接使用空余线程。否则任务被暂存在任务队列中
Executors.newSingleThreadExecutor()
只有一个任务的线程池,任务被保存在一个队列中,按照先进先出执行。
Executors.newCachedThreadPool()
可以根据实际情况调整线程池的数量。有空余线程就复用,否则创建新的线程。空余线程经过一段时间后会自动关闭。默认为60秒
Executors.newSingleThreadScheduledExecutor()
线程池大小为1,可以在某个固定的延时之后执行,或者周期性的执行任务
Executors.newScheduledExecutor()
同Executors.newSingleThreadScheduledExecutor()但是可以指定线程池数量
参数含义与内部实现
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize
线程池中的数量
maximumPoolSize
指定线程池最大线程数量
keepAliveTime
超过corePoolSize时,空余的线程存活时间
unit
keepAliveTime的单位
workQueue
被提交但未被执行的任务队列,是一个BlockingQueue接口的对象,用于存放Runnable对象,他有如下几种:
- 直接提交队列SynchronousQueue():该队列没有容量,一个插入要等待一个相应的删除操作。会不停的把任务提交给线程池。
线程池newCachedThreadPool就用了该队列。newCachedThreadPool的corePoolSize为0,maximumPoolSize为无穷大,因此当任务提交时,如果newCachedThreadPool没有空闲的线程,它会马上新建线程。 - 有界的任务队列ArrayBlockingQueue(int capacity),capacity为队列任务数量。当有新任务时,如果线程数不超过corePoolSize,就新建线程。如果超过corePoolSize就把任务放进队列。当任务放不下时且线程数不超过maximumPoolSize时,新建新的线程,如果超过开启拒绝策略。
- 无界的任务队列LinkedBlockingDeque:与有界的任务队列类似,区别在于capacity的大小没有限制。因此当线程数超过corePoolSize且任务队列放不下时会不停的新建线程,直到耗尽系统资源。Executors.newFixedThreadPool()使用了该队列,并把corePoolSize与maximumPoolSize的大小设置成一样。当然如给LinkedBlockingDeque指定大小,他也会变成有界任务队列
- 优先任务队列PriorityBlockingQueue:与有界的任务队列类似,区别在于可以设定任务队列的优先级。即让Runable对象实现Comparator接口,然后按照Comparator次序执行。
threadFactory
线程工厂,用于创建线程,他只有一个newThread(Runable r),一般用默认即可。如果想要自定义复写这个方法就可以。如:
ThreadFactory threadFactory = new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
//do sth
return new Thread(r);
}
};
handler
handler为线程池没有空闲线程且无法扩容,队列已满时的拒绝策略,JDK内置策略如下
- ThreadPoolExecutor.AbortPolicy():直接抛出异常,阻止系统工作。
public static class AbortPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
- ThreadPoolExecutor.CallerRunsPolicy():在调用者线程(即主线程)中运行丢弃的任务。
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
- ThreadPoolExecutor.DiscardOldestPolicy():丢弃最老的请求,也就是即将被执行的任务
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
- ThreadPoolExecutor.DiscardPolicy():直接丢弃无法处理的任务(即不做任何处理,rejectedExecution是个空方法)
public static class DiscardPolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
可以自定义handler,只需要实现RejectedExecutionHandler即可。可以参考:https://jishuin.proginn.com/p/763bfbd5c1a6
扩展线程池
ThreadPoolExecutor支持扩展,复写以下方法即可
ExecutorService es = new ThreadPoolExecutor(
5,
5,
1l,
TimeUnit.DAYS,
new LinkedBlockingDeque<Runnable>(),
Executors.defaultThreadFactory(),
c
){
/**
* 在任务开始前
* @param t
* @param r
*/
@Override
protected void beforeExecute(Thread t, Runnable r) {
//do sth
}
/**
* 在任务完成后
* @param t
* @param r
*/
@Override
protected void afterExecute(Runnable r, Throwable t) {
//do sth
}
/**
* 线程池退出时执行
*/
@Override
protected void terminated() {
//do sth
}
};
优化线程池线程数量
一般来说,线程池线程的数量要考虑cpu的数量,内存大小等因素。
计算线程池线程数量的大小公式为:
Nthreads = NcpuUcpu(1+w/c)
其中Nthreads为线程数量,Ncpu为cpu数量,Ucpu为cpu使用率,w/c为等待时间与计算时间的比值
线程池与堆栈
直接执行pools.submit()方法,出异常时无法输出堆栈信息。实现输出堆栈的修改如下:
- 可以改成pools.execute()
- Futrue f = pools.submit(),f.get();
- 复写ThreadPoolExecutor的execute或者submit方法
JDK并发容器
ConcurrentHashMap
- HashMap是线程不安全的,想要在多线程环境中使用HashMap,可以通过:
Map m = Collections.synchronizedMap(new HashMap<>());
来实现,这样做其实就是在SynchronizedMap中传入了一个HashMap,然后在家里synchronized的方法中调用get和put.
这样做put和get操作的性能会比较低,因此我们需要ConcurrentHashMap。
-
ConcurrentHashMap提高get和put操作性能的原因在于,在ConcurrentHashMap内部进一步分成了若干个小的HashMap,称之为段。默认为16个。这样操作get和put时就只需要获取那一段的锁就可以了。从而通过减少锁的粒度,提高了性能。
-
对于size操作,因为是全局的操作,ConcurrentHashMap需要同时获取所有段的锁,虽然首先会使用无锁操作,在失败时才会尝试加锁,但是他的性能还是比Collections.synchronizedMap(new HashMap<>())的差。
-
因此在多线程环境中ConcurrentHashMap适合与get与put多,size操作少的场景。
CopyOnWriteArrayList
- 对于CopyOnWriteArrayList,读操作是不会阻塞的,不管其他线程是读操作还是写操作都不会造成当前线程阻塞。
- 因为他的实现机制为:写操作不会直接修改原来的数组,而是操作一个副本,操作完毕把副本替换原来的数组。而原来的数组设计为不变模式,无法修改,这能被替换。
ConcurrentLinkedDeque
ConcurrentLinkedDeque是线程安全的LinkedDeque,可以说是高并发环境下性能最好的队列原因在于:
1.通过cas方法实现了无锁
2.不是每一次都会更新tail,减小 CAS 更新 tail 节点的次数
主要关注以下两个方法的实现offer与poll,参考:http://www.javashuo.com/article/p-tmfznfif-bu.html
offer
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
// 1. p is last node
if (q == null) {
// 1.1 经过自旋保证节点必定添加到数据链中
if (p.casNext(null, newNode)) {
// 1.2 p表明当前结点,当前节点不是尾节点时更新
// 也就是说tail不必定是尾节点,尾节点为tail或tail.next
// 更新失败了也不要紧,由于失败了表示有其余线程成功更新了tail节点
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
// 2. 遇到哨兵节点,从 head 开始遍历
// 可是若是 tail 被修改,则使用 tail(由于可能被修改正确了)
//哨兵节点即next指向自己的节点,也就是已经移除,等待被回收的节点
else if (p == q)
p = (t != (t = tail)) ? t : head;
// 3. 尾节点只多是tail或tail.next。若是tail发生变化则直接从tail开始遍历
else
//取下一个节点或者最后一个节点
// Check for tail updates after two hops.
// 其实我认为这里一直取p.next节点遍历最终能够遍历到尾节点,能够没必要取从新tail
// 可能从新取tail会遍历更快
p = (p != t && t != (t = tail)) ? t : q;
}
}
poll
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 1. 出队后 p.item 必定为 null
if (item != null && p.casItem(item, null)) {
if (p != h) // hop two nodes at a time
// 更新头节点并将头节点的 next 指向本身。成为哨兵节点,等 GC 回收
// 一样容许失败,说明其它的线程更新了头节点
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
// 2. 遍历到尾节点了,没有元素了
} else if ((q = p.next) == null) {
updateHead(h, p);
return null;
// 3. 出现哨兵节点,说明有其它线程poll后更新了head,须要从新从head开始遍历
} else if (p == q)
continue restartFromHead;
// 4. 继续遍历
else
p = q;
}
}
}
BlockingQeque
BlockingQeque是双阻塞队列:没有元素时notEmpty.wait()读取,插入新元素后通过notEmpty.signal();数据满后通过notFull.wati()阻塞写入,取走一个后通过notFull.signal()写入。
/** Main lock guarding all access */
final ReentrantLock lock = new ReentrantLock();
/** Condition for waiting takes */
private final Condition notEmpty = lock.newCondition();
/** Condition for waiting puts */
private final Condition notFull = lock.newCondition();
适合做数据共享通道,如消息队列。他有两个实现LinkedBlockingQeque和ArrayBlockingQueue,ArrayBlockingQueue适合做有界队列,LinkedBlockingQeque适合做无界队列。
ConcurrentSkipListMap
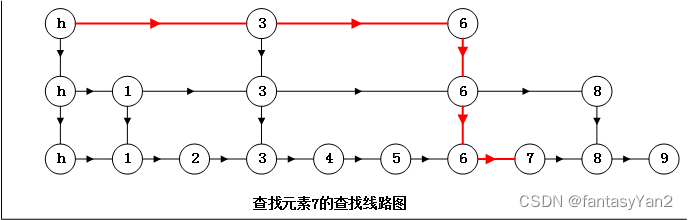
- ConcurrentSkipListMap的实现机制如图,同时通过Cas保证线程安全。
- 相比与ConcurrentHashMap,ConcurrentSkipListMap是有序的。性能方面在线程数少时ConcurrentHashMap的存储速度一般比ConcurrentSkipListMap快,但是因为ConcurrentSkipListMap的存储速度与线程数无关,因此线程数非常多时可以考虑用ConcurrentSkipListMap。















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









